## 错误示范:没有加逗号,a 的类型会是 int
a = (50)
print(f'a 的类型是: {type(a)}')
## 正确示范:加了逗号,b 才被识别为元组
b = (50,)
print(f'b 的类型是: {type(b)}')1 python基础知识
欢迎来到《商业大数据分析与应用》的第一堂课。商学院的同学们在开启编程之旅时可能会有些许忐忑。请放心,这门课程的设计初衷,正是为像你们一样没有编程背景,但对商业世界充满好奇与洞察力的未来领导者们量身定做的。我们将摒弃计算机科学中那些复杂的底层理论,聚焦于如何利用Python这一强大而友好的工具,解决我们每天在金融、市场、管理中遇到的实际问题。
1.1 Python基础与核心数据结构
Python秉承“优雅”、“明确”、“简单”的设计哲学,这使得它成为数据分析领域的首选语言。在本章,我们将从最基础的数据“容器”——元组(Tuple)、列表(List)和字典(Dictionary)——开始,学习如何组织和存储商业世界中的信息。
1.1.1 元组 (Tuple):不可变的记录
在商业分析中,我们常常会遇到一些一旦记录下来就不应再被修改的数据,比如一笔交易的成交时间、成交价格和成交量,或者一位客户的出生日期和身份证号。为了确保这类数据的完整性和安全性,Python提供了一种名为“元组”的数据结构。
元组(Tuple)是一个有序且不可变的元素集合。它的“不可变性”(Immutability)是其最核心的特征,意味着一旦创建,你无法增加、删除或修改元组中的任何元素。这就像是把数据刻在了石板上,稳固而可靠。
1.1.1.1 创建元组
创建元组非常简单,只需将一系列元素用逗号隔开,并用圆括号 () 包围起来。
## 创建一个空元组
tup1 = ()
print(f'tup1 的类型是: {type(tup1)}')
## 创建一个包含两个整数的元组
tup2 = (2, 3)
print(f'tup2 的内容是: {tup2}')
print(f'tup2 的类型是: {type(tup2)}')
特别提醒:单个元素的元组
当元组中只有一个元素时,必须在该元素后面加上一个逗号 ,,否则Python会将其误认为是普通的数值或字符串,而不是元组。
1.1.1.2 访问元组元素
元组是一个有序序列,我们可以像查阅一本书的特定页码一样,通过“索引”(Index)来访问其中的特定元素。在Python中,索引从 0 开始。
元组一旦被创建,我们只能访问(读取)其中的元素,而不能修改它们。这种访问方式与字符串非常相似。
1.1.1.3 元组的特点与常用方法
图 fig-tuple-summary 概括了元组的主要特性和操作方法。
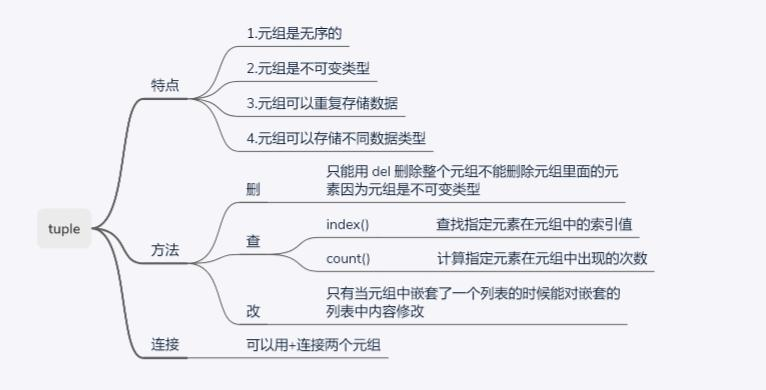
- 特点:
- 有序性: 元素的排列顺序是固定的。
- 不可变性: 创建后无法修改。
- 可重复: 可以包含重复的元素。
- 异构性: 可以同时存储不同数据类型的元素,如数字、字符串等。
- 方法:
del: 关键字del不能删除元组内的某个元素(因为元组不可变),但可以删除整个元组变量。index(): 查找指定元素在元组中首次出现的索引位置。count(): 计算指定元素在元组中出现的次数。
- 连接:
- 使用
+号可以将两个元组连接成一个新的元组。
- 使用
1.1.1.4 实践任务一:记录每日股票数据
现在,让我们通过一个实际任务来巩固对元组的理解。
任务描述:某金融数据服务商需要记录2023年3月中上旬(3月1日-3月14日)共十个交易日,每日收集到的分价表数据的股票只数。请你创建一个元组 tuple 来保存这些数据,并利用切片操作访问3月6日至3月9日的数据。
数据如下:
- 2023-03-14: 5110只
- 2023-03-13: 5108只
- 2023-03-10: 5103只
- 2023-03-09: 5101只
- 2023-03-08: 5099只
- 2023-03-07: 5088只
- 2023-03-06: 5098只
- 2023-03-03: 5097只
- 2023-03-02: 5091只
- 2023-03-01: 5094只
##题目一
tuple=('4102','4382','4922','3975','3407','2894','3217','4926','4531','4557')
##利用切片访问3月6日-3月9日的股票分价表数据
print(tuple[3:7])在 列表 lst-task-tuple-solution 中,我们首先创建了一个元组。请注意,虽然原始数据是数字,但代码中使用了字符串来存储,这体现了元组的异构性。接着,我们使用切片 tuple[3:7] 来提取索引从3到6(不包括7)的元素,这正好对应了任务要求的数据区间。
1.1.2 列表 (List):灵活的数据容器
与元组的“刻板”不同,列表(List)是Python中最为常用、也最为灵活的数据结构。它是一个有序且可变的集合。你可以把它想象成一个购物清单,你可以随时在清单上添加新商品、划掉已买的商品,或者更改商品的购买数量。在商业分析中,列表的这种灵活性使其非常适合处理动态变化的数据集,如追踪一段时间内的股票价格、管理营销活动的用户名单等。
1.1.2.1 列表的创建与基本操作
列表的创建与元组类似,但使用的是方括号 []。
## 1. 简单创建与使用
squares =
print(f'squares 列表内容: {squares}')
## 2. 与字符串一样,列表可以被索引和切片
print(f'第一个元素: {squares}') # 索引
print(f'最后一个元素: {squares[-1]}')
print(f'后三个元素: {squares[-3:]}') # 切片
print(f'复制整个列表: {squares[:]}')1.1.2.2 列表的可变性:修改与扩展
列表的核心特性是“可变性”(Mutability)。这意味着我们可以直接修改列表的内容。
## 3. 列表的连接操作
squares =
squares_extended = squares +
print(f'连接后的列表: {squares_extended}')
## 4. 列表是可变类型,可更改列表中内容
cubes = # 注意这里有一个错误的值 65
cubes = 64 # replace: 将索引为3的元素(65)替换为64
print(f'修正后的列表: {cubes}')除了直接修改和连接,列表还提供了一系列强大的方法(methods)来动态地管理其内容:
list.append(x): 在列表的末尾添加一个元素x。这就像在购物清单的最后加一项。list.insert(i, x): 在指定位置i插入一个元素x。这允许我们在清单中间插入一项。
1.1.2.3 实践任务二:处理股票成交数据
任务描述:你需要处理一份2023年3月中上旬共十个交易日的股票分时成交明细数据量。 1. 创建一个列表 list 来存储这些数据。 2. 利用索引访问3月6日的数据。 3. 利用负数索引访问最后三天的数据。
数据如下 (单位:只): 4557, 4531, 4926, 3217, 2894, 3407, 3975, 4922, 4382, 4102 (按日期倒序排列)
##题目二
list=['4102','4382','4922','3975','3407','2894','3217','4926','4531','4557']
##利用索引访问3月6日的股票分时成交明细数据
print(list)
##利用负数索引访问最后三天的股票分时成交明细数据
print(list[-3:])在 列表 lst-task-list-solution 中,我们看到如何精确地使用正索引 list[3] 定位到特定日期的数据,并使用负索引切片 list[-3:] 快捷地获取数据集尾部的部分,这在分析最近数据时非常高效。
1.1.3 字典 (Dictionary):键值对的世界
在现实世界中,我们不仅仅处理有序的序列,更多时候是处理具有“标签”或“键”的信息。例如,在个人信息表中,“姓名”对应“张三”,“年龄”对应“20”。Python中的字典(Dictionary)正是为此而生。
字典是一种无序的、可变的、通过键(key)来存取值(value)的数据结构。它就像一部真正的字典,你可以通过查找单词(键)来找到它的释义(值)。在金融和商业领域,字典是组织结构化数据的利器,比如用股票代码(键)关联公司名称、股价、市盈率等信息(值)。
1.1.3.1 创建字典
字典由花括号 {} 包围,内部由一系列的 key: value 对组成,每对之间用逗号隔开。
创建字典有两种主要方式:
- 直接法:一次性定义所有的键值对。
- 间接法:先创建一个空字典,然后逐个添加键值对。
## ① 直接法
tel_direct = {'jack': 4098, 'sape': 4139}
print(f'直接法创建: {tel_direct}')
## ② 间接法
tel_indirect = {} # 回顾下空集合的创建方式
tel_indirect['jack'] = 4098
tel_indirect['sape'] = 4139
print(f'间接法创建: {tel_indirect}')1.1.3.2 字典的访问与修改
我们可以通过键来访问和修改字典中的值。
tel = {'jack': 4098, 'sape': 4139}
## 访问字典的全部键 (keys) 和值 (values)
print(f'所有键: {tel.keys()}')
print(f'所有值: {tel.values()}')
## 修改jack的号码
tel['jack'] = 123456
print(f'修改后的字典: {tel}')keys() 和 values() 方法返回的是特殊的视图对象,它们会动态反映字典的变化。tel['jack'] = 123456 这行代码展示了如何通过键来更新对应的值。如果键 jack 不存在,这行代码则会创建一个新的键值对。
1.1.3.3 实践任务三:证券编码规则查询
任务背景:一位金融领域的初学者小智对A股市场的证券编码规则感到困惑,向你请教。你需要创建一个字典,将股票代码的开头数字与对应的板块进行一一映射,并能快速查询。
编码规则: - 600开头: 上证A股 - 900开头: 上证B股 - 000开头: 深证A股 - 200开头: 深证B股 - 400开头: 三板市场股票
任务要求: 1. 用两种方式({} 和 dict())分别创建这个字典。 2. 查询 000 开头对应的股票板块。
##题目三
##{}方法创建字典
a = {'600':"上证A股",'900':"上证B股",'000':"深证A股",'200':"深证B股",'400':"三板市场股票"}
##dict()方法
b=dict()
b["600"] = "上证A股"
b["900"] = "上证B股"
b["000"] = "深证A股"
b["200"] = "深证B股"
b["400"] = "三板市场股票"
##查询“000”开头对应股票
print(a['000'])在 列表 lst-task-dict-solution 中,我们不仅练习了字典的两种创建方法,还通过 a['000'] 演示了字典最核心的应用——通过键快速、高效地检索信息。这比在列表或元组中从头到尾搜索要快得多,尤其是在处理大规模数据时。
1.2 Python高级数据结构
在我们掌握了Python内建的元组、列表和字典之后,是时候接触更专业、更强大的数据结构了。在金融和数据科学领域,处理大规模的数值型数据是家常便饭。为了高效地完成这些任务,我们将引入一个名为NumPy的库。
NumPy (Numerical Python) 是Python科学计算的核心库。它提供了一个高性能的多维数组对象(ndarray),以及用于处理这些数组的各种工具。对于商学院的学生来说,你可以将NumPy数组看作是列表的“超级进化版”,它在数值运算速度、内存效率和数学函数支持方面远超普通列表。
1.2.1 列表(List) vs. NumPy数组(array)
尽管列表可以存储数据,但在进行大规模数值计算时,它有两个主要缺点: 1. 性能: Python列表是通用的容器,可以存储不同类型的对象。这种灵活性牺牲了性能。对列表中的每个元素进行数学运算,Python都需要进行类型检查,这会大大减慢计算速度。 2. 功能: 列表本身没有内置高级数学运算(如矩阵乘法、线性代数运算)的方法。
NumPy数组则解决了这些问题: 1. 同质性: NumPy数组要求所有元素必须是相同的数据类型(例如,全部是float64或int32)。这消除了类型检查的开销,并允许数据在内存中紧凑存储,从而极大地提高了运算效率。 2. 向量化操作: NumPy允许你直接对整个数组执行数学运算,而无需编写循环。这种“向量化”操作底层由高效的C语言或Fortran代码实现,速度飞快。
下面是一个简单的例子,展示了列表和NumPy数组的创建方式。
## 使用Python内置的列表
my_list =
print(f'这是一个列表: {my_list}')
## 使用Numpy创建数组
import numpy as np
my_array = np.array()
print(f'这是一个NumPy数组: {my_array}')1.2.2 Python内置 array 模块
在介绍强大的NumPy之前,值得一提的是Python本身也提供了一个内置的array模块。它同样可以创建同质类型的数组,比列表在存储上更高效,但其功能远不如NumPy强大。我们可以将它视为列表和NumPy数组之间的一个过渡。
array模块在创建时需要指定一个“类型码”,用来表明数组中存储的数据类型。例如,'i' 代表有符号整数。
1.2.2.1 创建与访问 array
import array
## 创建一个整数类型的数组
my_array = array.array('i',)
print(f'创建的array对象: {my_array}')
## 访问数组元素,索引方式与列表相同
print(my_array) # 输出数组的第一个元素
print(my_array) # 输出数组的最后一个元素1.2.2.2 修改、迭代与切片
array对象同样支持修改、迭代、获取长度和切片等基本操作,语法与列表几乎完全一致。
import array
my_array = array.array('i',)
## 修改数组元素
my_array = 6
print(f'修改后的第一个元素: {my_array}')
## 数组迭代
print('迭代输出:')
for i in my_array:
print(i)
## 数组长度
print(f'数组长度: {len(my_array)}')
## 数组切片
print(f'切片结果: {my_array[1:4]}')尽管内置array模块在特定场景下有用,但在我们的课程和绝大多数数据分析实践中,NumPy是当然不让的选择。
1.2.3 NumPy数组实战
NumPy的真正威力在于其创建多维数组和进行高效数值计算的能力。在金融领域,我们经常处理时间序列数据(一维)、截面数据(一维或二维)、面板数据(多维)等,NumPy都能轻松应对。
1.2.3.1 实践任务:模拟股票日收益率
问题描述: 假设你是一位量化分析师,需要模拟一个包含2000支股票、过去两年(约500个交易日)的日收益率数据。请使用numpy库创建一个符合标准正态分布(均值为0,标准差为1)的随机数数组来模拟这个数据集,并输出该数组的形状以及前5支股票、前5个交易日的模拟数据。
解题思路: 我们可以使用numpy.random模块中的standard_normal函数来生成符合标准正态分布的随机数。该函数接受一个元组作为参数,定义了输出数组的形状。
##题目一
import numpy as np
stocks = 2000 # 2000支股票
days = 500 # 两年大约500个交易日
## 生成服从正态分布:均值期望=0,标准差=1的序列
stock_day = np.random.standard_normal((stocks, days))
print(stock_day.shape) #打印数据组结构
## 打印出前五只股票,头五个交易日的涨跌幅情况
print(stock_day[0:5, :5])从 列表 lst-stock-simulation 的输出 (2000, 500) 中,我们可以清晰地看到数据的维度,即2000行(代表股票)和500列(代表交易日)。随后的矩阵则直观展示了模拟出的收益率数据。这在金融建模和风险分析中是非常基础且重要的一步。
1.2.4 Pandas Series: 带标签的数组
在进入更复杂的DataFrame之前,我们先来认识一下Pandas库的另一个核心数据结构:Series。Pandas是建立在NumPy之上的,专门用于数据处理和分析的库。
你可以将Pandas Series理解为一个带标签的一维NumPy数组。它由两部分组成: 1. 数据 (values): 内部其实就是一个NumPy数组。 2. 索引 (index): 为数据中的每一个元素都附上了一个标签。
这个“标签”功能对于商业数据分析至关重要。例如,我们可以用日期作为股票价格的索引,用公司名称作为财务数据的索引,使得数据更具可读性和操作性。
1.2.4.1 实践任务:创建金融数据序列
任务描述: 请使用Pandas库,通过一个Python列表 [1, 3, 5, 6, 10, 23] 创建一个Series对象。
##题目二
import pandas as pd
##(1)通过列表创建的Series
lst =
s1 = pd.Series(lst)
print(s1)观察 列表 lst-create-series 的输出,左边一列 0, 1, 2, 3, 4, 5 就是默认生成的整数索引,右边一列是我们的数据。dtype: int64 表明了这个Series中存储的是64位整数。在后续章节中,我们将学习如何为Series指定更有意义的索引。
1.3 程序控制结构
到目前为止,我们学习了如何存储和组织数据。但程序真正的威力在于它能够根据不同的条件执行不同的操作,或者重复执行某些任务。这就是所谓的“控制流”。Python提供了几种核心的控制结构,主要包括:
- 顺序结构:这是最简单的结构,代码从上到下逐行执行,我们之前的代码都遵循这个结构。
- 分支结构(条件语句):允许程序根据条件的真假来选择执行哪一段代码。核心是
if-else语句。 - 循环结构:让程序能够重复执行一段代码块。主要有
for循环和while循环。
本章将详细讲解分支和循环结构,它们是构建任何复杂商业逻辑的基础。
1.3.1 分支结构:if-else 语句
在商业决策中,我们无时无刻不在进行“如果…那么…”的判断。例如,“如果公司利润率超过20%,则发放奖金;否则,不发奖金。” if-else 语句就是用来在代码中实现这种逻辑的。
它的基本语法是:
if condition:
# 如果 condition 为真 (True),执行这里的代码
indented_block_A
else:
# 如果 condition 为假 (False),执行这里的代码
indented_block_B这里的 condition 是一个可以被判断真假的表达式。Python中,if 和 else 后面的冒号 : 以及代码块的缩进是强制性的语法要求,它定义了代码的层级结构。
1.3.1.1 实践任务一:个人所得税计算
案例背景: 根据简化的个人所得税规定,工资中高于5000元的部分,需要缴纳5%的个人所得税;低于或等于5000元的部分则免税。
任务要求: 假设一位员工的基本工资是8000元,请编写程序计算其税后工资。
##题目一
salary = 8000 # 基本工资
if salary <= 5000: # 判断基本工资是否小于等于5000
rate = 0 # 基本工资小于等于5000,不扣税,即扣税率为0%
else:
rate = 0.05 # 基本工资大于5000,扣税率为0.05,即5%
## 计算税后工资,基本工资-扣税,扣税额为超过3000部分的乘以扣税率
salary = salary - (salary - 5000) * rate
print("税后工资为:%d" % salary) # 将税后工资打印输出
逻辑错误警示
1.3.1.1.1 错误分析
在上述 列表 lst-tax-calculation 代码中,salary = salary - (salary - 5000) * rate 这一行计算税后工资的逻辑是错误的。当 salary <= 5000 时,rate 为 0,salary 的值不变,这是正确的。但当 salary > 5000 时,rate 为 0.05,它计算的税额是 (salary - 5000) * 0.05,然后从原始工资中减去这个税额。
然而,原始代码中有一处笔误或逻辑混淆,注释写的是“超过3000部分”,但代码逻辑是基于5000元起征点计算的。如果严格按照“工资大于3000元的部分将扣除5%”的原始问题描述(见PDF第46页),那么代码的判断和计算都应围绕3000元进行。此处代码与原始PPT描述不一致。
1.3.1.1.2 正确写法 (基于5000元起征点)
正确的逻辑应该是先计算应纳税额,再从总工资中扣除。
base_salary = 8000
taxable_income = 0
tax = 0
if base_salary > 5000:
taxable_income = base_salary - 5000
tax = taxable_income * 0.05
net_salary = base_salary - tax
print(f"税后工资为:{net_salary}")1.3.1.1.3 重要提醒
为通过平台检测,在线练习时仍需按原始错误代码输入。
1.3.2 循环结构
循环是编程中用于自动化重复性任务的强大工具。
1.3.2.1 while 循环:当条件满足时重复
while 循环会在一个指定条件为真的前提下,重复执行一段代码。它适用于那些你不知道具体要循环多少次,但知道循环应该在什么条件下停止的场景。
语法:
while condition:
# 只要 condition 为 True,就一直执行这里的代码
indented_block1.3.2.2 实践任务二:薪资录入系统
任务要求: 利用 while 循环实现一个简单的员工薪资录入功能。程序会不断提示用户输入薪资,如果输入小于等于0的数值,则提示错误并要求重新输入;如果输入’Q’(不区分大小写),则结束录入。最后,打印出成功录入的员工数量和已发放的总薪资。
##题目二
sum_salary = 0
salary_list = []
salary = 0
while True:
salary = input('请输入员工的薪资,输入Q结束计算:')
if salary.upper() == 'Q':
print('程序结束')
break
elif int(salary) <= 0:
print('您输入的数值有误,请重新输入')
continue
salary_list.append(salary)
sum_salary += int(salary)
print(len(salary_list))
print(sum_salary)在这个例子中,while True: 创建了一个“无限循环”。我们必须在循环内部提供一个退出的机制,这就是 break 语句的作用。当用户输入’Q’时,break 会立即终止循环。continue 语句则用于跳过当前这次循环的余下部分,直接进入下一次循环,这在我们处理无效输入时非常有用。
1.3.2.3 for 循环:遍历序列中的每一项
for 循环用于遍历一个序列(如列表、元组或字符串)中的每一个元素。它更适用于你已经明确知道要处理的数据集合以及循环次数的场景。
语法:
for item in sequence:
# 对 sequence 中的每一个 item,执行一次这里的代码
indented_block1.3.2.4 实践任务三:计算投资组合期望回报率
任务背景: 证券投资组合的期望报酬率(Expected Return)可以通过组合中各资产的期望报酬率与其权重的加权平均来计算。公式为:\(TR = \sum_{i=1}^{n} R_i \times A_i\)。其中,\(R_i\) 是第 \(i\) 种证券的期望报酬率,\(A_i\) 是其在组合中的权重。
任务要求: 已知一个投资组合中四种证券的期望报酬率和权重,请使用 for 循环自动计算该组合的总体投资回报率。
##题目三
Ri=[0.15,0.20,-0.10,0.35] #收益率序列
Ai=[0.3,0.2,0.3,0.2] #权重序列
TR=0
for j in range(len(Ri)):
TRij=Ri[j]*Ai[j]
TR+=TRij
print("投资组合的期望报酬率为:{:.2f}".format(TR))在 列表 lst-portfolio-return 中,range(len(Ri)) 生成了一个从0到3的数字序列 [0, 1, 2, 3]。for 循环依次取出这些数字作为索引 j,从而能够并行地访问 Ri 和 Ai 两个列表中的对应元素,完成加权求和的计算。这是 for 循环在数据处理中非常典型的应用。
1.4 函数式编程
随着我们编写的程序越来越复杂,将代码组织成可重用的逻辑块变得至关重要。这就是“函数”的作用。函数是一段组织好的、可重复使用的、用来实现单一或相关联功能的代码段。它能极大地提高代码的模块性和复用性。
本章我们将学习两种定义函数的方式:使用 def 关键字创建标准函数,以及使用 lambda 关键字创建轻量级的匿名函数。
1.4.1 自定义函数 (def)
函数就像一个加工机器,你给它一些原材料(参数),它会按照预设的流程(函数体内的代码)进行处理,并可能返回一个成品(返回值)。
1.4.1.1 函数的定义
一个标准Python函数的定义通常遵循以下结构:
def关键字: 表明你正在定义一个函数。- 函数名: 一个符合命名规则的标识符。
- 参数列表
(): 括号内是函数需要接收的输入,参数之间用逗号隔开。 - 冒号
:: 函数头的结束标志。 - 函数体: 缩进的代码块,包含了函数的具体逻辑。
return语句 (可选): 用于结束函数并返回一个值。如果没有return语句,函数执行完毕后默认返回None。
1.4.1.2 实践任务一:改进个人所得税计算器
让我们将 sec-task-if-else 中的个税计算逻辑封装成一个函数。
任务要求: 从键盘获取用户输入的基本工资,然后调用一个函数来计算税后工资并打印输出。税收规则同前:超过3000元的部分扣除5%的税。
##题目一
salary = float(input("请输入基本工资:")) # 从键盘上输入基本工资
if salary <= 3000: # 判断基本工资是否小于等于3000
rate = 0 # 基本工资小于等于3000,不扣税,即扣税率为0%
else:
rate = 0.05 # 基本工资打印300,扣税率为0.05,即5%
## 计算税后工资,基本工资-扣税,扣税额为超过3000部分的乘以扣税率
salary = salary - (salary - 3000) * rate
print("税后工资为:%d" % salary) # 将税后工资打印输出列表 lst-tax-function 尽管在逻辑上与之前的代码相同,并且没有显式地定义一个名为 tax_calculator 的函数,但它引入了 input() 函数。这使得程序具有了交互性,用户可以输入任意工资数值,程序会动态计算结果。这向我们展示了函数(无论是内置的 input() 还是我们自定义的)作为代码功能模块的价值。
1.4.1.3 实践任务二:计算项目净现值 (NPV)
任务背景:在资本预算中,净现值(Net Present Value, NPV)是评估投资项目可行性的重要指标。它将项目未来的现金流按一定的折现率(资本成本)折算成今天的价值。
任务要求: 编写一个名为 PV 的自定义函数,用于计算一系列未来现金流的现值。该函数需要接收折现率 R 和不定数量的未来现金流 NCF 作为参数。
##需要传入的参数,期数以及每期的现金流,单位为元。
def PV(R,*NCF):
pv=0 #初始化,后续要累加
n=1 #间隔为1年
for cf in NCF:
pv+=round(cf/pow((1+R),n),2) #pow()是幂函数
n+=1
return print("现值结果是:{:.2f}元".format(pv))
##调用自定义的现值函数PV()
PV(0.05,-10000,8000,12000)
PV(0.05,-20000,-500,2000,10000,16000,30000)在 列表 lst-pv-function 中,*NCF 的星号 * 是一个重要的语法,它允许函数接收任意数量的位置参数,并将它们打包成一个元组。这使得我们的 PV 函数非常灵活,可以计算任意期数的项目现值。
1.4.2 lambda 函数:简洁的匿名函数
lambda 函数是Python中一种特殊的、匿名的、单行函数。当我们需要一个功能简单、只用一次且不想为其正式命名的函数时,lambda 是一个绝佳的选择。
1.4.2.1 lambda 的特性
- 匿名: 它没有正式的函数名。
- 单行表达式: 函数体只能是一个单独的表达式,该表达式的计算结果就是函数的返回值。
- 简洁: 语法非常紧凑:
lambda arguments: expression。
1.4.2.2 lambda 的用法
lambda 函数虽然小巧,但用法灵活: 1. 赋值给变量: add = lambda x, y: x + y,之后可以像普通函数一样调用 add(1, 2)。 2. 作为返回值: 一个函数可以返回一个 lambda 函数。 3. 作为参数传递: 这是 lambda 最常见的用途,特别是与 map(), filter(), sorted() 等函数结合使用。例如,map(lambda x: x + 1, [1, 2, 3]) 会对列表中的每个元素执行加一操作。
1.4.2.3 实践任务三:计算算数平均收益率
任务要求: 使用lambda函数定义一个计算算术平均值的函数。然后,利用这个新定义的函数,求解给定的一周上证综指涨跌幅数据的算术平均值。
已知数据: | 日期 | 涨跌幅 | |—|—| | 2022-9-9 | 26.468 | | 2022-9-8 | -10.7081 | | 2022-9-7 | 2.8477 | | 2022-9-6 | 43.5348 | | 2022-9-5 | 1.4337 |
提示: 平均值等于n个数字的总和除以n。
(由于用户未提供此任务的Python代码,我们将根据任务描述自行编写一个示例。)
## 上证综指一周的涨跌幅数据
returns = [26.468, -10.7081, 2.8477, 43.5348, 1.4337]
## 使用 lambda 函数定义一个计算平均值的函数
## 它接收一个列表 l,返回列表总和除以列表长度
average = lambda l: sum(l) / len(l)
## 调用 lambda 函数计算平均涨跌幅
avg_return = average(returns)
print(f"上证综指一周的算术平均涨跌幅为: {avg_return:.4f}")在 列表 lst-avg-return-lambda 中,lambda l: sum(l) / len(l) 这行代码以极其简洁的方式定义了一个求平均值的函数,并将其赋给了变量 average。这充分展示了lambda在定义简单、一次性的计算逻辑时的优雅和高效。
1.4.3 Python常用内置函数
Python提供了一系列开箱即用的内置函数,它们是执行常见任务的快捷方式。熟练掌握这些函数将极大提高我们的编程效率。图 fig-builtin-functions-list 展示了Python官方文档中的部分内置函数列表。
本节我们将重点介绍几个在数据分析中极为常用的内置函数。
1.4.3.1 数值运算函数
abs(): 返回一个数的绝对值。对于复数,返回其模。round(number, [ndigits]): 将数字四舍五入到指定的小数位数。max()/min(): 返回可迭代对象(如列表)中的最大/最小值。sum(iterable, start=0): 对序列中的所有项求和。
## abs()
print(f'abs(-12) = {abs(-12)}')
## round()
print(f'round(2.4827, 2) = {round(2.4827, 2)}')
print(f'round(2.48) = {round(2.48)}')
## max() 和 min()
data = [12.4, 2, 5, 8]
print(f'max of {data} is {max(data)}')
print(f'min of {data} is {min(data)}')
## sum()
list1 =
tup1 = (13, 17, 20)
print(f'sum of {list1} is {sum(list1)}')
print(f'sum of {list1} with start=1 is {sum(list1, 1)}')1.4.3.2 排序函数: sorted() vs list.sort()
Python提供了两种排序方式,它们的区别对于初学者来说非常重要:
sorted(iterable, key=None, reverse=False)(内置函数):- 返回一个新的、排好序的列表,不改变原始对象。
- 可以对任何可迭代对象(列表、元组、字典等)进行排序。
- 默认升序 (
reverse=False)。
list.sort(key=None, reverse=False)(列表方法):- 原地操作,直接修改原始列表,没有返回值 (返回
None)。 - 只能被列表对象调用。
- 原地操作,直接修改原始列表,没有返回值 (返回
list1 =
## 使用 sorted()
sorted_list = sorted(list1)
print(f'使用 sorted() 后的新列表: {sorted_list}')
print(f'原始 list1 保持不变: {list1}')
## 使用 list.sort()
list1.sort()
print(f'使用 list.sort() 后,原始 list1 被修改: {list1}')对字典使用 sorted() 时,默认会对其键(keys)进行排序。
dic = {'a': 1, 'b': 4, 'd': 2}
## 默认对键进行排序
print(f'对字典键排序: {sorted(dic)}')
## 通过key参数指定按值排序 (此处str.lower不适用,仅为语法示例)
## 实际应使用 lambda item: item
print(f'sorted(dic,key=str.lower) 的结果: {sorted(dic,key=str.lower)}')1.4.3.3 实践任务四:券商股数据分析
背景: H公司研究团队需要对A股上市券商进行分析。表 tbl-broker-data 是前期梳理的2018年净利润排名前10的券商在2019年一季度的相关数据。
| 证券名称 | 证券代码 | 2018年净利润(亿元) | 2019年一季度股价涨跌幅 | 2019年3月29日收盘价(元) |
|---|---|---|---|---|
| 中信证券 | 600030 | 98.7643 | 54.7783% | 24.78 |
| 国泰君安 | 601211 | 70.7004 | 31.5274% | 20.15 |
| 海通证券 | 600837 | 57.7071 | 59.4318% | 14.03 |
| 华泰证券 | 600301 | 51.6089 | 38.3333% | 22.41 |
| 广发证券 | 000776 | 46.3205 | 27.5237% | 16.17 |
| 招商证券 | 600999 | 44.4626 | 30.7463% | 17.52 |
| 申万宏源 | 000166 | 42.4781 | 35.6265% | 5.52 |
| 国信证券 | 002736 | 34.3125 | 61.7682% | 13.54 |
| 中信建投 | 601066 | 31.0343 | 193.341% | 25.55 |
| 中国银河 | 601311 | 29.3174 | 73.4604% | 11.83 |
任务要求: 1. 创建券商名称列表,计算其元素个数,并将其转换为一个从1开始的带索引的列表。 2. 创建2018年净利润列表,计算总和与平均数。 3. 创建2019年一季度股价涨跌幅列表,找出最大和最小涨幅。 4. 创建收盘价列表,并将其由低到高排序。
stock = ["中信证券","国泰君安","海通证券","华泰证券","广发证券","招商证券","申万宏源","国信证券","中信建设","中国银河"]
profit = [98.7643,70.7004,57.7071,51.6089,46.3205,44.4626,42.4781,34.3125,31.0343,29.3174]
return_Q1 = [0.547783,0.315274,0.594318,0.383333,0.275237,0.307463,0.356265,0.617682,1.93341,0.734604]
price = [24.78,20.15,14.03,22.41,16.17,17.52,5.52,13.54,25.55,11.83]
print(len(stock)) #计算列表中元素的个数并输出
print(list(enumerate(stock,start=1))) #创建带有索引并且以列表方式输出
profit_total =sum(profit) #计算10家证券公司的净利润总和
profit_average =profit_total/len(stock) #计算每家证券公司平均净利润
print("2018年净利润排名前10位的证券公司净利润总和(亿元)",profit_total)
print("2018年净利润排名前10位的证券公司净利润平均数(亿元)",round(profit_average,4))
return_max =max(return_Q1) #找出最大涨幅
return_min =min(return_Q1) #找出最小涨幅
print("2019年1季度股价的最大涨幅",return_max)
print("2019年1季度股价的最小涨幅",return_min)
price_sorted =sorted(price) #将股价由小到大排序
print(price_sorted)这个综合任务 列表 lst-broker-analysis 完美地展示了 len(), enumerate(), sum(), max(), min(), sorted() 和 round() 等多个内置函数如何协同工作,快速地从原始数据列表中提取出有价值的商业洞察。
1.5 模块化编程:以 math 模块为例
当我们的分析任务变得更加复杂,特别是涉及到科学计算和数学运算时,Python的内置函数可能就不够用了。为了解决这个问题,Python采用了“模块化”的设计思想。
一个模块(Module)就是一个包含了Python定义和语句的文件(通常是.py文件)。我们可以通过import语句将其他模块中的函数、类和变量引入到我们当前的代码中来使用。这就像是为我们的工具箱添加新的专业工具。
math模块是Python标准库中非常重要的一个,它提供了大量用于浮点数运算的数学函数和常数。
1.5.1 导入模块
导入模块主要有两种方式:
import math: 导入整个math模块。在使用时,需要通过模块名.函数名的方式调用,例如math.pow(2, 15)。from math import *: 导入math模块中所有的公开成员(函数、变量等)到当前的命名空间。之后可以直接使用函数名,例如pow(2, 15)。
import math
print(math.pow(2,15))
from math import *
print(pow(2,15))from module import * 的使用建议
虽然 from math import * 看起来更方便,但在大型项目中,我们通常不推荐这种用法。因为它可能导致命名冲突——如果你自己也定义了一个名为pow的函数,它就会覆盖掉从math模块导入的pow函数,从而引发难以察觉的错误。
更推荐的做法是 import math,或者只导入需要的特定函数,如 from math import pow, sqrt。
1.5.2 math 模块常用功能
math模块包含了丰富的数学工具,我们可以通过dir(math)函数来查看其包含的所有内容。
1.5.2.1 数学常数
math.pi: 圆周率 \(\pi\) (3.14159…)math.e: 自然常数 \(e\) (2.71828…)
1.5.2.2 数值处理函数
- 取整:
math.ceil(x): 向上取整,返回大于或等于x的最小整数。math.floor(x): 向下取整,返回小于或等于x的最大整数。math.trunc(x): 截断取整,直接去掉小数部分。
- 绝对值:
math.fabs(x): 返回浮点数的绝对值,功能与内置的abs()类似。
- 阶乘:
math.factorial(x): 计算x的阶乘 (x!)。
- 平方根:
math.sqrt(x): 计算x的平方根。
1.5.2.3 三角函数与对数函数
- 三角函数:
math.cos(x),math.sin(x)等,注意这里的x是以弧度为单位。 - 对数运算:
math.log(x, base): 计算以base为底的x的对数。如果省略base,则计算自然对数 \(\ln(x)\)。math.log10(x): 计算以10为底的对数。math.log2(x): 计算以2为底的对数。
下面是一些常用函数的代码示例:
import math
## 取整函数
x1 = 5.7
print(f'ceil(5.7) = {math.ceil(x1)}')
print(f'trunc(5.7) = {math.trunc(x1)}')
print(f'floor(5.7) = {math.floor(x1)}')
## 三角函数 (pi/3 弧度等于 60度)
x2 = math.pi/3
print(f'cos(pi/3) = {math.cos(x2)}')
print(f'sin(pi/3) = {math.sin(x2)}')
## 绝对值
x3 = -8.8
print(f'fabs(-8.8) = {math.fabs(x3)}')
## 阶乘
x5 = 5
print(f'factorial(5) = {math.factorial(x5)}')
## 对数运算
x, y = 8, 4
print(f'log(8, 4) = {math.log(x, y)}') # 以4为底8的对数
print(f'ln(e) = {math.log(math.e)}') # 自然对数
## 平方根
print(f'sqrt(16) = {math.sqrt(16)}')1.5.2.4 实践任务:计算最优套期保值数量
背景: 在金融衍生品中,套期保值是用来规避价格风险的一种常见策略。最优套期保值数量(Optimal Hedge Ratio)决定了需要购买多少份期货合约来对冲现货资产的风险。其计算公式通常为: \[ N = h \times \frac{Q_A}{Q_F} \] 其中,\(N\) 是所需期货合约的数量,\(h\) 是最优套保比率,\(Q_A\) 是被套期保值的现货资产总价值,\(Q_F\) 是一张期货合约的价值(规模)。
任务要求: 1. 自定义一个函数,用于计算期货的最优套期保值数量。 2. 由于期货合约不能以小数形式交易,计算出的结果必须是整数。请利用math模块中的取整函数来实现。
(由于用户未提供此任务的Python代码,我们将根据任务描述自行编写一个示例。)
import math
def calculate_optimal_hedge_contracts(h, Q_A, Q_F):
"""
计算最优套期保值所需的期货合约数量
h: 最优套保比率
Q_A: 被套期保值资产的金额
Q_F: 1张期货的规模
"""
if Q_F == 0:
return "期货规模不能为0"
# 计算理论上的合约数量
n_float = h * (Q_A / Q_F)
# 在实际操作中,通常对结果进行四舍五入取整,但本题要求使用取整函数
# 我们这里使用向下取整 floor 作为示例
n_integer = math.floor(n_float)
return n_integer
## 案例:
## 假设某公司持有价值1,000,000元的大豆现货 (Q_A)
## 市场波动计算得出最优套保比率 h = 0.85
## 每张大豆期货合约代表10吨,市价为3,000元/吨,则一张合约价值 Q_F = 30,000元
h_ratio = 0.85
asset_value = 1000000
future_scale = 30000
num_contracts = calculate_optimal_hedge_contracts(h_ratio, asset_value, future_scale)
print(f"为对冲 {asset_value} 元的现货资产,应购买 {num_contracts} 张期货合约。")在 列表 lst-optimal-hedge 中,我们定义了一个业务逻辑清晰的函数。关键的一步是 math.floor(n_float),它确保了我们计算出的合约数量是一个可以实际交易的整数,体现了数学工具在解决实际金融问题中的应用。根据不同的风险偏好,这里也可以选用 math.ceil()(向上取整)或 round()(四舍五入)。
1.6 面向对象编程 (OOP)
当我们处理的商业问题越来越复杂时,仅仅使用函数和基本数据结构可能会让代码变得混乱和难以维护。面向对象编程(Object-Oriented Programming, OOP)提供了一种更高级的组织代码的方式,它将数据和操作这些方法封装在一起,形成一个独立的对象(Object)。
对于商学院的同学来说,可以这样理解: - 对象 (Object): 真实世界中的任何事物,比如一个“客户”、一张“订单”、一支“股票”。 - 类 (Class): 对象的蓝图或模板。例如,“客户”这个类定义了所有客户都应该具有的属性(如姓名、ID、联系方式)和可以执行的操作(如下单、查询历史记录)。 - 实例化: 根据“客户”这张蓝图,创建一个具体的客户“张三”,这个过程就叫做实例化。张三就是一个客户类的实例 (Instance)。
在Python中,万物皆对象。这种编程范式让我们的代码结构更清晰,更贴近真实世界的商业逻辑。
1.6.1 类的创建与实例化
最简单的类定义如下:
class ClassName:
<statement-1>
.
.
.
<statement-N>1.6.1.1 __init__ 方法:对象的初始化
当我们创建一个类的实例时(例如,创建一个具体的学生对象),我们通常希望立刻为这个对象设定一些初始属性(如学生的姓名和分数)。__init__ 方法就是这个目的,它是一个特殊的“构造函数”,在对象创建时会被自动调用。
__init__ 方法的第一个参数必须是 self,它代表了被创建的实例本身。通过 self.属性名 = 值 的方式,我们就可以为实例绑定属性。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
语法注意
__init__ 的左右两边是两个下划线 _。
1.6.1.2 数据封装:在类中定义方法
面向对象的核心思想之一是“封装”,即将数据(属性)和操作数据的方法(函数)捆绑在一起。在类中定义的函数,我们称之为方法 (Method)。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
# 数据的方法
def print_score(self):
print('%s:%s' % (self.name, self.score))1.6.2 访问限制:私有变量
有时候,我们不希望类的某些内部属性被外部直接访问或修改,以保证数据的安全和封装的完整性。在Python中,如果一个属性名以两个下划线 __ 开头,它就变成了一个私有变量 (private variable)。私有变量只能在类的内部被访问,外部代码无法直接调用。
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
# 数据的方法
def print_score(self):
print('%s:%s' % (self.__name, self.__score))
def get_grade(self):
if self.__score >= 90:
return 'A'
elif self.__score >= 60:
return 'B'
else:
return 'C'
## 尝试从外部访问私有变量会导致错误
bart = Student('Bart Simpson', 59)
## print(bart.__name) # 这行代码会报错 AttributeError为了让外部能够安全地访问或修改私有变量,我们可以定义公共的 get 和 set 方法,例如 get_name() 或 set_score()。这允许我们在修改前进行数据校验,增强了代码的健壮性。
1.6.3 继承与多态
1.6.3.1 继承
继承是OOP的另一大支柱。它允许我们创建一个新类(子类),这个子类可以自动获得另一个已存在类(父类)的所有属性和方法。这极大地促进了代码的重用。
例如,我们可以定义一个通用的 Animal 类,它有 run() 方法。然后,Dog 和 Cat 类可以继承自 Animal 类,它们将自动拥有 run() 方法,无需重复编写。
class Animal(object):
def run(self):
print('动物正在跑......')
class Dog(Animal):
pass
class Cat(Animal):
pass
## Dog 和 Cat 的实例自动拥有了 run 方法
dog = Dog()
dog.run()
cat = Cat()
cat.run()1.6.3.2 多态
多态意味着“多种形态”。当子类和父类有相同的方法名时,如果我们调用这个方法,程序会执行子类的方法,而不是父类的。这称为方法的覆盖 (Override)。
多态的好处在于,我们可以编写一个接收父类类型参数的函数,但实际可以传入任何子类的实例,而函数无需任何修改就能正常工作。
class Animal(object):
def run(self):
print('动物正在跑......')
class Dog(Animal):
def run(self):
print('小狗正在跑......')
def eat(self):
print('小狗在吃饭......')
def run_twice(animal):
animal.run()
animal.run()
## 传入 Animal 实例
run_twice(Animal())
## 传入 Dog 实例,调用的是 Dog 的 run 方法
run_twice(Dog())如 列表 lst-polymorphism-example 所示,run_twice 函数的设计非常通用,它不关心传入的是 Animal 还是 Dog,只要对象有 run 方法即可。这就是多态的威力,它让我们的代码更具扩展性和灵活性。
1.6.4 实践任务
1.6.4.1 任务一:定义Person类和Stock类
任务要求: 1. 定义一个 Person 类。创建两个实例 mayun 和 wangjianlin,并分别为它们添加 company 属性,值分别为 “阿里巴巴” 和 “万达集团”。 2. 定义一个 Stock 类,使用 __init__ 方法在创建实例时完成代码(code)、市值(value)和除息日(breath_removal)三个属性的赋值。类中还需定义一个 rise 方法。创建 CNPC 实例并调用其方法和属性。
##题目一
##(1) Person类
class Person(object):
pass
## mayun对象
mayan = Person()
mayan.company = "阿里巴巴"
## wangjianlin对象
wangjianlin = Person()
mayan.company = "万达集团"
##(2) 股票类
class Stock(object):
def __init__(self,code, value, breath_removal):
self.code = code
self.value = value
self.breath_removal = breath_removal
def rise(self):
print("股票开始涨了")
CNPC = Stock(601857, "1.28万亿", "2022-9-20")
print(CNPC.code, CNPC.value, CNPC.breath_removal)
CNPC.rise()1.6.4.2 任务二:实现继承与super()函数
任务要求: 建立三个类:jumin(居民)、chengren(成人)、guanyuan(官员)。 - jumin 类包含身份证号、姓名、出生日期。 - chengren 类继承自 jumin,并额外包含学历、职业两项数据。 - guanyuan 类继承自 chengren,并额外包含党派、职务两项数据。 要求每个类的字段都以私有属性的方式存储,并提供公共方法进行数据访问。请使用 super() 函数来调用父类的 __init__ 方法。
##题目二
class jumin():
def __init__(self,idcard,name,birthday):
self.__idcard = idcard
self.__name = name
self.__birthday = birthday
def get_name(self):
return self.__name
def set_name(self,name):
self.__name = name
class chengren(jumin):
def __init__(self,idcard,name,birthday,xueli,job):
super().__init__(idcard,name,birthday)
self.__xueli = xueli
self.__job = job
class guanyuan(chengren):
def __init__(self, idcard, name, birthday, xueli, job,dangpai,zhiwu):
super().__init__(idcard,name,birthday,xueli,job)
self.__dangpai = dangpai
self.__zhiwu = zhiwu
gy = guanyuan("123","lhy","1998-1-23","博士","python教授","民主","科员")
name = gy.get_name()
print(name)在 列表 lst-task-oop-2-solution 中,super().__init__(...) 是关键。它允许子类在执行自己的初始化逻辑之前,先调用父类的初始化方法,从而继承父类的属性,避免了代码的重复。这在构建复杂继承体系时是标准且高效的做法。
1.7 文件操作
在商业数据分析中,数据很少是直接写在代码里的。更多时候,我们需要从外部文件中读取数据(如CSV文件、Excel文件、文本文件),经过处理和分析后,再将结果写入新的文件。因此,掌握文件操作是至关重要的一步。
Python提供了统一的操作接口来处理文本文件和二进制文件。基本流程分为三步:“打开 - 操作 - 关闭”。
1.7.1 文件的打开与关闭
1.7.1.1 open() 函数
我们使用Python的内置函数 open() 来打开一个文件,它会返回一个文件对象。其基本语法为: f = open(file_path, mode, encoding="utf-8") - file_path: 文件名(或包含路径的文件名)的字符串。 - mode: 一个字符串,表示文件的打开模式。 - encoding: 文件的编码格式,对于处理中文文本,通常指定为 "utf-8"。
1.7.1.2 文件模式 (mode)
打开文件的模式决定了我们能对文件进行哪些操作。表 tbl-file-modes 列出了一些常用模式。
| 模式 | 描述 |
|---|---|
r |
读模式 (Read): 只能读取文件。如果文件不存在会报错。这是默认模式。 |
w |
写模式 (Write): 只能写入文件。如果文件存在,会清空原有内容;如果文件不存在,会创建新文件。 |
a |
追加模式 (Append): 只能写入文件。在文件末尾追加内容,不会清空原有内容。如果文件不存在,会创建新文件。 |
r+ |
读写模式。 |
rb |
以二进制格式读取文件。 |
wb |
以二进制格式写入文件。 |
1.7.1.3 close() 方法
文件操作完成后,必须调用文件对象的 close() 方法来关闭文件。这会释放操作系统资源,并确保所有写入操作都已保存到磁盘。忘记关闭文件,尤其是在写模式下,可能会导致数据丢失。
## 打开(或创建)一个名为 output.txt 的文件用于写入
outfile = open('output.txt', 'w')
## ... 这里可以进行写入操作 ...
## 操作完成后,关闭文件
outfile.close()1.7.2 读写文本文件
1.7.2.1 写入文件
write()方法: 将指定的字符串写入文件。需要注意的是,write()不会自动添加换行符,需要我们手动添加\n。print()函数:print函数也可以通过file参数将内容输出到文件,并且它会自动在末尾添加换行符。
outfile = open('output.txt', 'w')
## 使用 write 方法,需要手动加换行符
outfile.write('Hello, World!\n')
## 使用 print 函数,自动换行
print('hello!', file=outfile)
outfile.close()1.7.2.2 读取文件
read(size): 读取指定大小(字节)的内容。如果省略size,则读取整个文件内容。readline(): 读取文件中的一行,包括行尾的换行符。
1.7.2.3 实践任务一:处理股价数据
任务描述: 给定某只股票一周的5个股价数据,请完成以下操作: 1. 将这些股价数据写入一个新的文本文件 input.txt 中,要求每个数值占一行。 2. 从 input.txt 文件中读取数据。 3. 计算这5天的平均股价。 4. 将平均股价追加到 input.txt 文件的末尾。 5. 输出整个文件的最终内容。
已知股价: 10.41, 9.88, 10.24, 10.68, 11.00
(由于用户未提供此任务的Python代码,我们将根据任务描述自行编写一个示例。)
## 已知股价数据
prices = [10.41, 9.88, 10.24, 10.68, 11.00]
filename = "input.txt"
## 1. 将数据写入文件
with open(filename, 'w') as f:
for price in prices:
f.write(str(price) + '\n')
print(f"成功将数据写入 {filename}")
## 2. 从文件中读取数据并计算平均值
read_prices = []
with open(filename, 'r') as f:
for line in f:
read_prices.append(float(line.strip()))
average_price = sum(read_prices) / len(read_prices)
print(f"计算出的5日平均股价为: {average_price:.2f}")
## 3. 将平均值追加到文件末尾
with open(filename, 'a') as f:
f.write(f"Average Price: {average_price:.2f}\n")
print("已将平均股价追加到文件。")
## 4. 输出最终文件内容
print("\n--- 文件最终内容 ---")
with open(filename, 'r') as f:
print(f.read())在 列表 lst-stock-price-io 中,我们使用了一种更安全、更简洁的文件操作方式:with open(...) as f:。这种语法的好处是,with 语句块执行完毕后,Python会自动替我们关闭文件,即使在操作过程中发生错误也不例外。这是处理文件的推荐方式。
1.7.3 使用Pandas进行文件读写
对于商学院的学生来说,我们处理的数据大多是结构化的表格数据。在这种情况下,使用 Pandas 库来读写文件会比原生的文件操作方便得多。Pandas可以轻松处理CSV、Excel、JSON、SQL数据库等多种格式。
import pandas as pd
txt=['a flat percentage rate of income','a long position','a sales slip','a short position','aboriginal cost']
df_1=pd.DataFrame(txt)
print(df_1)
df_1.to_csv('test.txt', sep='\t', index=False)
data=pd.read_table('test.txt')
print(data)
dict = { "流通中货币(MO)":{"2022.01":"18.5%","2022.02":"5.8%","2022.03":"10%","2022.04":"11.5%","2022.05":"13.5%","2022.06":"13.9%","2022.07":"13.9%","2022.08":"14.3%","2022.09":"13.6%","2022.10":"14.4%","2022.11":"14.1%","2022.12":"15.3%"}}
df=pd.DataFrame(dict)
print(df)
df.to_csv('test.csv')
data=pd.read_csv('test.csv')
print(data)在 列表 lst-pandas-io-demo 中,我们用几行代码就完成了数据框的创建、保存为CSV/TXT文件,以及从文件中重新读取为数据框的整个流程,展示了Pandas在数据I/O方面的强大与便捷。
1.7.4 二进制文件与随机访问
除了人类可读的文本文件,计算机中还有大量二进制文件,如图片、音频、视频和编译后的程序等。二进制文件直接存储字节数据,通常更节省空间且读写更快。
1.7.4.1 读写二进制文件
操作二进制文件与文本文件类似,只需在打开模式后加上 'b',如 'rb' (读二进制) 或 'wb' (写二进制)。
- 读取:
read()方法返回的是一个bytes对象,而不是字符串。 - 写入:
write()方法需要接收一个bytes对象作为参数。
1.7.4.2 随机访问 (seek)
对于普通文件读取,我们都是从头到尾顺序读取。但有时我们需要直接跳转到文件的特定位置进行读写,这就是随机访问。文件对象的 seek() 方法可以实现这个功能,它用于移动文件内部的读写指针。
f.seek(offset, whence) - offset: 偏移的字节数。 - whence: - 0 (默认): 从文件开头计算偏移。 - 1: 从当前位置计算偏移。 - 2: 从文件末尾计算偏移。
## 创建一个示例二进制文件
with open('workfile', 'wb+') as f:
f.write(b'0123456789abcdef')
# 从开头偏移5个字节,即移动到第6个字节
f.seek(5)
print(f'移动到第6个字节后读取1个字节: {f.read(1)}')
# 从文件末尾向前偏移3个字节
f.seek(-3, 2)
print(f'移动到倒数第3个字节后读取1个字节: {f.read(1)}')1.7.4.3 实践任务二:读取GIF图片信息
任务描述: GIF图片文件头部的特定位置存储了关于图片的信息。请编写程序,打开一个GIF图片文件(以二进制模式),将文件指针移动到第10个字节的位置,并读取随后的两个字节并输出。
import os
path='boxplot.png'
binfile=open(path,'rb')
binfile.seek(9) #移动到第10个字节
data=binfile.read(2) #读取
binfile.close()
print(data)
潜在错误提示
1.7.4.3.1 错误分析
在 列表 lst-read-gif-header 代码中,脚本尝试打开一个名为 boxplot.png 的文件。.png 是PNG图片格式的扩展名,而任务描述中提到的是GIF图片。虽然两种都是图片格式,但其内部的二进制结构是完全不同的。使用解析GIF文件格式的逻辑去读取PNG文件的特定字节,得到的结果可能没有实际意义。
这是一个逻辑上的不匹配,尽管代码在语法上是正确的(只要文件存在)。在真实的商业项目中,正确识别和处理文件格式至关重要。
1.7.4.3.2 正确做法
应确保提供的文件路径 path 指向一个真实的 .gif 文件,或者调整代码逻辑以正确解析 .png 文件的格式。
1.7.4.3.3 重要提醒
为通过平台检测,在线练习时仍需按原始错误代码输入。
1.8 错误与异常处理
在编写和运行程序的过程中,遇到错误是不可避免的。比如,我们可能会尝试打开一个不存在的文件,或者用一个数字除以零。当Python程序在执行时遇到无法正常处理的情况,它会抛出一个异常 (Exception)。如果这个异常没有被处理,程序就会立即终止并显示一条错误信息。
为了编写出更加健壮、可靠的商业应用程序,我们需要学会如何捕获 (catch) 并处理 (handle) 这些异常,而不是让程序直接崩溃。Python为此提供了 try...except 语句。
1.8.1 try/except 语句
try/except 语句的基本工作原理是: 1. try 块: 将你认为可能会引发异常的代码放入 try 语句块中。 2. except 块: 如果 try 块中的代码确实引发了异常,Python会立即跳出 try 块,并寻找一个能够匹配该异常类型的 except 块来执行。如果找到了,程序会执行 except 块中的代码,然后继续正常执行下去;如果没有找到匹配的 except 块,程序仍然会终止。 3. else 块 (可选): 如果 try 块中的代码没有引发任何异常,else 块中的代码就会被执行。 4. finally 块 (可选): 无论 try 块中是否发生异常,finally 块中的代码总是会被执行。这通常用于执行清理操作,如关闭文件或数据库连接。
1.8.1.1 基本语法
try:
# 尝试执行的代码
<statements>
except ExceptionType1:
# 如果发生 ExceptionType1 异常,执行这里的代码
<statements>
except (ExceptionType2, ExceptionType3):
# 如果发生 ExceptionType2 或 ExceptionType3 异常,执行这里的代码
<statements>
else:
# 如果没有异常发生,执行这里的代码
<statements>
finally:
# 无论如何都会执行这里的代码
<statements>1.8.1.2 实践案例分析
让我们通过一个组合案例来理解 try/except/else/finally 的完整流程。
##(1)
def Compare(a, b):
try:
if a > b:
raise BaseException('后一天收益{}不能小于前一天收益{}'.format(b,a))
else:
print(b - a)
except BaseException as f :
print(f)
Compare(5,4)
##(2)
try:
num = 1/0
except: #except 语句
print("except 语句")
else: #else 语句
print("else 语句")
finally: #finally 语句
print("finally 语句")在 列表 lst-exception-handling-demo 中: - 第一个例子 使用 raise 关键字主动抛出了一个异常。try 块捕获了这个 BaseException,并执行了 except 块中的 print(f) 语句。这在业务逻辑检查中非常有用,例如检查输入数据是否合规。 - 第二个例子 尝试执行 1/0,这会引发一个 ZeroDivisionError。 - try 块中的代码引发异常。 - 程序跳转到 except 块,打印 “except 语句”。 - else 块被跳过,因为它只在没有异常时执行。 - 最后,finally 块被执行,打印 “finally 语句”。
1.8.1.3 try-finally 的重要应用:资源清理
在文件操作或数据库连接等场景中,确保资源(如文件句柄)总是被正确关闭至关重要。try-finally 结构是实现这一点的经典方式。
## 错误的方式:如果在 writeData 过程中发生异常,close() 将不会被执行
outfile = open(filename, 'w')
writeData(outfile)
outfile.close()
## 正确的方式:使用 try-finally
outfile = open(filename, 'w')
try:
writeData(outfile)
finally:
# 无论 writeData 是否成功,文件都会被关闭
outfile.close()这保证了即使在处理数据时发生意外,我们的程序也不会留下未关闭的文件,避免了资源泄露。当然,更现代和推荐的做法是使用我们之前在 sec-file-io 章节中提到的 with 语句,它在内部就实现了类似 try-finally 的逻辑。
1.8.1.4 实践任务:完善文件操作代码
任务描述: 将下方不完整的代码补充完整,要求在已有代码的基础上,使用 finally 语句块确保文件句柄一定被关闭,并打印提示信息 “正关闭文件”。
已知代码:
try:
# Open a file in write-mode
f = open("myfile.txt", 'w')
f.write("Hello World!")
except IOError as e:
print("An error occurred:", e)(由于用户未提供此任务的Python代码,我们将根据任务描述自行编写一个示例。)
f = None # 在try块外部初始化f,以便finally可以访问
try:
# Open a file in write-mode
f = open("myfile.txt", 'w')
f.write("Hello World!")
except IOError as e:
print("An error occurred:", e)
finally:
if f: # 确保f已经被成功打开
print("正关闭文件")
f.close()列表 lst-file-close-finally 展示了 finally 的典型应用。我们将 f.close() 放在 finally 块中,这样无论写入操作 f.write() 是否成功,关闭文件的代码都将得到执行,保证了程序的健壮性。
1.9 数据库操作入门
在真实的商业环境中,绝大多数数据都存储在数据库中,而非零散的文件里。数据库能够高效、安全、有组织地管理海量数据。结构化查询语言(SQL)是与数据库交互的标准语言。幸运的是,Python通过各种库提供了与主流数据库(如MySQL, PostgreSQL, SQLite等)连接和交互的能力。
本章将以 SQLite 为例,介绍如何使用Python进行基本的数据库操作。SQLite是一个轻量级的、无服务器的数据库,它将整个数据库存储为一个单一的文件,非常适合学习、原型开发和小型应用。
1.9.1 数据库的连接与管理
操作数据库的第一步是建立连接,就像打开一扇通往数据仓库的大门。在Python中,我们使用 sqlite3 这个标准库来与SQLite数据库交互。
import sqlite3
## 1. 连接数据库(如果文件不存在会自动创建)
print("=== 1.正在连接数据库...===")
conn = sqlite3.connect('financial_market.db')
## 2. 创建游标对象 (Cursor)
cursor = conn.cursor()
print("数据库连接成功!")
## ... 在这里执行SQL操作 ...
## 操作完成后,关闭游标和连接
## print("=== 10. 关闭数据库连接 ===")
## cursor.close()
## conn.close()
## print("数据库连接已关闭!")sqlite3.connect(): 这个函数用于建立与数据库文件的连接。如果指定的.db文件不存在,它会自动被创建。conn.cursor(): 连接建立后,我们需要创建一个游标 (Cursor) 对象。你可以把游标想象成在文本编辑器中闪烁的光标,我们通过它来执行SQL命令并获取结果。
操作完成后,与文件操作一样,必须关闭连接以释放资源。顺序是先关闭游标,再关闭连接。
1.9.2 SQL 核心语句
SQL主要包含四种核心操作,通常被称为 CRUD 操作:Create (创建), Read (读取), Update (更新), Delete (删除)。
1.9.2.1 创建表 (CREATE TABLE)
创建表就像在数据仓库里搭建货架,用于规定数据的存储结构。我们需要定义表的名称以及每一列(字段)的名称和数据类型。
import sqlite3
conn = sqlite3.connect('financial_market.db')
cursor = conn.cursor()
## 3. 创建新的金融数据表(股票持仓表)
print("=== 3. 创建股票持仓表 ===")
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_holdings (
stock_id TEXT PRIMARY KEY, -- 股票代码
stock_name TEXT NOT NULL, -- 股票名称
quantity INTEGER NOT NULL, -- 持仓数量
purchase_price REAL NOT NULL, -- 买入价格
purchase_date TEXT NOT NULL, -- 买入日期
market_value REAL -- 当前市值(计算字段)
)
''')
print("股票持仓表创建成功!")
conn.commit() # 提交创建表的事务
conn.close()IF NOT EXISTS: 防止因表已存在而导致的执行错误。- 数据类型:
TEXT(文本),INTEGER(整数),REAL(浮点数)。 - 约束 (Constraints):
PRIMARY KEY: 主键,唯一标识表中的每一行,值不能重复且不能为空。NOT NULL: 非空约束,该列的值不能为空。
conn.commit(): 在对数据库进行任何修改(如创建、插入、更新、删除)之后,需要调用commit()方法来提交事务,使更改永久生效。
1.9.2.2 插入数据 (INSERT INTO)
插入数据就是往货架上摆放货物。
import sqlite3
conn = sqlite3.connect('financial_market.db')
cursor = conn.cursor()
## 4. 插入测试数据
print("=== 4. 插入测试数据 ===")
stocks = [
('000001', '平安银行', 1000, 15.23, '2025-06-10', None),
('601318', '中国平安', 500, 48.56, '2025-06-15', None),
('600519', '贵州茅台', 200, 1789.00, '2025-06-20', None)
]
## 使用INSERT OR IGNORE避免唯一性冲突
cursor.executemany("INSERT OR IGNORE INTO stock_holdings VALUES (?, ?, ?, ?, ?, ?)", stocks)
print("执行了插入操作(重复数据会被忽略)")
conn.commit() # 提交插入数据的事务
conn.close()executemany(): 当需要插入多条数据时,使用executemany()会比多次调用execute()更高效。?: 这是参数占位符,可以防止SQL注入攻击,是安全的编程实践。
1.9.2.3 查询数据 (SELECT)
查询是数据库最常用的操作,是从表中获取信息。
import sqlite3
conn = sqlite3.connect('financial_market.db')
cursor = conn.cursor()
## 5. 查询当前持仓数据
print("=== 5. 查询当前持仓数据 ===")
cursor.execute("SELECT * FROM stock_holdings")
holdings = cursor.fetchall()
## 打印表头
print(f"{'股票代码':<15}{'股票名称':<10}{'持仓数量':<15}{'买入价格':<20}{'买入日期':<16}{'当前市值'}")
## 打印每一行数据
for stock in holdings:
print(f"{stock:<15}{stock:<10}{stock:<15}{stock:<20}{stock:<16}{stock or '未计算'}")
conn.close()SELECT *:*是通配符,表示选择所有列。cursor.fetchall(): 获取查询结果集中的所有行。此外还有fetchone()(获取一行) 和fetchmany(size)(获取指定数量的行)。
1.9.2.4 更新数据 (UPDATE)
更新用于修改表中已有的数据。
import sqlite3
conn = sqlite3.connect('financial_market.db')
cursor = conn.cursor()
## 6. 修改持仓数据(增加某只股票的持有量)
print("=== 6. 修改持仓数据 ===")
stock_id = '000001' # 要修改的股票代码
additional_quantity = 200 # 增加的持仓数量
## 查询当前持仓
cursor.execute("SELECT quantity FROM stock_holdings WHERE stock_id = ?", (stock_id,))
current_quantity = cursor.fetchone()
## 更新持仓数量
new_quantity = current_quantity + additional_quantity
cursor.execute("UPDATE stock_holdings SET quantity = ? WHERE stock_id = ?", (new_quantity, stock_id))
print(f"股票 {stock_id} 持仓从 {current_quantity} 股增加到 {new_quantity} 股!")
conn.commit() # 提交更新事务
conn.close()WHERE:WHERE子句至关重要,它用于指定更新或删除操作的目标行。如果没有WHERE子句,UPDATE或DELETE将会作用于表中的所有行!
1.9.2.5 删除数据 (DELETE)
删除用于从表中移除数据。
-- 删除客户CUST002的所有交易记录
DELETE FROM financial_transactions WHERE customer_id = 'CUST002';同样,WHERE 子句在这里也是必不可少的,以确保只删除特定的数据。
1.9.3 综合实践任务:股票持仓管理系统
背景: 你是一家金融投资公司的初级数据分析师,公司新开展股票投资业务,需要你使用Python和SQLite搭建一个简易的股票持仓管理系统。
要求: 请整合本章所学知识,编写一个完整的Python脚本,实现以下全部流程: 1. 连接到 financial_market.db 数据库。 2. 查询并显示数据库中已有的表及其结构。 3. 如果 stock_holdings 表不存在,则创建该表。 4. 向表中插入三只股票的初始持仓数据。 5. 查询并以格式化的方式打印所有持仓数据。 6. 将“平安银行”(000001)的持仓量增加200股。 7. 再次查询并打印更新后的持仓数据。 8. 金融分析: 假设当前市场价格分别为平安银行15.80元、中国平安49.25元、贵州茅台1820.50元,请更新每只股票的市值(market_value)字段,并计算和打印当前的总持仓市值。 9. 清理数据:为下次运行做准备,删除stock_holdings表中的所有数据(但保留表结构)。 10. 关闭数据库连接。
(下面的代码块是多个操作的整合,作为对本章知识的综合应用。)
import sqlite3
## 1. 连接数据库
print("正在连接数据库...")
conn = sqlite3.connect('financial_market.db')
cursor = conn.cursor()
print("数据库连接成功!")
## 2. 查询已有数据表
print("=== 2. 查询已有数据表 ===")
cursor.execute("SELECT name FROM sqlite_master WHERE type='table' AND name='stock_holdings'")
tables = cursor.fetchall()
if tables:
print("数据库中存在 stock_holdings 表。")
else:
print("数据库中没有 stock_holdings 表。")
## 3. 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_holdings (
stock_id TEXT PRIMARY KEY, stock_name TEXT NOT NULL, quantity INTEGER NOT NULL,
purchase_price REAL NOT NULL, purchase_date TEXT NOT NULL, market_value REAL
)''')
conn.commit()
## 4. 插入数据
stocks = [
('000001', '平安银行', 1000, 15.23, '2025-06-10', None),
('601318', '中国平安', 500, 48.56, '2025-06-15', None),
('600519', '贵州茅台', 200, 1789.00, '2025-06-20', None)
]
cursor.executemany("INSERT OR IGNORE INTO stock_holdings VALUES (?, ?, ?, ?, ?, ?)", stocks)
conn.commit()
print("=== 4. 数据插入完成 ===")
## 5. 查询数据
print("=== 5. 初始持仓数据 ===")
cursor.execute("SELECT * FROM stock_holdings")
holdings = cursor.fetchall()
for stock in holdings: print(stock)
## 6. 更新数据
print("=== 6. 修改持仓数据 ===")
stock_id = '000001'
additional_quantity = 200
cursor.execute("SELECT quantity FROM stock_holdings WHERE stock_id = ?", (stock_id,))
current_quantity = cursor.fetchone()
new_quantity = current_quantity + additional_quantity
cursor.execute("UPDATE stock_holdings SET quantity = ? WHERE stock_id = ?", (new_quantity, stock_id))
conn.commit()
print(f"股票 {stock_id} 持仓已更新至 {new_quantity} 股!")
## 7. 再次查询
print("=== 7. 更新后的持仓数据 ===")
cursor.execute("SELECT * FROM stock_holdings")
holdings = cursor.fetchall()
for stock in holdings: print(stock)
## 8. 金融分析
print("=== 8. 金融分析:计算总持仓价值 ===")
current_prices = {'000001': 15.80, '601318': 49.25, '600519': 1820.50}
for stock_id, price in current_prices.items():
cursor.execute("UPDATE stock_holdings SET market_value = quantity * ? WHERE stock_id = ?", (price, stock_id))
conn.commit()
cursor.execute("SELECT SUM(market_value) FROM stock_holdings")
total_value = cursor.fetchone()
print(f"当前持仓总市值: ¥{total_value:.2f}")
## 9. 数据清理
print("=== 9. 数据清理 ===")
cursor.execute("DELETE FROM stock_holdings") #【要求三】
conn.commit()
print("已清空股票持仓表数据!")
## 10. 关闭连接
print("=== 10. 关闭数据库连接 ===")
cursor.close()
conn.close()
print("数据库连接已关闭!")
潜在错误提示
1.9.3.0.1 错误分析
在 SQL基本操作.ipynb 原始脚本的第8步(金融分析)中,打印更新后持仓明细的代码存在一个格式化字符串的错误。 原始代码为: print(f"{stock[0]:<10}{stock[1]:<10}{stock[2]:<12}{stock[3]:<12}{stock[4]:<12}{stock[5]:<12.2f}") stock[5] 是一个浮点数,但是它被放在了一个固定宽度的字符串格式化中,并且试图同时应用浮点数格式化 <12.2f。这会导致 ValueError: Invalid format specifier。正确的做法是只应用浮点数格式化,或者先格式化为字符串再进行对齐。
1.9.3.0.2 正确写法
一种正确的写法是分开处理对齐和浮点数格式化: market_val_str = f"{stock[5]:.2f}" print(f"{stock[0]:<10}{stock[1]:<10}{stock[2]:<12}{stock[3]:<12}{stock[4]:<12}{market_val_str:<12}")
1.9.3.0.3 重要提醒
为通过平台检测,在线练习时仍需按原始错误代码输入。