import numpy as np # 导入numpy库,用于数值计算(如对数转换、多项式拟合等)
import pandas as pd # 导入pandas库,用于数据框操作(读取、筛选、合并等)
import matplotlib.pyplot as plt # 导入matplotlib绑图库,用于创建图形和子图
import seaborn as sns # 导入seaborn库,用于绘制统计类型的高级图表(如箱线图)
import os # 导入os模块,用于检测操作系统类型以自适应数据路径
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 设置中文字体优先级列表,确保图表中文正常显示
plt.rcParams['axes.unicode_minus'] = False # 解决坐标轴负号显示为方块的兼容性问题
# 根据当前操作系统自动选择本地数据根目录路径(Windows用C盘,Linux用挂载盘)
DATA_ROOT = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
# 构造上市公司财务报表数据文件的完整路径
FINANCIAL_STMT_PATH = os.path.join(DATA_ROOT, 'stock/financial_statement.h5') # 构建数据文件的完整路径
# 构造上市公司基本信息数据文件的完整路径
STOCK_BASIC_PATH = os.path.join(DATA_ROOT, 'stock/stock_basic_data.h5') # 构建数据文件的完整路径2 统计学习导论 (Introduction)
2.1 统计学习概述 (An Overview of Statistical Learning)
统计学习(Statistical Learning)是指一组广泛用于理解和分析数据的工具集与基础框架。站在商业与经济分析的视角,这些工具致力于从海量的非结构化或结构化数据中挖掘出隐藏的模式,从而支持更高质量的商业决策。这套工具通常分为两大类:监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。
从形式化的微观经济或计量经济学角度看,假设我们观测到一个我们极度关心的响应变量 (Response Variable,或因变量) \(Y\)(例如公司的季报净利润、某只股票的次日收益率,或者是某个客户是否会违约),以及 \(p\) 个可能影响它的特征属性 (Features,或自变量) \(X_1, X_2, \dots, X_p\)(例如宏观经济指标、公司财务比率、客户的历史交易记录等)。我们假设 \(Y\) 和输入特征向量 \(X = (X_1, X_2, \dots, X_p)\) 之间存在某种关系,这种关系可以被抽象地表示为:
\[ Y = f(X) + \epsilon \tag{2.1}\]
在这个方程中,\(f\) 是一个未知的固定函数,它代表了特征 \(X\) 传达给目标 \(Y\) 的系统性信息结构;\(\epsilon\) 则是一个随机误差项 (Error Term),它捕捉了所有未能被 \(X\) 完全解释的噪音或潜在遗漏变量,且与 \(X\) 独立、均值为零。在传统的计量经济学中,我们往往假设 \(f(X)\) 具有高度严格的线性结构;但在现代统计学习中,\(f\) 可以是高度复杂的非线性映射(例如深度神经网络或随机森林)。在 式 2.1 中,\(f\) 正是我们试图去“学习”和逼近的核心对象。统计学习本质上是一套用于从经验数据中估计 \(f\) 的算法、原则和理论。
在监督学习框架下,算法会在具有确定性“答案”(即存在 \(Y\))的历史数据中进行学习,从而构建一个预测或推断模型。这类模型在当今的金融信贷风控系统、高频量化交易、乃至电子商务的个性化推荐中扮演着基础设施的角色。而在无监督统计学习中,我们手中只有输入变量而没有目标标签 \(Y\);尽管缺少了明确的“指导”,我们依然能够利用这些前沿算法去挖掘数据内部的拓扑结构——比如在完全未知客户类别的情况下进行商业市场分群,或者在数千支股票中发现潜在的隐藏板块联动关系。
为了直观展示统计学习的工作流程,我们可以参考 图 2.1。
为了说明统计学习的一些应用,我们简要讨论本书中考虑的三个真实世界数据集。
统计学习在中国金融领域的典型应用
统计学习方法已经深度渗透到中国金融行业的各个运营环节。以下是几个商学院学生需要重点关注的前沿应用领域:
- 智能信贷风控:蚂蚁集团、京东金融等互联网金融平台使用梯度提升树(XGBoost)和深度学习网络,整合数万维的用户行为特征(如消费频率、还款习惯、社交网络特征等),实时评估贷款申请人的违约概率。相比传统的逻辑回归评分卡模型,这些方法将不良贷款率降低了约30%-50%。
- 量化投资策略:国内头部量化私募(如幻方量化、明汯投资)广泛使用机器学习方法从A股海量的价量数据中挖掘交易信号。Lasso回归和弹性网络用于高维因子筛选,随机森林和XGBoost用于非线性收益率预测,LSTM网络用于捕捉时间序列中的动态模式。
- 保险精算与定价:中国人寿、平安保险等公司使用生存分析模型(如Cox比例风险模型)来估计保单持有人的风险事件发生概率,并据此进行差异化定价。
- 供应链优化:京东物流利用时间序列预测方法(如Prophet模型和ARIMA-GARCH混合模型)来预测区域商品需求,优化仓储布局和配送路线规划。
这些应用的核心挑战始终是相同的——如何在商业噪音中滤出真正带来价值的确定性规律(挖掘 \(f\)),并坚决防范由随机噪音(\(\epsilon\))带来的灾难性误判。
2.2 上市公司财务数据 (Corporate Financial Data)
在这个应用中,我们研究影响中国长三角地区上市公司净利润 (Net Profit) 的多个因素。具体而言,我们希望了解公司的营业收入 (Revenue)、总资产 (Total Assets) 以及所处行业与其盈利能力之间的关联。这个数据集通过 RQSDK 获取, 并经过本地清洗和整理。
考虑 图 2.2 的左侧面板, 它显示了长三角地区制造业上市公司净利润与营业收入的关系。有强烈的证据表明, 净利润随着营业收入的增加而增加, 呈现出正相关关系。红色曲线提供了给定收入水平下平均净利润的估计值。然而, 数据点的分散程度也表明, 仅凭收入常常不足以精确预测净利润, 因为利润率在不同公司间差异巨大。
我们还有每家公司的总资产规模和行业分类信息。图 2.2 的中图和右图显示了净利润与总资产、子行业的关系。显然, 资产规模较大的公司通常拥有更高的净利润上限, 但也伴随着更大的波动。不同的子行业(如汽车制造 vs 医药制造)在相同的资产规模下表现出不同的盈利特征。
通过结合营业收入、总资产和行业信息, 我们可以获得对公司净利润的最准确预测。这个回归问题是量化基本面分析的核心任务之一。
为了将理论付诸实践,我们将分步演示如何从本地存储的数据文件中读取公司的财务报表和基本信息,完成金融数据清洗与特征工程的全流程,最终以图形化方式检验净利润与营收、资产之间的相关关系。
第一步:导入库与配置环境
首先,我们需要导入数据分析和可视化所需的Python库,并进行中文字体和数据路径的基本配置。numpy 负责数值运算,pandas 负责数据框操作,matplotlib 和 seaborn 负责图形绘制,os 负责操作系统兼容的路径处理。
上面这段代码完成了三项基本配置:(1) 加载了后续分析所需的全部Python库;(2) 将 matplotlib 的默认字体设置为”思源宋体”,这是一款开源的中文字体,确保图表中的中文标签能够正确渲染;(3) 通过 os.name 的判断逻辑实现了跨平台兼容——无论你是在Windows还是Linux环境下运行,代码都能自动定位到正确的数据目录。
第二步:加载数据并筛选长三角地区上市公司
下面我们从本地的 h5 (HDF5) 文件中读取财务报表和公司基本信息两张表,将它们按照股票代码进行合并,然后筛选出我们感兴趣的长三角地区(上海、江苏、浙江、安徽)的公司。h5 (HDF5) 是一种高效的二进制存储格式,非常适合处理大型结构化金融数据,读取速度远快于传统的CSV文件。
financial_statements_data = pd.read_hdf(FINANCIAL_STMT_PATH) # 从本地h5文件一次性读取全部A股上市公司的财务报表数据
stock_basic_info = pd.read_hdf(STOCK_BASIC_PATH) # 从本地h5文件读取所有上市公司的基本信息(名称、行业、地区等)
# 筛选出2023年第四季度的年度报告数据(quarter列格式为'YYYYqN'字符串,如'2023q4'代表年报)
financial_data_2023 = financial_statements_data[ # 从全量财务数据中筛选2023年第四季度的记录
financial_statements_data['quarter'] == '2023q4' # 仅匹配年报季度标识
].copy() # 使用.copy()创建独立副本,避免后续操作触发pandas的SettingWithCopyWarning
join_key = 'order_book_id' # 定义两张表的合并键,order_book_id是每只股票的唯一标识符(如'600104.XSHG')
# 将财务数据与基本信息按照股票代码进行内连接合并,从而获取每家公司的名称、地区和行业分类
merged_company_data = pd.merge( # 合并数据表
financial_data_2023, # 左表:2023年年报财务数据
stock_basic_info[[join_key, 'province', 'industry_name']], # 右表:仅选取需要的3列(province=省份, industry_name=行业名称)
on=join_key, # 按照股票代码进行匹配
how='inner' # 内连接:仅保留两张表中都存在的公司
) # 执行内连接合并操作
yrd_provinces_list = ['上海市', '江苏省', '浙江省', '安徽省'] # 定义长三角四省市的名称列表(province列使用全称)
# 从合并后的数据中筛选出注册地位于长三角地区的上市公司
yrd_companies_data = merged_company_data[ # 对合并后数据进行地区筛选
merged_company_data['province'].isin(yrd_provinces_list) # 保留省份名称在长三角列表中的行
].copy() # 使用.copy()创建独立副本,避免SettingWithCopyWarning这段代码的核心操作是表的合并(pd.merge)。在金融数据分析中,公司的财务指标和行业分类信息通常存储在不同的数据表中。通过 order_book_id(股票代码)作为唯一键将它们连接起来,我们就能将”某公司的净利润是多少”与”该公司属于什么行业、位于哪个省份”这两类信息整合到同一行记录中,从而支持后续的分组分析。
第三步:数据清洗与对数变换
拿到原始数据后,不能直接拿来分析。金融数据中常见的问题包括:缺失值、零值(如新上市公司尚无营收)、以及极端的长尾分布(个别巨型企业的营收可能是中小企业的上万倍)。下面的代码完成了两项关键的预处理操作:剔除无效记录和对数变换。
# 构建数据有效性过滤条件:要求营业收入>100万、总资产>100万、且净利润为正
# 这一步剔除了ST公司、空壳公司等不具分析意义的记录
is_valid_record = (
(yrd_companies_data['revenue'] > 1e6) & # 营业收入大于100万
(yrd_companies_data['total_assets'] > 1e6) & # 总资产大于100万
(yrd_companies_data['net_profit'] > 0) # 净利润为正
)
yrd_cleaned_data = yrd_companies_data[is_valid_record].copy() # 仅保留满足全部三个条件的观测值
# 对数变换(Log-Transformation):将具有长尾分布的财务绝对金额转换为对数尺度
# 这样做的好处是:(1)压缩极端值的影响;(2)使变量分布更接近正态;(3)对数尺度下的线性关系对应原始尺度下的幂律关系
yrd_cleaned_data['log_revenue'] = np.log10(yrd_cleaned_data['revenue']) # 对营业收入取以10为底的对数
yrd_cleaned_data['log_assets'] = np.log10(yrd_cleaned_data['total_assets']) # 对总资产取以10为底的对数
yrd_cleaned_data['log_profit'] = np.log10(yrd_cleaned_data['net_profit']) # 对净利润取以10为底的对数
# 统计每个行业的公司数量,并选取公司数目最多的前5个行业用于后续对比分析
top_industries_names = yrd_cleaned_data['industry_name'].value_counts().head(5).index # 按行业名称统计公司数量,取前5大行业
# 过滤出仅属于前5大行业的公司子集,作为最终的绘图数据
plotting_data = yrd_cleaned_data[yrd_cleaned_data['industry_name'].isin(top_industries_names)] # 保留行业名在前5大行业列表中的记录为什么要做对数变换?在现实中,中国A股最大的上市公司(如工商银行)的营收可以达到数千亿元,而一些小型公司的营收可能只有几千万元。如果直接用原始金额绘制散点图,所有中小企业都会被挤压到坐标轴原点附近,完全看不清分布规律。取常用对数(\(\log_{10}\))后,10亿元变为9,100亿元变为11,1000亿元变为12——不同量级的公司在对数尺度上均匀”展开”,使得我们能够更清晰地观察变量之间的线性趋势。
第四步:绘制散点图与箱线图
完成数据准备后,我们使用 matplotlib 创建一个包含三个子图(Subplot)的图形面板:左图展示净利润与营收的关系,中图展示净利润与资产的关系,右图通过箱线图对比不同行业的利润分布差异。
academic_colors_palette = ['#E3120B', '#2C3E50', '#008080', '#F0A700', '#8E9EAA'] # 定义学术配色方案:红、深蓝灰、青、金、灰
fig, axes = plt.subplots(1, 3, figsize=(16, 5)) # 创建1行3列的子图网格,总宽度16英寸、高度5英寸
# ---- 左图:净利润 vs 营业收入散点图 ----
axes[0].scatter(plotting_data['log_revenue'], plotting_data['log_profit'], alpha=0.4, s=25, c='#2C3E50') # 绘制散点,alpha=0.4使重叠点可见
poly_coeff = np.polyfit(plotting_data['log_revenue'], plotting_data['log_profit'], 1) # 用一次多项式(即线性回归)拟合趋势线
axes[0].plot(plotting_data['log_revenue'], np.polyval(poly_coeff, plotting_data['log_revenue']), color='#E3120B', lw=2.5) # 绘制红色趋势线
axes[0].set_xlabel('Log10 营业收入', fontsize=11) # 设置x轴标签
axes[0].set_ylabel('Log10 净利润', fontsize=11) # 设置y轴标签
axes[0].set_title('净利润与营业收入呈强线性关系', fontweight='bold') # 设置子图标题
# ---- 中图:净利润 vs 总资产散点图 ----
axes[1].scatter(plotting_data['log_assets'], plotting_data['log_profit'], alpha=0.4, s=25, c='#008080') # 用青色绘制资产-利润散点
poly_coeff_assets = np.polyfit(plotting_data['log_assets'], plotting_data['log_profit'], 1) # 对资产-利润关系进行线性拟合
axes[1].plot(plotting_data['log_assets'], np.polyval(poly_coeff_assets, plotting_data['log_assets']), color='#E3120B', lw=2.5) # 绘制红色趋势线
axes[1].set_xlabel('Log10 总资产', fontsize=11) # 设置x轴标签
axes[1].set_title('盈利随资产规模同步增长', fontweight='bold') # 设置描述性标题
# ---- 右图:不同行业的利润分布箱线图 ----
sns.boxplot(x='industry_name', y='log_profit', data=plotting_data, ax=axes[2], palette=academic_colors_palette) # 按行业名称分组绘制箱线图
axes[2].set_xlabel('细分行业', fontsize=11) # 设置x轴标签
axes[2].set_title('不同行业利润分布存在显著性差异', fontweight='bold') # 设置描述性标题
plt.xticks(rotation=30) # 将x轴行业标签旋转30度以避免重叠
for ax in axes: # 遍历三个子图
ax.grid(True, linestyle='--', alpha=0.5) # 为每个子图添加虚线网格,增强可读性
plt.tight_layout() # 自动调整子图间距,防止标签重叠
plt.show() # 渲染并显示最终图形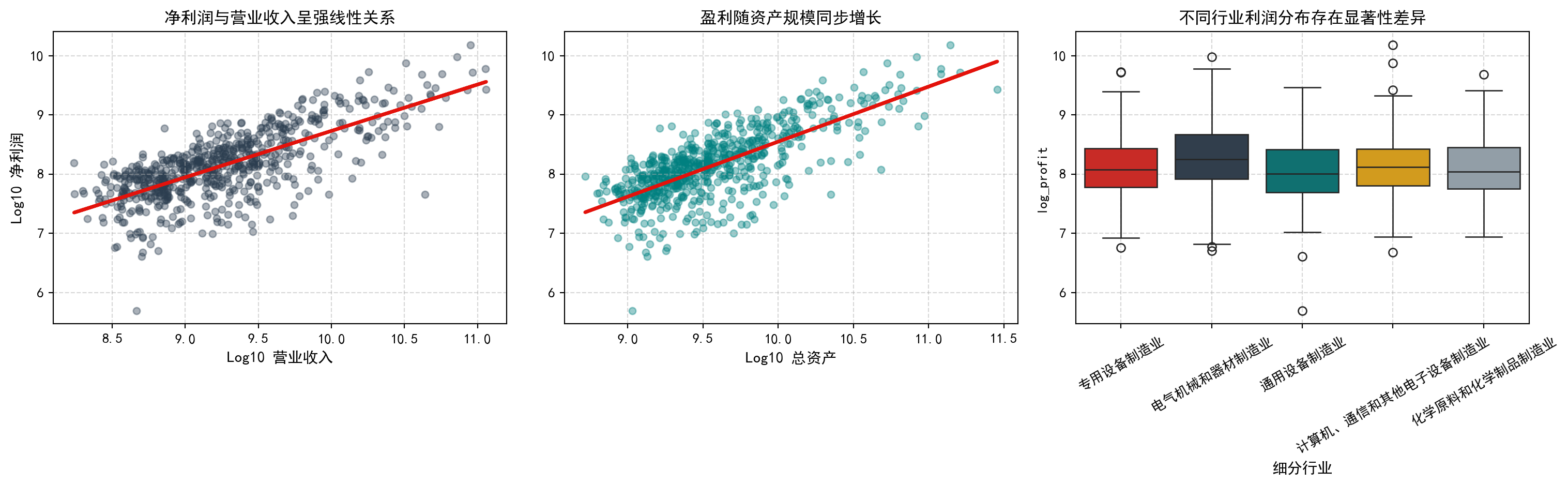
图 2.2 的三幅子图给出了直观的分析结论。左图的散点云呈现出非常明显的正相关线性趋势(由红色拟合线标示),说明在对数尺度上,营业收入是预测净利润最有力的单一指标。中图展示了类似的正相关模式,但数据点的离散程度更大,表明资产规模虽然与利润正相关,但其预测精度不如营收。右图的箱线图则揭示了行业间的利润率差异——例如,高毛利率的行业(如半导体、生物医药)和低毛利率行业(如传统制造)在利润分布上有明显的位置差异。这些分析结果告诉我们:一个好的预测模型应该综合使用营收、资产和行业信息,而不是仅依赖其中一个变量。
2.3 股票市场数据 (Stock Market Data)
在统计学习中,预测连续型或定量输出值(如净利润)的过程通常被称为回归问题 (Regression Problem)。然而,在许多商业决策场景中,我们更关心定性或离散型的输出,这被称为分类问题 (Classification Problem)。
例如,在 章节 5 章中,我们研究一个具有代表性的股票市场数据集。对于交易员或基金经理而言,一个核心的分类任务是预测指数或个股在给定日期会上涨还是下跌。
考虑长三角地区的汽车行业龙头——上汽集团 (600104.SH)。我们使用其历史日度收益率数据。如果今日的收益率为正,我们标记为“上涨”;否则标记为“下跌”。我们的目标是利用过去几天的历史表现(滞后项,Lags)作为特征,来学习一个分类映射。
图 2.3 显示了历史滞后收益率与今日市场涨跌之间的关系。在成熟的市场中,这种关系往往是非常微弱的,这反映了市场效率。
下面我们将通过代码分步演示如何加载上汽集团的历史日频价格数据,计算每日收益率,并利用特征工程中经常使用的 shift 函数构建”滞后收益率”作为预测特征。
第一步:加载上汽集团股价数据并计算收益率
我们首先从本地前复权价格文件中读取上汽集团的全部历史行情,然后基于收盘价计算每日百分比收益率(pct_change() 方法的含义是 \((P_t - P_{t-1})/P_{t-1}\))。
PRICE_DATA_PATH = os.path.join(DATA_ROOT, 'stock/stock_price_pre_adjusted.h5') # 构造前复权行情数据的完整文件路径
stock_price_history = pd.read_hdf(PRICE_DATA_PATH).reset_index() # 读取全部A股日度前复权价格数据,将MultiIndex转为普通列
# 从全市场数据中筛选出股票代码为'600104.XSHG'的上汽集团,创建独立副本以避免修改原始数据
saic_motor_data = stock_price_history[stock_price_history['order_book_id'] == '600104.XSHG'].copy()
saic_motor_data['date'] = pd.to_datetime(saic_motor_data['date']) # 将日期列转换为标准datetime格式
saic_motor_data = saic_motor_data.sort_values('date') # 按日期升序排列,确保时间序列的前后顺序正确
# 计算每日简单收益率:(今日收盘价 - 昨日收盘价) / 昨日收盘价
saic_motor_data['daily_return'] = saic_motor_data['close'].pct_change() # 计算百分比变化(收益率)上面的代码完成了数据的加载和收益率计算。pct_change() 是 pandas 时间序列分析中最常用的方法之一,它自动计算相邻两个时间点之间的变化百分比。对于股价时间序列而言,这正好就是每日投资回报率。
第二步:构建滞后特征并定义分类标签
接下来,我们利用 shift() 函数创建过去 1 到 5 天的”回溯”收益率作为预测特征,并将当日收益率的正负作为二分类标签。shift(lag) 的作用是把整列数据向下移动 lag 行——这意味着第 \(t\) 行的 lag_return_1 值实际上是第 \(t-1\) 天的收益率。
num_lags = 5 # 定义需要构建的滞后特征数量为5(即使用过去5天的收益率信息)
for lag in range(1, num_lags + 1): # 循环创建lag_return_1到lag_return_5共5列
# shift(lag)将daily_return列向下平移lag行,实现"回溯"效果
saic_motor_data[f'lag_return_{lag}'] = saic_motor_data['daily_return'].shift(lag) # 将收益率向下平移lag行,生成第lag天前的历史收益率
# 定义二分类目标标签:当日收益率>0标记为1(上涨),否则标记为0(下跌),并转换为整数类型
saic_motor_data['market_direction'] = (saic_motor_data['daily_return'] > 0).astype(int)
# 仅保留2015年以后的数据,并删除因shift操作产生的前5行缺失值
saic_analysis_dataset = saic_motor_data[saic_motor_data['date'] >= '2015-01-01'].dropna() # 筛选2015年后数据并剔除缺失行通过这段特征工程代码,我们将一维的收益率时间序列”展开”成了一个包含5个特征的数据表。对于第 \(t\) 天的记录,其特征向量为 \((r_{t-1}, r_{t-2}, r_{t-3}, r_{t-4}, r_{t-5})\),标签为 \(y_t \in \{0, 1\}\)。这是将时间序列预测问题转化为标准分类问题的经典手法,也是量化投资中最基础的建模范式之一。
第三步:绘制滞后收益率与涨跌方向的箱线图
最后我们将数据按照”上涨日”和”下跌日”分组,分别绘制不同滞后天数下的收益率分布箱线图,从而直观展示历史收益率对未来涨跌的区分能力。
fig, axes = plt.subplots(1, 3, figsize=(15, 5)) # 创建1行3列的子图布局
lag_indices = [1, 2, 3] # 选择前3个滞后项进行可视化展示
for i, lag_idx in enumerate(lag_indices): # 对每个滞后项依次绘制箱线图
sns.boxplot( # 使用seaborn绑制分组箱线图,按涨跌方向分组展示滞后收益率分布
x='market_direction', # x轴为今日涨跌方向(0或1)
y=f'lag_return_{lag_idx}', # y轴为对应滞后天数的历史收益率
data=saic_analysis_dataset, # 使用前面构建的分析数据集
ax=axes[i], # 指定绑制到第i个子图上
palette=['#E3120B', '#008080'], # 下跌日用红色,上涨日用青色
showfliers=False # 不显示离群点,使箱体形状更清晰
) # 完成单个滞后项的箱线图绑制
axes[i].set_xticklabels(['下跌日', '上涨日']) # 将数字标签替换为中文描述
axes[i].set_title(f'滞后项 Lag {lag_idx} 收益分布', fontweight='bold') # 设置子图标题标明滞后阶数
axes[i].set_xlabel('今日方向') # 设置x轴标签
axes[i].set_ylabel('过去收益率') # 设置y轴标签
axes[i].grid(True, axis='y', alpha=0.3) # 仅在y轴方向添加淡色网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示最终图形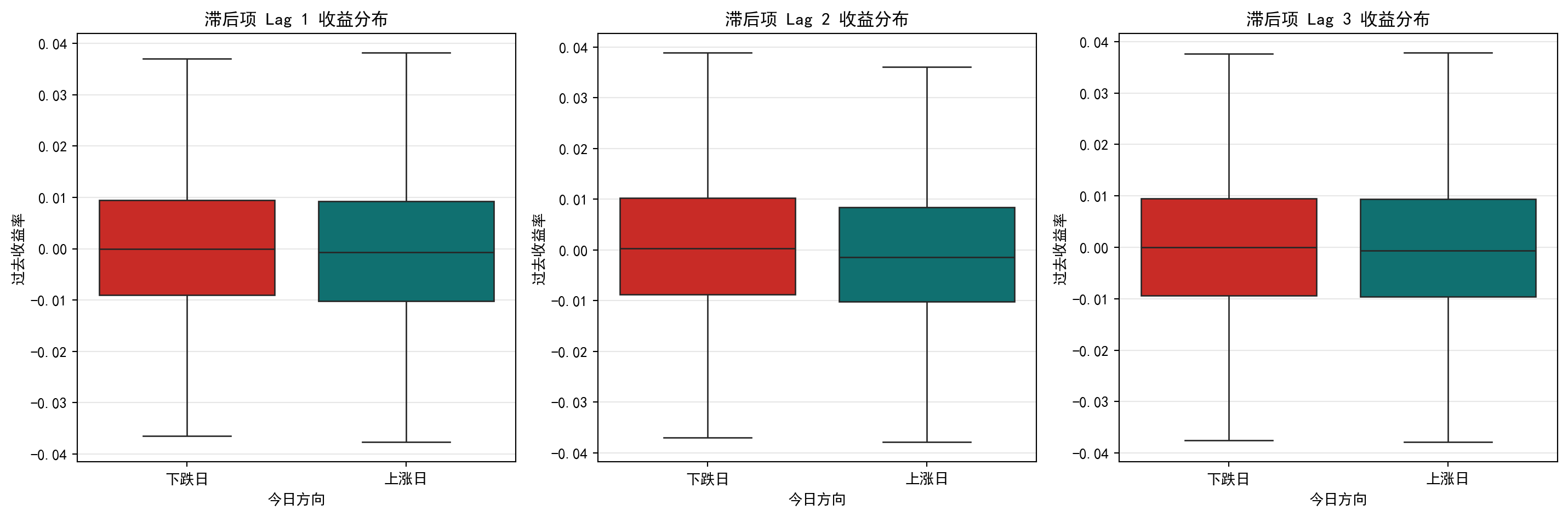
观察 图 2.3 的三幅箱线图,一个重要的视觉发现是:无论是 Lag 1(昨天)、Lag 2(前天)还是 Lag 3(大前天)的收益率,“上涨日”和”下跌日”对应的箱体在位置和形状上几乎完全重合。两组箱体的中位线(箱子中间的横线)、四分位间距(箱子的高度)都极为相似。这意味着,如果你仅凭某一天的历史收益率来猜测明天的涨跌方向,你的准确率几乎等同于抛硬币——这正体现了金融市场中”弱式有效”的特征:过去的价格信息已经被市场充分消化,很难被简单地用来赚取超额利润。
虽然单一变量的箱线图显示出较弱的区分度,但通过组合这些多维度的滞后项,现代统计学习分类器能够尝试在多维空间中提取非平凡的预测模式。在接下来的代码中,我们将数据集严格按照时间发生顺序划分为训练集(前75%历史数据用于让模型学习历史规律)和测试集(后25%最新数据绝对隔离,用于模拟未来的真实预测)。
第四步:准备特征矩阵并按时间顺序划分训练/测试集
在金融预测中,数据划分绝不能随机打乱。我们必须严格按照时间先后顺序,用历史数据训练、用未来数据测试,以模拟真实投资决策中只能利用已知信息的约束条件。
from sklearn.linear_model import LogisticRegression # 导入逻辑回归分类器
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis # 导入LDA和QDA
from sklearn.neighbors import KNeighborsClassifier # 导入K近邻分类器
from sklearn.metrics import accuracy_score # 导入准确率评估函数
# 构建特征列名列表:lag_return_1到lag_return_5
feature_columns = [f'lag_return_{i}' for i in range(1, 6)] # 使用列表推导式
features_matrix = saic_analysis_dataset[feature_columns] # 提取5列滞后收益率作为特征矩阵X
target_vector = saic_analysis_dataset['market_direction'] # 提取涨跌方向标签作为目标向量y
# 按时间顺序将前75%数据划为训练集,后25%数据划为测试集(绝不随机打乱)
split_point = int(0.75 * len(features_matrix)) # 计算75%分位点的行数索引
features_train, features_test = features_matrix.iloc[:split_point], features_matrix.iloc[split_point:] # 切分特征矩阵
target_train, target_test = target_vector.iloc[:split_point], target_vector.iloc[split_point:] # 切分目标向量第五步:训练四种分类模型并计算测试精度
我们选择了四种经典的统计学习分类器,它们将在后续章节中被逐一深入讲解。在这里先让读者对它们的预测表现有一个初步的直观印象。
# 定义待评估的四种分类模型及其名称
classifiers_dict = { # 构建包含四种分类模型的字典,键为模型名称,值为模型实例
'逻辑回归': LogisticRegression(), # 基于Sigmoid函数的线性分类器
'线性判别分析 (LDA)': LinearDiscriminantAnalysis(), # 假设各类数据共享协方差矩阵
'二次判别分析 (QDA)': QuadraticDiscriminantAnalysis(), # 允许各类拥有不同协方差矩阵
'K-近邻 (K=3)': KNeighborsClassifier(n_neighbors=3) # 基于空间距离的非参数分类器
} # 字典定义完毕,共4个待对比的分类器
prediction_accuracies = {} # 创建空字典用于存储各模型的测试准确率
for name, clf in classifiers_dict.items(): # 遍历每个模型
clf.fit(features_train, target_train) # 在训练集上拟合模型参数
predictions = clf.predict(features_test) # 对测试集进行预测
prediction_accuracies[name] = accuracy_score(target_test, predictions) # 计算并存储该模型预测准确率上面的循环中,fit() 方法让模型”学习”训练数据中的历史规律,而 predict() 方法则让训练好的模型对从未见过的测试数据做出预测。accuracy_score() 将模型的预测结果与测试集的真实标签进行逐一比对,返回正确预测占总预测数的比例。
第六步:可视化各模型的预测表现
最后,我们将四个模型的测试集准确率绘制成水平条形图,并标注50%的随机基准线。如果模型准确率接近50%,说明其预测能力与随机猜测无异。
plt.figure(figsize=(10, 6)) # 创建10x6英寸的画布
bar_colors = ['#2C3E50', '#008080', '#F0A700', '#8E9EAA'] # 为四个模型分配不同颜色
plt.barh(list(prediction_accuracies.keys()), list(prediction_accuracies.values()), color=bar_colors, alpha=0.8) # 绘制水平条形图
plt.axvline(x=0.5, color='#E3120B', linestyle='--', label='随机水平 (50%)') # 添加红色虚线标注50%随机基准
plt.xlim(0.48, 0.55) # 设置x轴范围为48%~55%,放大观察准确率差异
plt.xlabel('测试集预测准确率') # 设置x轴标签
plt.title('上汽集团次日涨跌预测准确率对比', fontweight='bold') # 设置图表标题
plt.legend() # 显示图例
plt.grid(axis='x', linestyle=':', alpha=0.6) # 在x轴方向添加点状网格线
plt.show() # 渲染并显示图形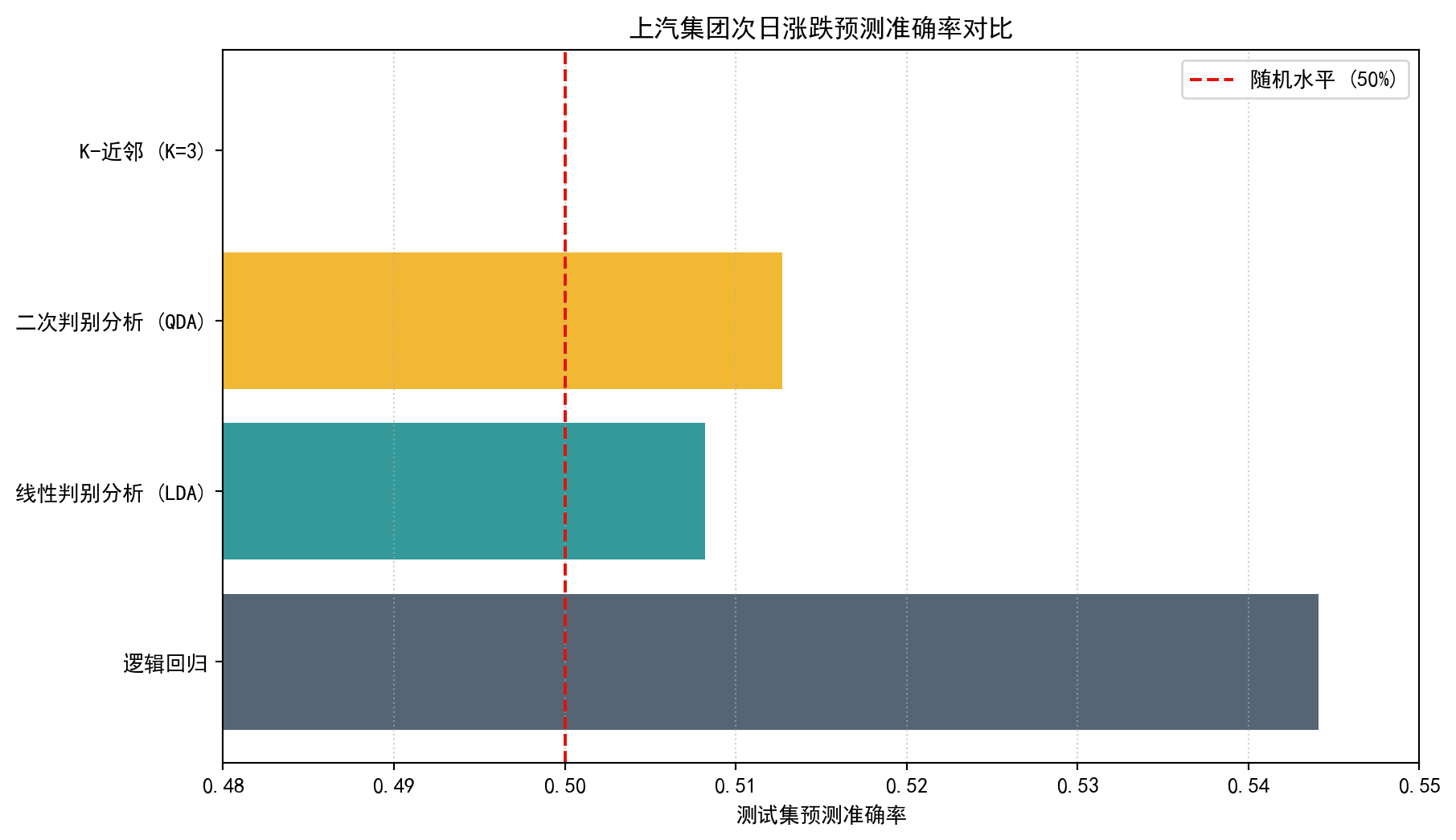
当你观察 图 2.4 的运行结果时,你会发现所有模型的准确率都在 50%(等同于掷硬币的纯随机水平)左右艰难徘徊,这正是金融市场实盘预测的真正残酷之处。四种模型——无论是基于线性决策边界的逻辑回归和LDA,还是允许非线性边界的QDA和KNN——在这一简单任务上的表现几乎没有本质差别,这进一步印证了仅凭历史价格信息难以稳定盈利的市场有效性假说。
关于股市预测的重要警告与理论约束
在尝试应用统计学习进行股市预测时,必须警惕以下核心风险:
- 弱式有效市场 (Weak-form EMH): Eugene Fama在1970年提出的有效市场假说指出,如果过去的价格信息已完全反映在当前价格中,那么统计学习很难通过单纯的历史收益率获得超额收益 (Alpha)。
- 数据窥探 (Data Snooping): 当我们测试成千上万种特征和模型组合时,某些模型由于随机巧合而在测试集上表现优异。这种现象在金融领域极其普遍。
- 结构突变 (Structural Break): 金融市场的底层规律可能随着制度、宏观环境或参与者行为的改变而发生突变,导致历史训练的模型完全失效。
2.4 量化多因子模型与高维问题 (Quantitative Multi-Factor Models and High-Dimensionality)
在现代商业和金融分析中,我们越来越多地面临所谓的“高维数据”挑战。在此类情境中,\(p\)(预测变量或特征的数量)可能接近甚至远远大于 \(n\)(观测样本的数量)。
以当下中国股票市场的量化投资为例。在构建“多因子模型”时,分析师为了捕获市场中微小的超额收益(Alpha),会设计海量的量化因子:传统的财务因子(如市盈率、资产负债率)、基于交易的高频价量因子(如订单簿不平衡率、分钟级动量)、甚至是从新闻文本和社交媒体情绪中提取的非结构化因子。导致的结果是,我们面对一家上市公司,可能同时提取了超过 2000 个预测特征 (\(p=2000\)),而用来训练下个月收益率预测模型的时间截面样本(比如沪深300成分股)只有 300 个 (\(n=300\))。
数学视角:维数灾难 (The Curse of Dimensionality)
当 \(p > n\) 时,传统的统计计量方法(例如普通的普通最小二乘法 OLS)会遭遇机制性崩溃,因为支撑求解参数的矩阵 \(\mathbf{X}^T\mathbf{X}\) 是完全奇异(不可逆)的。更直观地说,由于供我们参考的样本太少而可用的解释变量太多,模型总能通过复杂的拼凑,“完美”记忆历史数据中的每一丝随机波动。这在统计中被称为过拟合。此时,模型预测明天股票收益率的能力几乎为零。
为了在海量的特征中抽丝剥茧,并解决矩阵不可逆的问题,本书在后续章节(如第 章节 7 章)中将深入探讨正则化 (Regularization) 和特征降维机制。例如:
- Lasso 回归: 它能够在建立模型的同时进行严厉的因子筛选,将绝大多数冗余或无预测能力的量化因子权重直接”压缩”为零,从而提供一个极其稀疏、可解释性强的投资策略。
- 岭回归 (Ridge): 通过特殊的惩罚机制限制所有参数的幅度增长,使得模型在处理高度互相关(如各种动量因子相互高度相关)的多重共线性数据时,依然能够保持异常稳定的表现。
随着算力的普及和数据获取门槛的降低,高维统计学习技术已经被国内各大券商自营和头部量化私募广泛运用于交易逻辑的挖掘中。理解如何在 \(p \gg n\) 的极限状态下依然保持分析的严谨性,是高阶商业数据分析的核心素养。
2.5 机器学习时代的理论融合 (Theoretical Integration in the Era of Machine Learning)
在数据科学席卷全球商业应用之前,统计学和古典人工智能曾是相互平行的独立分支。经典的统计文献专注于用精妙的数学推导来证明估计量的无偏性和一致性,而早期的计算机科学则致力于利用规则引擎或启发式搜索解决特定任务。
而在过去的数十年间,尤其是在工业界急需处理极其复杂、非线性、高维数据集的迫切需求下,这两个领域迎来了历史性的融合。一方面,基于最大似然和贝叶斯决策理论的统计根基,为机器学习中那些看似“黑盒”的复杂算法提供了严密的概率推断和误差控制分析(如模型是否产生了过度学习和记忆)。另一方面,计算机硬件算力的爆发式增长和算理(如反向传播优化算法)的创新,使得学者们可以摆脱纯粹理论推导的枷锁,使用诸如随机森林、梯度提升树甚至是数千层网络结构的深度学习架构去真正拟合现实世界中的非线性 \(f(X)\)。
在中国本土的市场环境里,这种理论的融合正激发出巨大的商业潜力。例如,在数字信贷领域,互联网大厂的金融科技平台不再局限于使用传统的逻辑回归和几个维度的财务指标来发放贷款,而是利用庞大的树模型整合多达数万维的用户行为轨迹来实时评估违约风险;在股票市场,主流的交易机构则结合了传统的金融工程与深度神经网络来实现对高频数据的降噪和趋势捕获。
统计学习与机器学习、人工智能的关系与定位
对于商学院学生而言,在面对铺天盖地的技术名词时保持清晰的认知尤为重要。这三个词语的内涵具有嵌套或交叉的属性:
首先,人工智能 (Artificial Intelligence) 是一个拥有宏大愿景的学科大类,目标是打造能够模拟人类认知和决策的系统;而机器学习 (Machine Learning) 是当前实现这一目标最具生命力的技术路径,它侧重于让计算机自己从数据中”学习”规律而非依靠人类硬编码规则。
最后,统计学习 (Statistical Learning) 是为整个机器学习大厦提供工程图纸的数学与统计基石。它不仅仅关注模型能否在测试集上取得高分(这是传统工程实践的最高诉求),更关注预测结果为什么好、它的置信区间有多宽、以及特征到底对结果产生了多大的边际效应(这是商业决策的核心诉求)。本书坚持从统计学习的视角来阐述算法,旨在赋予你在海量数据面前保持冷静分析、不盲从算法黑盒的能力。
2.6 本书概览 (This Book)
本书提供了对统计学习领域广泛而深入的介绍。我们的目标是解释统计学习方法何时以及为何有用,并举例说明这些方法如何应用于实际数据分析。我们专注于理解统计学习的概念和基础,而不是深入探讨每个领域的理论发展。
本书的组织结构如下:
- 第 章节 2 章(统计学习导论):介绍监督学习和无监督学习的区别,并通过实例说明统计学习的应用领域
- 第 章节 3 章(什么是统计学习?):形式化地介绍统计学习理论,定义损失函数、偏差-方差权衡等核心概念
- 第 章节 4 章(线性回归):详细介绍简单线性回归和多元线性回归,包括最小二乘估计、假设检验、置信区间等
- 第 章节 5 章(分类):讨论逻辑回归、线性判别分析、二次判别分析、K近邻等分类方法
- 第 章节 6 章(重采样方法):介绍交叉验证和Bootstrap方法,用于模型评估和选择
- 第 章节 7 章(线性模型选择与正则化):讨论子集选择、岭回归、Lasso、主成分分析等方法
- 第 章节 8 章(超越线性):介绍多项式回归、样条光滑、广义加性模型等非线性方法
- 第 章节 9 章(基于树的方法):讨论决策树、Bagging、随机森林、Boosting等方法
- 第 章节 10 章(支持向量机):详细介绍最大间隔分类器、支持向量机、支持向量回归等
- 第 章节 11 章(深度学习):介绍神经网络、反向传播、卷积神经网络、循环神经网络等
- 第 章节 12 章(生存分析与删失数据):讨论Kaplan-Meier估计、对数秩检验、Cox比例风险模型等
- 第 章节 13 章(无监督学习):介绍主成分分析、聚类分析(K-means、层次聚类)等方法
- 第 章节 14 章(多重检验):讨论多重检验问题、错误发现率(FDR)控制等
本书使用的工具和数据集
本书使用Python作为主要的编程语言,主要使用以下工具包:
- NumPy:数值计算基础库
- Pandas:数据操作和分析
- Matplotlib 和 Seaborn:数据可视化
- Scikit-learn:机器学习算法库
- Statsmodels:统计建模和计量经济学
- PyTorch:深度学习框架
本书的案例数据全部来自中国本土真实市场数据,存储在本地数据目录中(Windows: C:\qiufei\data,Linux: /home/ubuntu/r2_data_mount/data)。主要数据源包括:
- 上市公司基本信息 (
stock/stock_basic_data.h5):股票代码、名称、行业分类、上市时间、所在地区等。 - 上市公司财务报表 (
stock/financial_statement.h5):2005-2025年A股全部上市公司的季度财务数据,涵盖资产负债表、利润表和现金流量表核心指标。 - 股票日度行情数据 (
stock/stock_price_pre_adjusted.h5等):2005-2025年A股日度OHLC行情,提供前复权、后复权和不复权三个版本。 - 估值因子数据 (
stock/valuation_factors_quarterly_15_years.h5):2011-2025年A股全部上市公司的季度估值因子指标。 - 指数、期货与基金数据 (
index/、future/、fund/文件夹):各类市场指数、期货合约和基金净值数据。 - 中国地理数据 (
map/文件夹):省、市、县级GeoJSON地图数据,用于地理可视化。
2.7 谁应该阅读本书? (Who Should Read This Book?)
本书是为那些希望在理论和实践之间建立桥梁的读者设计的。具体而言,本书适合以下读者:
- 高年级本科生:希望系统学习统计学习理论基础和实际应用的学生。我们假设读者具备微积分、线性代数、概率论和数理统计的基本知识
- 研究生:需要将统计学习方法应用于各自研究领域的学生,包括统计学、计算机科学、经济学、工程学、生物信息学等
- 数据分析师和科学家:希望深入了解所用方法的理论基础,并能够根据具体问题选择合适方法的专业人士
- 对人工智能和机器学习感兴趣的从业者:希望理解机器学习算法背后的统计原理,而不仅仅是调用API包的用户
本书既适合课堂教学,也适合自学。每章都包含丰富的图表、实例和习题,帮助读者理解和掌握统计学习的核心概念和方法。
先修知识要求
为了充分理解本书内容,读者应具备以下数学基础:
- 数学基础:
- 微积分:导数、偏导数、梯度、积分
- 线性代数:矩阵运算、特征值和特征向量、矩阵分解
- 概率论:随机变量、概率分布、期望、方差、协方差
- 数理统计:估计理论、假设检验、置信区间
- 编程能力:
- 本书假设读者没有编程基础。所有代码示例都配有逐行详细注释,从零开始解释每一条Python语句的功能和逻辑。读者只需按照示例操作即可。
- 对于有一定编程基础的读者,可以跳过基础注释,专注于统计方法的应用逻辑。
- 补充资源: 对于数学基础较弱的读者,推荐阅读Gilbert Strang的《Introduction to Linear Algebra》,以及Deisenroth等人编写的《Mathematics for Machine Learning》。
2.8 符号与记号 (Notation and Symbols)
本书采用以下标准记号:
- 标量:使用小写字母,如\(x, y, z\)
- 向量:使用粗体小写字母,如\(\mathbf{x}, \mathbf{y}, \mathbf{z}\)
- 矩阵:使用粗体大写字母,如\(\mathbf{X}, \mathbf{Y}, \mathbf{Z}\)$
- 随机变量:使用大写字母,如\(X, Y, Z\)
- 估计量:在参数上方添加帽子,如\(\hat{\beta}, \hat{y}, \hat{\sigma}^2\)
- 转置:使用上标\(^T\),如\(\mathbf{A}^T\)
- 逆矩阵:使用上标\(^{-1}\),如\(\mathbf{A}^{-1}\)
- 期望:使用\(E[\cdot]\)
- 方差:使用\(\text{Var}(\cdot)\)
- 协方差:使用\(\text{Cov}(\cdot, \cdot)\)
在回归问题中:
- \(n\):观测数量(样本量)
- \(p\):预测变量(特征)数量
- \(\mathbf{x}_i\):第\(i\)个观测的预测变量向量,\(p \times 1\)
- \(y_i\):第\(i\)个观测的响应变量(标量)
- \(\mathbf{X}\):所有观测的预测变量矩阵,\(n \times p\)
- \(\mathbf{y}\):所有观测的响应变量向量,\(n \times 1\)
在分类问题中:
- \(K\):类别数量
- \(G_k\):第\(k\)个类别
- \(p_k(x) = P(Y=k | X=x)\):给定\(X=x\)时属于第\(k\)类的条件概率
关于数学符号的说明
本书尽量使用标准的统计学习符号系统,但也注意到不同文献可能采用不同的约定。读者在阅读其他资料时可能会遇到符号差异,例如:
- 有些文献使用\(\beta\)表示回归系数,有些使用\(\theta\)或\(w\)
- 有些文献使用\(\mathbf{x}\)表示列向量,有些表示行向量
- 有些文献用\(n\)表示样本量,有些用\(N\)或\(m\)
关键是要理解每个符号在具体上下文中的含义,而不是死记硬背。本书在每次引入新符号时都会明确定义其含义和维度。
2.9 数据集说明 (Data Sets Used in This Book)
本书使用的全部案例数据均来自中国本土真实市场数据,存储在本地数据目录中。读者无需联网即可完成所有代码示例和练习。
本地数据路径(代码会自动检测操作系统并选择正确路径):
- Windows:
C:\qiufei\data - Linux:
/home/ubuntu/r2_data_mount/data
读者可以从教材的数据网站获取这些本地数据,将本机数据的文件名前添加 https://assets.qiufei.site/data/ 这串字符串,就可以获取数据的下载链接。比如,想获取stock/stock_basic_data.h5 这一数据,其网址就是:https://assets.qiufei.site/data/stock/dupont_analysis_data.h5
核心数据文件一览:
| 数据文件 | 说明 | 典型应用场景 |
|---|---|---|
stock/stock_basic_data.h5 |
上市公司基本信息(代码、名称、行业、地区等) | 公司筛选、行业分析 |
stock/financial_statement.h5 |
2005-2025年季度财务报表数据 | 财务分析、面板数据建模 |
stock/stock_price_pre_adjusted.h5 |
2005-2025年日度前复权行情 | 收益率计算、技术分析 |
stock/stock_price_post_adjusted.h5 |
2005-2025年日度后复权行情 | 长期投资收益率分析 |
stock/valuation_factors_quarterly_15_years.h5 |
2011-2025年季度估值因子 | 多因子模型、价值投资 |
index/ 文件夹 |
各类市场指数数据 | 市场基准分析 |
map/ 文件夹 |
省市县级GeoJSON地图 | 地理可视化 |
Python依赖安装(基于python 3.10):
pip install numpy pandas matplotlib seaborn scikit-learn statsmodels torch所有在本书中使用的数据集都会在首次使用时详细说明其来源、结构和含义。我们优先使用:
- 本地存储的真实数据:确保所有读者都可以离线复现
- 可追溯的数据版本:使用固定时间截面的数据快照
- 中国本土上市公司数据:优先选择长三角地区企业作为案例
2.10 理论来源与前沿
统计学习既继承了数理统计中关于估计与推断的传统,也吸收了计算机科学中关于算法与泛化的思想。回归与分类等基本任务可以追溯到最小二乘与极大似然;而现代意义上的‘学习’强调在有限样本下控制泛化误差,并在偏差-方差权衡、正则化与模型选择等框架下形成一套统一语言。
近十年来,统计学习的前沿发展一方面来自大规模数据与算力带来的深度学习革命,另一方面来自可解释性、公平性与稳健性等对现实部署提出的新约束。在中国的商业场景中,典型的挑战包括:行业结构快速变化导致的分布漂移、监管对模型可解释性的要求、以及多源异构数据(财务、交易、文本、图像)的融合。
2.11 练习
2.11.1 概念题
基本定义:解释什么是统计学习。用一句话分别概括“监督学习”与“无监督学习”的核心目标。
可解释性与准确度:本书强调“预测准确度”与“模型可解释性”之间的权衡。请给出一个中国商业场景(如银行信贷审批),说明两者冲突的具体表现。
研究可复现性:为什么在学术研究和企业生产中强调“可复现性”?请列出实现可复现所需的至少三个要素。
数学符号理解:在 式 2.1 中,\(f\) 和 \(\epsilon\) 分别代表什么?为什么我们总是假设 \(E(\epsilon) = 0\)?
2.11.2 应用题
- 本地行情探索:利用你本机的 A 股数据,选择一家长三角地区的上市公司(如上海的“上汽集团”或杭州的“海康威视”),完成以下任务:
- 使用 Python 读取其 2015-2025 年的后复权收盘价数据。
- 绘制股价走势图。
- 计算并报告日收益率的峰度 (Kurtosis) 和偏度 (Skewness)。
- 思考题:如果收益率分布表现出明显的“肥尾”特征,这对传统的统计假设(如正态分布)意味着什么?
- 业务场景建模:某电商平台希望预测哪些用户在未来一个月内会流失。
- 这是一个监督学习还是无监督学习问题?
- 这是一个回归问题还是分类问题?
- 列出至少三个可能有助于预测流失的特征(Features)。
2.11.3 理论题
损失函数分析:在回归问题中,我们通常最小化平方损失 (Squared Loss) \((y - \hat{y})^2\)。请给出一个该损失函数可能不适用的场景,并建议一个替代方案。
泛化误差:一句话解释什么是“泛化误差” (Generalization Error),以及为什么我们不能直接使用训练集误差来估计它。
2.12 练习参考解答
2.12.1 概念题解答
统计学习定义:统计学习是一套用于建模和理解复杂数据集的数学框架。监督学习的目标是学习输入与输出之间的映射以进行预测;无监督学习的目标是发现数据内部的隐含结构。
权衡示例:在银行信贷审批中,使用深度神经网络可能实现极高的违约预测准确度。但根据监管要求,银行必须能向被拒贷客户解释原因(如“负债率过高”)。高准确度的黑盒模型往往缺乏这种可解释性,导致业务无法合规。
可复现性:可复现性确保了研究结论的客观性和生产环境的稳定性。要素包括:(1) 数据版本控制;(2) 完整的源代码;(3) 确定的软件环境(如 Conda environment.yml)。
数学符号:\(f\) 代表系统性特征与响应变量之间的确定性关系;\(\epsilon\) 代表无法被特征解释的随机噪声。假设 \(E(\epsilon) = 0\) 是为了确保 \(f\) 是 \(Y\) 的无偏条件期望,即 \(f(X) = E(Y|X)\)。
2.12.2 应用题解答
- 上汽集团行情分析代码实现:
在下面的参考代码中,我们首先使用 pandas 工具包准确去读取指定路径下的量化行情数据,并经过时间类型转换和升序排列(确保时间序列分析的严肃性)。接着,我们利用对数进行差分计算了股票的对数收益率(Log Return,因为其在时间序列的累加运算中具备良好的数学性质且消除了单利复利差异)。随后,调用 .skew() 和 .kurt() 函数快速输出了偏度与峰度,帮助我们定量评估该资产收益真实分布与理论正态分布之间的背离程度,从而启发对尾部风险的思考。
import pandas as pd # 导入pandas库用于数据框操作
import numpy as np # 导入numpy库用于数值计算
import matplotlib.pyplot as plt # 导入matplotlib用于图表绘制
import os # 导入os模块用于跨平台路径处理
# 根据操作系统自动选择本地数据根目录路径
data_root = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
# 拼接后复权股价数据文件的完整路径(后复权适合计算长期投资回报)
price_file_path = os.path.join(data_root, 'stock/stock_price_post_adjusted.h5')
market_price_dataframe = pd.read_hdf(price_file_path).reset_index() # 从本地读取全市场后复权股价数据,将MultiIndex转为普通列
# 从全量数据中筛选上汽集团(股票代码600104.XSHG)的历史记录
saic_stock_data = market_price_dataframe[market_price_dataframe['order_book_id'] == '600104.XSHG'].copy()
saic_stock_data['date'] = pd.to_datetime(saic_stock_data['date']) # 将日期列转换为标准datetime格式
saic_stock_data = saic_stock_data.sort_values('date') # 按照交易日期升序排列
# 使用对数差分法计算日对数收益率:ln(P_t / P_{t-1})
saic_stock_data['daily_log_return'] = np.log(saic_stock_data['close'] / saic_stock_data['close'].shift(1))
cleaned_return_series = saic_stock_data['daily_log_return'].dropna() # 删除首行因shift产生的缺失值
skewness_val = cleaned_return_series.skew() # 计算收益率分布的偏度(衡量分布的不对称程度)
kurtosis_val = cleaned_return_series.kurt() # 计算收益率分布的峰度(衡量尾部厚度,正态分布的超额峰度为0)
print(f'上汽集团收益率偏度: {skewness_val:.4f}') # 输出偏度值,负值表示左偏(下跌尾部更长)
print(f'上汽集团收益率峰度: {kurtosis_val:.4f}') # 输出峰度值,正值表示肥尾(极端事件更频繁)上汽集团收益率偏度: 0.0912
上汽集团收益率峰度: 3.2219思考题解答:肥尾特征意味着极端收益发生的概率远高于正态分布的预测。这意味着基于正态假设的风险模型(如传统的 VaR)可能会严重低估金融危机期间的潜在损失。
- 用户流失预测:
- 监督学习。
- 分类问题(二分类:流失 vs 留存)。
- 特征:过去 30 天登录频率、平均客单价、最近一次消费距今时长。
2.12.3 理论题解答
损失函数:当数据中存在大量离群值(Outliers)时,平方损失会由于对大误差的二阶惩罚而过度向离群值偏移。替代方案是使用绝对损失 (L1 Loss),即 \(|y - \hat{y}|\),它对离群值更稳健。
泛化误差:泛化误差是模型在先前未见过的全新数据上的预期误差。训练误差通常会由于模型对噪声的过拟合而偏低,因此不能作为真实预测性能的可靠指标。