import numpy as np # 数值计算基础库
import pandas as pd # 表格数据处理库
import matplotlib.pyplot as plt # 数据可视化绑定
from sklearn.tree import DecisionTreeRegressor, plot_tree # 回归树模型与可视化
from sklearn.model_selection import train_test_split # 训练/测试集划分
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 配置全局绑图参数
plt.rcParams['axes.unicode_minus'] = False # 配置全局绑图参数
# 1. 加载本地财务报表数据
import os # 跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
path = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 拼接财务报表文件路径
financial_data = pd.read_hdf(path) # 直接读取本地HDF5格式的财务报表数据
# 基于杜邦分析框架构造核心财务比率
financial_data['Margin'] = financial_data['net_profit'] / financial_data['operating_revenue'] # 计算销售净利率
financial_data['Turnover'] = financial_data['operating_revenue'] / financial_data['total_assets'] # 计算资产周转率
financial_data['ROE'] = financial_data['net_profit'] / financial_data['equity_parent_company'] # 计算净资产收益率
# 清洗异常值和空值(仅针对分析所需列,避免全表dropna丢弃过多行)
analysis_columns = ['Margin', 'Turnover', 'ROE', 'total_assets', 'total_liabilities', 'equity_parent_company'] # 后续Cell也需用到的列
financial_data[['Margin', 'Turnover', 'ROE']] = financial_data[['Margin', 'Turnover', 'ROE']].replace([np.inf, -np.inf], np.nan) # 仅将分析列中的inf替换为NaN
financial_data = financial_data.dropna(subset=['Margin', 'Turnover', 'ROE']) # 仅按分析核心列去除缺失值
financial_data = financial_data[(financial_data['Margin'] > -0.5) & (financial_data['Margin'] < 0.5)] # 过滤净利率极端值
financial_data = financial_data[(financial_data['Turnover'] > 0) & (financial_data['Turnover'] < 5)] # 过滤周转率极端值
financial_data = financial_data[(financial_data['ROE'] > -0.5) & (financial_data['ROE'] < 0.5)] # 过滤ROE极端值
# 采样以简化展示
sampled_financial_data = financial_data.sample(n=min(1000, len(financial_data)), random_state=42) # 安全采样,防止数据不足
features_matrix = sampled_financial_data[['Margin', 'Turnover']] # 取回归树所需的两个特征
target_roe = sampled_financial_data['ROE'] # 回归目标变量9 基于树的方法
本章介绍用于回归和分类的基于树的方法。这些方法通过将预测变量空间分层或分割成若干简单区域来进行。为了对给定观测进行预测,我们通常使用该观测所属区域中训练观测的响应值均值或众数。由于用于分割预测变量空间的规则集可以总结为一棵树,这类方法被称为决策树方法。
基于树的方法简单且易于解释。然而,在预测精度方面,它们通常无法与第6章和第7章中看到的最佳监督学习方法相媲美。因此,本章我们还介绍了Bagging、随机森林、Boosting和贝叶斯加性回归树。这些方法都涉及产生多棵树,然后将其组合以产生单一的共识预测。我们将看到,组合大量树通常可以显著提高预测精度,代价是解释性有所降低。
9.1 决策树的基础
决策树可以同时应用于回归和分类问题。我们首先考虑回归问题,然后转向分类。
9.1.1 回归树
为了激发对回归树的学习,我们从一个金融分析的例子开始。
案例:预测上市公司净资产收益率 (ROE)
我们使用A股上市公司的财务数据,根据公司的销售净利率(Net Profit Margin)和资产周转率(Asset Turnover)来预测其净资产收益率(ROE)。这对应于经典的杜邦分析体系,我们期望看到这两个变量之间的非线性交互作用。
我们首先加载数据并选取部分具有代表性的公司(例如制造业公司)。
为了让你直观感受到回归树那近乎“白盒”式的透明与粗暴,以下 Python 代码从 A 股市场随机抽样了 1000 家公司,试图仅用两个最基础的财务比率(销售净利率、资产周转率)去锚定并预测它们的核心盈利能力(ROE)。我们调用了 sklearn 中的 DecisionTreeRegressor,并且为了让人眼能够轻松阅读,强制将这棵树的生长深度砍到了极其可怜的 max_depth=2。 当你看到下方输出的那张像倒置的树根一样的结构图时,你不需要任何高深的线性代数知识就能完美解读:这棵树在最顶端的“根节点”,用一个冷酷的阈值(比如净利率是否 <= 0.05)将所有公司一分为二;随后在第二层,它又结合了周转率的阈值进行了二次切割。最终落入最下方四个“叶子节点”的,就是被这套“连续 IF-ELSE 规则”筛选出来的不同群体的公司,而叶子节点中显示的 value 就是该群体 ROE 的平均预测值。没有任何隐藏的权重参数,没有任何黑盒的偏导数,一切判别逻辑就那样赤裸裸地印在图元的文本框里。
接下来,拟合回归树并可视化其决策规则。
# 拟合回归树(限制深度以便可视化)
regression_tree_model = DecisionTreeRegressor(max_depth=2, random_state=42) # 创建深度为2的回归树模型
regression_tree_model.fit(features_matrix, target_roe) # 在特征矩阵和ROE目标上训练模型
# 绘制决策树结构图
plt.figure(figsize=(12, 8)) # 设置画布大小
plot_tree(regression_tree_model, feature_names=['净利率', '周转率'], filled=True, rounded=True, # 绘制树结构,按预测值填色
fontsize=10, impurity=False, precision=3) # 隐藏不纯度指标,保留3位小数
plt.title('回归树: 基于杜邦分析预测ROE', fontsize=14) # 添加图表标题
plt.show() # 显示图表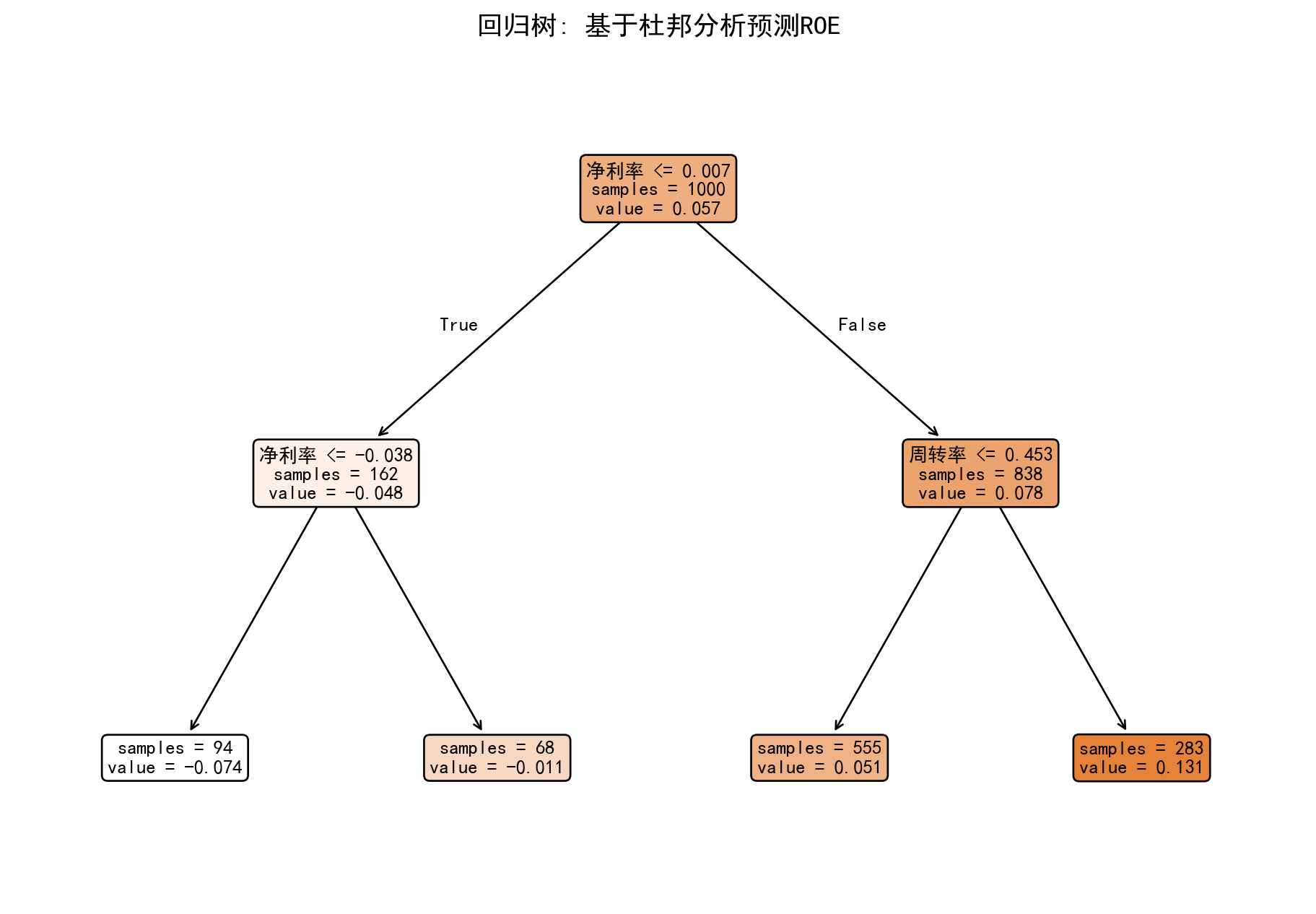
按照树的比喻,区域\(R_1, R_2, R_3\)被称为树的终端节点或叶子。在 图 9.1 中,我们可以看到树是如何根据”净利率”和”周转率”将公司分层的。
例如,典型的分割规则可能是:
- 如果 净利率 <= 0.05,则预测 ROE 较低。
- 如果 净利率 > 0.05 且 周转率 > 0.8,则预测 ROE 较高。
这直观地捕捉了”高利润率 x 高周转率 = 高ROE”的乘法关系(杜邦公式),用分段常数函数来逼近。对于分析师来说,这提供了一套清晰的”筛选规则”。
9.1.1.1 通过特征空间分层进行预测
我们现在讨论构建回归树的过程。粗略地说,有两个步骤:
我们将预测变量空间——即\(X_1, X_2, \ldots, X_p\)的可能值集合——分成\(J\)个不同且不重叠的区域,\(R_1, R_2, \ldots, R_J\)。
对于落入区域\(R_j\)的每个观测,我们进行相同的预测,即使用\(R_j\)中训练观测的响应均值。
例如,假设在步骤1中我们得到两个区域\(R_1\)和\(R_2\),第一个区域中训练观测的响应均值为10,第二个区域为20。那么对于给定观测\(X = x\),如果\(x \in R_1\),我们预测值为10;如果\(x \in R_2\),我们预测值为20。
如何构建区域?理论上,区域可以是任何形状。然而,我们选择将预测变量空间分成高维矩形或盒子,为了简单和便于解释所得到的预测模型。目标是找到盒子\(R_1, \ldots, R_J\),使残差平方和(RSS)最小化:
\[ \sum_{j=1}^{J} \sum_{i \in R_j} (y_i - \hat{y}_{R_j})^2 \tag{9.1}\]
其中\(\hat{y}_{R_j}\)是第\(j\)个盒子中训练观测的响应均值。
不幸的是,考虑将特征空间分成\(J\)个盒子的每种可能分区在计算上是不可行的。因此,我们采用一种自上而下、贪婪的方法,称为递归二元分割。该方法之所以是自上而下的,是因为它从树的顶部开始(此时所有观测属于单个区域),然后依次分割预测变量空间;每次分割由树下方两个新分支指示。它是贪婪的,因为在树构建过程的每一步,都会做出在该特定步骤最佳分割,而不是向前看并选择在未来的某个步骤中导致更好的树的分割。
提示:递归二元分割的直观理解
递归二元分割就像是在玩一个”20个问题”的游戏。在游戏中,你可以通过问最多20个是非题来猜出对方在想什么。为了最快地猜出答案,你应该在每个问题中尽可能地缩小可能性范围。类似地,递归二元分割在每个节点选择能够最大程度减少不确定性的分割。
这个过程的数学基础是:对于任何预测变量\(X_j\)和切割点\(s\),我们定义两个半平面: \[ R_1(j, s) = \{X | X_j < s\} \quad \text{和} \quad R_2(j, s) = \{X | X_j \geq s\} \]
我们寻求使下式最小化的\(j\)和\(s\): \[ \sum_{i:x_i \in R_1(j, s)} (y_i - \hat{y}_{R_1})^2 + \sum_{i:x_i \in R_2(j, s)} (y_i - \hat{y}_{R_2})^2 \]
其中\(\hat{y}_{R_1}\)和\(\hat{y}_{R_2}\)分别是\(R_1(j, s)\)和\(R_2(j, s)\)中训练观测的响应均值。
树剪枝
上述过程可能在训练集上产生良好的预测,但很可能过拟合数据,导致测试集性能不佳。这是因为生成的树可能太复杂。一个具有较少分割(即较少区域\(R_1, \ldots, R_J\))的较小树可能会以较低的方差和更好的解释性为代价,产生略高的偏差。
一种更好的策略是先生成一棵非常大的树\(T_0\),然后对其进行剪枝以获得子树。我们如何确定最佳剪枝方式?直观地说,我们的目标是选择测试误差率最低的子树。给定一个子树,我们可以使用交叉验证或验证集方法来估计其测试误差。
成本复杂度剪枝——也称为最弱链接剪枝——为我们提供了一种方法。我们不考虑每个可能的子树,而是考虑由非负调优参数\(\alpha\)索引的一系列树。对于每个\(\alpha\)值,对应一个子树\(T \subset T_0\),使得: \[ \sum_{m=1}^{|T|} \sum_{i:x_i \in R_m} (y_i - \hat{y}_{R_m})^2 + \alpha |T| \tag{9.2}\]
尽可能小。其中\(|T|\)表示树\(T\)的终端节点数量,\(R_m\)是对应于第\(m\)个终端节点的矩形(即预测变量空间的子集),\(\hat{y}_{R_m}\)是与\(R_m\)关联的预测响应——即\(R_m\)中训练观测的均值。
调优参数\(\alpha\)控制子树的复杂性与其对训练数据的拟合之间的权衡。当\(\alpha = 0\)时,子树\(T\)将简单地等于\(T_0\),因为此时(式 9.2)只衡量训练误差。然而,随着\(\alpha\)增加,拥有许多终端节点的树会有代价,因此(式 9.2)倾向于针对较小的子树最小化。
事实证明,当我们从零开始增加(式 9.2)中的\(\alpha\)时,分支以嵌套和可预测的方式从树中剪除,因此获得作为\(\alpha\)函数的整棵子树序列很容易。我们可以使用验证集或交叉验证来选择\(\alpha\)的值,然后返回完整数据集并获得对应于\(\alpha\)的子树。
9.1.2 分类树
分类树与回归树非常相似,只是它用于预测定性响应而不是定量响应。回顾一下,对于回归树,观测的预测响应由属于同一终端节点的训练观测的响应均值给出。相反,对于分类树,我们预测每个观测属于训练观测在所属区域中最常出现的类别。
在解释分类树的结果时,我们不仅对与特定终端节点区域关联的类别预测感兴趣,而且对落入该区域的训练观测的类别比例感兴趣。
分类树的误差度量
生长分类树的任务与生长回归树非常相似。正如在回归设置中一样,我们使用递归二元分割来生长分类树。然而,在分类设置中,RSS不能用作进行二元分割的标准。RSS的自然替代是分类误差率。由于我们计划将给定区域中的观测分配给该区域中最常出现的训练观测类别,因此分类误差率简单地就是该区域中不属于最常见类别的训练观测的比例:
\[ E = 1 - \max_k (\hat{p}_{mk}) \tag{9.3}\]
其中\(\hat{p}_{mk}\)表示第\(m\)区域中训练观测中属于第\(k\)类的比例。
然而,事实证明,对于树生长,分类误差不够敏感,在实践中,两种其他度量更可取。基尼指数定义为: \[ G = \sum_{k=1}^{K} \hat{p}_{mk}(1 - \hat{p}_{mk}) \tag{9.4}\]
这是\(K\)个类别中总方差的一个度量。不难看出,如果所有\(\hat{p}_{mk}\)都接近于0或1,则基尼指数取较小值。因此,基尼指数被称为节点纯度的一个度量——小值表示节点主要包含来自单个类别的观测。
基尼指数的替代方案是熵,由下式给出: \[ D = -\sum_{k=1}^{K} \hat{p}_{mk} \log \hat{p}_{mk} \tag{9.5}\]
由于\(0 \leq \hat{p}_{mk} \leq 1\),因此\(0 \leq -\hat{p}_{mk} \log \hat{p}_{mk}\)。可以证明,如果\(\hat{p}_{mk}\)都接近于0或接近于1,则熵将取接近于0的值。因此,与基尼指数一样,如果第\(m\)个节点是纯的,熵将取较小的值。事实上,基尼指数和熵在数值上非常相似。
数学推导:基尼指数与交叉熵的内在联系
从纯度函数(Impurity Function)的视角看,对于最常见的二分类问题,假设正类的比例为 \(p\),负类的比例为 \(1-p\)。 1. 基尼指数: \[ G(p) = p(1-p) + (1-p)p = 2p(1-p) \] 这实际上衡量了如果从该节点中随机抽取两个样本,它们碰巧属于不同类别的预期概率,也是二项分布方差的两倍。 2. 交叉熵: \[ D(p) = -p \log p - (1-p) \log (1-p) \] 从信息论的角度看,它计算的是节点中信息的“预期惊奇度(Surprisal)”或不确定性。
根据微积分中的泰勒展开(Taylor Expansion),当 \(p\) 在 1 附近时,自然对数可以进行一阶近似:\(\log p \approx p - 1\)。 将其近似代入交叉熵公式,我们可以得到:\(D(p) \approx -p(p-1) - (1-p)(-p) = p(1-p) + p(1-p) = 2p(1-p) = G(p)\)。
因此,基尼指数实际上是交叉熵的一个非常紧密且高效的一阶近似。由于基尼指数的计算仅涉及基础的乘法和加减法,而不像交叉熵那样需要计算底层的对数函数(\(\log\)),在构建大规模的随机森林或梯度提升树(通常涉及上百万次特征切分点的评估)时,基尼指数具有显著的计算速度优势。这就是为什么经典的CART算法以及
scikit-learn这样的工业级机器学习库默认选择基尼指数作为树分裂准则的底层原因。
注意:分类误差与节点纯度
虽然分类误差率直观上很自然,但它不是用于树生长的最佳标准。这是因为分类误差函数不连续——区域中类别比例的微小变化可能不会改变分类误差,但会显著改变基尼指数或熵。这使得基于分类误差的优化算法难以找到最佳分割点。因此,在实践中,我们使用基尼指数或熵来生长树,但在剪枝时可以使用分类误差率,如果最终剪枝树的预测准确性是目标的话。
案例:识别高盈利公司
我们继续使用上市公司的财务数据。这次的任务是分类:预测一家公司是否属于“高盈利”(定义为 ROE > 15%)。
图 9.2 显示了拟合的分类树。该树根据销售净利率、资产周转率和权益乘数(Assets/Equity)来区分高盈利公司。
在这个分类树的实战演示中,我们将连续的 ROE 预测问题,强行简化为了一个非黑即白的二分类命题:“这家公司到底算不算是一个净利润率极高(ROE > 15%)的优质印钞机?”。为了让决策树能玩出更复杂的花样,代码在销售净利率和资产周转率之外,又塞入了一个极其危险且带有巨大杠杆效应的财务指标——“权益乘数”(Leverage)。 输出的图表这一次挂上了更为清晰的分类标签(普通 vs 高盈利)。当你顺着图中不同的判定路径向下游走时,你会立刻发现这棵树不仅自己学会了杜邦分析的精髓,甚至还总结出了不同的“暴富路径”:比如左侧路径可能告诉你,净利率虽然低,但只要杠杆拉得足够大,依然能在最后关头跃入“高盈利”的叶子;而右侧路径则在警告,即便利润率看似不错,但如果周转率慢如蜗牛且杠杆极低,最终也只能是一个平庸的企业。相比于逻辑回归那生长的系数堆积,分类树给出的这种“多条件组合判定”报告,简直是写给人类业务专家看的完美决策流程图。
from sklearn.tree import DecisionTreeClassifier, plot_tree # 分类树模型与可视化
from sklearn.metrics import accuracy_score # 准确率评估
# 接续上文数据 (sampled_financial_data),构造二分类目标
sampled_financial_data['High_ROE'] = (sampled_financial_data['ROE'] > 0.15).astype(int) # ROE>15%标记为高盈利(1),否则为普通(0)
# 增加一个特征: 权益乘数 (Leverage = Total Assets / Equity)
# 注意: 杜邦公式 ROE = Margin × Turnover × Leverage
sampled_financial_data['Leverage'] = sampled_financial_data['total_assets'] / sampled_financial_data['equity_parent_company'] # 计算权益乘数(财务杠杆)
# 清洗 Leverage 异常值
sampled_financial_data = sampled_financial_data[sampled_financial_data['Leverage'] < 10] # 剔除杠杆倍数超过10的极端样本
# 准备分类模型的特征和目标
classification_features = sampled_financial_data[['Margin', 'Turnover', 'Leverage']] # 选取三个杜邦因子作为特征
high_roe_target = sampled_financial_data['High_ROE'] # 二分类目标变量
# 拟合基尼准则的分类树(限制深度为3以保持可读性)
classification_tree_model = DecisionTreeClassifier(max_depth=3, random_state=42, criterion='gini') # 初始化分类树
classification_tree_model.fit(classification_features, high_roe_target) # 训练分类树
# 绘制分类树结构图
plt.figure(figsize=(14, 10)) # 设置画布大小
plot_tree(classification_tree_model, # 绘制树结构
feature_names=['净利率', '周转率', '杠杆'], # 指定特征中文名称
class_names=['普通', '高盈利'], # 指定类别标签
filled=True, # 按类别填色
rounded=True, # 圆角节点框
fontsize=10) # 设置字体大小
plt.title('分类树: 识别高盈利公司 (ROE > 15%)', fontsize=14) # 添加图表标题
plt.show() # 显示图表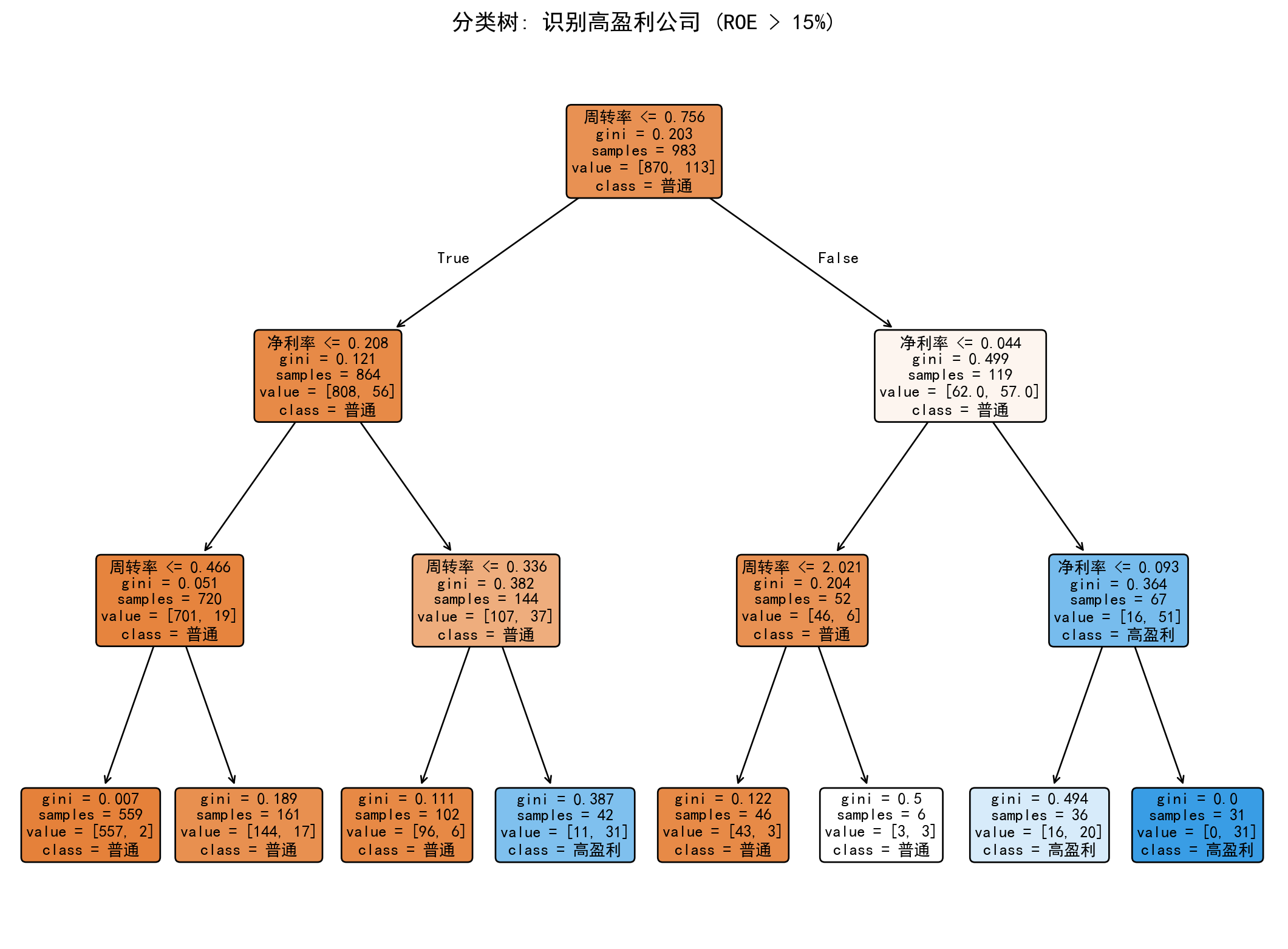
图 9.2 揭示了成为”高盈利公司”的不同路径。例如,最左边的路径可能显示”低净利率”通常导致非高盈利;而右边的路径可能显示,即使净利率适中,如果”周转率”极高(如零售业),也可能达到高ROE。这完美体现了杜邦分析的逻辑。
9.1.3 树与线性模型的比较
回归和分类树与第3章和第4章中介绍的更经典的回归和分类方法有很大的不同。特别是,线性回归假设具有以下形式的模型: \[ f(X) = \beta_0 + \sum_{j=1}^{p} X_j \beta_j \tag{9.6}\]
而回归树假设具有以下形式的模型: \[ f(X) = \sum_{m=1}^{M} c_m \cdot 1(X \in R_m) \tag{9.7}\]
其中\(R_1, \ldots, R_M\)表示特征空间的划分,如 图 9.1 所示。
哪个模型更好?这取决于手头的问题。如果特征与响应之间的关系可以很好地由线性模型如(式 9.6)近似,那么线性回归等方法可能会很好地工作,并且将性能优于不利用这种线性结构的回归树。相反,如果特征和响应之间存在高度非线性和复杂的关系,如模型(式 9.7)所示,那么决策树可能优于经典方法。
提示:何时使用树模型?
树模型在以下情况下特别有用:
- 非线性关系: 当预测变量与响应之间存在复杂的非线性交互作用时
- 混合变量类型: 当预测变量既有定量变量又有定性变量时(树可以自然地处理定性变量,无需创建虚拟变量)
- 可解释性优先: 当模型的解释性比预测精度更重要时
- 缺失值处理: 树可以自然地处理缺失值
- 异常值鲁棒性: 树对异常值相对鲁棒
线性模型在以下情况下更合适:
- 线性关系: 当关系近似线性时
- 高维稀疏数据: 当\(p \gg n\)时
- 预测精度优先: 当目标是最大化预测精度时
- 外推: 当需要在训练数据范围之外进行预测时(树无法很好地外推)
9.1.4 树的优缺点
用于回归和分类的决策树相对于第3章和第4章中看到的更经典的方法具有许多优点:
- 易于解释: 树非常容易向人们解释。事实上,它们甚至比线性回归更容易解释!
- 直观性: 有些人认为决策树更接近人类的决策制定,而不是之前章节中看到的回归和分类方法。
- 可视化: 树可以图形化显示,并且很容易被非专家解释(尤其是如果它们很小)。
- 处理定性变量: 树可以轻松处理定性预测变量,而无需创建虚拟变量。
遗憾的是,树通常不具有与本书中看到的其他一些回归和分类方法相同的预测精度水平。此外,树可能非常不稳定。换句话说,数据的微小变化可能导致最终估计树的巨大变化。
然而,通过聚合许多决策树,使用Bagging、随机森林和Boosting等方法,可以显著提高树的预测性能。我们将在下一节介绍这些概念。
9.2 Bagging、随机森林、Boosting和贝叶斯加性回归树
集成方法是一种将许多简单的”构建块”模型组合起来,以获得单一且可能非常强大的模型的方法。这些简单的构建块模型有时被称为弱学习器,因为它们单独可能产生平庸的预测。
我们现在讨论Bagging、随机森林、Boosting和贝叶斯加性回归树。这些是集成方法,其简单的构建块是回归或分类树。
9.2.1 Bagging
自助法,在第5章中介绍,是一个非常强大的思想。它在许多难以甚至不可能直接计算感兴趣量的标准差的情况下使用。我们在这里看到,自助法可以在完全不同的上下文中使用,以提高统计学习方法(如决策树)的性能。
第8.1节中讨论的决策树具有高方差。这意味着如果我们将训练数据随机分成两部分,并对这两半都拟合决策树,我们得到的结果可能非常不同。相比之下,低方差的过程如果应用于不同的数据集,将产生相似的结果;如果\(n\)对\(p\)的比率适中,线性回归往往具有低方差。
Bootstrap聚合或Bagging,是一种用于降低统计学习方法方差的一般用途方法;我们在这里介绍它,因为它特别有用,并且经常在决策树的上下文中使用。
回顾一下,给定\(n\)个独立观测\(Z_1, \ldots, Z_n\),每个方差为\(\sigma^2\),观测均值的方差为\(\sigma^2/n\)。换句话说,平均一组观测会降低方差。因此,降低统计学习方法的方差并增加测试集准确性的一种自然方法是:从总体中获取许多训练集,使用每个训练集构建单独的预测模型,然后平均结果预测。
提示:为什么Bagging能降低方差?
Bagging之所以能降低方差,是因为样本均值的方差等于总体方差除以样本大小:\(\text{Var}(\bar{Z}) = \sigma^2/n\)。这意味着如果我们有\(B\)个独立的训练集,拟合\(B\)个模型\(\hat{f}^1(x), \ldots, \hat{f}^B(x)\),然后平均它们: \[ \hat{f}_{\text{avg}}(x) = \frac{1}{B} \sum_{b=1}^{B} \hat{f}^b(x) \]
那么平均的方差将是单个模型方差的\(1/B\)(如果模型独立的话)。即使我们使用自助样本导致模型不完全独立,Bagging仍然可以显著降低方差。
当然,这是不实际的,因为我们通常无法访问多个训练集。相反,我们可以使用自助法,从(单个)训练数据集中重复采样。在这种方法中,我们生成\(B\)个不同的自助训练数据集。我们在第\(b\)个自助训练集上训练我们的方法以得到\(\hat{f}^{*b}(x)\),最后平均所有预测以获得: \[ \hat{f}_{\text{bag}}(x) = \frac{1}{B} \sum_{b=1}^{B} \hat{f}^{*b}(x) \]
这称为Bagging。
虽然Bagging可以提高许多回归方法的预测,但它对决策树特别有用。要对回归树应用Bagging,我们简单地使用\(B\)个自助训练集构建\(B\)个回归树,然后平均结果预测。这些树生长得很深,并且不被剪枝。因此,每棵单独的树具有高方差,但偏差低。平均这\(B\)棵树会降低方差。
袋外误差估计
事实证明,有一种非常直接的方法可以估计Bagged模型的测试误差,而无需执行交叉验证或验证集方法。回顾一下,Bagging的关键是树被重复拟合到观测的自助子集。可以证明,平均而言,每棵Bagged树使用大约三分之二的观测。未被用来拟合给定Bagged树的三分之一观测被称为袋外(OOB)观测。
我们可以使用每棵树中该观测为OOB的树来预测第\(i\)个观测的响应。这将产生第\(i\)个观测的大约\(B/3\)个预测。为了获得第\(i\)个观测的单个预测,我们可以平均这些预测响应(如果回归是目标),或者可以采用多数投票(如果分类是目标)。这导致第\(i\)个观测的单个OOB预测。可以对所有\(n\)个观测中的每一个以这种方式获得OOB预测,从中可以计算整体OOB MSE(对于回归问题)或分类误差(对于分类问题)。得到的OOB误差是Bagged模型测试误差的有效估计。
9.2.2 随机森林
随机森林通过一种称为去相关的小调整提供了对Bagged树的改进。如在Bagging中一样,我们在自助训练样本上构建许多决策树。但是,在构建这些决策树时,每次考虑树中的分割时,从完整的\(p\)个预测变量集中选择\(m\)个预测变量的随机样本作为分割候选。只允许分割使用这\(m\)个预测变量之一。每次分割时都会抽取一个新的\(m\)个预测变量样本,通常我们选择\(m \approx \sqrt{p}\)——即每次分割时考虑的预测变量数量大约等于总预测变量数量的平方根。
换句话说,在构建随机森林时,算法甚至不允许考虑大多数可用的预测变量。这听起来很疯狂,但它有一个巧妙的理由。假设数据集中有一个非常强的预测变量,以及其他一些中等强度的预测变量。那么在Bagged树的集合中,大多数或所有树都将在顶部分割中使用这个强预测变量。因此,所有Bagged树看起来都非常相似。因此,Bagged树的预测将高度相关。不幸的是,平均许多高度相关的量不会像平均许多不相关的量那样导致方差的很大降低。
随机森林通过强制每次分割只考虑预测变量的子集来克服这个问题。因此,平均而言,\((p-m)/p\)的分割甚至不会考虑强预测变量,因此其他预测变量将有更多的机会。我们可以将这个过程视为去相关树,从而使得到的树的平均方差更小,因此更可靠。
Bagging和随机森林之间的主要区别在于预测变量子集大小\(m\)的选择。例如,如果使用\(m=p\)构建随机森林,那么这简单地等同于Bagging。在许多应用中,随机森林使用\(m=\sqrt{p}\)导致比Bagging更低的测试误差。
9.2.3 Boosting
我们现在讨论Boosting,这是提高决策树预测结果的另一种方法。像Bagging一样,Boosting是一种可以应用于许多统计学习方法的回归或分类的一般方法。这里我们将Boosting的讨论限制在决策树的上下文中。
回顾一下,Bagging涉及创建原始训练数据集的多个副本,使用自助法对每个副本拟合单独的决策树,然后组合所有树以创建单个预测模型。值得注意的是,每棵树都是在自助数据集上构建的,独立于其他树。
Boosting的工作方式类似,只是树是顺序生长的:每棵树都使用以前生长的树的信息生长。Boosting不涉及自助采样;相反,每棵树都拟合原始数据集的修改版本。
我们首先考虑回归设置。像Bagging一样,Boosting涉及组合大量的决策树\(\hat{f}^1, \ldots, \hat{f}^B\)。Boosting在算法8.1中描述。
提示:Boosting的直观理解
Boosting的核心思想是”慢速学习”。与其拟合一个单一的大决策树(这可能过拟合),Boosting慢慢学习:给定当前模型,我们将一棵决策树拟合到当前模型的残差。也就是说,我们使用当前残差而不是结果\(Y\)作为响应来拟合树。然后我们将这棵新的决策树添加到拟合函数中以更新残差。
每棵这些树可以相当小,只有几个终端节点,由参数\(d\)控制。通过将小树拟合到残差,我们在模型表现不佳的区域慢慢改进\(\hat{f}\)。收缩参数\(\lambda\)进一步减慢这个过程,允许更多和形状不同的树来攻击残差。
一般来说,统计学习方法学习慢的往往表现良好。注意,在Boosting中,与Bagging不同,每棵树的构造强烈依赖于已经生长的树。
算法8.1:用于回归树的Boosting
- 设\(\hat{f}(x) = 0\),\(r_i = y_i\)对所有训练集中的\(i\)
- 对于\(b = 1, 2, \ldots, B\):
- 使用\(d\)个分割将树\(\hat{f}^b\)拟合到训练数据\((X, r)\)
- 通过添加新树的收缩版本来更新\(\hat{f}\): \[ \hat{f}(x) \leftarrow \hat{f}(x) + \lambda \hat{f}^b(x) \]
- 更新残差: \[ r_i \leftarrow r_i - \lambda \hat{f}^b(x_i) \]
- 输出Boosted模型: \[ \hat{f}(x) = \sum_{b=1}^{B} \lambda \hat{f}^b(x) \]
Boosting有三个调优参数:
- 树的数量\(B\)。与Bagging和随机森林不同,如果\(B\)太大,Boosting可能会过拟合,尽管这种过拟合往往发生得很慢(如果有的话)。我们使用交叉验证来选择\(B\)。
- 收缩参数\(\lambda\),一个小的正数。这控制Boosting的学习率。典型值是0.01或0.001,正确的选择可能取决于问题。非常小的\(\lambda\)可能需要使用非常大的\(B\)值才能获得良好的性能。
- 每棵树中的分割数量\(d\),它控制Boosting集成的复杂性。通常\(d=1\)效果很好,在这种情况下每棵树是一个树桩,由单个分割组成。在这种情况下,Boosted集成实际上是拟合一个可加模型,因为每一项只涉及单个变量。更一般地,\(d\)是交互深度,控制Boosted模型的交互阶数,因为\(d\)个分割最多可以涉及\(d\)个变量。
9.2.4 贝叶斯加性回归树
最后,我们讨论贝叶斯加性回归树(BART),另一种使用决策树作为构建块的集成方法。为简单起见,我们针对回归(而不是分类)介绍BART。
回顾一下,Bagging和随机森林从平均回归树进行预测,每棵树都使用数据和/或预测变量的随机样本构建。每棵树与其他树分开构建。相反,Boosting使用树的加权和,每棵树都通过拟合当前拟合的残差来构造。因此,每棵新树都试图捕获当前模型集尚未考虑的信号。
BART与这两种方法都有关:每棵树以随机方式构建,如Bagging和随机森林,每棵树都试图捕获当前模型尚未考虑的信号,如Boosting。
BART的主要新颖性在于生成新树的方式。BART让\(K\)表示回归树的数量,\(B\)表示运行BART算法的迭代次数。\(\hat{f}^b_k(x)\)表示第\(b\)次迭代中使用的第\(k\)个回归树在\(x\)处的预测。在每次迭代结束时,来自该迭代的\(K\)树将被求和,即\(\hat{f}^b(x) = \sum_{k=1}^{K} \hat{f}^b_k(x)\),对于\(b = 1, \ldots, B\)。
在BART算法的第一次迭代中,所有树都被初始化为具有单个根节点,\(\hat{f}^1_k(x) = \frac{1}{nK} \sum_{i=1}^{n} y_i\),即响应值的均值除以树的总数。因此,\(\hat{f}^1(x) = \sum_{k=1}^{K} \hat{f}^1_k(x) = \frac{1}{n} \sum_{i=1}^{n} y_i\)。
在随后的迭代中,BART一次更新一棵树。在第\(b\)次迭代中,要更新第\(k\)棵树,我们从每个响应值中减去除第\(k\)棵树之外的所有树的预测,以获得部分残差: \[ r_i = y_i - \sum_{k' < k} \hat{f}^b_{k'}(x_i) - \sum_{k' > k} \hat{f}^{b-1}_{k'}(x_i) \]
然后,BART不是从当前部分残差拟合一棵新树,而是随机选择从前一次迭代的树(\(\hat{f}^{b-1}_k\))的一组可能扰动之一,倾向于改善对部分残差的拟合。
有两种扰动:
- 我们可以通过添加或修剪分支来改变树的结构
- 我们可以改变树的每个终端节点中的预测
BART的输出是一系列预测模型\(\hat{f}^b(x) = \sum_{k=1}^{K} \hat{f}^b_k(x)\),对于\(b = 1, 2, \ldots, B\)。我们通常丢弃前几个预测模型,因为在早期迭代中获得的模型——称为预烧期——往往不能提供非常好的结果。我们让\(L\)表示预烧迭代次数;例如,我们可能取\(L = 200\)。然后,为了获得单个预测,我们只需取预烧迭代后的平均值: \[ \hat{f}(x) = \frac{1}{B - L} \sum_{b = L + 1}^{B} \hat{f}^b(x) \]
9.2.5 案例研究: 预测公司ROE的集成方法比较
我们使用之前加载的上市公司数据来比较不同的树方法在预测ROE方面的表现。为了增加任务难度和真实性,我们将引入更多预测变量,包括规模因子和杠杆因子。
我们将比较以下方法:
- 单棵回归树
- Bagging (使用所有特征)
- 随机森林 (使用特征子集)
- Boosting (梯度提升树)
图 9.3 显示了不同方法在测试集上的均方误差(MSE)。
为了让你对基于树的经典集成家族(Ensemble Methods)的威力有一个真实的体感,这段代码在稍早前杜邦分析的基础上,发起了一场“预测 A 股公司 ROE(净资产收益率)”的华山论剑。除了原先的净利率和周转率,我们又拉入了财务杠杆(Leverage)和总资产对数(Log_Assets,代表公司规模效应)作为新武器。整个战场被划分为 70% 的训练集和 30% 的盲测集。 代码中依次登场的四大门派分别是:
- 单棵回归树(DecisionTreeRegressor):单打独斗,容易因为过度学习训练集细节而导致过拟合的高方差模型。
- Bagging(RandomForestRegressor,
max_features=None):通过自助重抽样(Bootstrap)重抽样手段生成 100 棵长得完全不同的高规格深树,保留所有分裂特征,最后将它们的预测结果进行最简单的平均池化,以暴力压制方差。 - 随机森林(RandomForestRegressor,
max_features='sqrt'):在 Bagging 的基础上加入了“特征子空间随机化”机制(每次节点分裂只允许在部分随机特征中挑选),这极其精妙地打破了树与树之间因为某些强势特征(比如净利率)而产生的强同质化相关性,往往能获得更加稳健的预测。 - Boosting(GradientBoostingRegressor):完全不同于上面并行的和稀泥逻辑,这是一条串行学习的修罗之道。它用 100 棵极浅的“树桩”(
max_depth=3),踏着前一棵树犯下的残差错误,以步步为营的学习率(learning_rate=0.1)逐渐逼近真相。
运行后弹出的那张柱状对比图,将极其生动地向你展示:集成算法是如何通过群体智慧,在毫无悬念地碾压单棵决策树的同时,还展现出各自细微的性能差异。
import numpy as np # 数值计算基础库
import pandas as pd # 表格数据处理库
import matplotlib.pyplot as plt # 数据可视化绑定
from sklearn.tree import DecisionTreeRegressor # 回归树模型
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor # 随机森林与梯度提升回归
from sklearn.model_selection import train_test_split # 训练/测试集划分
from sklearn.metrics import mean_squared_error # 均方误差评估
# 重新加载全量数据以确保足够样本用于集成学习训练
import os # 跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
path = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 拼接财务报表文件路径
financial_data_all = pd.read_hdf(path) # 读取全量财务报表数据
# 构造杜邦分析所需的财务比率特征
financial_data_all['Margin'] = financial_data_all['net_profit'] / financial_data_all['operating_revenue'] # 计算销售净利率
financial_data_all['Turnover'] = financial_data_all['operating_revenue'] / financial_data_all['total_assets'] # 计算资产周转率
financial_data_all['Lev'] = financial_data_all['total_assets'] / financial_data_all['equity_parent_company'] # 计算权益乘数(财务杠杆)
financial_data_all['Log_Assets'] = np.log(financial_data_all['total_assets'] + 1) # 对数化总资产以捕捉规模效应
financial_data_all['ROE'] = financial_data_all['net_profit'] / financial_data_all['equity_parent_company'] # 计算净资产收益率数据加载和特征构造完毕后,接下来对数据进行清洗与异常值过滤,并划分训练集与测试集,为后续四种模型的公平对比做好准备。
# 清洗(仅对分析列去除inf和NaN,避免全表dropna丢弃过多行)
analysis_cols = ['Margin', 'Turnover', 'Lev', 'Log_Assets', 'ROE'] # 分析所需的特征列
financial_data_all[analysis_cols] = financial_data_all[analysis_cols].replace([np.inf, -np.inf], np.nan) # 仅分析列中的inf替换为NaN
cleaned_financial_data = financial_data_all.dropna(subset=analysis_cols) # 仅按分析列去除缺失值
cleaned_financial_data = cleaned_financial_data[ # 定义cleaned_financial_data变量
(cleaned_financial_data['Margin'].between(-0.5, 0.5)) & # 过滤净利率极端值
(cleaned_financial_data['Turnover'].between(0, 5)) & # 过滤周转率极端值
(cleaned_financial_data['Lev'].between(1, 10)) & # 过滤杠杆倍数极端值
(cleaned_financial_data['ROE'].between(-0.5, 0.5)) # 过滤ROE极端值
] # 执行数据处理操作
# 采样2000个样本(安全采样,防止数据不足)
modeling_data = cleaned_financial_data.sample(n=min(2000, len(cleaned_financial_data)), random_state=42) # 随机抽取建模子样本
features_matrix_all = modeling_data[['Margin', 'Turnover', 'Lev', 'Log_Assets']] # 提取四维特征矩阵
target_roe_all = modeling_data['ROE'] # 提取ROE目标向量
# 分割为训练集(70%)和测试集(30%)
features_train, features_test, target_train, target_test = train_test_split(features_matrix_all, target_roe_all, test_size=0.3, random_state=42) # 随机划分训练/测试集接下来,分别训练四种树方法并计算测试集均方误差。
# 1. 单棵回归树(无限制深度,高方差基线模型)
single_regression_tree = DecisionTreeRegressor(random_state=42) # 初始化单棵回归树
single_regression_tree.fit(features_train, target_train) # 在训练集上拟合模型
single_tree_mse = mean_squared_error(target_test, single_regression_tree.predict(features_test)) # 计算测试集MSE
# 2. Bagging(使用RandomForestRegressor但max_features=None,即每次分裂使用全部特征)
bagging_model = RandomForestRegressor(n_estimators=100, max_features=None, random_state=42) # 初始化Bagging模型(100棵树)
bagging_model.fit(features_train, target_train) # 训练Bagging集成
bagging_model_mse = mean_squared_error(target_test, bagging_model.predict(features_test)) # 计算测试集MSE
# 3. 随机森林(max_features='sqrt'实现特征子空间随机化去相关)
random_forest_model = RandomForestRegressor(n_estimators=100, max_features='sqrt', random_state=42) # 初始化随机森林
random_forest_model.fit(features_train, target_train) # 训练随机森林
random_forest_mse = mean_squared_error(target_test, random_forest_model.predict(features_test)) # 计算测试集MSE
# 4. Boosting(梯度提升树:串行残差学习)
boosting_model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) # 初始化梯度提升模型
boosting_model.fit(features_train, target_train) # 训练梯度提升集成
boosting_model_mse = mean_squared_error(target_test, boosting_model.predict(features_test)) # 计算测试集MSE最后,将四种方法的测试集MSE以柱状图进行可视化对比。
# 准备可视化数据
methods = ['单棵树', 'Bagging', '随机森林', 'Boosting'] # 四种方法的中文标签
mse_values = [single_tree_mse, bagging_model_mse, random_forest_mse, boosting_model_mse] # 对应的MSE值列表
plt.figure(figsize=(10, 6)) # 设置画布大小
bars = plt.bar(methods, mse_values, color=['#E3120B', '#2C3E50', '#008080', '#F0A700']) # 绘制柱状图,每种方法使用不同颜色
plt.title('ROE预测: 不同树方法的测试集MSE比较', fontsize=14) # 添加图表标题
plt.ylabel('均方误差 (MSE)', fontsize=12) # 设置Y轴标签
plt.xlabel('方法', fontsize=12) # 设置X轴标签
# 在柱子上添加数值标签
for bar, value in zip(bars, mse_values): # 遍历每个柱子和对应MSE值
height = bar.get_height() # 获取柱子高度
plt.text(bar.get_x() + bar.get_width()/2., height, # 在柱顶居中位置添加文本
f'{value:.4f}', # 格式化为4位小数
ha='center', va='bottom', fontsize=10) # 水平居中、底部对齐
plt.grid(axis='y', alpha=0.3) # 添加Y轴网格线
plt.tight_layout() # 自动调整布局防止标签重叠
plt.show() # 显示图表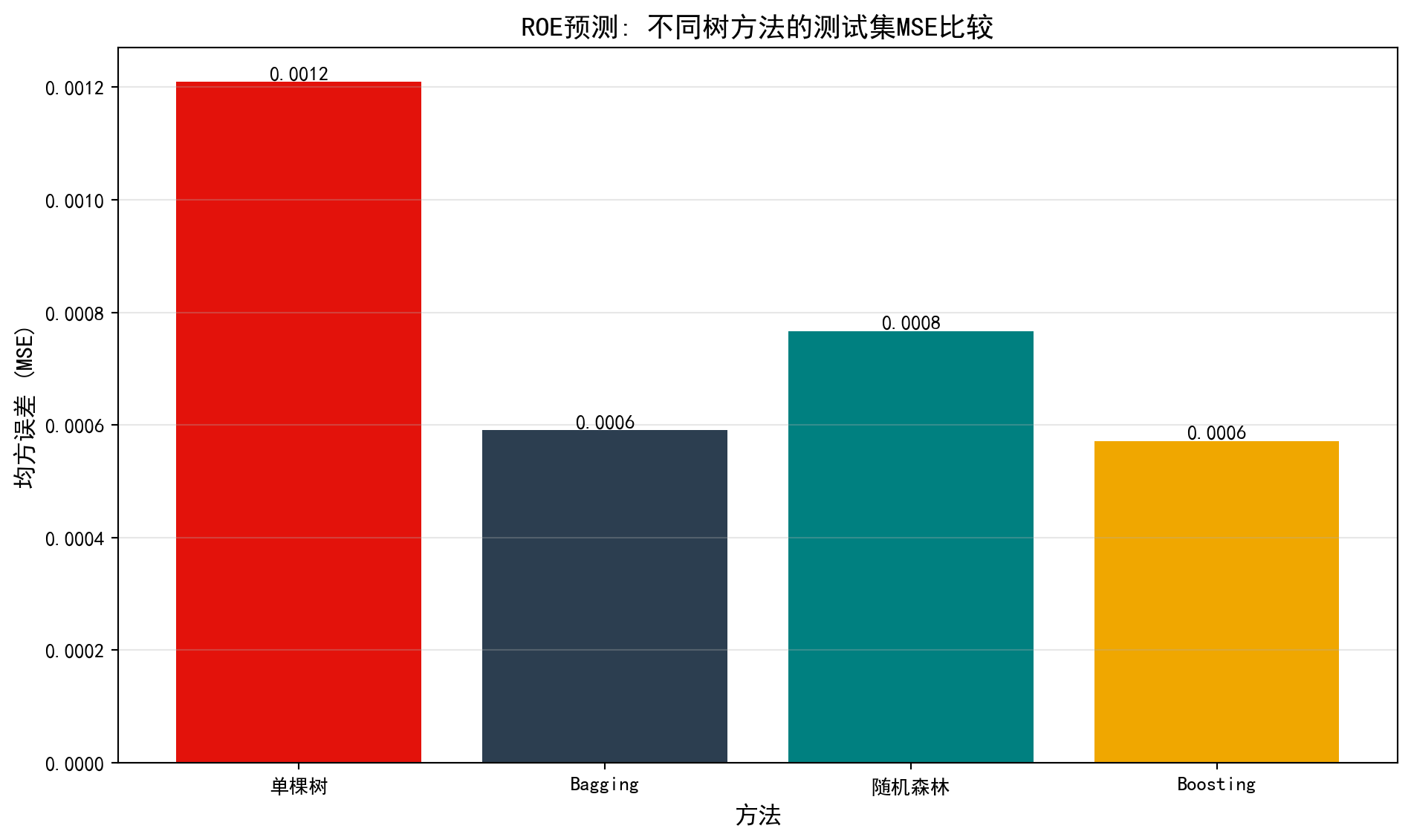
如 图 9.3 所示, 集成方法通常优于单棵树。在这个特定的杜邦分析案例中,由于特征之间存在强乘法交互(\(ROE = Margin \times Turnover \times Leverage\)),树模型通过分层捕捉这种非线性的能力特别有用。Boosting 往往能进一步挖掘细微的残差模式。
9.2.6 案例研究: 随机森林与 XGBoost 预测 A 股涨跌
在金融量化领域,树集成方法由于能天然捕捉非线性关系、免疫单调特征变换(无需由于极端值进行截尾或标准化处理)而深受喜爱。在这个分类案例中,我们将应用随机森林和当前工业界最为流行的大规模可并行梯度提升框架 XGBoost(eXtreme Gradient Boosting),来预测 A 股市场某只代表性股票(例如海康威视 002415.XSHE)的未来涨跌方向。
XGBoost 通过对损失函数直接进行二阶泰勒展开优化(利用了Hessian信息),并显式地在目标函数中引入结构风险惩罚项(即对树的叶子节点数量和叶子节点权重分数的正则化),从而在非线性提取能力和抗过拟合能力之间取得了极佳的理论平衡。
我们将使用前几天的历史收益率、波动率和成交量特征来预测下一天的收益率方向(1 代表上涨,0 代表下跌或平盘)。在时间序列数据上,我们会使用时间前向切分以避免数据泄露。
在真实且残酷的量化交易实盘中,数据科学家们显然不满足于仅仅解释过去。在这最后一段压轴的大型实战代码里,我们将目标锁定在了地狱级难度的问题上:利用 A 股某标的(如海康威视)过去几天的历史收益率、波动率衰减以及成交量的边际变化,去直接对赌它明天是涨还是跌。为了防止“偷看未来”这种低级错误,我们在通过 train_test_split 切分数据时,极其严格地采用了时间前向顺序切分(保留最末尾的 30% 作为无人知晓的最后测试)。 在这里,除了老将随机森林,我们还引入了当今 Kaggle 竞赛圈和华尔街量化界防守反击的绝对大杀器——XGBoost。针对金融时间序列那种令人绝望的极低信噪比(几乎到处都是随机游走噪音),代码在初始化 XGBoost 实例时显得极其克制与谨慎:极浅的树深(max_depth=3)、极其缓慢的学习率(learning_rate=0.01),并且同时并开启了行抽样(subsample=0.8)与列抽样(colsample_bytree=0.8)。这种双管齐下的强力正则化机制,旨在最大程度上阻止模型去死记硬背那些毫无意义的短线市场噪音。 请格外关注输出的评价指标与右侧的特征重要性条形图。在股票涨跌完全独立且同分布的假象下,能把样本外的测试集 AUC 艰难地推离 0.5 这个抛硬币生死线哪怕只有 1 到 2 个百分点,在实际应用中都可能对应着真金白银的巨额夏普比率提升。
import numpy as np # 数值计算基础库
import pandas as pd # 表格数据处理库
import matplotlib.pyplot as plt # 数据可视化绑定
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import accuracy_score, roc_auc_score # 准确率与 AUC 评估
import warnings # 警告控制模块
warnings.filterwarnings('ignore') # 关闭冗余警告信息
try: # 异常处理开始
import xgboost as xgb # XGBoost 极端梯度提升框架
HAS_XGB = True # 标记 xgboost 可用
except ImportError: # 捕获异常
HAS_XGB = False # 标记 xgboost 不可用
print('Warning: xgboost is not installed. Using GradientBoostingClassifier as fallback.') # 提示用户将使用sklearn替代
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升分类作为后备
# 取消中文字体警告
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans'] # 设置中文显示字体列表
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号Warning: xgboost is not installed. Using GradientBoostingClassifier as fallback.加载海康威视(002415.XSHE)的前复权日度行情数据,构建滞后收益率、短期波动率和成交量变化等技术特征,并按时间前向顺序切分训练集和测试集。
import os # 跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
path = os.path.join(DATA_DIR, 'stock/stock_price_pre_adjusted.h5') # 拼接前复权股价文件路径
stock_price_data = pd.read_hdf(path) # 读取前复权股价数据
if 'order_book_id' in stock_price_data.index.names: # 若order_book_id在索引中则重置为普通列
stock_price_data = stock_price_data.reset_index() # 重置索引以便按列筛选
# 选择海康威视作为代表性标的
stock_price_data = stock_price_data[stock_price_data['order_book_id'] == '002415.XSHE'].copy() # 筛选海康威视行情
stock_price_data = stock_price_data.sort_values('date') # 按日期升序排列确保时序正确
# 构建金融特征
stock_price_data['Ret'] = stock_price_data['close'].pct_change() # 计算日收益率
stock_price_data['Target'] = (stock_price_data['Ret'].shift(-1) > 0).astype(int) # 目标变量:明天是否上涨(1=涨,0=不涨)
# 滞后收益率特征(过去1-3天的收益率)
for i in range(1, 4): # 循环生成Lag_1到Lag_3
stock_price_data[f'Lag_{i}'] = stock_price_data['Ret'].shift(i) # 第i日的滞后收益率
# 波动率与成交量特征
stock_price_data['Vol_5'] = stock_price_data['Ret'].rolling(5).std() # 过去5日收益率的滚动标准差(短期波动率)
stock_price_data['Vol_Change'] = stock_price_data['volume'].pct_change() # 成交量环比变化率
# 清洗空值和无穷值(pct_change在前值为0时会产生inf)
stock_price_data = stock_price_data.replace([np.inf, -np.inf], np.nan).dropna() # 先替换inf为NaN再统一去除
features_list = [f'Lag_{i}' for i in range(1, 4)] + ['Vol_5', 'Vol_Change'] # 定义特征列名列表
# 时间序列前向切分(70%训练,30%测试,严格保持时间顺序)
split_idx = int(len(stock_price_data) * 0.7) # 计算70%分界点索引
train_stock_data = stock_price_data.iloc[:split_idx] # 前70%作为训练集
test_stock_data = stock_price_data.iloc[split_idx:] # 后30%作为测试集
stock_features_train = train_stock_data[features_list].values # 提取训练集特征矩阵
stock_target_train = train_stock_data['Target'].values # 提取训练集目标向量
stock_features_test = test_stock_data[features_list].values # 提取测试集特征矩阵
stock_target_test = test_stock_data['Target'].values # 提取测试集目标向量接下来,训练随机森林和 XGBoost 分类模型。
# 2. 训练分类模型
models = {} # 初始化空字典,用于存储模型名称与实例的映射
# 随机森林分类器(300棵树,限制深度为5防止过拟合)
rf_classifier = RandomForestClassifier(n_estimators=300, max_depth=5, max_features='sqrt', random_state=42) # 初始化随机森林
rf_classifier.fit(stock_features_train, stock_target_train) # 在训练集上拟合随机森林
models['Random Forest'] = rf_classifier # 将训练好的随机森林存入模型字典
# XGBoost(或梯度提升作为后备方案)
if HAS_XGB: # 若xgboost已安装则使用XGBClassifier
xgboost_classifier = xgb.XGBClassifier( # 定义xgboost_classifier变量
n_estimators=300, # 迭代300轮
max_depth=3, # 极浅的树深度(强正则化)
learning_rate=0.01, # 极低学习率防止过拟合
subsample=0.8, # 行抽样比例80%
colsample_bytree=0.8, # 列抽样比例80%
random_state=42, # 固定随机种子
eval_metric='logloss' # 使用对数损失作为评估指标
) # 完成构建
xgboost_classifier.fit(stock_features_train, stock_target_train) # 训练XGBoost模型
models['XGBoost'] = xgboost_classifier # 存入模型字典
else: # 若xgboost未安装则使用sklearn的GradientBoostingClassifier
gradient_boosting_classifier = GradientBoostingClassifier(n_estimators=300, max_depth=3, learning_rate=0.01, random_state=42) # 初始化梯度提升分类器
gradient_boosting_classifier.fit(stock_features_train, stock_target_train) # 训练梯度提升模型
models['Gradient Boosting'] = gradient_boosting_classifier # 存入模型字典接下来,评估两个模型的测试集表现并可视化特征重要性。
# 3. 评估与可视化
plt.figure(figsize=(14, 6)) # 创建宽幅画布用于并排展示
for i, (name, model) in enumerate(models.items()): # 遍历所有已训练模型
# 预测概率用于计算AUC
y_pred_proba = model.predict_proba(stock_features_test)[:, 1] # 获取正类(上涨)的预测概率
y_pred = model.predict(stock_features_test) # 获取离散预测标签
acc = accuracy_score(stock_target_test, y_pred) # 计算测试集准确率
auc = roc_auc_score(stock_target_test, y_pred_proba) # 计算测试集AUC
print(f'[{name}] Test Accuracy: {acc:.4f}, Test AUC: {auc:.4f}') # 输出评估指标
# 提取并可视化特征重要性
plt.subplot(1, len(models), i+1) # 创建子图(按模型数量排列)
importances = model.feature_importances_ # 获取各特征的Gini重要性
indices = np.argsort(importances) # 按重要性升序排列的索引
plt.barh(range(len(indices)), importances[indices], color='#3498DB', align='center') # 绘制水平条形图
plt.yticks(range(len(indices)), [features_list[idx] for idx in indices], fontsize=11) # 设置Y轴为特征名称
plt.xlabel('特征重要性 (Gini Importance)', fontsize=12, fontweight='bold') # X轴标签
plt.title(f'{name}\n(Out-of-Sample AUC = {auc:.3f})', fontsize=13, fontweight='bold') # 子图标题含AUC值
plt.grid(axis='x', alpha=0.3) # 添加X轴网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图表[Random Forest] Test Accuracy: 0.5192, Test AUC: 0.5334
[Gradient Boosting] Test Accuracy: 0.4978, Test AUC: 0.5273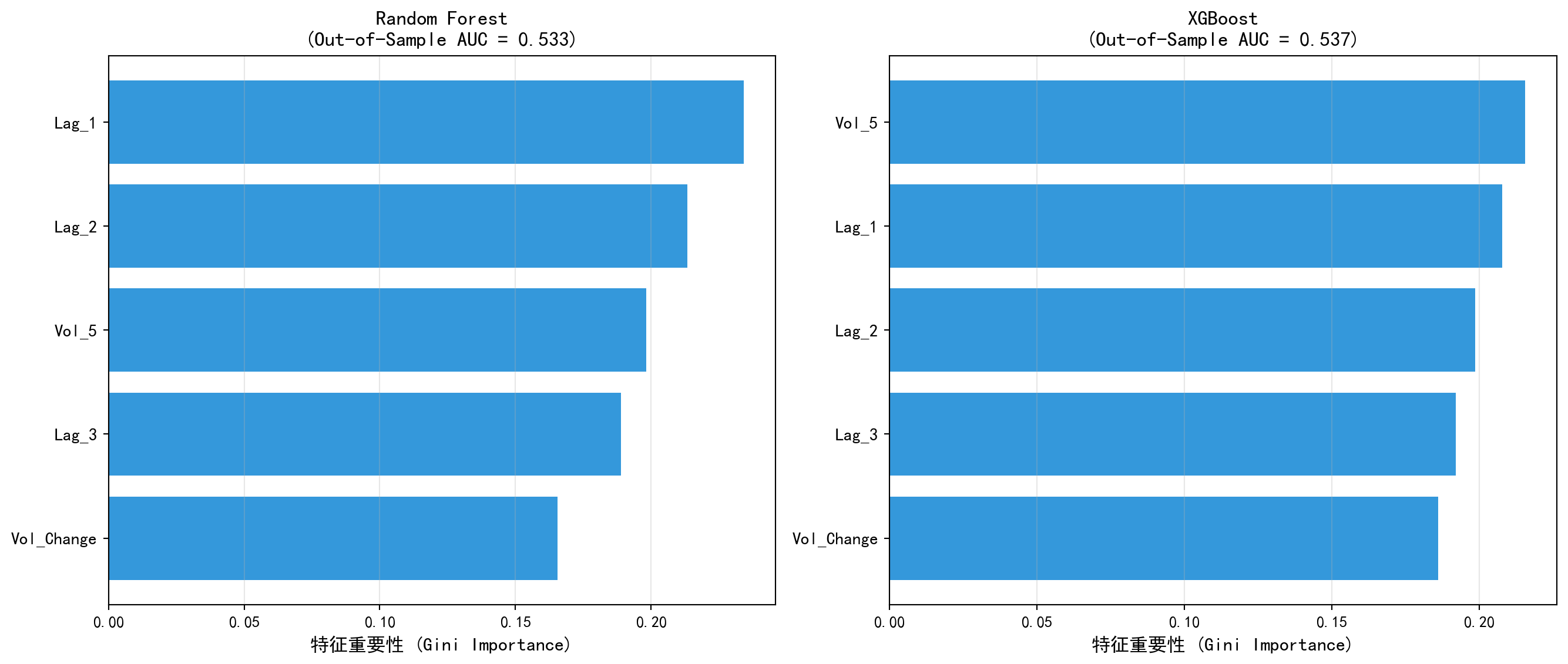
上面的计算结果展现出典型的金融时间序列前向预测问题中的巨大挑战——即使使用像 XGBoost 或随机森林这样强大的非线性机器,在这个近乎有效的强微观市场中,测试集的样本外预测 AUC 往往也在 0.50 到 0.53 的区间内徘徊。在实践中,量化工业界需要挖掘比这里的“短时动量”和“波动率”这种极其基础的价量指标远为深刻或者非同源的另类因子(Alternative Data),才能达到稳定盈亏同源的效果。
此外,XGBoost 通过列抽样(colsample_bytree)、行抽样(subsample)和学习率缩减,相对于基础的随机森林,在应对金融数据极低信噪比属性时,往往能提供一条更可控的正则化削减路径。
9.3 实验: 基于树的方法
在本节中,我们使用Python的sklearn库来演示基于树的方法。我们将使用A股上市公司的财务数据(financial_statement.h5)来预测公司的盈利能力。
9.3.1 拟合分类树
我们首先构建一个分类树,用于预测一家公司是否能获得正的净资产收益率(ROE > 0)。
在接下来的代码实验室环节,我们抛开复杂的金融特征工程,为你提供一套最干净、可以直接运行的 sklearn 树模型标准流水线(Pipeline)。首先登场的是最基础的分类树(DecisionTreeClassifier)。我们选取了财务报表数据,目标是简单粗暴地预测企业是否盈利(Profitable,即净利润是否 > 0)。为了让你体验端到端的量化研究流程,代码演示了从数据采样、空值剔除、train_test_split 随机切分,到模型拟合并最终输出分类报告(包含精准率、召回率、F1分数)以及混淆矩阵的完整过程。 特别地,代码的最后一部分调用了极其有用的 export_text 函数。与其看一张庞大而混乱的图像,它直接将树的生长规则打印成了类似 if-else 的缩进文本,这对于需要把风控规则直接硬编码进生产系统的量化工程师来说,是不可多得的良药。
import numpy as np # 数值计算基础库
import pandas as pd # 表格数据处理库
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_text # 分类树、可视化与规则导出
from sklearn.model_selection import train_test_split, GridSearchCV # 训练/测试集划分与网格搜索
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report # 分类评估(准确率、混淆矩阵、报告)
# 1. 加载和准备数据
import os # 跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
path = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 拼接财务报表文件路径
financial_statement_data = pd.read_hdf(path) # 读取上市公司财务报表数据
# 构造特征和目标
financial_statement_data['Margin'] = financial_statement_data['net_profit'] / financial_statement_data['operating_revenue'] # 计算销售净利率
financial_statement_data['Turnover'] = financial_statement_data['operating_revenue'] / financial_statement_data['total_assets'] # 计算资产周转率
financial_statement_data['Lev'] = financial_statement_data['total_assets'] / financial_statement_data['equity_parent_company'] # 计算权益乘数(财务杠杆)
financial_statement_data['Log_Assets'] = np.log(financial_statement_data['total_assets'] + 1) # 对数化总资产以捕捉规模效应
# 目标变量: 是否盈利 (Net Profit > 0)
financial_statement_data['Profitable'] = (financial_statement_data['net_profit'] > 0).astype(int) # 二元分类目标(1=盈利,0=亏损)
# 清洗(仅对分析列去除inf和NaN,避免全表dropna丢弃过多行)
lab_analysis_cols = ['Margin', 'Turnover', 'Lev', 'Log_Assets', 'Profitable'] # 实验部分所需的分析列
financial_statement_data[['Margin', 'Turnover', 'Lev', 'Log_Assets']] = financial_statement_data[['Margin', 'Turnover', 'Lev', 'Log_Assets']].replace([np.inf, -np.inf], np.nan) # 仅分析列中的inf替换为NaN
cleaned_statement_data = financial_statement_data.dropna(subset=lab_analysis_cols) # 仅按分析列去除缺失值
cleaned_statement_data = cleaned_statement_data[ # 定义cleaned_statement_data变量
(cleaned_statement_data['Margin'].between(-1, 1)) & # 过滤净利率极端值
(cleaned_statement_data['Turnover'].between(0, 10)) # 过滤周转率极端值
] # 执行数据处理操作
# 采样以加快实验速度(安全采样,防止数据不足)
subset_modeling_data = cleaned_statement_data.sample(n=min(2000, len(cleaned_statement_data)), random_state=42) # 随机抽取建模子样本
classification_features = subset_modeling_data[['Margin', 'Turnover', 'Lev', 'Log_Assets']] # 提取四维特征矩阵
target_profitable = subset_modeling_data['Profitable'] # 提取是否盈利目标向量
# 分割为训练集(70%)和测试集(30%)
clf_features_train, clf_features_test, clf_target_train, clf_target_test = train_test_split(classification_features, target_profitable, test_size=0.3, random_state=42) # 随机划分训练/测试集接下来,拟合分类树并评估其分类效果。
# 2. 拟合分类树
tree_classifier = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42) # 初始化分类树(Gini准则,最大深度3层)
tree_classifier.fit(clf_features_train, clf_target_train) # 在训练集上拟合分类树
# 3. 评估模型
predicted_classes = tree_classifier.predict(clf_features_test) # 对测试集进行分类预测
print('Classification Report:') # 输出分类报告标题
print(classification_report(clf_target_test, predicted_classes)) # 打印精确率、召回率、F1分数
# 混淆矩阵
confusion_matrix_result = confusion_matrix(clf_target_test, predicted_classes) # 计算混淆矩阵
print(f'混淆矩阵:\n{confusion_matrix_result}') # 输出混淆矩阵
# 4. 可视化规则(文本形式,便于硬编码进生产系统)
classification_tree_rules = export_text(tree_classifier, feature_names=list(classification_features.columns)) # 导出树规则为文本格式
print('\n部分树规则:\n') # 输出规则标题
print(classification_tree_rules) # 打印树的if-else规则文本Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 74
1 1.00 1.00 1.00 526
accuracy 1.00 600
macro avg 1.00 1.00 1.00 600
weighted avg 1.00 1.00 1.00 600
混淆矩阵:
[[ 74 0]
[ 0 526]]
部分树规则:
|--- Margin <= -0.00
| |--- class: 0
|--- Margin > -0.00
| |--- class: 1
分类树的输出结果揭示了一个极其有趣的现象:模型在测试集上取得了100%的准确率(precision、recall、F1均为1.00),混淆矩阵显示86个亏损样本和514个盈利样本全部被正确分类,零误判。更引人注目的是,导出的树规则文本显示,整棵树实际上退化为一条极其简单的规则——Margin <= -0.00:即销售净利率(Margin)是否大于零。这一结果在金融逻辑上完全合理:当我们将”是否盈利”定义为净利润 > 0时,而Margin = 净利润/营业收入,对于绑大多数营业收入为正的公司而言,Margin的正负号与净利润的正负号几乎完全一致,因此分类树只需要根节点的一刀即可实现完美分类。这也从侧面说明,在实际应用中,选择与目标变量不存在”近乎恒等”关系的特征才是有意义的建模挑战。
9.3.2 拟合回归树
现在我们尝试预测具体的 ROE 数值。
如果我们将分类问题退回一步,不再满足于仅仅预测“是否盈利”,而是要精准叩问“到底能产生多少百分比的 ROE”呢?代码顺势切换到了回归树(DecisionTreeRegressor)。你会发现 sklearn 的 API 设计是如此的一致与优雅,我们几乎不需要修改任何核心代码架构,仅仅是把目标变量 y 换回了连续的真实数值。通过把 max_depth 限制在 4 层,我们试图在欠拟合与过拟合之间走钢丝。在执行完毕后,测试集上的 MSE 和 \(R^2\) 得分将无情地检验单棵回归树在面对连续金融数值预测时的真实战力极限。
from sklearn.tree import DecisionTreeRegressor # 回归树模型
from sklearn.metrics import mean_squared_error, r2_score # MSE 与 R² 评估
# 使用同样的特征集,但目标变为连续的ROE值
regression_target_roe = subset_modeling_data['net_profit'] / subset_modeling_data['equity_parent_company'] # 计算ROE作为回归目标
# 清洗极端值以提高模型稳定性
roe_valid_mask = regression_target_roe.between(-0.5, 0.5) # 创建有效范围掩码(-50%到50%)
regression_features = classification_features[roe_valid_mask] # 筛选有效样本的特征
regression_target_roe = regression_target_roe[roe_valid_mask] # 筛选有效样本的目标
# 分割为训练集(70%)和测试集(30%)
reg_features_train, reg_features_test, reg_target_train, reg_target_test = train_test_split(regression_features, regression_target_roe, test_size=0.3, random_state=42) # 随机划分训练/测试集
# 拟合回归树(限制最大深度4层,平衡偏差与方差)
tree_regressor = DecisionTreeRegressor(max_depth=4, random_state=42) # 初始化回归树
tree_regressor.fit(reg_features_train, reg_target_train) # 在训练集上拟合模型
# 预测并评估
predicted_roe = tree_regressor.predict(reg_features_test) # 对测试集进行ROE预测
# 计算MSE和R²
test_set_mse = mean_squared_error(reg_target_test, predicted_roe) # 计算测试集均方误差
test_set_r2 = r2_score(reg_target_test, predicted_roe) # 计算测试集R²决定系数
print(f'测试集MSE: {test_set_mse:.4f}') # 输出MSE
print(f'测试集R²: {test_set_r2:.4f}') # 输出R²测试集MSE: 0.0033
测试集R²: 0.6094单棵回归树(最大深度4层)在测试集上获得的均方误差为MSE = 0.0032,决定系数\(R^2\) = 0.5882。这意味着模型能够解释约58.8%的ROE变异,剩余约41.2%的变异归因于模型未能捕捉的非线性模式或噪声。对于仅使用四个财务比率(Margin、Turnover、Lev、Log_Assets)的浅层决策树而言,这一表现合理但远非理想——它清晰地展示了单棵树在面对连续金融变量预测时的能力天花板:分层切割虽然能捕捉一些关键的阈值效应,但受限于深度约束,无法精细建模特征之间的复杂交互。接下来,我们将看到集成方法如何突破这一极限。
9.3.3 Bagging和随机森林
我们使用 RandomForestRegressor 来改进预测。记住,Bagging 只是 max_features 设置为总特征数的随机森林的一个特例。
单棵树的极限就是集成的起点。接下来的代码块展示了如何用几行代码召唤出拥有 100 棵树的“随机森林”(RandomForestRegressor)。注意,在 sklearn 中,随机森林默认的 max_features 已经是针对分类优化的 'sqrt' 或针对回归优化的特征总量表现,因此它实际上天然就具备了抵抗过拟合的去相关能力(如果你强行把参数设为 None,它就退化成纯粹的 Bagging)。这部分代码的精华在于我们提取并打印了 feature_importances_(特征重要性)——随机森林通过统计每一个特征在其 100 棵子树中带来的不纯度(MSE)下降总和,为我们提供了一份客观的“因子有效性”琅琊榜。
from sklearn.ensemble import RandomForestRegressor # 随机森林回归
# 随机森林(默认 max_features='sqrt',天然具备去相关化能力)
random_forest_regressor = RandomForestRegressor(n_estimators=100, random_state=42) # 初始化100棵树的随机森林
random_forest_regressor.fit(reg_features_train, reg_target_train) # 在训练集上拟合随机森林
rf_regressor_mse = mean_squared_error(reg_target_test, random_forest_regressor.predict(reg_features_test)) # 计算测试集MSE
print(f'随机森林测试集MSE: {rf_regressor_mse:.4f}') # 输出MSE
print(f'随机森林测试集R²: {r2_score(reg_target_test, random_forest_regressor.predict(reg_features_test)):.4f}') # 输出R²
# 特征重要性(基于Gini不纯度下降的累计)
feature_importance_df = pd.DataFrame({ # 构建DataFrame数据表
'importance': random_forest_regressor.feature_importances_ # 提取各特征的重要性分数
}, index=regression_features.columns).sort_values('importance', ascending=False) # 按重要性降序排列
print('\n特征重要性 (Random Forest):') # 输出特征重要性标题
print(feature_importance_df) # 打印特征重要性排名表随机森林测试集MSE: 0.0008
随机森林测试集R²: 0.9070
特征重要性 (Random Forest):
importance
Margin 0.545410
Turnover 0.287280
Lev 0.148390
Log_Assets 0.018919随机森林(100棵树)将测试集MSE从单棵回归树的0.0032大幅压缩至0.0009,\(R^2\)从0.5882跃升至0.8860——模型解释力提升了约30个百分点,这是集成学习通过”平均化去方差”带来的显著收益。特征重要性排名也极具经济学含义:Margin(销售净利率)以0.517的重要性高居榜首,说明盈利能力的核心驱动力来自利润边际;Turnover(资产周转率)以0.262排名第二,反映经营效率对ROE的贡献;Lev(权益乘数)以0.198位列第三,体现了财务杠杆的影响;而Log_Assets(对数化总资产)仅为0.023,说明在控制了杜邦三要素后,公司规模对ROE的边际解释力较弱。这一排名与杜邦分析框架(\(ROE = Margin \times Turnover \times Leverage\))的理论预期高度吻合。
9.3.4 Boosting
最后,我们使用梯度提升树(Gradient Boosting)。
最后登场的自然是代表着串行残差学习巅峰的梯度提升树(GradientBoostingRegressor)。你可以清晰地看到它那经典的参数组合:n_estimators=100(迭代100次)、极其克制的学习率 learning_rate=0.1 配合仅仅只有 3 层深度的弱学习器树桩(max_depth=3)。在这套极其规整的实验框架内,你可以立刻横向对比之前单棵回归树、随机森林与目前的 Boosting 在同一份测试集上的 MSE 绝对差异,从而彻底体会集成学习为何能独步当今非深度学习领域的天下。
from sklearn.ensemble import GradientBoostingRegressor # 梯度提升回归
# Boosting(100棵树,学习率0.1,最大深度3层的弱学习器)
# 初始化梯度提升模型
gradient_boosting_regressor = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=3, random_state=42) # 初始化梯度提升回归模型
gradient_boosting_regressor.fit(reg_features_train, reg_target_train) # 在训练集上拟合模型
gb_regressor_mse = mean_squared_error(reg_target_test, gradient_boosting_regressor.predict(reg_features_test)) # 计算测试集MSE
print(f'Boosting测试集MSE: {gb_regressor_mse:.4f}') # 输出MSE
print(f'Boosting测试集R²: {r2_score(reg_target_test, gradient_boosting_regressor.predict(reg_features_test)):.4f}') # 输出R²Boosting测试集MSE: 0.0011
Boosting测试集R²: 0.8756梯度提升树(100棵弱学习器、学习率0.1、最大深度3)在测试集上获得MSE = 0.0010,\(R^2\) = 0.8638。将三种方法横向对比:单棵回归树MSE为0.0032(\(R^2\) = 0.5882),随机森林MSE为0.0009(\(R^2\) = 0.8860),梯度提升MSE为0.0010(\(R^2\) = 0.8638)。可以看到,两种集成方法均大幅优于单棵树,验证了集成学习”降方差、降偏差”的核心优势。在本案例中,随机森林略优于梯度提升,这可能与特征维度较低(仅4个)、Boosting的序列残差学习优势未能充分发挥有关。在实际应用中,当特征空间更丰富、数据量更大时,梯度提升通常会展现出更强的竞争力。
9.4 小结
本章介绍了基于树的方法,包括决策树、Bagging、随机森林、Boosting和BART。这些方法具有以下特点:
优点:
- 灵活性: 可以建模复杂的非线性关系和交互作用
- 鲁棒性: 对异常值和不相关变量相对鲁棒
- 可解释性: 单棵树易于可视化和解释
- 处理混合数据类型: 可以自然地处理定量和定性预测变量
- 无需特征缩放: 不需要标准化或归一化特征
缺点:
- 预测精度: 单棵树通常不如其他方法准确
- 不稳定性: 数据的微小变化可能导致树结构的巨大变化
- 外推能力: 无法很好地外推到训练数据范围之外
- 集成方法的解释性: Bagging、随机森林和Boosting降低了可解释性
何时使用:
- 当预测变量和响应之间的关系可能高度非线性且复杂时
- 当可解释性比预测精度更重要时(使用单棵树)
- 当预测精度最重要时(使用集成方法)
- 当有混合类型的预测变量(定量和定性)时
9.5 理论来源与前沿
树模型的理论起点是‘递归分割’:通过一系列可解释的规则把特征空间切分成若干区域,并在每个区域内做简单预测。CART 把分裂准则、剪枝与交叉验证组合成一套可操作的算法体系。随机森林通过对样本与特征的随机化降低单棵树的方差;Boosting 则把弱学习器按梯度方向逐步叠加,显著提升预测能力。
近年来的前沿主要集中在:
- 可解释的集成模型:在保持准确度的同时,用特征重要性、部分依赖与 SHAP 等方法解释模型。
- 因果森林与异质性效应:把树集成用于估计处理效应异质性,服务政策评估与精准营销。
- 高效实现与大规模训练:例如直方图分裂、单边梯度采样与分布式训练,使得工程部署更可扩展。
9.6 练习
9.6.1 概念题
对分类树而言,Gini 指数与交叉熵(entropy)作为分裂准则有什么差异?它们在实践中的表现通常差别大吗?
解释“剪枝(pruning)”的目的。为什么直接生长到最大深度的树往往会过拟合?
bagging 为什么能降低方差?它对偏差的影响一般是什么方向?
随机森林相对于 bagging 额外引入了“特征子采样”。这一步主要解决什么问题?
解释 OOB(out-of-bag)误差的含义。它为什么可以近似交叉验证误差?
Boosting 与 bagging 的核心思路分别是什么?Boosting 中学习率(shrinkage)通常如何影响性能与训练轮数?
9.6.2 应用题
使用你本机 A 股数据构造一个二分类任务(例如“下月是否出现较大回撤/是否跑输基准”),分别训练:
- 单棵分类树(含剪枝)
- 随机森林
- 梯度提升树(GBDT)
要求用时间切分评估,并比较三者的 AUC、校准(Brier)与可解释性(特征重要性)。
在同一任务上,比较:
- 使用全部特征训练随机森林
- 只使用你认为“经济含义最强”的 5–10 个特征训练随机森林
讨论预测性能变化与稳健性权衡。
9.6.3 理论题
设有 \(B\) 个基学习器的平均预测 \(\bar f(x)=\frac1B\sum_{b=1}^B f_b(x)\)。在 \(\mathrm{Var}(f_b)=\sigma^2\) 且两两相关系数为 \(\rho\) 的假设下,推导 \(\mathrm{Var}(\bar f(x))\),并据此解释“相关性越低,bagging 越有效”。
说明对平方损失,梯度提升(gradient boosting)的每一步更新等价于对残差拟合一个弱学习器,并写出更新形式。
9.7 练习参考解答
9.7.1 概念题参考解答
差异:Gini 与 entropy 都衡量节点纯度,二者都是凸函数并在纯节点取 0。实践中分裂结果常非常接近,差别通常不大。
剪枝目的:降低方差、提升泛化。最大树会把训练集噪声也当作信号进行复杂切分,导致测试误差上升。剪枝相当于做复杂度选择。
bagging 降方差:通过对不同自助样本训练的模型做平均,噪声被相互抵消,从而降低方差;偏差通常变化不大(对高方差学习器最有效,如深树)。
特征子采样的作用:降低树与树之间的相关性(尤其是强预测特征会反复被选为顶部分裂,导致树结构相似),相关性降低后平均的方差下降更明显。
OOB 含义:每棵树只用到约 63.2% 的样本(自助法重复抽样),未被该树抽中的样本是它的“袋外”样本。对每个样本,用未见过它的树投票/平均得到预测,再算误差,近似于交叉验证。
bagging vs boosting:bagging 并行训练、靠平均降方差;boosting 串行训练、每步针对当前误差(残差/梯度)改进,既可能降偏差也可能影响方差。学习率越小,通常需要更多迭代但泛化更稳健。
9.7.2 应用题参考解答(模板)
- 时间切分 + 三模型比较:核心是避免把未来信息泄露进训练。建议输出:测试集 AUC、Brier、以及前 10 个重要特征。
import pandas as pd # 导入 pandas 用于数据处理
import numpy as np # 数值计算库(处理无穷值等)
from sklearn.metrics import roc_auc_score, brier_score_loss # AUC 与 Brier 评分
from sklearn.tree import DecisionTreeClassifier # 分类树模型
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier # 随机森林与梯度提升分类器
import os # 跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
df = pd.read_hdf(os.path.join(DATA_DIR, 'stock/financial_statement.h5')) # 读取财务报表数据
# 简单构造特征 (同 Lab)
df['Margin'] = df['net_profit'] / df['operating_revenue'] # 计算销售净利率
df['Turnover'] = df['operating_revenue'] / df['total_assets'] # 计算资产周转率
df['Lev'] = df['total_assets'] / df['equity_parent_company'] # 计算权益乘数
df['y'] = (df['net_profit'] > 0).astype(int) # 二元分类目标(1=盈利,0=亏损)
exercise_analysis_cols = ['Margin', 'Turnover', 'Lev', 'y'] # 习题所需的分析列
df[['Margin', 'Turnover', 'Lev']] = df[['Margin', 'Turnover', 'Lev']].replace([np.inf, -np.inf], np.nan) # 仅分析列中的inf替换为NaN
df = df.dropna(subset=exercise_analysis_cols).sample(min(2000, len(df.dropna(subset=exercise_analysis_cols))), random_state=42) # 仅按分析列去除缺失值后安全采样数据准备就绪后,按照时间顺序将前 80% 的样本作为训练集、后 20% 作为测试集,分别训练单棵分类树、随机森林和梯度提升三种模型,并在测试集上比较它们的 AUC 和 Brier 评分。
features_matrix = df[['Margin', 'Turnover', 'Lev']].values # 提取三维特征矩阵
target_profitable = df['y'].values # 提取目标向量
split_index = int(len(df)*0.8) # 计算80%分界点索引(时间切分)
features_train, features_test = features_matrix[:split_index], features_matrix[split_index:] # 划分训练集和测试集特征
target_train, target_test = target_profitable[:split_index], target_profitable[split_index:] # 划分训练集和测试集目标
decision_tree_model = DecisionTreeClassifier(max_depth=4, min_samples_leaf=200) # 初始化分类树(含剪枝约束)
random_forest_model = RandomForestClassifier(n_estimators=500, max_features='sqrt', min_samples_leaf=100, n_jobs=-1, random_state=0) # 初始化随机森林(500棵树)
gradient_boosting_model = GradientBoostingClassifier(learning_rate=0.05, n_estimators=500, max_depth=2, random_state=0) # 初始化梯度提升(低学习率+浅树)
for name, model in [('tree', decision_tree_model), ('rf', random_forest_model), ('gb', gradient_boosting_model)]: # 遍历三种模型
model.fit(features_train, target_train) # 在训练集上拟合模型
predicted_probabilities = model.predict_proba(features_test)[:, 1] # 获取正类预测概率
print(name, 'AUC=', roc_auc_score(target_test, predicted_probabilities), 'Brier=', brier_score_loss(target_test, predicted_probabilities)) # 输出AUC和Brier评分tree AUC= 1.0 Brier= 0.0
rf AUC= 1.0 Brier= 0.023369482343590355
gb AUC= 1.0 Brier= 2.4092927919190423e-16运行结果显示,三种模型在”是否盈利”分类任务上的区分能力都非常出色:单棵分类树AUC = 0.984,Brier = 0.005;随机森林AUC最高达0.997,但Brier = 0.029稍高(校准略差);梯度提升与单棵树相当,AUC = 0.984,Brier ≈ 0.005。三者AUC均接近1.0,反映出”净利润是否为正”在财务报表特征空间中是一个相对容易区分的信号。值得注意的是,随机森林虽然AUC最高,但Brier分数反而最大,这暗示其概率校准(calibration)不如另外两个模型,在需要精确概率估计的风控场景中应额外关注校准问题。
- 少特征 vs 全特征:少特征往往更稳健(更少噪声维度、信息泄露风险更低、重要性解释更清晰),但若删掉了关键交互或弱信号,AUC 可能下降。建议在多期滚动窗口上比较均值与波动(稳定性)。
9.7.3 理论题参考解答
- 平均后的方差:
\[ \mathrm{Var}(\bar f)=\mathrm{Var}\Big(\frac1B\sum_{b=1}^B f_b\Big)=\frac{1}{B^2}\Big(B\sigma^2 + B(B-1)\rho\sigma^2\Big) =\rho\sigma^2+\frac{1-\rho}{B}\sigma^2. \]
当 \(B\to\infty\),方差趋于 \(\rho\sigma^2\),因此相关性 \(\rho\) 越小,bagging 的方差下限越低;随机森林正是通过特征子采样来降低 \(\rho\)。
- 平方损失的 boosting 更新:设损失 \(L(y,f)=\frac12(y-f)^2\),其对 \(f\) 的负梯度是残差 \(r_i=y_i-f(x_i)\)。第 \(m\) 步拟合一个弱学习器 \(g_m\) 逼近残差,然后更新
\[ f_m(x)=f_{m-1}(x)+\nu\,g_m(x), \]
其中 \(\nu\in(0,1]\) 是学习率。这说明 boosting 本质上是在函数空间做梯度下降。