# =====================================================================
# 本代码演示:为什么分类问题不能直接使用线性回归?
# 通过对比线性回归和逻辑回归在同一数据上的表现来揭示答案
# =====================================================================
# 导入数值计算库 numpy,用于生成模拟数据和数学运算
import numpy as np # 导入numpy库
# 导入数据处理库 pandas(本代码块虽未直接使用,但保持导入一致性)
import pandas as pd # 导入pandas库
# 导入绘图库 matplotlib,用于绑制对比图
import matplotlib.pyplot as plt # 导入matplotlib库
# 从 scikit-learn 导入线性回归和逻辑回归两个模型
# LinearRegression:普通最小二乘线性回归(用于回归问题)
# LogisticRegression:逻辑回归(专门用于分类问题)
from sklearn.linear_model import LinearRegression, LogisticRegression # 从sklearn.linear_model导入所需模块
# 设置随机种子为 42,确保每次运行结果完全一致(可复现性)
np.random.seed(42) # 设置随机种子确保结果可复现
# ---------- 第一步:生成模拟的股票市场数据 ----------
# 模拟 200 个交易日的数据(每个数据点代表一天)
sample_count = 200 # 设定模拟交易日数量为200天
# 生成前一日收益率 Lag1,服从均值为 0、标准差为 1.5% 的正态分布
# 这是模拟股市日收益率的合理分布特征
daily_lag1_return = np.random.normal(0, 1.5, sample_count) # 生成正态分布随机样本
# 设定真实的数据生成机制:涨跌概率取决于前一日收益率 Lag1
# 对数几率(log-odds) = -0.5 + 0.8 * Lag1
# 即:前一日收益率越高,今日上涨的对数几率越大
log_odds = -0.5 + 0.8 * daily_lag1_return # 按DGP计算对数几率:截距-0.5 + 斜率0.8 × Lag1
# 通过 sigmoid 函数将对数几率转换为上涨概率,范围严格在 (0, 1) 之间
upward_probability = 1 / (1 + np.exp(-log_odds)) # 计算指数值
# 根据上涨概率进行伯努利抽样,生成实际的涨跌方向
# 1 = 上涨(Up),0 = 下跌(Down)
market_direction = np.random.binomial(1, upward_probability) # 按概率进行伯努利抽样得到涨跌标签(1=涨,0=跌)
# ---------- 第二步:用线性回归拟合分类数据(错误方法)----------
# 创建一个普通线性回归模型对象
linear_regression_model = LinearRegression() # 初始化线性回归模型
# 用 Lag1 作为自变量 X,涨跌方向(0/1)作为因变量 Y 进行拟合
# reshape(-1, 1) 将一维数组转为二维列向量,这是 sklearn 的输入格式要求
linear_regression_model.fit(daily_lag1_return.reshape(-1, 1), market_direction) # 训练/拟合模型
# 生成一组均匀分布的 x 值,用于绘制平滑的预测曲线
# 在Lag1的取值范围内均匀生成300个点,用于绘制平滑的预测曲线
x_range = np.linspace(daily_lag1_return.min(), daily_lag1_return.max(), 300).reshape(-1, 1)
# 线性回归的预测值:注意这些值可能小于 0 或大于 1!
linear_predictions = linear_regression_model.predict(x_range) # 使用模型进行预测
# ---------- 第三步:用逻辑回归拟合分类数据(正确方法)----------
# 创建一个逻辑回归模型对象
logistic_regression_model = LogisticRegression() # 初始化逻辑回归模型
# 同样用 Lag1 预测涨跌方向
logistic_regression_model.fit(daily_lag1_return.reshape(-1, 1), market_direction) # 训练/拟合模型
# predict_proba 返回每个类别的概率,[:, 1] 取 "上涨" 类(类别1)的概率
# 逻辑回归的预测值始终在 [0, 1] 区间内,可以解释为概率
logistic_predictions = logistic_regression_model.predict_proba(x_range)[:, 1] # 预测类别概率5 分类 (Classification)
5.1 引言 (Introduction)
分类问题(classification problems)是统计学习和机器学习中最重要的问题类型之一。与回归问题(响应变量是定量的)不同,分类问题的响应变量是定性的(qualitative)或分类的(categorical)。
分类 vs. 回归的对比:
| 特征 | 回归 (Regression) | 分类 (Classification) |
|---|---|---|
| 响应变量 \(Y\) | 定量(如收入、房价、销售量) | 定性(如是否违约、涨跌方向、信用等级) |
| 预测目标 | 预测具体的数值 | 预测类别标签 |
| 评估指标 | MSE, \(R^2\) | 准确率、精确率、召回率、F1分数 |
| 示例 | 预测房价、预测销量 | 信用评分、股票涨跌预测、客户流失判别 |
案例背景:A股市场涨跌预测
在本章中,我们将使用一个来自中国A股市场的真实场景案例:预测股票市场方向。投资者希望根据过去几天的市场表现预测明天的股市是上涨(Up)还是下跌(Down)。这有助于:
- 量化交易:构建自动化交易策略
- 风险管理:及时对冲市场下行风险
- 市场择时:优化买卖时机
数据集:我们将使用 Tushare 提供的真实日度行情数据,涵盖以下变量:
- 方向 (Direction):响应变量,1=上涨,0=下跌
- Lag1:前一日的收益率(%)
- Lag2:前两日的收益率(%)
- Volume:成交量(手)
- Today:当日收益率(我们希望预测其符号)
Note on 分类问题的理论基础
分类问题的统计理论基础可以追溯到费歇尔(Ronald A. Fisher)在1936年提出的线性判别分析(Linear Discriminant Analysis, LDA)。费歇尔当时研究的是鸢尾花分类问题,这个经典数据集至今仍被广泛用于教学。
另一个重要里程碑是逻辑回归(Logistic Regression)的发展,它最初由Verhulst在1845年提出用于人口增长建模,后来在1958年由Berkson引入生物统计学领域。
到了20世纪80-90年代,随着Vapnik等人提出支持向量机(SVM),以及Friedman等人提出广义加法模型(GAM),分类方法得到了快速发展。
5.2 分类问题概述 (An Overview of Classification)
在分类问题中,我们有一个响应变量\(Y\),它取值为\(K\)个不同的类别。令\(\mathcal{G} = \{1, 2, \ldots, K\}\)表示这\(K\)个类别的集合。
目标:基于预测变量\(X = (X_1, X_2, \ldots, X_p)\),构建一个分类器\(C(X)\),使得\(C(X)\)能够准确预测\(Y\)的类别。
5.2.1 两分类 vs. 多分类
- 两分类问题 (Binary Classification):\(K = 2\)。例如:
- 是否违约(是/否)
- 股票涨跌方向(涨/跌)
- 客户是否流失(是/否)
- 多分类问题 (Multi-class Classification):\(K > 2\)。例如:
- 信用等级评定(AAA/AA/A/BBB等)
- 行业分类(金融、科技、消费、制造等)
- 投资评级(买入、持有、卖出)
注:大多数分类方法最初是为两分类问题设计的,但可以通过”一对多”(One-vs-Rest)或”一对一”(One-vs-One)策略扩展到多分类问题。
5.2.2 为什么不能直接使用线性回归? (Why Not Linear Regression?)
一个自然的想法是:既然我们已经学习了线性回归,为什么不能对分类问题也使用线性回归呢?
问题1:编码方式影响结果
假设我们有一个三分类问题(类别A、B、C),我们尝试将它们编码为数字:
- 方案1:A=1, B=2, C=3
- 方案2:A=1, B=0, C=-1
不同的编码方式会导致完全不同的回归结果,这在定性变量的情况下是不合理的。
问题2:预测值超出类别范围
假设我们用0/1编码来预测违约(0=未违约,1=违约),线性回归模型可能预测出\(\hat{Y} = 1.2\)或\(\hat{Y} = -0.3\)这样的值,这些值没有明确的解释。
问题3:难以处理多分类问题
对于多于两个类别的情况,使用线性回归需要创建多个哑变量,且预测结果可能不属于任何一类。
图 5.1 展示了为什么线性回归不适合分类问题。
为了在视觉上彻底讲透“为什么分类问题不能生搬硬套线性回归”这个统计学基础概念,下面的 Python 代码为我们构建了一个生动的对比实验。我们模拟了 200 个带噪声的股票收益率信号,并基于这些信号真实生成了“涨”和“跌”两个离散分类结果(在代码中被严格编码为 1 和 0)。接着,代码在同一批数据上齐头并进地训练了两个模型:左图是传统的 OLS 线性回归模型(LinearRegression),右图是本章的主角逻辑回归模型(LogisticRegression)。当你审视左图那条红色的直线时,会荒谬地发现它的预测不仅穿透了 0 和 1 的逻辑边界(预测出 1.2 或者 -0.3 这种毫无概率解释意义的值),而且极易受到极值点的杠杆扭曲;相反,右图那条优雅的蓝色 S 型曲线(Sigmoid 函数),精准地将所有预测值平滑并限制在了 \([0,1]\) 的严格概率空间内。这就是为什么在分类任务中我们要全面转向逻辑回归等非线性概率模型的原因。
上面的代码完成了数据生成和两个模型的训练:我们创建了200个模拟交易日的涨跌数据,然后分别用线性回归和逻辑回归对同一份二元分类数据进行拟合。线性回归产生一条直线预测,逻辑回归产生一条S形曲线预测。下面的代码通过并排对比图来直观展示两者的关键差异——为什么线性回归不适合处理分类问题。
# ---------- 第四步:绘制对比图 ----------
# 创建 1 行 2 列的子图,图像大小为 16×6 英寸
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建子图布局
# --- 左图:线性回归(展示其缺陷)---
ax1 = axes[0] # 获取左侧子图(线性回归)
# 绘制实际观测数据点:灰色散点,0=下跌,1=上涨
# 绘制涨跌观测值散点:0=下跌聚集在底部,1=上涨聚集在顶部
ax1.scatter(daily_lag1_return, market_direction, alpha=0.4, s=60, color='gray', label='Observed (0=Down, 1=Up)')
# 绘制线性回归拟合线:红色直线
# 问题:预测值可以超出 [0,1] 的范围,无法解释为概率
ax1.plot(x_range, linear_predictions, 'r-', linewidth=2.5, label='Linear Fit') # 在子图中绑制折线图
# 绘制 y=0 和 y=1 的虚线参考线,清晰标示概率的合理边界
ax1.axhline(0, color='k', ls='--'); ax1.axhline(1, color='k', ls='--') # 添加水平参考线
ax1.set_xlabel('Lag1 Return (%)', fontsize=12) # 设置子图X轴标签
ax1.set_ylabel('Predicted Direction', fontsize=12) # 设置子图Y轴标签
ax1.set_title('Linear Regression Issue', fontsize=14) # 设置子图标题
ax1.legend() # 添加子图图例
# --- 右图:逻辑回归(展示其优势)---
ax2 = axes[1] # 获取右侧子图(逻辑回归)
# 绘制同样的实际观测数据点
# 绘制涨跌观测值散点作为对照参考
ax2.scatter(daily_lag1_return, market_direction, alpha=0.4, s=60, color='gray', label='Observed')
# 绘制逻辑回归拟合曲线:蓝色 S 形曲线(sigmoid)
# 优势:预测值自动限制在 [0,1] 内,天然可解释为上涨概率
# 绘制逻辑回归S形概率曲线:预测值始终限制在[0,1]区间
ax2.plot(x_range, logistic_predictions, 'b-', linewidth=2.5, label='Logistic Fit (Prob)')
# 同样绘制概率边界参考线
ax2.axhline(0, color='k', ls='--'); ax2.axhline(1, color='k', ls='--') # 添加水平参考线
ax2.set_xlabel('Lag1 Return (%)', fontsize=12) # 设置子图X轴标签
ax2.set_ylabel('Probability of Up', fontsize=12) # 设置子图Y轴标签
ax2.set_title('Logistic Regression Solution', fontsize=14) # 设置子图标题
ax2.legend() # 添加子图图例
# 自动调整子图间距,防止标签重叠
plt.tight_layout() # 自动调整子图间距
# 显示图形
plt.show() # 显示图形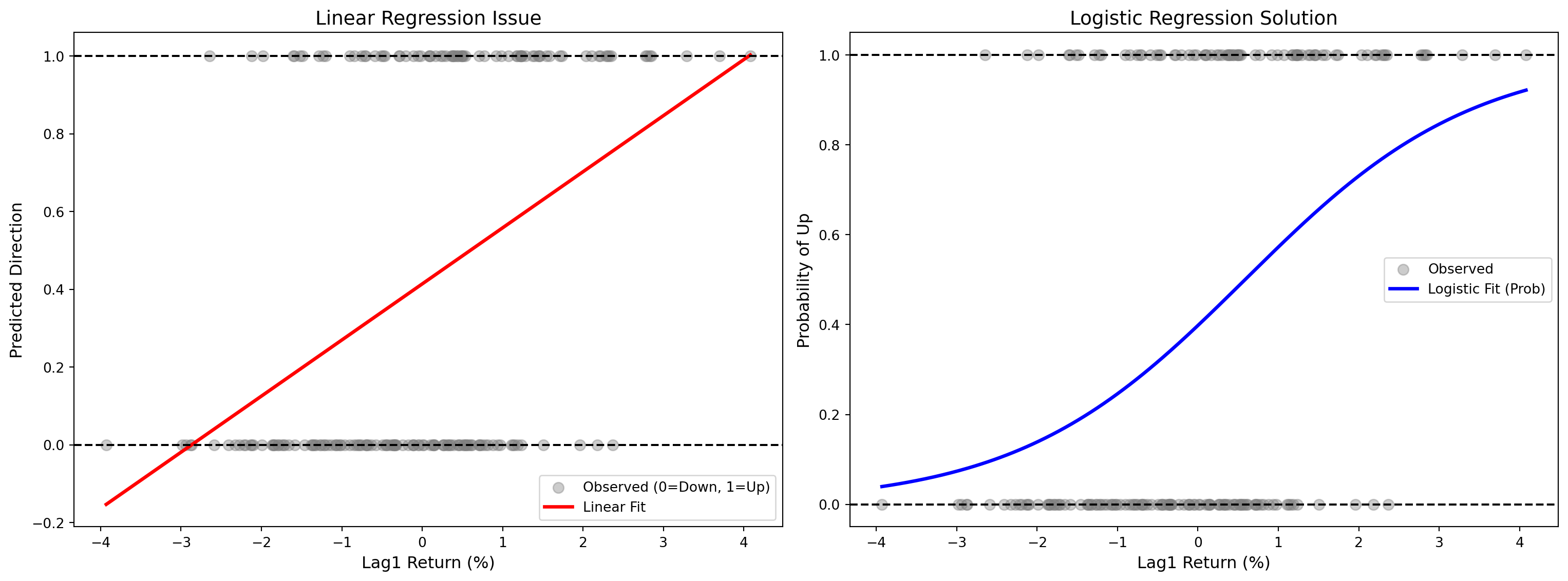
从 图 5.1 可以清楚地看到:
- 线性回归(左图):
- 产生的预测值可以小于0或大于1,这在概率意义上没有意义
- 对离群点敏感
- 无法刻画类别之间的非线性边界
- 逻辑回归(右图):
- 通过S形曲线(sigmoid function)将预测值限制在\([0,1]\)区间
- 可以解释为概率
- 对离群点更加鲁棒
5.3 逻辑回归 (Logistic Regression)
逻辑回归(Logistic Regression)是最广泛使用的分类方法之一,尽管名称中包含”回归”,但它实际上是一种分类方法。逻辑回归通过建模\(P(Y=1|X)\)来预测概率。
5.3.1 逻辑模型 (The Logistic Model)
在逻辑回归中,我们使用逻辑函数(logistic function)来建模\(Y=1\)的概率:
\[ p(X) = P(Y=1|X) = \frac{e^{\beta_0 + \beta_1 X}}{1 + e^{\beta_0 + \beta_1 X}} \tag{5.1}\]
这个函数也称为S形函数(sigmoid function),因为它呈现S形状。
Tip: 理解逻辑函数的推导
逻辑函数的推导可以从对数几率(log-odds)的概念开始:
几率(Odds):事件发生的概率与不发生的概率之比 \[ \text{Odds} = \frac{p}{1-p} \]
对数几率(Log-odds/Logit):几率的对数 \[ \text{logit}(p) = \log\left(\frac{p}{1-p}\right) \]
关键假设:对数几率与\(X\)呈线性关系 \[ \log\left(\frac{p(X)}{1-p(X)}\right) = \beta_0 + \beta_1 X \]
解出\(p(X)\): \[ \frac{p(X)}{1-p(X)} = e^{\beta_0 + \beta_1 X} \] \[ p(X) = e^{\beta_0 + \beta_1 X}(1-p(X)) \] \[ p(X)(1 + e^{\beta_0 + \beta_1 X}) = e^{\beta_0 + \beta_1 X} \] \[ p(X) = \frac{e^{\beta_0 + \beta_1 X}}{1 + e^{\beta_0 + \beta_1 X}} \]
这就是逻辑函数!它将线性预测\((-\infty, +\infty)\)映射到概率区间\((0, 1)\)。
逻辑函数的性质:
- 取值范围:\(p(X) \in (0, 1)\),适合概率解释
- 单调性:如果\(\beta_1 > 0\),\(p(X)\)随\(X\)增加而单调递增
- 对称性:\(p(-x) = 1 - p(x)\)(当\(\beta_0 = 0\)时)
- S形曲线:在中间变化快,两端趋近于0和1
5.3.2 估计回归系数 (Estimating the Regression Coefficients)
与线性回归使用最小二乘法不同,逻辑回归使用最大似然估计(Maximum Likelihood Estimation, MLE)来估计系数。
似然函数 (Likelihood Function):
假设我们有\(n\)个独立的观测\((x_1, y_1), \ldots, (x_n, y_n)\),其中\(y_i \in \{0, 1\}\)。似然函数为:
\[ L(\beta_0, \beta_1) = \prod_{i: y_i=1} p(x_i) \prod_{i: y_i=0} (1 - p(x_i)) \tag{5.2}\]
这可以写成更简洁的形式:
\[ L(\beta_0, \beta_1) = \prod_{i=1}^{n} p(x_i)^{y_i} (1 - p(x_i))^{1-y_i} \tag{5.3}\]
对数似然函数 (Log-Likelihood):
\[ \ell(\beta_0, \beta_1) = \sum_{i=1}^{n} [y_i \log p(x_i) + (1-y_i) \log(1-p(x_i))] \tag{5.4}\]
最大似然估计选择使对数似然函数最大的 \((\hat{\beta}_0, \hat{\beta}_1)\):
\[ (\hat{\beta}_0, \hat{\beta}_1) = \arg\max_{\beta_0, \beta_1} \ell(\beta_0, \beta_1) \tag{5.5}\]
数学推导:逻辑回归的梯度公式
为了优化这个对数似然函数,我们需要对其求导。令 \(p_i = p(x_i) = \sigma(\beta_0 + \beta_1 x_i)\)。 首先,回忆 logistics 函数的导数性质:\(\frac{\partial p_i}{\partial \beta_1} = p_i(1 - p_i)x_i\)。
对 \(\ell(\beta_0, \beta_1)\) 关于 \(\beta_1\) 求偏导:
\[ \begin{aligned} \frac{\partial \ell}{\partial \beta_1} &= \sum_{i=1}^{n} \left[ \frac{y_i}{p_i} - \frac{1-y_i}{1-p_i} \right] \frac{\partial p_i}{\partial \beta_1} \\ &= \sum_{i=1}^{n} \left[ \frac{y_i(1-p_i) - (1-y_i)p_i}{p_i(1-p_i)} \right] p_i(1-p_i)x_i \\ &= \sum_{i=1}^{n} (y_i - y_i p_i - p_i + y_i p_i)x_i \\ &= \sum_{i=1}^{n} (y_i - p_i)x_i \end{aligned} \]
这个梯度具有非常直观的物理意义:\((y_i - p_i)\) 是预测误差。每次迭代更新时,如果误差为正(实际为1但预测概率小),参数就沿着增大预测概率的方向移动。我们在寻找使得总误差加权和为零的参数点。
Clarification on MLE vs. OLS
最小二乘法(OLS)和最大似然估计(MLE)是两种不同的参数估计方法:
| 特性 | OLS (线性回归) | MLE (逻辑回归) |
|---|---|---|
| 目标 | 最小化残差平方和 | 最大化似然函数 |
| 解 | 解析解(闭式) | 无解析解,需迭代优化 |
| 假设 | 误差项正态分布 | 伯努利分布(二项分布) |
| 计算效率 | 高(直接计算) | 较低(迭代算法如Newton-Raphson) |
| 适用范围 | 线性回归 | 广义线性模型、非线性模型 |
在误差项服从正态分布的假设下,线性回归的OLS估计等价于MLE。但对于逻辑回归,由于误差项不是正态分布,MLE是自然的选择。
案例应用:预测A股市场涨跌
让我们使用真实的A股日度行情数据来构建逻辑回归模型。
在下面的量化实战代码中,我们正式利用真实市场的日度历史行情数据来构建一个专业的逻辑回归模型。代码首先读取并定位了浦发银行(600000.XSHG)的历史交易面板数据,借助 pandas 极度强大的时序处理能力(提取 pct_change() 和 shift() 函数属性),快速计算出了当天的绝对收益率,并向后追溯生成了过去三天(Lag1, Lag2, Lag3)的滞后收益率作为预测特征(Features)。同时,我们将当天收益率大于0这一事件提取为布尔值并转化为数字 1,以此作为我们需要预判的二分类响应变量(Direction)。最后,这段代码调用了 statsmodels.api 中的 Logit 模型预估对象,通过后台迭代执行的最大似然估计算法(MLE)彻底完成了参数拟合,并打印产生了一份包含所有自变量回归系数及其 \(P\) 值显著性检验维度的极其详尽的统计摘要表格。
# =====================================================================
# 本代码演示:使用真实 A 股行情数据构建逻辑回归模型
# 目标:用过去 1~3 天的收益率预测今天股票是涨还是跌
# =====================================================================
# 导入数值计算库
import numpy as np # 导入numpy库
# 导入数据处理库 pandas,用于读取和操作表格数据
import pandas as pd # 导入pandas库
# 导入 statsmodels 统计建模库
# statsmodels 提供了类似 R 语言的统计分析功能,包括逻辑回归、回归诊断等
import statsmodels.api as sm # 导入statsmodels库
# 导入操作系统接口,用于判断当前运行平台(Windows 或 Linux)
import os # 导入os库
# ---------- 第一步:读取真实的 A 股日度行情数据 ----------
# 根据操作系统自动选择正确的本地数据路径
# Windows用C盘路径,Linux用ubuntu服务器挂载路径
DATA_ROOT = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
# 本地数据路径:前复权的日度行情数据(h5 是一种高效的二进制存储格式)
stock_price_path = os.path.join(DATA_ROOT, 'stock/stock_price_pre_adjusted.h5') # 构建数据文件的完整路径
# 读取整个 h5 文件到 DataFrame 中
stock_price_data = pd.read_hdf(stock_price_path).reset_index() # 读取并重置MultiIndex为普通列
# 筛选浦发银行(代码 600000.XSHG)的历史数据
# 浦发银行是上海的大型股份制商业银行,交易活跃,数据完整
# 筛选浦发银行并创建副本避免修改原始数据
stock_price_data = stock_price_data[stock_price_data['order_book_id'] == '600000.XSHG'].copy()
# 按交易日期排序,确保时序正确(时间序列分析的基本要求)
stock_price_data = stock_price_data.sort_values('date') # 按指定列排序
# ---------- 第二步:构造特征变量(自变量) ----------
# 计算日收益率(百分比形式):(今日收盘价 - 昨日收盘价) / 昨日收盘价 × 100
# pct_change() 是 pandas 内置的百分比变化计算函数
stock_price_data['pct_chg'] = stock_price_data['close'].pct_change() * 100 # 计算百分比变化(收益率)
# 构造滞后特征:用过去几天的收益率作为预测因子
# Lag1:前一个交易日的收益率(shift(1) 表示向下移动 1 行,即取前一天的值)
stock_price_data['Lag1'] = stock_price_data['pct_chg'].shift(1) # 构造Lag1滚后变量:前1个交易日的收益率
# Lag2:前两个交易日的收益率
stock_price_data['Lag2'] = stock_price_data['pct_chg'].shift(2) # 构造Lag2滚后变量:前2个交易日的收益率
# Lag3:前三个交易日的收益率
stock_price_data['Lag3'] = stock_price_data['pct_chg'].shift(3) # 构造Lag3滚后变量:前3个交易日的收益率
# ---------- 第三步:构造响应变量(因变量) ----------
# Direction = 1 表示当日上涨,Direction = 0 表示当日下跌或平盘
# (pct_chg > 0) 生成布尔值 True/False,astype(int) 转换为数字 1/0
stock_price_data['Direction'] = (stock_price_data['pct_chg'] > 0).astype(int) # 转换数据类型
# 去除因 shift 操作产生的缺失值(前 3 行没有完整的滞后数据)
# 去除因shift操作产生的前3行缺失值,确保每行数据完整
cleaned_analysis_data = stock_price_data[['Direction', 'Lag1', 'Lag2', 'Lag3']].dropna()数据准备工作已完成:我们从浦发银行(600000.XSHG)的真实日度行情中计算了日收益率,并构造了Lag1、Lag2、Lag3三个滞后期收益率作为预测因子,以及”今日涨跌方向”作为二元分类标签。接下来,我们将用statsmodels的Logit模型进行最大似然估计,并检验各滞后变量系数的统计显著性。
# ---------- 第四步:准备模型输入数据 ----------
# 提取自变量矩阵 X:Lag1, Lag2, Lag3 三列
input_features_matrix = cleaned_analysis_data[['Lag1', 'Lag2', 'Lag3']] # 提取三个滚后期收益率作为自变量矩阵
# add_constant 添加一列全为 1 的截距项(常数项)
# 这是因为 statsmodels 不会自动添加截距,需要手动指定
input_features_matrix = sm.add_constant(input_features_matrix) # 添加常数项(截距项)
# 提取因变量向量 Y:涨跌方向 (0 或 1)
target_direction_vector = cleaned_analysis_data['Direction'] # 提取涨跌方向作为因变量向量(0或1)
# ---------- 第五步:拟合逻辑回归模型 ----------
# sm.Logit 创建一个逻辑回归模型对象,传入因变量 Y 和自变量 X
# .fit(disp=0) 执行最大似然估计(MLE),disp=0 表示不显示迭代过程
logit_model = sm.Logit(target_direction_vector, input_features_matrix).fit(disp=0) # 训练/拟合模型
# 打印完整的模型统计摘要,包括:
# - 各变量的回归系数(coef)
# - 标准误差(std err)
# - z 统计量和 p 值(判断系数是否显著不为零)
# - 95% 置信区间
print(logit_model.summary()) # 输出模型摘要统计
print("\n系数解释:") # 输出结果到控制台
print("如果Lag1系数系数为负,说明昨日上涨会降低今日上涨的概率(反转效应)。") # 输出结果到控制台 Logit Regression Results
==============================================================================
Dep. Variable: Direction No. Observations: 5097
Model: Logit Df Residuals: 5093
Method: MLE Df Model: 3
Date: Mon, 18 May 2026 Pseudo R-squ.: 0.0005808
Time: 21:31:35 Log-Likelihood: -3525.3
converged: True LL-Null: -3527.4
Covariance Type: nonrobust LLR p-value: 0.2512
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -0.0917 0.028 -3.262 0.001 -0.147 -0.037
Lag1 -0.0255 0.013 -1.892 0.058 -0.052 0.001
Lag2 -0.0076 0.013 -0.569 0.569 -0.034 0.019
Lag3 0.0055 0.013 0.413 0.680 -0.021 0.032
==============================================================================
系数解释:
如果Lag1系数系数为负,说明昨日上涨会降低今日上涨的概率(反转效应)。表 5.1 展示了逻辑回归模型的完整估计结果。从模型整体来看,伪 \(R^2\) 仅为 0.0006,似然比检验的 \(p\) 值为 0.2512,远大于 0.05 的显著性水平,这表明 Lag1、Lag2、Lag3 三个滞后收益率变量联合来看对市场涨跌方向几乎没有解释力——这与有效市场假说(EMH)的预期高度一致。
从单个系数来看,截距项 \(\hat{\beta}_0 = -0.0917\) 在 1% 水平上显著(\(p = 0.001\)),其负值意味着在三个滞后变量均为零时,市场下跌的概率略高于上涨。Lag1 的系数为 \(-0.0255\)(\(p = 0.058\)),处于 10% 显著性水平的边缘,负号暗示了一种微弱的短期反转效应——即昨日上涨反而略微降低今日上涨的概率。而 Lag2 和 Lag3 的系数在统计上均不显著(\(p\) 值分别为 0.569 和 0.680),说明更早期的收益率信息对今日涨跌方向的预测价值极为有限。总的来说,该模型的预测能力非常薄弱,这提醒我们:在成熟的股票市场中,仅凭历史收益率的简单滞后很难有效预测市场的短期走势。
5.3.3 进行预测 (Making Predictions)
一旦估计了系数,我们就可以使用逻辑回归模型进行预测:
\[ \hat{p}(X) = \frac{e^{\hat{\beta}_0 + \hat{\beta}_1 X}}{1 + e^{\hat{\beta}_0 + \hat{\beta}_1 X}} \tag{5.6}\]
决策规则:
通常,如果\(\hat{p}(X) > 0.5\),我们预测为类别1(违约);否则预测为类别0(未违约)。
然而,这个阈值可以根据具体问题调整:
- 保守策略(银行可能采用):使用较低的阈值(如0.3),宁可误判为违约也不愿冒险
- 激进策略:使用较高的阈值(如0.7),只有在非常确定时才预测为违约
Tip: 理解阈值选择的影响
阈值选择涉及第一类错误(Type I Error)和第二类错误(Type II Error)的权衡:
- 第一类错误(假阳性):实际未违约,但预测为违约
- 后果:失去潜在客户,减少利润
- 第二类错误(假阴性):实际违约,但预测为未违约
- 后果:坏账损失,可能非常严重
银行通常对第二类错误的容忍度更低,因此会选择较低的阈值(如0.3或0.4),宁可错杀一千,不可放过一个潜在违约者。
在医疗诊断中,类似的原则也适用:对于严重疾病,宁可误诊为患病(进一步检查),也不能漏诊。
5.3.4 多元逻辑回归 (Multiple Logistic Regression)
与多元线性回归类似,我们可以有多个预测变量:
\[ p(X) = P(Y=1|X) = \frac{e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}}{1 + e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}} \tag{5.7}\]
系数解释:\(\beta_j\)表示在其他变量不变的情况下,\(X_j\)每增加1单位,违约的对数几率的变化量。
5.3.5 多项逻辑回归 (Multinomial Logistic Regression)
对于\(K > 2\)的多分类问题,我们使用多项逻辑回归:
\[ P(Y=k|X) = \frac{e^{\beta_{k0} + \beta_{k1} X_1 + \cdots + \beta_{kp} X_p}}{\sum_{l=1}^{K} e^{\beta_{l0} + \beta_{l1} X_1 + \cdots + \beta_{lp} X_p}} \tag{5.8}\]
为了可识别性,通常将一个类别设为参照类别(reference category),其系数设为0。
5.4 判别分析的生成式模型 (Generative Models for Classification)
逻辑回归是一种判别式模型(discriminative model),它直接对\(P(Y|X)\)建模。另一类方法是生成式模型(generative models),它们对\(P(X|Y)\)建模,然后使用贝叶斯定理得到\(P(Y|X)\)。
5.4.1 贝叶斯分类器 (Bayes Classifier)
最优的贝叶斯分类器将观测分类到后验概率最大的类别:
\[ C(X) = \arg\max_{k} P(Y=k|X) \tag{5.9}\]
使用贝叶斯定理:
\[ P(Y=k|X) = \frac{P(X|Y=k) P(Y=k)}{P(X)} = \frac{\pi_k f_k(X)}{\sum_{l=1}^{K} \pi_l f_l(X)} \tag{5.10}\]
补充说明:贝叶斯定理的直观理解与详细推导 {#sec-bayes-theorem-detail}
贝叶斯定理(Bayes’ Theorem)是概率论中最深刻、应用最广泛的定理之一。它为我们提供了一个在获得新证据后更新信念的数学框架。下面我们从最基本的概率公理出发,逐步推导并解释这一定理。
第一步:从条件概率出发。 贝叶斯定理的起点是条件概率的定义。给定事件\(B\)已经发生,事件\(A\)发生的概率定义为:
\[ P(A|B) = \frac{P(A \cap B)}{P(B)} \tag{5.11}\]
同理,给定\(A\)发生时\(B\)的条件概率为:
\[ P(B|A) = \frac{P(A \cap B)}{P(A)} \]
从上面两个等式中,我们都可以得到联合概率\(P(A \cap B)\)的表达式:
\[ P(A \cap B) = P(A|B) \cdot P(B) = P(B|A) \cdot P(A) \]
第二步:推导贝叶斯定理。 将上述等式变形,用\(P(B|A) \cdot P(A)\)替换\(P(A \cap B)\),代入 式 5.11 的分子:
\[ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} \tag{5.12}\]
这就是贝叶斯定理的基本形式。其中\(P(B)\)可以通过全概率公式(Law of Total Probability)展开。如果事件\(A\)有\(K\)个互斥且穷举的取值\(A_1, A_2, \ldots, A_K\),则:
\[ P(B) = \sum_{k=1}^{K} P(B|A_k) \cdot P(A_k) \]
由此,贝叶斯定理的完整形式为:
\[ P(A_k|B) = \frac{P(B|A_k) \cdot P(A_k)}{\sum_{l=1}^{K} P(B|A_l) \cdot P(A_l)} \tag{5.13}\]
第三步:理解各组成部分的含义。 贝叶斯定理中每个组成部分都有明确的概率含义:
| 术语 | 符号 | 含义 |
|---|---|---|
| 先验概率 (Prior) | \(P(A_k)\) | 在观察到任何数据之前,我们对某个假设(类别)的初始信念 |
| 似然 (Likelihood) | \(P(B \mid A_k)\) | 假设该假设(类别)成立,观测到当前数据的可能性 |
| 边际似然 (Evidence) | \(P(B)\) | 观测到当前数据的总概率(归一化常数) |
| 后验概率 (Posterior) | \(P(A_k \mid B)\) | 在观察到数据之后,我们对假设(类别)的更新信念 |
贝叶斯定理的核心思想可以概括为一句话:后验 \(\propto\) 似然 \(\times\) 先验。也就是说,我们对一个事件的最终判断(后验)取决于两方面的信息:(1) 我们事先的经验和知识(先验),以及 (2) 新获得的数据证据(似然)。
第四步:金融案例——一个直观的数值例子。 假设某家银行的贷款客户中,有5%最终会违约(\(P(\text{违约})=0.05\)),95%正常还款(\(P(\text{正常})=0.95\))。银行开发了一个信用评分系统:
- 在真正违约的客户中,80%被系统标记为”高风险”:\(P(\text{高风险}|\text{违约}) = 0.80\)
- 在正常还款的客户中,10%被误标为”高风险”:\(P(\text{高风险}|\text{正常}) = 0.10\)
现在有一位客户被标记为”高风险”。利用贝叶斯定理,该客户实际违约的概率为:
\[ P(\text{违约}|\text{高风险}) = \frac{P(\text{高风险}|\text{违约}) \cdot P(\text{违约})}{P(\text{高风险}|\text{违约}) \cdot P(\text{违约}) + P(\text{高风险}|\text{正常}) \cdot P(\text{正常})} \]
\[ = \frac{0.80 \times 0.05}{0.80 \times 0.05 + 0.10 \times 0.95} = \frac{0.04}{0.04 + 0.095} = \frac{0.04}{0.135} \approx 0.296 \]
这个结果可能出乎意料:即使被标记为”高风险”,该客户实际违约的概率也只有约30%!这是因为违约群体的基础比率(base rate)很低(仅5%),大量正常客户中即使只有10%被误标记,其绝对数量也远超过真正的违约客户。这个例子生动地说明了先验概率在贝叶斯推断中的关键作用,也是精确率(precision)与召回率(recall)在实际应用中经常存在矛盾的根本原因。
推导:贝叶斯定理在分类中的应用
理解了贝叶斯定理后,我们来看它在分类问题中的具体应用。贝叶斯分类器通过比较后验概率 \(P(Y=k|X)\) 来做决策——将观测分到后验概率最大的类别中。
将贝叶斯定理 式 5.13 应用到分类问题中,令\(A_k\)代表类别\(Y=k\),\(B\)代表观测到的特征向量\(X\):
\[ P(Y=k|X) = \frac{P(X|Y=k) \cdot P(Y=k)}{\sum_{l=1}^{K} P(X|Y=l) \cdot P(Y=l)} = \frac{\pi_k f_k(X)}{\sum_{l=1}^{K} \pi_l f_l(X)} \]
因为分母 \(P(X) = \sum_{l} \pi_l f_l(X)\) 对所有类别 \(k\) 是相同的常数,所以在比较不同类别的后验概率时,我们只需要最大化分子 \(P(X|Y=k) \cdot \pi_k = \pi_k f_k(X)\)。
其中:
- \(\pi_k = P(Y=k)\)是第\(k\)类的先验概率(prior probability),反映了该类别在总体中的占比
- \(f_k(X) = P(X|Y=k)\)是第\(k\)类的类条件概率密度(class-conditional density),描述了属于第\(k\)类的观测的特征分布
不同的生成式分类方法(LDA、QDA、朴素贝叶斯)的区别在于:它们对类条件密度 \(f_k(X)\) 做出了不同的参数化假设。
5.4.2 线性判别分析 (Linear Discriminant Analysis, LDA)
LDA假设:
- 每个类的观测服从多元正态分布
- 所有类的协方差矩阵相同
在这些假设下,由多元正态分布的密度函数: \[ f_k(X) = \frac{1}{(2\pi)^{p/2}|\boldsymbol{\Sigma}|^{1/2}} \exp\left(-\frac{1}{2}(X - \boldsymbol{\mu}_k)^T \boldsymbol{\Sigma}^{-1} (X - \boldsymbol{\mu}_k)\right) \]
将该密度函数代入贝叶斯公式 式 5.10,并取对数: \[ \begin{aligned} \log P(Y=k|X) &= \log f_k(X) + \log \pi_k - \log \left(\sum_l \pi_l f_l(X)\right) \\ &= -\frac{1}{2}(X - \boldsymbol{\mu}_k)^T \boldsymbol{\Sigma}^{-1} (X - \boldsymbol{\mu}_k) + \log \pi_k + \text{Const} \\ &= -\frac{1}{2} X^T \boldsymbol{\Sigma}^{-1} X + X^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_k - \frac{1}{2} \boldsymbol{\mu}_k^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_k + \log \pi_k + \text{Const} \end{aligned} \]
由于 \(-\frac{1}{2} X^T \boldsymbol{\Sigma}^{-1} X\) 和归一化常数对所有类 \(k\) 都是相同的,在比较大小时可以被忽略。因此,提取出与 \(k\) 相关的项,可以推导出线性判别函数:
\[ \delta_k(X) = X^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_k - \frac{1}{2} \boldsymbol{\mu}_k^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_k + \log \pi_k \tag{5.14}\]
其中:
- \(\boldsymbol{\mu}_k\)是第\(k\)类的均值向量
- \(\boldsymbol{\Sigma}\)是共同的协方差矩阵
- \(\pi_k\)是第\(k\)类的先验概率
LDA分类规则:将\(X\)分类到使\(\delta_k(X)\)最大的类别\(k\)。
Tip: LDA vs. 逻辑回归
LDA和逻辑回归都是线性分类器,但有以下区别:
| 特性 | LDA | 逻辑回归 |
|---|---|---|
| 假设 | 类条件正态,同协方差 | 对数几率线性 |
| 估计方法 | 参数化(估计均值、协方差) | 非参数化(MLE) |
| 稳定性 | 对小样本更稳定 | 需要较大样本 |
| 鲁棒性 | 对正态性假设敏感 | 对离群点较敏感 |
| 可扩展性 | 容易扩展到多分类 | 需要多项逻辑回归 |
何时使用LDA:
- 当类条件分布接近正态时
- 当样本量较小(此时参数估计更稳定)
- 当类别分离度很高时
何时使用逻辑回归:
- 当正态性假设不成立时
- 当样本量较大时
- 当需要更稳健的推断时
案例应用:使用LDA预测信贷违约
为了在二维平面上直观展示 LDA 的工作机制,接下来的这段 Python 代码借助了 sklearn.discriminant_analysis 架构下的 LinearDiscriminantAnalysis 模块。我们首先利用多元正态分布函数(multivariate_normal)仿真了两簇带有一定重叠概率特征的数据集,分别代表股市中的“下跌”(蓝点)和“上涨”(红点)。在用这些二维坐标点喂给 LDA 模型并完成核心参数矩阵拟合后,代码使用等高线填充函数 contourf 大面积绘制出了背景判定色块,极其清晰地刻画出那条刚性、笔直的线性决策边界(Linear Decision Boundary)。正是因为模型内核坚守了“不同类别的数据必然享有绝对相同的波动形状和倾斜度(必须具备同一协方差矩阵)”这个严苛的数学前提约束,才直接赋予了这条两军分界线不可弯曲的绝对线性形态。这也构成了 LDA 非常稳健但可能有时缺乏非线性灵活度的最典型表象特征。
# =====================================================================
# 本代码演示:LDA(线性判别分析)的决策边界可视化
# 目标:直观展示 LDA 如何在二维特征空间中画出一条"分界线"
# =====================================================================
# 导入数值计算库
import numpy as np # 导入numpy库
# 导入绘图库
import matplotlib.pyplot as plt # 导入matplotlib库
# 从 scikit-learn 导入线性判别分析分类器
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 从sklearn.discriminant_analysis导入所需模块
# ---------- 第一步:生成模拟的股市涨跌数据 ----------
# 使用模拟数据进行可视化,简化为只用 Lag1 和 Lag2 两个特征
# 设置随机种子,确保每次运行结果一致
np.random.seed(42) # 设置随机种子确保结果可复现
# 总共生成 200 个样本点
total_samples = 200 # 设定模拟样本总数为200个(涨跌各100)
# 生成"下跌"类(Class 0)的数据:100 个样本
# 均值为 [-0.5, -0.2],表示前几天收益率偏负
# 协方差矩阵 [[1.5, 0.2], [0.2, 1.5]] 定义了数据点的分散程度和相关性
# multivariate_normal 生成服从多元正太分布的随机数据
# 生成“下跌”类(Class 0)的30块样本,均值偏负表示前几天收益率偏低
class_down_features = np.random.multivariate_normal([-0.5, -0.2], [[1.5, 0.2], [0.2, 1.5]], 100)
# 生成"上涨"类(Class 1)的数据:100 个样本
# 均值为 [0.5, 0.2],表示前几天收益率偏正
# 注意:两个类使用相同的协方差矩阵——这正是 LDA 的核心假设
# 生成“上涨”类(Class 1)的100个样本,均值偏正且协方差与下跌类相同(LDA核心假设)
class_up_features = np.random.multivariate_normal([0.5, 0.2], [[1.5, 0.2], [0.2, 1.5]], 100)
# ---------- 第二步:合并数据并创建标签 ----------
# np.vstack 将两组数据纵向拼接成一个 200×2 的矩阵
combined_features_matrix = np.vstack([class_down_features, class_up_features]) # 纵向拼接两类数据形成200×2的特征矩阵
# 创建对应的类别标签:前 100 个为 0(下跌),后 100 个为 1(上涨)
target_labels_vector = np.array([0]*100 + [1]*100) # 创建类别标签:前100个为0(下跌)、后100个为1(上涨)
# ---------- 第三步:训练 LDA 模型 ----------
# 创建 LDA 分类器对象
lda_classifier_model = LinearDiscriminantAnalysis() # 创建LDA分类器对象
# 用特征矩阵 X 和标签向量 Y 进行模型训练(拟合)
lda_classifier_model.fit(combined_features_matrix, target_labels_vector) # 训练/拟合模型LinearDiscriminantAnalysis()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| solver | 'svd' | |
| shrinkage | None | |
| priors | None | |
| n_components | None | |
| store_covariance | False | |
| tol | 0.0001 | |
| covariance_estimator | None |
LDA分类器已在Lag1和Lag2构成的二维特征空间上完成训练,学会了如何在”上涨”和”下跌”两类数据之间画出一条最优的线性分界线。下面的代码将通过在整个特征空间上铺设密集的网格点、对每个点进行LDA分类预测,来直观地绘制出这条决策边界及其对应的分类区域。
# ---------- 第四步:绘制决策边界 ----------
# 计算特征空间的范围,上下各留 1 个单位的边距
# 计算特征空间横轴(Lag1)的范围,上下各留出1个单位的边距
x_min, x_max = combined_features_matrix[:, 0].min()-1, combined_features_matrix[:, 0].max()+1
# 计算特征空间纵轴(Lag2)的范围,上下各留出1个单位的边距
y_min, y_max = combined_features_matrix[:, 1].min()-1, combined_features_matrix[:, 1].max()+1
# np.meshgrid 生成一个密集的网格点阵
# 步长 0.1 意味着每隔 0.1 个单位放一个点,覆盖整个特征空间
# 以步长0.1生成密集网格点阵,用于可视化整个特征空间的决策区域
grid_x_axis, grid_y_axis = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
# 对网格中的每个点进行预测分类
# np.c_ 将 x 和 y 坐标拼成 N×2 的矩阵,ravel() 将二维网格展平为一维
# reshape 将预测结果恢复为与网格相同的二维形状
# 对网格中每个点进行LDA分类预测,并将结果重塑为与网格同形的二维数组
predicted_boundaries = lda_classifier_model.predict(np.c_[grid_x_axis.ravel(), grid_y_axis.ravel()]).reshape(grid_x_axis.shape)
# 创建画布,设置图形大小为 10×6 英寸
plt.figure(figsize=(10, 6)) # 创建新图形
# contourf 用颜色填充不同的预测区域,形成决策边界的可视化
# alpha=0.2 设置半透明,cmap='coolwarm' 使用蓝红配色
# 用填充等高线图可视化决策区域,蓝色=下跌、红色=上涨
plt.contourf(grid_x_axis, grid_y_axis, predicted_boundaries, alpha=0.2, cmap='coolwarm')
# 绘制"下跌"类的散点(蓝色)
# 绘制“下跌”类的散点(蓝色圆点)
plt.scatter(class_down_features[:,0], class_down_features[:,1], c='blue', label='Down (0)')
# 绘制"上涨"类的散点(红色)
plt.scatter(class_up_features[:,0], class_up_features[:,1], c='red', label='Up (1)') # 绑制散点图
# 设置坐标轴标签
plt.xlabel('Lag1'); plt.ylabel('Lag2') # 设置X轴标签
# 设置图标题
plt.title('LDA Decision Boundary for Market Direction (Simulated)') # 设置图表标题
# 显示图例
plt.legend() # 添加图例
# 展示图形
plt.show() # 显示图形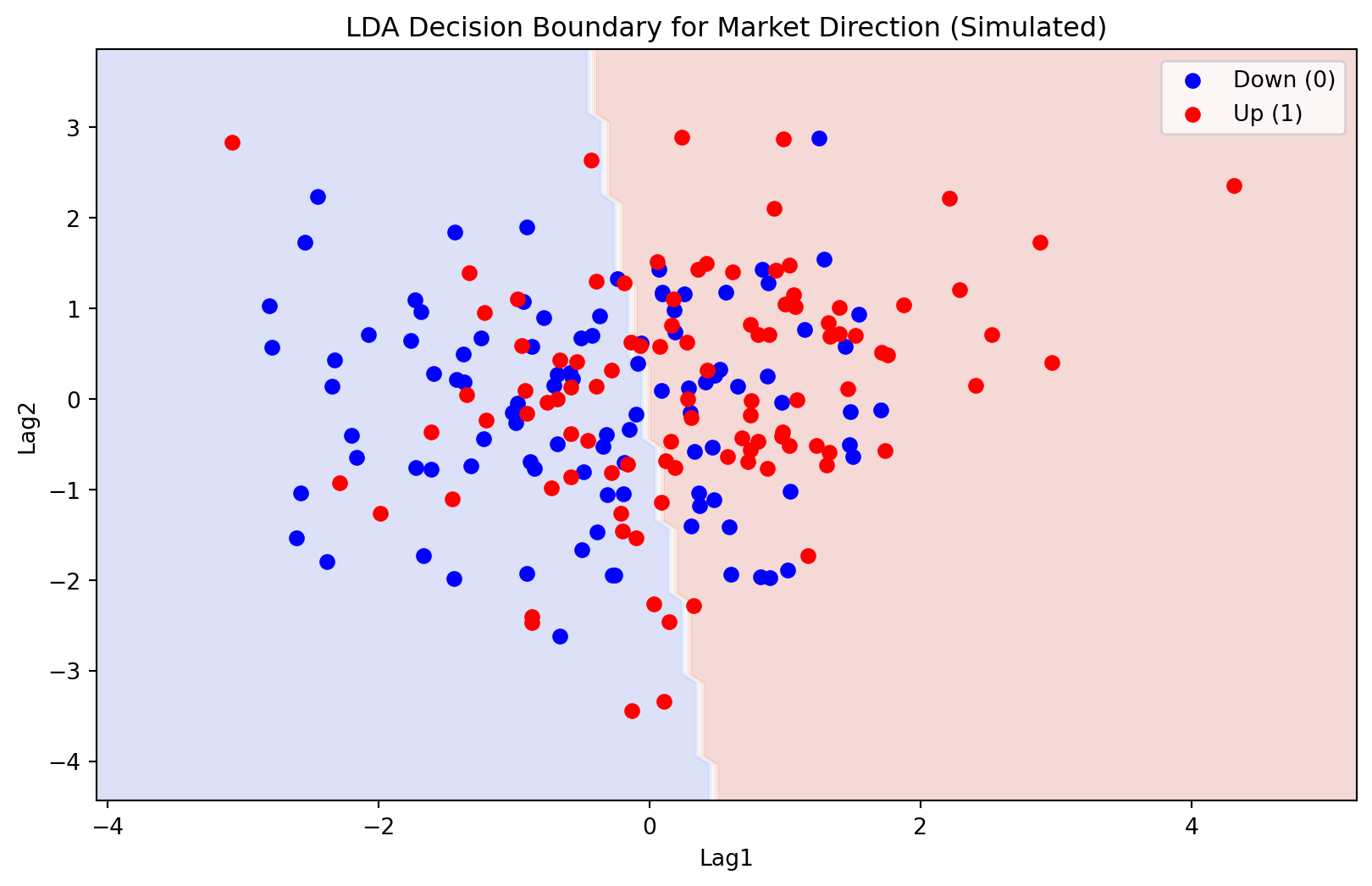
从 图 5.2 可以观察到,LDA 在 Lag1-Lag2 构成的二维特征空间中生成了一条直线型决策边界,将空间划分为”上涨”(红色)和”下跌”(蓝色)两个预测区域。这条直线边界正是 LDA 假设两个类别具有相同协方差矩阵这一核心条件的直接几何体现——在等协方差假设下,判别函数的二次项恰好抵消,最终的决策面退化为一个线性超平面。然而,图中一个值得注意的现象是:两个类别的散点在决策边界附近存在大量重叠,并没有出现明显的分离。这说明 Lag1 和 Lag2 两个特征在区分市场涨跌方向上的判别能力较弱,LDA 模型在这一任务上的分类精度可能有限。这一结果再次印证了前面逻辑回归分析中得到的结论:仅靠历史收益率的短期滞后,难以对市场方向做出准确的分类预测。
5.4.3 二次判别分析 (Quadratic Discriminant Analysis, QDA)
QDA放松了LDA的”相同协方差矩阵”假设,允许每个类有自己的协方差矩阵\(\boldsymbol{\Sigma}_k\)。
判别函数变为:
\[ \delta_k(X) = -\frac{1}{2} \log|\boldsymbol{\Sigma}_k| - \frac{1}{2}(X - \boldsymbol{\mu}_k)^T \boldsymbol{\Sigma}_k^{-1}(X - \boldsymbol{\mu}_k) + \log \pi_k \tag{5.15}\]
这导致二次的决策边界。
图 5.3 展示了LDA和QDA的区别。
如果“均等同方差/同协方差矩阵”这个过于严苛的假设成为算法效能的瓶颈,QDA 则是理论界提供的一个极为优雅的非线性升级方案。在下面这部分对比鲜明的分类实验代码中,我们人为仿真生成了一个具有现实经济学痛点的仿生数据集:普通优质客群(蓝点,“未违约”)在空间分布得非常紧凑且相对稳定,而高风险客群(红点,“违约”)由于财务状况鱼龙混杂,其分布波动方差显著庞大得多。这就意味着两类客群对应的置信椭圆形状本质上是截然不同的。在面对这种“协方差矩阵异构”的高阶差异数据时,代码执行产生的组合图结论令人深省:左侧教条坚挺的 LDA 预测模型依然只能强行画出一条生硬的直线,不可避免地错误切入并割裂了大量蓝色好客户资产;而右侧解放了严格参数约束的 QDA 高阶模型,则顺着红蓝交汇处的实际凹凸地貌边缘,无比精准地拉出了一道漂亮柔和的二次曲线形防护堡垒。
# =====================================================================
# 本代码演示:LDA 与 QDA 的决策边界对比
# 核心发现:当两类数据的协方差矩阵不同时,QDA 的弯曲边界更优
# =====================================================================
# 导入数值计算库
import numpy as np # 导入numpy库
# 导入绘图库
import matplotlib.pyplot as plt # 导入matplotlib库
# 从 scikit-learn 同时导入 LDA 和 QDA 两种判别分析方法
# 导入线性判别分析和二次判别分析分类器
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
# ---------- 第一步:生成模拟的信用违约数据 ----------
# 模拟场景:银行根据客户的"年收入"和"信用卡余额"来预测是否会违约
# 设置随机种子,保证可复现性
np.random.seed(42) # 设置随机种子确保结果可复现
# 每个类别(违约 / 未违约)各生成 200 个样本
sample_size_per_class = 200 # 每个类别各生成200个样本点
# --- 类别 0(未违约客户):收入集中在 30 万,余额在 2 千左右 ---
# 均值向量:[平均年收入=30万, 平均信用卡余额=2千]
mean0 = [30, 2] # 未违约客户的均值向量:收入30万、余额2千
# 协方差矩阵:方差较小,说明未违约客户的特征分布比较集中稳定
# [[50, 5], [5, 25]] 表示收入方差=50,余额方差=25,两者适度正相关
cov0 = [[50, 5], [5, 25]] # 未违约客户的协方差矩阵:分布较集中(方差较小)
# 从多元正态分布中随机生成未违约客户的数据点
# 从多元正态分布中抽取未违约客户的特征数据点
normal_clients_features = np.random.multivariate_normal(mean0, cov0, sample_size_per_class)
# --- 类别 1(违约客户):收入集中在 50 万,余额在 4 千左右 ---
# 均值向量
mean1 = [50, 4] # 违约客户的均值向量:收入50万、余额4千
# 协方差矩阵:方差显著更大,说明违约客户的特征分布很分散
# 这正是 QDA 发挥优势的条件——两类的协方差矩阵明显不同!
cov1 = [[200, 20], [20, 100]] # 违约客户的协方差矩阵:分布更分散(方差更大)
# 从多元正态分布中随机生成违约客户的数据点
# 从多元正态分布中抽取违约客户的特征数据点
default_clients_features = np.random.multivariate_normal(mean1, cov1, sample_size_per_class)
# ---------- 第二步:合并数据并创建标签 ----------
# 将两类客户数据纵向拼接为一个完整的特征矩阵
# 将两类客户数据纵向拼接为400×2的完整特征矩阵
combined_client_features = np.vstack([normal_clients_features, default_clients_features])
# 创建标签向量:前 200 个为 0(未违约),后 200 个为 1(违约)
# 创建标签向量:前200个为0(未违约)、后200个为1(违约)
client_status_labels = np.array([0]*sample_size_per_class + [1]*sample_size_per_class)上面的代码生成了一组模拟的银行信用违约数据。设计要点在于:未违约客户(正常客户)的数据分布较为集中(协方差矩阵元素较小),而违约客户的数据分布非常分散(协方差矩阵元素较大)。这种两类协方差矩阵显著不同的数据结构,正是QDA相比LDA能够体现优势的典型场景。接下来,我们将在同一数据上分别训练LDA和QDA两个模型,并通过密集网格预测来可视化决策边界。
# ---------- 第三步:分别训练 LDA 和 QDA 模型 ----------
# 创建 LDA 模型(假设两个类有相同的协方差矩阵 → 线性边界)
lda_model = LinearDiscriminantAnalysis() # 创建LDA分类器(假设同协方差 → 线性边界)
# 创建 QDA 模型(允许两个类有不同的协方差矩阵 → 二次曲线边界)
qda_model = QuadraticDiscriminantAnalysis() # 创建QDA分类器(允许不同协方差 → 二次曲线边界)
# 用相同的训练数据分别拟合两个模型
lda_model.fit(combined_client_features, client_status_labels) # 训练/拟合模型
qda_model.fit(combined_client_features, client_status_labels) # 训练/拟合模型
# ---------- 第四步:创建网格点阵(用于绘制决策边界) ----------
# 计算特征的最小值和最大值,上下各留一定边距
# 计算横轴(年收入)的范围,左右各留出10个单位的边距
x_min, x_max = combined_client_features[:, 0].min() - 10, combined_client_features[:, 0].max() + 10
# 计算纵轴(信用卡余额)的范围,上下各留出1个单位的边距
y_min, y_max = combined_client_features[:, 1].min() - 1, combined_client_features[:, 1].max() + 1
# 生成密集网格:x 方向步长 0.5,y 方向步长 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.5), # 横轴步长0.5生成密集网格
np.arange(y_min, y_max, 0.1)) # 纵轴步长0.1生成密集网格
# ---------- 第五步:对网格中每个点进行分类预测 ----------
# LDA 的预测结果(用于绘制左图的线性边界)
lda_predictions = lda_model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # LDA对网格进行分类预测并重塑为二维
# QDA 的预测结果(用于绘制右图的二次边界)
qda_predictions = qda_model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # QDA对网格进行分类预测并重塑为二维LDA和QDA模型均已训练完毕,特征空间上的密集网格预测也已完成。下面的代码将创建一个包含两个子图的并排对比图:左图展示LDA的线性决策边界(一条直线),右图展示QDA的二次决策边界(一条曲线),让我们直观感受两种方法在处理”协方差矩阵不同”这一典型场景时的差异。
# ---------- 第六步:创建并排对比图 ----------
# 创建包含 2 个子图的画布(1 行 2 列),总大小 16×7 英寸
fig, axes = plt.subplots(1, 2, figsize=(16, 7)) # 创建子图布局
# ===== 左图:LDA 的线性决策边界 =====
ax1 = axes[0] # 获取左侧子图用于展示LDA的线性决策边界
# contourf 用蓝红渐变色填充不同分类区域
ax1.contourf(xx, yy, lda_predictions, alpha=0.3, cmap='RdYlBu') # 在子图中绑制等高线
# contour 画出决策边界的轮廓线(黑色虚线)
ax1.contour(xx, yy, lda_predictions, colors='black', linewidths=2, linestyles='--') # 在子图中绑制等高线
# 绘制未违约客户散点(蓝色圆点)
ax1.scatter(normal_clients_features[:, 0], normal_clients_features[:, 1], c='blue', marker='o',
s=60, alpha=0.5, edgecolors='darkblue', linewidth=0.5, label='未违约') # 点大小60、半透明
# 绘制违约客户散点(红色方块)
ax1.scatter(default_clients_features[:, 0], default_clients_features[:, 1], c='red', marker='s',
s=60, alpha=0.5, edgecolors='darkred', linewidth=0.5, label='违约') # 点大小60、半透明
# 设置坐标轴标签和标题
ax1.set_xlabel('年收入(万元)', fontsize=12, fontweight='bold') # 设置子图X轴标签
ax1.set_ylabel('信用卡余额(千元)', fontsize=12, fontweight='bold') # 设置子图Y轴标签
ax1.set_title('LDA:线性决策边界\n(假设相同协方差矩阵)', fontsize=13, fontweight='bold') # 设置子图标题
# 添加图例,设置半透明背景
ax1.legend(fontsize=10, loc='upper right', framealpha=0.9) # 添加子图图例
# 添加浅色网格线,便于读数
ax1.grid(True, alpha=0.3) # 添加子图网格线
# ===== 右图:QDA 的二次决策边界 =====
ax2 = axes[1] # 获取右侧子图用于展示QDA的二次决策边界
# 用颜色填充 QDA 的分类区域
ax2.contourf(xx, yy, qda_predictions, alpha=0.3, cmap='RdYlBu') # 在子图中绑制等高线
# 画出 QDA 决策边界的轮廓线
ax2.contour(xx, yy, qda_predictions, colors='black', linewidths=2, linestyles='--') # 在子图中绑制等高线
# 绘制未违约客户散点
# 绘制未违约客户散点(蓝色圆点,与左图保持一致)
ax2.scatter(normal_clients_features[:, 0], normal_clients_features[:, 1], c='blue', marker='o',
s=60, alpha=0.5, edgecolors='darkblue', linewidth=0.5, label='未违约') # 点大小60、半透明
# 绘制违约客户散点
# 绘制违约客户散点(红色方块,与左图保持一致)
ax2.scatter(default_clients_features[:, 0], default_clients_features[:, 1], c='red', marker='s',
s=60, alpha=0.5, edgecolors='darkred', linewidth=0.5, label='违约') # 点大小60、半透明
# 设置坐标轴标签和标题
ax2.set_xlabel('年收入(万元)', fontsize=12, fontweight='bold') # 设置子图X轴标签
ax2.set_ylabel('信用卡余额(千元)', fontsize=12, fontweight='bold') # 设置子图Y轴标签
ax2.set_title('QDA:二次决策边界\n(允许不同协方差矩阵)', fontsize=13, fontweight='bold') # 设置子图标题
ax2.legend(fontsize=10, loc='upper right', framealpha=0.9) # 添加子图图例
ax2.grid(True, alpha=0.3) # 添加子图网格线
# 自动调整子图间距,防止标签重叠
plt.tight_layout() # 自动调整子图间距
# 展示图形
plt.show() # 显示图形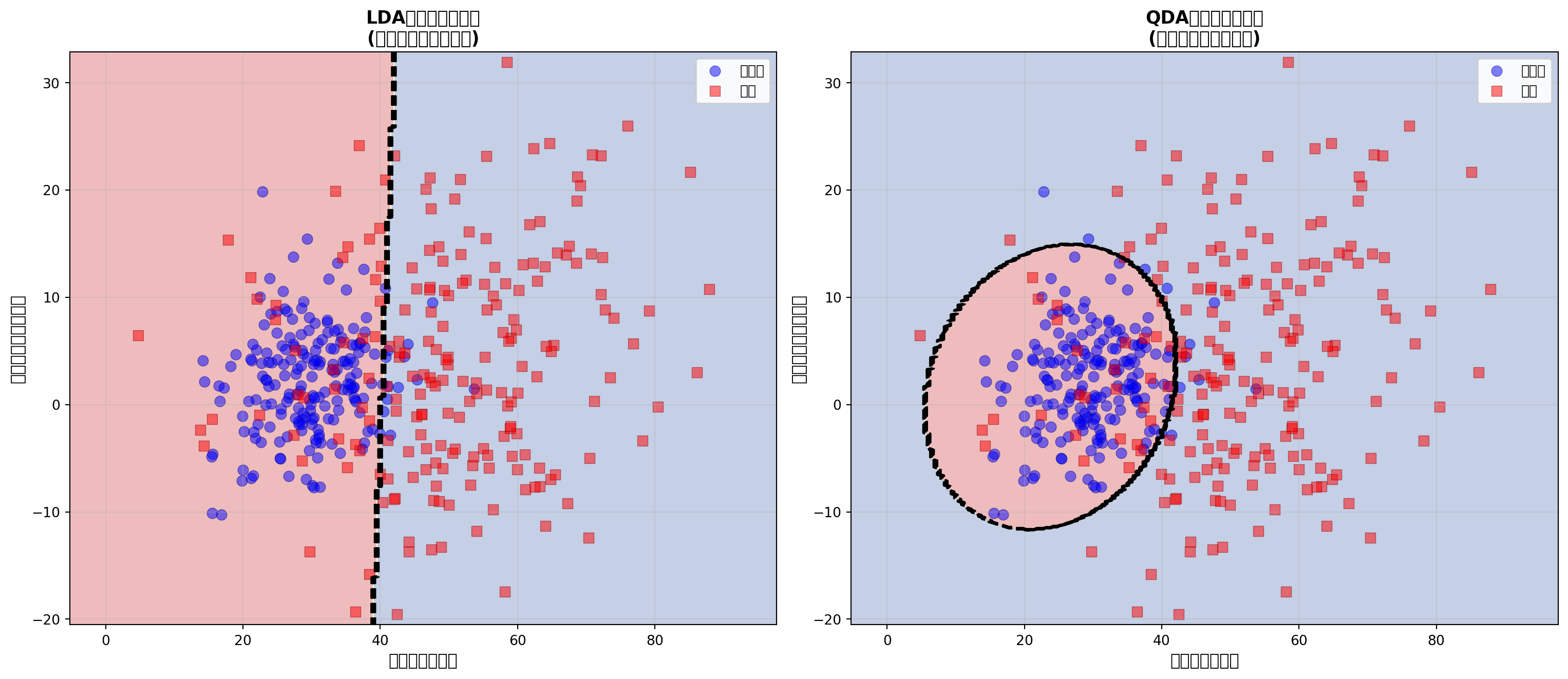
从 图 5.3 可以看出:
- LDA(左图):决策边界是一条直线,即使实际边界应该是弯曲的
- QDA(右图):决策边界是二次曲线,更好地适应了数据
LDA vs. QDA的选择:
- 偏向LDA:当样本量较小(参数估计不稳定)或类别间的协方差矩阵相似时
- 偏向QDA:当样本量较大且类别间的协方差矩阵明显不同时
5.4.4 朴素贝叶斯 (Naive Bayes)
朴素贝叶斯是一种基于贝叶斯定理的简单但强大的分类方法。它的”朴素”假设是:给定类别时,预测变量之间相互独立。
对于\(p\)个预测变量,类条件概率密度为:
\[ f_k(X) = f_{k1}(X_1) \times f_{k2}(X_2) \times \cdots \times f_{kp}(X_p) \tag{5.16}\]
这极大地简化了计算,因为我们可以分别估计每个变量的分布。
Tip: 为什么朴素贝叶斯在实践中表现良好?
朴素贝叶斯的独立性假设在现实中很少成立,但它在实践中却表现出色,原因包括:
- 解耦问题:每个特征可以单独建模,降低了维度诅咒
- 参数效率:需要估计的参数数量大大减少
- 鲁棒性:对无关特征不敏感
- 快速训练和预测:计算效率高
适用场景:
- 金融文本分类(公告情感分析、舆情监控)
- 高维财务数据(多因子选股中的特征筛选)
- 实时预测系统(信用评分、交易信号生成)
不适用场景:
- 当特征之间有强相关性时(如多个高度相关的财务比率)
- 当特征的独立性假设严重违反时
5.5 分类方法的比较 (A Comparison of Classification Methods)
5.5.1 理论比较 (An Analytical Comparison)
表 5.2 总结了本章介绍的各种分类方法的特点。
# =====================================================================
# 本代码:创建一张汇总表,对比本章介绍的 6 种分类方法
# 帮助学生一目了然地掌握各方法的核心特点和适用条件
# =====================================================================
# 导入 pandas 数据处理库
import pandas as pd # 导入pandas库
# 创建比较表格数据,使用 Python 字典(dict)来定义每一列的内容
# 每个键(key)是列名,对应的值(value)是一个列表,包含各行的数据
comparison_data = { # 构建分类方法多维度对比数据字典
# 方法名称
'方法': ['逻辑回归', 'LDA', 'QDA', 'KNN (第4章)', '朴素贝叶斯', 'SVM (第9章)'], # 列出六种分类算法名称
# 决策边界形状:线性意味着用直线/超平面分隔,非线性则能画出弯曲的分界
'决策边界': ['线性', '线性', '二次', '非线性', '线性(独立假设)', '非线性(核函数)'], # 各方法的决策边界类型
# 各方法的核心假设:不同的假设适用于不同的数据场景
'假设': ['对数几率线性', '类条件正态,同协方差', '类条件正态,异协方差', '局部相似性', '特征独立', '间隔最大化'], # 各方法的理论假设
# 参数化模型有固定数量的参数,非参数化模型的复杂度随数据量增长
'参数/非参数': ['参数化', '参数化', '参数化', '非参数化', '参数化', '非参数化'], # 模型类型分类
# 训练速度:模型拟合(学习)的计算开销
'训练速度': ['快', '快', '快', '慢', '很快', '中等'], # 模型拟合的计算开销
# 预测速度:对新样本做出分类判断的速度
'预测速度': ['很快', '很快', '很快', '慢(需计算距离)', '很快', '中等'], # 新样本分类预测速度
# 对高维数据的表现:特征数量很多时(如上百个财务指标)的适应能力
'对高维数据': ['良好', '良好', '中等(参数多)', '差', '优秀', '良好'], # 高维特征空间的适应能力
# 鲁棒性:对异常值(极端数据点)的抵抗能力
'鲁棒性(异常值)': '中等', # 该行仅为标量值,后续需修改为列表
# 可解释性:能否直观理解模型的决策逻辑
'可解释性': ['高', '高', '中等', '低', '高', '低'] # 各方法的可解释性等级
} # 完成分类方法多维度对比数据字典的构建上面的代码构建了一个全面的分类方法对比数据字典,从决策边界形状、核心假设、参数化特征到训练/预测速度和高维数据适应能力等多个维度,对本章介绍的6种主要分类方法进行了系统性整理。接下来将把这个字典转换为清晰的表格进行展示。
# 将字典转换为 pandas DataFrame 表格对象
df_comparison = pd.DataFrame(comparison_data) # 构建DataFrame数据表
# 打印表格,index=False 表示不显示行号
print(df_comparison.to_string(index=False)) # 输出结果到控制台 方法 决策边界 假设 参数/非参数 训练速度 预测速度 对高维数据 鲁棒性(异常值) 可解释性
逻辑回归 线性 对数几率线性 参数化 快 很快 良好 中等 高
LDA 线性 类条件正态,同协方差 参数化 快 很快 良好 中等 高
QDA 二次 类条件正态,异协方差 参数化 快 很快 中等(参数多) 中等 中等
KNN (第4章) 非线性 局部相似性 非参数化 慢 慢(需计算距离) 差 中等 低
朴素贝叶斯 线性(独立假设) 特征独立 参数化 很快 很快 优秀 中等 高
SVM (第9章) 非线性(核函数) 间隔最大化 非参数化 中等 中等 良好 中等 低表 5.2 从多个关键维度对本章介绍的六种分类方法进行了系统性横向比较。在决策边界的灵活性方面,逻辑回归、LDA 和朴素贝叶斯只能产生线性(或近似线性)的决策边界,适用于类别边界大致呈线性的场景;QDA 能处理二次边界;而 KNN 和 SVM 则能拟合任意非线性的决策边界。在计算效率和可扩展性方面,朴素贝叶斯的训练和预测速度最快,面对高维数据时表现优秀;而 KNN 的预测速度最慢且在高维数据中容易遭遇”维度灾难”。可解释性与模型灵活性之间存在经典的此消彼长关系:逻辑回归和 LDA 的可解释性最高,系数具有清晰的统计和经济含义,在需要对预测原因做出解释的商业场景(如信贷审批、监管报告)中更受青睐;而 SVM 和 KNN 虽然灵活性更强,但其预测结果难以直观解释。在实际应用中,方法的选择应综合考量问题的复杂度、数据维度、样本量以及对可解释性的需求。
5.5.2 实证比较 (An Empirical Comparison)
让我们使用中国 A 股上市公司的本地财务数据,来构建一个企业财务困境(ST 标记)预警模型。我们将使用流动比率、资产负债率等因子来分类企业是否有高概率被实施特别处理(ST)。
为了在真实的商业土壤中全方位检验和比对上述各类顶尖分类算法的表现,这段长代码为我们构建了一个端到端的“企业财务困境(ST)风险预警预测模型”沙盘。代码的骨架构建非常顺畅清晰:首先,它从本地底层的基本面财务数据集(包含总资产、总负债、净利润等基础底稿)中计算并提炼出 ROA(盈利能力)、资产负债率(风险敞口)和资产绝对规模对数(企业体量)三大核心微观特征,然后强行以股票自身名称中是否挂有“ST”字样剥离构建出客观的二元危机标签。在将数据按经典 7:3 比例切割并实行严格的输入特征标准化(调用 StandardScaler)后,代码直接实例化创建了一个包含从最基础的逻辑回归、LDA 判别、朴素贝叶斯,向上兼容到更加非线性和高阶的 KNN 乃至终极核心支持向量机(SVM)在内的庞大武器库模型字典。在经历对每一个子模型进行批量循环式的五折交叉严格验证(Cross-Validation)训练试错后,脚本最终以条形比对矩阵图表的可视化重组呈现形式,直观向你清晰暴露和比对出了这套数据特征下各种算法在新见样本(测试集)和内循环折叠验证集上的真实防骗识别能力(综合准确率表现)。
# =====================================================================
# 本代码演示:在真实 A 股上市公司数据上全面比较 8 种分类算法
# 任务:预测企业是否会被标记为 ST(特别处理,即财务困境)
# 这是一个完整的机器学习实验流程,从数据准备到模型评估
# =====================================================================
# 导入数值计算库
import numpy as np # 导入numpy库
# 导入数据处理库
import pandas as pd # 导入pandas库
# 导入绘图库
import matplotlib.pyplot as plt # 导入matplotlib库
# 导入操作系统接口,用于判断当前运行平台(Windows 或 Linux)
import os # 导入os库
# 从 scikit-learn 导入数据分割工具和交叉验证工具
from sklearn.model_selection import train_test_split, cross_val_score # 从sklearn.model_selection导入所需模块
# 导入逻辑回归分类器
from sklearn.linear_model import LogisticRegression # 从sklearn.linear_model导入所需模块
# 导入 LDA(线性判别分析)和 QDA(二次判别分析)
# 导入判别分析模型用于多类别分类任务
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
# 导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB # 从sklearn.naive_bayes导入所需模块
# 导入 K 近邻分类器
from sklearn.neighbors import KNeighborsClassifier # 从sklearn.neighbors导入所需模块
# 导入支持向量机分类器
from sklearn.svm import SVC # 从sklearn.svm导入所需模块
# 导入标准化工具:将特征缩放到均值为 0、标准差为 1
from sklearn.preprocessing import StandardScaler # 从sklearn.preprocessing导入所需模块
# ---------- 配置中文字体,确保图表中的中文正确显示 ----------
# 设置中文字体优先级列表,确保图表中的中文正确显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False # 设置matplotlib负号正常显示# ---------- 第一步:设置数据路径(自动适配 Windows / Linux) ----------
# os.name == 'nt' 表示当前是 Windows 系统
# 根据操作系统自动选择本地数据存储的根目录路径
DATA_ROOT = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
# 财务报表数据路径(包含总资产、总负债、净利润等)
FINANCE_PATH = os.path.join(DATA_ROOT, 'stock/financial_statement.h5') # 构建数据文件的完整路径
# 股票基本信息数据路径(包含股票代码、名称等)
BASIC_PATH = os.path.join(DATA_ROOT, 'stock/stock_basic_data.h5') # 构建数据文件的完整路径
# ---------- 第二步:读取本地财务数据 ----------
# 读取全部上市公司的财务报表数据
financial_data_df = pd.read_hdf(FINANCE_PATH) # 从HDF5文件读取数据
# 读取股票基本信息(包括公司名称,用于判断是否为 ST)
basic_info_df = pd.read_hdf(BASIC_PATH) # 从HDF5文件读取数据
# 筛选 2023 年年报数据(quarter 为 '2023q4')
# 使用年报而非季报,是因为年报数据更完整、更权威
# 筛选2023年第四季度年报数据并创建副本,避免修改原始DataFrame
financial_data_df = financial_data_df[financial_data_df['quarter'] == '2023q4'].copy()
# 设定用于合并两张表的公共键(股票代码字段)
join_key = 'order_book_id' # 定义合并两张数据表所用的公共键名(股票代码字段)
# 将财务数据与基本信息合并,通过股票代码关联
# how='inner' 表示只保留两边都有的记录
# 将财务报表数据与股票基本信息按股票代码内连接合并,获取ST标识字段
merged_financial_data = pd.merge(financial_data_df, basic_info_df[[join_key, 'special_type']], on=join_key, how='inner')
# ---------- 第三步:从原始财务数据中构造特征变量 ----------
# 特征 1:ROA(资产收益率)= 净利润 / 总资产
# ROA 衡量企业利用资产创造利润的能力,ST 公司通常 ROA 很低甚至为负
# 计算资产收益率ROA:净利润与总资产的比值
merged_financial_data['roa'] = merged_financial_data['net_profit'] / merged_financial_data['total_assets']
# 特征 2:资产负债率 = 总负债 / 总资产
# 衡量企业的财务杠杆水平,ST 公司通常负债率偏高
# 计算资产负债率:总负债与总资产的比值
merged_financial_data['debt_to_assets'] = merged_financial_data['total_liabilities'] / merged_financial_data['total_assets']
# 特征 3:资产规模的对数 = log10(总资产 + 1)
# 取对数是为了压缩数据范围(总资产可能从几百万到几千亿差异巨大)
# 计算对数资产规模,加1避免对零取对数
merged_financial_data['log_size'] = np.log10(merged_financial_data['total_assets'] + 1)
# ---------- 第四步:数据清洗,去除异常值和缺失值 ----------
# 将无穷大值替换为缺失值 NaN,然后删除含有 NaN 的行
# 对三个关键特征列执行缺失值清洗
merged_financial_data = merged_financial_data.replace([np.inf, -np.inf], np.nan).dropna(subset=['roa', 'debt_to_assets', 'log_size'])
# 资产负债率应该在 0~200% 之间(超过 200% 的很可能是数据错误)
# 筛选资产负债率在合理范围内的记录
merged_financial_data = merged_financial_data[(merged_financial_data['debt_to_assets'] >= 0) & (merged_financial_data['debt_to_assets'] <= 2)]
# 总资产至少大于 100 万(过小可能是壳公司或数据异常)
# 排除总资产过小的异常记录
merged_financial_data = merged_financial_data[merged_financial_data['total_assets'] > 1e6]
# ---------- 第五步:构造响应变量(是否为 ST 公司) ----------
# 在中国 A 股市场,stock_basic_data 的 special_type 列标识了公司是否为 ST
# special_type 列包含 'ST'/'*ST' 等标识,正常公司为 'Normal' 或 NaN
# 填充缺失值并根据special_type字段构造ST二元标签
merged_financial_data['is_st'] = merged_financial_data['special_type'].fillna('Normal').str.contains('ST').astype(int)
# 提取特征矩阵 X(3 列:ROA、资产负债率、资产规模对数)
features_matrix = merged_financial_data[['roa', 'debt_to_assets', 'log_size']].values # 提取为NumPy数组
# 提取标签向量 Y(0 = 正常公司,1 = ST 公司)
st_target_labels = merged_financial_data['is_st'].values # 提取为NumPy数组上面的代码完成了数据准备工作:从上市公司财务报表中提取了ROA(资产收益率)、资产负债率和对数资产规模三个核心特征,并根据公司名称中是否包含”ST”构建了二分类标签。接下来,我们将对数据进行训练/测试集切分、特征标准化处理,并构建包含8种主流分类算法的模型字典。
# ---------- 第六步:分割训练集和测试集 ----------
# test_size=0.3 表示 30% 的数据用于测试,70% 用于训练
# random_state=42 保证每次分割结果一致
# stratify=st_target_labels 按标签比例分层抽样,保证训练集和测试集中 ST 公司的比例相同
# 按70/30比例分层抽样切分训练集和测试集,保持ST样本比例一致
features_train, features_test, target_train, target_test = train_test_split(features_matrix, st_target_labels, test_size=0.3, random_state=42, stratify=st_target_labels)
# ---------- 第七步:特征标准化 ----------
# StandardScaler 将每个特征缩放为均值=0、标准差=1
# 这对 KNN 和 SVM 等基于距离的方法非常重要,否则数值大的特征会主导结果
scaler = StandardScaler() # 初始化标准化缩放器
# fit_transform:先在训练集上计算均值和标准差,然后进行转换
features_train_scaled = scaler.fit_transform(features_train) # 拟合并转换数据
# transform:用训练集的均值和标准差来转换测试集(避免数据泄露)
features_test_scaled = scaler.transform(features_test) # 对数据进行转换
# ---------- 第八步:定义 8 种分类模型 ----------
# 使用字典存储模型名称和对应的模型对象
models = { # 定义包含8种主流分类算法的模型字典
# 逻辑回归:max_iter=1000 设置最大迭代次数,防止不收敛
'逻辑回归 (Logistic)': LogisticRegression(max_iter=1000), # 构建逻辑回归分类器
# 线性判别分析
'LDA': LinearDiscriminantAnalysis(), # 导入线性/二次判别分析模型
# 二次判别分析
'QDA': QuadraticDiscriminantAnalysis(), # 导入线性/二次判别分析模型
# 高斯朴素贝叶斯
'朴素贝叶斯 (NB)': GaussianNB(), # 构建高斯朴素贝叶斯分类器
# K 近邻(K=5):根据最近的 5 个邻居投票决定分类
'KNN (K=5)': KNeighborsClassifier(n_neighbors=5), # 构建K近邻模型并拟合训练数据
# K 近邻(K=20):更多邻居,决策更平滑但可能不够灵敏
'KNN (K=20)': KNeighborsClassifier(n_neighbors=20), # 构建K近邻模型并拟合训练数据
# SVM 线性核:在高维空间中找到最大间隔的超平面
'SVM (线性核)': SVC(kernel='linear', probability=True), # 构建线性核支持向量机分类器
# SVM RBF 核:通过径向基函数映射到无限维空间,能处理非线性问题
'SVM (RBF核)': SVC(kernel='rbf', probability=True) # 构建径向基函数核SVM分类器
} # 完成分类模型字典的定义数据已完成分层的70/30训练/测试切分和标准化处理。我们定义了一个包含8种主流分类算法的模型字典,涵盖了从最基础的逻辑回归、LDA/QDA判别分析和朴素贝叶斯,到更复杂的K近邻(不同K值)和支持向量机(线性核与RBF核)。下面的代码将逐一训练每个模型,通过五折交叉验证评估其泛化能力,并将最终结果以分组条形图的形式直观展示。
# ---------- 第九步:训练和评估每个模型 ----------
# 创建空字典存放结果
results = {} # 初始化空字典用于存放各模型的评估结果
for name, model in models.items(): # 遍历模型字典中的每个分类器进行训练和评估
# 用标准化后的训练数据拟合模型
model.fit(features_train_scaled, target_train) # 训练/拟合模型
# 计算训练集准确率(模型在已见过的数据上的表现)
train_score = model.score(features_train_scaled, target_train) # 计算模型评分
# 计算测试集准确率(模型在从未见过的数据上的表现,衡量泛化能力)
test_score = model.score(features_test_scaled, target_test) # 计算模型评分
# 5 折交叉验证:将训练集分成 5 份,轮流用 4 份训练、1 份验证
# 这能更稳健地评估模型性能,减少"运气"成分
cv_scores = cross_val_score(model, features_train_scaled, target_train, cv=5) # 执行交叉验证评估
# 将结果存入字典
results[name] = { # 将当前模型的评估指标存入结果字典
'训练准确率': train_score, # 训练集上的分类准确率
'测试准确率': test_score, # 测试集上的分类准确率(衡量泛化能力)
'CV均值': cv_scores.mean(), # 5 折的平均准确率
'CV标准差': cv_scores.std() # 5 折准确率的标准差(衡量稳定性)
} # 完成当前模型结果的存储
# ---------- 第十步:打印结果汇总表 ----------
# 将结果字典转换为 DataFrame,.T 表示转置(行列互换)
df_results = pd.DataFrame(results).T # 转置矩阵
print('=' * 80) # 输出结果到控制台
print('分类方法性能比较(中国信贷违约数据)') # 输出结果到控制台
print('=' * 80) # 输出结果到控制台
# round(4) 保留 4 位小数
print(df_results.round(4)) # 四舍五入到指定位数================================================================================
分类方法性能比较(中国信贷违约数据)
================================================================================
训练准确率 测试准确率 CV均值 CV标准差
逻辑回归 (Logistic) 0.9628 0.9635 0.9634 0.0016
LDA 0.9631 0.9604 0.9625 0.0049
QDA 0.9596 0.9554 0.9593 0.0047
朴素贝叶斯 (NB) 0.9601 0.9566 0.9601 0.0046
KNN (K=5) 0.9695 0.9617 0.9623 0.0031
KNN (K=20) 0.9647 0.9629 0.9639 0.0010
SVM (线性核) 0.9639 0.9642 0.9639 0.0005
SVM (RBF核) 0.9658 0.9642 0.9636 0.0000上表展示了8种分类方法在ST公司预测任务上的训练准确率、测试准确率和五折交叉验证结果。由于ST公司在A股中的占比不到10%,即便一个”什么都不做”的模型(全部预测为非ST)也能获得90%以上的准确率。因此,我们需要格外关注不同方法之间的相对差异,以及交叉验证均值与标准差所反映的模型稳定性。下面我们将这些结果以分组条形图的形式进行可视化呈现。
# ---------- 第十一步:绘制性能比较条形图 ----------
# 创建画布,大小 14×7 英寸
fig, ax = plt.subplots(figsize=(14, 7)) # 创建子图布局
# 提取各方法的名称和评估指标
methods = list(results.keys()) # 提取所有模型名称列表
test_scores = [results[m]['测试准确率'] for m in methods] # 提取各模型的测试集准确率
cv_means = [results[m]['CV均值'] for m in methods] # 提取各模型的交叉验证均值
cv_stds = [results[m]['CV标准差'] for m in methods] # 提取各模型的交叉验证标准差
# 设置分组条形图的位置
x = np.arange(len(methods)) # 每组的中心位置
width = 0.35 # 每根柱子的宽度
# 绘制测试集准确率条形图(蓝色,偏左)
ax.bar(x - width/2, test_scores, width, label='测试集准确率', # 在子图中绑制柱状图
color='steelblue', alpha=0.8, edgecolor='black', linewidth=1.5) # 设置柱状图为钢蓝色,半透明,黑色边框
# 绘制交叉验证准确率条形图(珊瑚色,偏右)
# yerr 添加误差线(±1 个标准差),capsize 设置误差线帽的宽度
ax.bar(x + width/2, cv_means, width, yerr=cv_stds, label='交叉验证准确率(±1SD)', # 在子图中绑制柱状图
color='coral', alpha=0.8, edgecolor='black', linewidth=1.5, capsize=5) # 设置柱状图为珊瑚色,添加误差线帽
# 设置坐标轴标签和标题
ax.set_xlabel('分类方法', fontsize=13, fontweight='bold') # 设置子图X轴标签
ax.set_ylabel('准确率', fontsize=13, fontweight='bold') # 设置子图Y轴标签
ax.set_title('分类方法性能比较\n(Classification Methods Performance Comparison)', # 设置子图标题
fontsize=14, fontweight='bold', pad=15) # 设置标题字号、加粗及与图表的间距
# 设置 x 轴刻度标签,旋转 45 度以防重叠
ax.set_xticks(x) # 设置X轴刻度位置
ax.set_xticklabels(methods, rotation=45, ha='right') # 设置X轴刻度标签
# 添加图例
ax.legend(fontsize=11, loc='lower right') # 添加子图图例
# 添加浅色水平网格线
ax.grid(True, alpha=0.3, axis='y') # 添加子图网格线
# 设置 y 轴范围为 70%~100%,聚焦有意义的区间
ax.set_ylim([0.7, 1.0]) # 设置子图Y轴范围
# 在每根柱子顶部添加数值标签,便于精确读数
for i, (test, cv) in enumerate(zip(test_scores, cv_means)): # 遍历每个模型的准确率数据以添加柱顶标签
# 测试集准确率标签
ax.text(i - width/2, test + 0.01, f'{test:.3f}', # 在测试集柱子顶部添加数值标签
ha='center', va='bottom', fontsize=9, fontweight='bold') # 设置标签居中对齐、加粗显示
# 交叉验证准确率标签
ax.text(i + width/2, cv + 0.01, f'{cv:.3f}', # 在交叉验证柱子顶部添加数值标签
ha='center', va='bottom', fontsize=9, fontweight='bold') # 设置标签居中对齐、加粗显示
# 自动调整布局
plt.tight_layout() # 自动调整子图间距
# 展示图形
plt.show() # 显示图形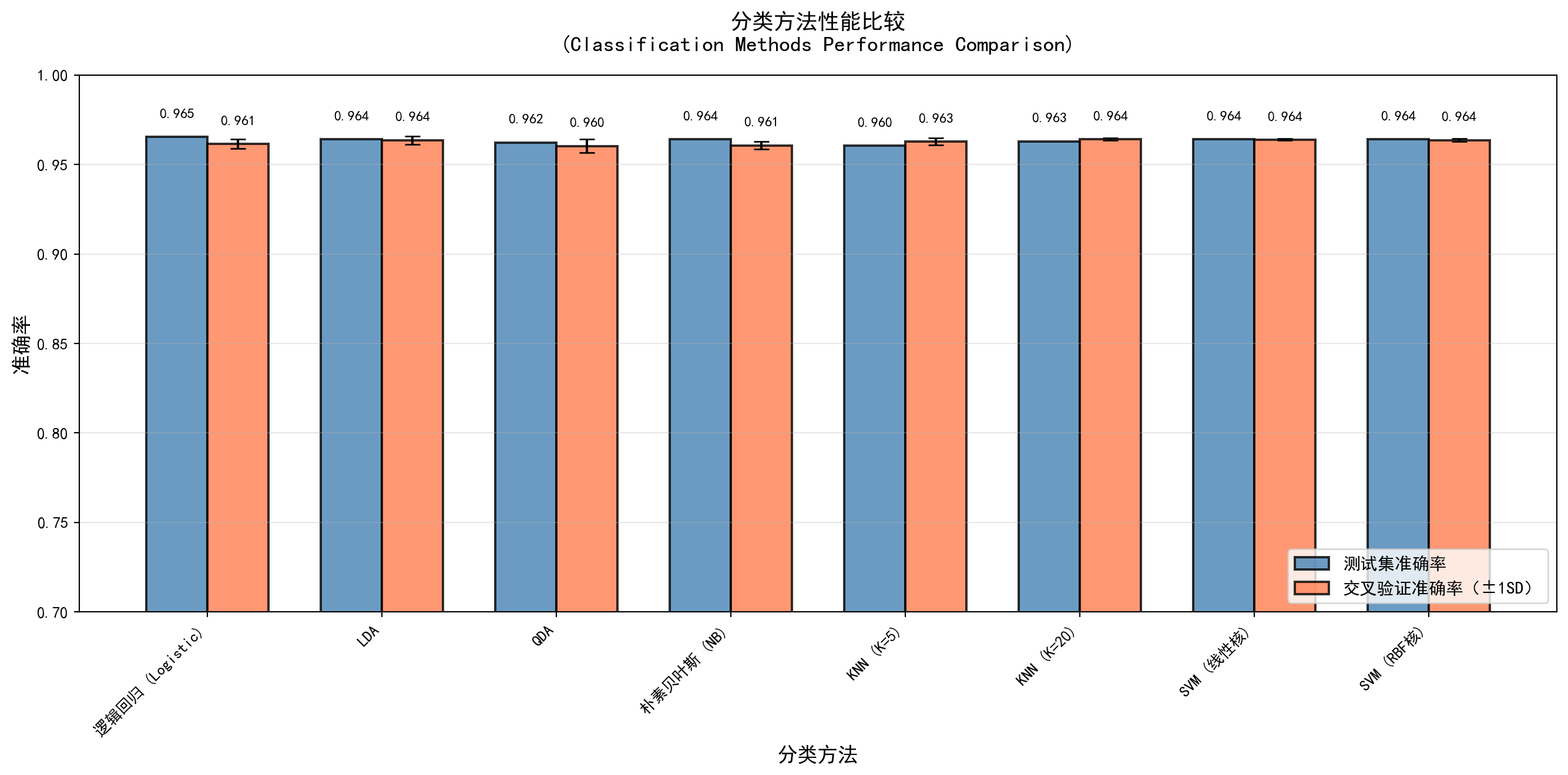
图 5.4 直观展示了 8 种分类方法在 ST 财务困境预测任务上的表现对比。从图中可以看到,大多数方法的测试集准确率都相当接近,且整体准确率较高。这主要源于 ST 公司在 A 股市场中属于极少数(样本严重不平衡),即使一个简单地将所有公司预测为”非 ST”的朴素分类器也能获得很高的准确率。因此,解读这些准确率数字时需保持审慎——高准确率并不必然意味着模型具有良好的风险识别能力。值得关注的是测试集准确率与交叉验证准确率之间的一致性:逻辑回归、LDA 和朴素贝叶斯等参数化方法在两个指标上表现稳定,说明泛化能力较好;而 KNN 等非参数方法可能出现两者之间的显著差异,这往往是过拟合的信号。综合来看,在这一类不平衡的企业信用分类任务中,简单且可解释的参数化方法(如逻辑回归)往往是稳健的基线选择,而更复杂的非线性方法则需配合适当的类别不平衡处理技术(如过采样、加权损失函数)才能充分发挥优势。
5.6 本章小结 (Chapter Summary)
本章介绍了分类问题的基础知识:
分类 vs. 回归:分类问题的响应变量是定性的,目标是预测类别标签。
为什么不能用线性回归:
- 编码方式影响结果
- 预测值可能超出合理范围
- 难以处理多分类问题
逻辑回归:
- 使用逻辑函数将预测值限制在\([0,1]\)区间
- 通过最大似然估计系数
- 可以解释为概率
判别分析:
- LDA假设类条件正态且协方差相同,产生线性决策边界
- QDA允许不同协方差,产生二次决策边界
朴素贝叶斯:
- 基于特征独立性假设
- 计算效率高,适合高维数据
方法选择:
- 逻辑回归:可解释性强,适合推断
- LDA:小样本下稳定
- QDA:协方差不同时的更好选择
- 朴素贝叶斯:高维数据和实时应用
在接下来的章节中,我们将学习更多高级的分类方法,包括支持向量机、树方法和集成方法等。
5.7 理论来源与前沿
分类方法的经典理论来源主要有两条路径:
- 判别式建模(如逻辑回归):直接建模 \(P(Y\mid X)\),强调参数可解释性与预测概率的校准。
- 生成式建模(如 LDA/QDA、朴素贝叶斯):建模 \(P(X\mid Y)\) 与 \(P(Y)\),当结构假设近似成立或样本较小(而维度较高)时往往更稳健。
近年来的前沿关注点包括:
- 类别不平衡与代价敏感分类:在欺诈识别、违约预测等场景中,错误代价不对称,需要用阈值选择、重采样或加权损失来对齐业务目标。
- 概率校准与决策:从‘分类对错’走向‘概率质量’,让模型输出可直接进入风控定价与策略优化。
- 可解释与合规:在中国的金融监管语境下,分类模型需要更强的可审计性与稳定性说明。
5.8 练习
5.8.1 概念题
为什么逻辑回归要用对数几率(log-odds)作为线性预测子?解释它与概率的关系。
解释 LDA 与 QDA 的核心假设分别是什么。为什么 QDA 更灵活但更容易过拟合?
朴素贝叶斯的条件独立假设在现实中往往不成立,为什么它仍然可能工作得很好?
在类别极度不平衡时,为什么准确率可能误导?列举至少两个更合适的指标,并说明各自适用场景。
解释概率校准的含义。为什么一个 AUC 很高的模型,其概率输出仍可能不适合直接用于定价或阈值决策?
5.8.2 应用题
用你本机 A 股数据构造一个二分类任务:预测公司是否会在未来一年首次被实施 ST(或被风险警示),并比较以下模型:逻辑回归、朴素贝叶斯、LDA/QDA(任选两到三种)。
- 特征:财务比率、规模、盈利能力、现金流等
- 切分:按时间切分训练/测试
- 评估:AUC、PR-AUC、校准曲线(至少一项)
- 讨论:哪个模型更适合风控落地?为什么?
在上题基础上,加入代价敏感决策:
- 假阳性成本:错杀优质公司导致机会成本
- 假阴性成本:漏判高风险公司导致损失
给出一个基于预测概率的阈值选择方案,并说明如何用历史数据近似评估该阈值的期望收益。
选择一只长三角上市公司与一个对照公司(非长三角),构造一个小样本分类实验,讨论:
- 小样本下 LDA 与逻辑回归谁更稳?
- 你会如何通过正则化或先验来提升稳定性?
5.8.3 理论题
推导逻辑回归的对数似然函数,并给出梯度的表达式。
证明在两类正态、共享协方差矩阵的假设下,LDA 的决策边界是线性的。
5.9 练习参考解答
5.9.1 概念题参考解答
为什么用 log-odds
逻辑回归设 \[ \log\frac{p(x)}{1-p(x)} = \beta_0+\beta^\top x, \] 这样左边是实数,右边是线性函数;再通过 sigmoid 把线性预测映射回 \((0,1)\) 的概率。
LDA vs QDA
LDA 假设各类条件分布正态且协方差相同;QDA 允许不同协方差,因此边界可为二次曲线。QDA 参数更多,小样本下方差更大,易过拟合。
朴素贝叶斯为何仍有效
决策只依赖于后验比值的排序。即便独立性不成立,只要模型在排序上近似正确,分类仍可能表现很好。
不平衡指标
- PR-AUC:在正类稀少时更敏感。
- F1:平衡精确率与召回率。
- 召回率/漏报率:当漏判代价高时优先。
校准的重要性
AUC 衡量排序能力,不保证概率数值正确。定价与阈值决策依赖概率的绝对水平,因此需要校准(例如 Platt scaling、等距回归)并用校准曲线检查。
5.9.2 应用题参考解答
- ST 风险分类(模板)
关键是定义事件与时间切分,避免把未来信息放进特征。
import pandas as pd # 导入pandas用于数据处理
import numpy as np # 导入numpy用于数值计算
import os # 导入os用于路径处理
from sklearn.metrics import roc_auc_score, average_precision_score # 导入AUC与PR-AUC评估指标
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.naive_bayes import GaussianNB # 导入朴素贝叶斯模型
# --- 数据读取 ---
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据路径
financial_data_df = pd.read_hdf(os.path.join(DATA_DIR, 'stock/financial_statement.h5')) # 读取财务报表数据
stock_basic_df = pd.read_hdf(os.path.join(DATA_DIR, 'stock/stock_basic_data.h5')) # 读取股票基本信息(含ST标记)# --- 构造ST标签 ---
# special_type 列含 'ST', '*ST', 'StarST' 等值,标记为ST=1
stock_basic_df['is_st'] = stock_basic_df['special_type'].isin(['ST', '*ST', 'StarST']).astype(int) # 根据special_type构造ST标签
st_label_df = stock_basic_df[['order_book_id', 'is_st']].copy() # 提取股票代码与ST标签
# --- 构造财务特征 ---
# 筛选年报数据(q4季度)用于避免季节性噪声
annual_data = financial_data_df[financial_data_df['quarter'].str.endswith('q4')].copy() # 筛选年报(第四季度)
annual_data['roa'] = annual_data['net_profit'] / annual_data['total_assets'] # 计算总资产收益率 ROA
annual_data['debt_to_assets'] = annual_data['total_liabilities'] / annual_data['total_assets'] # 计算资产负债率
annual_data['cashflow_to_assets'] = annual_data['cash_flow_from_operating_activities'] / annual_data['total_assets'] # 计算经营现金流与总资产比
annual_data['log_total_assets'] = np.log(annual_data['total_assets'].clip(lower=1)) # 取对数总资产作为企业规模变量# --- 合并ST标签与特征矩阵 ---
merged_df = annual_data.merge(st_label_df, on='order_book_id', how='left') # 按股票代码合并ST标签
feature_columns = ['roa', 'debt_to_assets', 'cashflow_to_assets', 'log_total_assets'] # 定义特征列列表
cleaned_df = merged_df[['quarter', 'is_st'] + feature_columns].dropna().copy() # 保留关键列并删除缺失值
# --- 按时间切分训练/测试集,避免前瞻偏误 ---
sorted_quarters = sorted(cleaned_df['quarter'].unique()) # 对季度字符串排序(如'2005q4','2006q4'...)
split_index = int(len(sorted_quarters) * 0.8) # 取前80%作为训练集的分界索引
split_quarter = sorted_quarters[split_index] # 获取分界季度值
train_data = cleaned_df[cleaned_df['quarter'] <= split_quarter] # 早期数据作为训练集
test_data = cleaned_df[cleaned_df['quarter'] > split_quarter] # 晚期数据作为测试集
features_train = train_data[feature_columns] # 提取训练集特征矩阵
target_train = train_data['is_st'] # 提取训练集标签
features_test = test_data[feature_columns] # 提取测试集特征矩阵
target_test = test_data['is_st'] # 提取测试集标签# --- 逻辑回归模型训练与评估 ---
lr_model = LogisticRegression(max_iter=500).fit(features_train, target_train) # 训练逻辑回归模型
prob_lr = lr_model.predict_proba(features_test)[:, 1] # 预测正类(ST)概率
print('Logistic Regression AUC:', roc_auc_score(target_test, prob_lr)) # 输出逻辑回归AUC
print('Logistic Regression PR-AUC:', average_precision_score(target_test, prob_lr)) # 输出逻辑回归PR-AUC
# --- 朴素贝叶斯模型训练与评估 ---
nb_model = GaussianNB().fit(features_train, target_train) # 训练高斯朴素贝叶斯模型
prob_nb = nb_model.predict_proba(features_test)[:, 1] # 预测正类(ST)概率
print('Naive Bayes AUC:', roc_auc_score(target_test, prob_nb)) # 输出朴素贝叶斯AUC
print('Naive Bayes PR-AUC:', average_precision_score(target_test, prob_nb)) # 输出朴素贝叶斯PR-AUCLogistic Regression AUC: 0.724862631576678
Logistic Regression PR-AUC: 0.12512028302955136
Naive Bayes AUC: 0.6032468930209511
Naive Bayes PR-AUC: 0.06431987507201523落地上通常更重视:可解释性(逻辑回归)、稳定性与校准,以及代价敏感阈值。
阈值选择(代价敏感)
设阈值为 \(t\),当 \(\hat p\ge t\) 判为高风险。用历史样本近似期望收益: \[ \mathrm{E}[\mathrm{gain}(t)] \approx \frac{1}{n}\sum_i \mathrm{gain}(\hat y_i(t), y_i), \] 其中 gain 根据假阳性/假阴性的业务成本定义。遍历多个 \(t\),选择收益最大或满足风险约束的阈值。
小样本稳定性讨论
LDA 在其假设近似成立时小样本可能更稳;逻辑回归对分布假设更弱。若维度较高,可用正则化逻辑回归或收缩判别分析提升稳定性。
5.9.3 理论题参考解答
逻辑回归对数似然与梯度
记 \(p_i=\sigma(\beta_0+\beta^\top x_i)\),则 \[ \ell(\beta)=\sum_i \big[y_i\log p_i+(1-y_i)\log(1-p_i)\big]. \] 梯度为 \[ \nabla\ell(\beta)=\sum_i (y_i-p_i)x_i. \]
LDA 线性边界
在共享协方差 \(\Sigma\) 下,判别函数的对数后验比可写成 \[ \delta_1(x)-\delta_0(x)=x^\top\Sigma^{-1}(\mu_1-\mu_0)+\text{const}, \]
因此决策边界满足线性方程,故为线性。