import pandas as pd # 数据分析库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
from sklearn.decomposition import PCA # 主成分分析
from sklearn.preprocessing import StandardScaler # 数据标准化工具
# 1. 加载数据
import os # 文件系统操作
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
path_fin = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 财务报表文件路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 股票基本信息文件路径
financial_statements = pd.read_hdf(path_fin) # 读取上市公司财务报表数据
stock_basic_data = pd.read_hdf(path_basic) # 读取股票基本信息数据
# 2. 数据清洗与特征构造
# 我们尽量选取同一报告期的数据,例如2022年年报(截止日期 2022-12-31)
# 由于 h5 可能没有 end_date,我们用 info_date 近似或选取最近一期
# 转换日期列为datetime类型,便于后续时间筛选
financial_statements['info_date'] = pd.to_datetime(financial_statements['info_date']) # 将列转换为日期时间类型
# 取每只股票最新的财报 (假设数据包含多个时期)
# 更好的做法是选特定年份。这里取每个股票在2023-01-01 之后发布的最新一份年报
recent_financials = financial_statements[financial_statements['info_date'] > '2023-01-01'].sort_values('info_date').groupby('order_book_id').tail(1) # 筛选2023年后最新一期财报
# 合并基本信息 (获取行业):stock_basic_data 中行业列名为 citics_2019_l1_name,此处重命名为 industry_name 便于后续引用
stock_basic_with_industry = stock_basic_data[['order_book_id', 'citics_2019_l1_name', 'province']].rename(columns={'citics_2019_l1_name': 'industry_name'}) # 提取并重命名行业分类列
merged_financial_data = pd.merge(recent_financials, stock_basic_with_industry, on='order_book_id', how='inner') # 合并财务数据与基本信息
# 仅保留长三角地区(上海、江苏、浙江、安徽)的上市公司进行分析
yangtze_river_delta_provinces = ['上海市', '江苏省', '浙江省', '安徽省'] # 定义长三角省份列表(省份名含行政后缀)
merged_financial_data = merged_financial_data[merged_financial_data['province'].isin(yangtze_river_delta_provinces)].copy() # 筛选长三角地区上市公司13 无监督学习(Unsupervised Learning)
在前面的章节中,我们主要讨论了*监督学习**方法,如回归和分类。在监督学习中,我们通常有\(p\) 个特征\(X_1, X_2, \ldots, X_p\) 以及一个响应变量\(Y\),目标是利用 \(X\) 来预测\(Y\)。
本章将转向无监督学习,这是一类统计工具,用于我们只有特征 \(X_1, X_2, \ldots, X_p\) 但没有响应变量\(Y\) 的情形。无监督学习的目标是发现关于这些测量的有趣模式:
- 是否有一种信息丰富的方式来可视化数据。
- 能否发现变量或观测值中的子群体。
无监督学习的挑战
与监督学习相比,无supervised 学习通常更具挑战性:
- 没有明确的目标:没有响应变量来指导学习过程
- 结果难以评估:缺乏像交叉验证这样通用的评估方法
- 更主观:结果更多依赖研究者的判断
然而,无监督学习在数据探索和模式发现中至关重要。
13.1 无监督学习的主要类型
- 主成分分析(PCA):降维和可视化
- 聚类分析:发现数据中的子群体
- 关联规则挖掘:发现变量间的关联(如购物篮分析)
- 异常检测:识别数据中的异常点
本章重点介绍前两种方法。
13.2 主成分分析(PCA)
13.2.1 PCA 的基本思想
假设我们有\(n\) 个观测,每个观测有\(p\) 个特征。当 \(p\) 很大时:
- 如何可视化数据?
- 是否能找到数据的低维表示,保留大部分信息?
核心思想:找到数据变化最大的方向,用这些方向来表示数据。
PCA 的直观解释
想象你在拍摄一个三维物体:
- 从某个角度拍摄,只能看到物体的部分信息
- 如果你找到了最佳拍摄角度,可以用一张二维照片最大程度地展现三维物体
- PCA 就是在寻找数据的”最佳拍摄角度
在数学上,PCA 寻找的是数据方差最大的方向,这些方向称为主成分。
13.2.2 第一主成分
第一主成分是特征的标准化线性组合:
\[ Z_1 = \phi_{11}X_1 + \phi_{21}X_2 + \cdots + \phi_{p1}X_p \tag{13.1}\]
满足约束: \[ \sum_{j=1}^{p} \phi_{j1}^2 = 1 \tag{13.2}\]
使得 \(Z_1\) 的方差最大化。
优化问题:
\[ \max_{\phi_{11}, \ldots, \phi_{p1}} \left\{ \frac{1}{n} \sum_{i=1}^{n} \left( \sum_{j=1}^{p} \phi_{j1} x_{ij} \right)^2 \right\} \]
约束:{j=1}^{p} {j1}^2 = 1$
数学推导:PCA 的奇异值分的(SVD) 视角
虽然上面是从方差最大化的角度定义主成分,但在实际计算和深层代数理论中,PCA 的*奇异值分的(Singular Value Decomposition, SVD)** 密不可分。
假设中心化(均值为0)后的\(n \times p\) 数据矩阵的\(\mathbf{X}\)。根据线性代数定理,任何实矩的\(\mathbf{X}\) 都可以分解为。 \[ \mathbf{X} = \mathbf{U} \mathbf{\Sigma} \mathbf{V}^T \] 其中。 - \(\mathbf{U}\) 的\(n \times n\) 的正交矩阵(\(\mathbf{U}^T\mathbf{U} = \mathbf{I}\)),其列的\(\mathbf{X}\mathbf{X}^T\) 的特征向量。 - \(\mathbf{V}\) 的\(p \times p\) 的正交矩阵(\(\mathbf{V}^T\mathbf{V} = \mathbf{I}\)),其列的\(\mathbf{X}^T\mathbf{X}\) 的特征向量。 - \(\mathbf{\Sigma}\) 的\(n \times p\) 的对角矩阵,对角线元的\(\sigma_i\) 称为奇异值,且 \(\sigma_1 \geq \sigma_2 \geq \cdots \geq 0\)。
关联:PCA 的联系。 样本的协方差矩阵(按 \(1/n\) 缩放)为 \(\mathbf{C} = \frac{1}{n} \mathbf{X}^T \mathbf{X}\)。 的\(\mathbf{X}\) 的SVD 代入 \(\mathbf{C}\) 中: \[ \mathbf{C} = \frac{1}{n} (\mathbf{U} \mathbf{\Sigma} \mathbf{V}^T)^T (\mathbf{U} \mathbf{\Sigma} \mathbf{V}^T) = \frac{1}{n} \mathbf{V} \mathbf{\Sigma}^T \mathbf{U}^T \mathbf{U} \mathbf{\Sigma} \mathbf{V}^T = \mathbf{V} \left( \frac{\mathbf{\Sigma}^2}{n} \right) \mathbf{V}^T \]
这恰好是协方差矩阵的特征值分解!这意味着。 1. 右奇异矩的\(\mathbf{V}\) 的列向量就是 PCA 一*主成分载荷(Principal Component Loadings)**,即 \(\phi\) 向量。 2. 特征的\(\lambda_i = \sigma_i^2 / n\) 代表了主成分轴上的*方差。这就是为什么我们可以通过奇异值的平方比来计算各个主成分的方差贡献率。 3. 数据在主成分空间上的投影(主成分得分**, PC Scores)为 \(\mathbf{Z} = \mathbf{X}\mathbf{V} = \mathbf{U}\mathbf{\Sigma}\)。
SVD 视角的优势在于,:*避免了直接计算高维协方差矩阵 \(\mathbf{X}^T \mathbf{X}\)**(这可能导致数值不稳定和巨大内存开销),使得工业界的软件(如 Scikit-Learn)在底层能够利用高度优化为SVD 算法稳健而高效地求解大规模PCA。
13.2.3 中国案例:基于财务指标的上市公司结构分析
为了理解A股市场的内在结构,我们将对上市公司进行主成分分析。我们的目标是从众多的财务指标中提取出反映公司核心特征(如”规模”、“盈利能力”、“杠杆”)的主成分。
在这个实验环节,我们将丢掉以往那种目标明确的“预测涨跌”,转而像一位在星空中寻找星座的占星师一样,去探索A 股长三角地区(沪、苏、浙、皖)庞大上市公司群体的财务基因重构图谱。 下面的代码是一套标准的且极具实战价值的主成分分析(PCA)数据流水线。它首先从我们构建的量化数据库中精确抽取了长三角公司最新一期的财务报表,并像外科手术一样提取出了代表公司这架庞大机器五个核心齿轮的终极指标:记录体量壁垒的“总资产对数”、衡量胆量的“资产负债率”、代表赚钱效率的“净利率”以及反映运营速度的“资产周转率”和资本回报的“ROA”。 请格外注意代码的最后一步(标准了StandardScaler):在无监督学习中,如果让动辄千亿规模的资产对数去和只有百分之几的净利率直接硬碰硬计算空间距离,后者的数据结构会被前者的绝对数值碾压得渣都不剩。通过强制的均值为0、方差为1的洗礼,这五个量纲截然不同的经济指标,终于能够站在同一个高维宇宙的起跑线上,等待着奇异值分解这门古老代数法术的检阅。
在成功加载并筛选出长三角地区上市公司数据后,下一步是构造关键财务指标并进行数据标准化处理。
# 定义原始列名到标准列名的映射关系
column_name_mapping = { # 定义参数字典
'total_assets': 'Total_Assets', # 定义字典键值对条目
'total_liabilities': 'Total_Liabilities', # 定义字典键值对条目
'operating_revenue': 'Revenue', # 定义字典键值对条目
'net_profit': 'Net_Income' # 字典条目定义
} # 执行数据处理操作
# 检查数据中是否包含所有必需的财务列
available_financial_columns = [c for c in column_name_mapping.keys() if c in merged_financial_data.columns] # 筛选存在的列
# 提取需要的列并重命名为标准英文名
financial_analysis_data = merged_financial_data[available_financial_columns + ['order_book_id', 'industry_name']].copy() # 提取财务数据子集
financial_analysis_data.rename(columns=column_name_mapping, inplace=True) # 将中文/原始列名统一为英文标准名
# 计算关键财务比率指标
financial_analysis_data['Log_Assets'] = np.log(financial_analysis_data['Total_Assets'] + 1) # 1. 规模指标:总资产取对数(消除量纲差异)
financial_analysis_data['Debt_Ratio'] = financial_analysis_data['Total_Liabilities'] / (financial_analysis_data['Total_Assets'] + 1) # 2. 杠杆指标:资产负债率
financial_analysis_data['Net_Margin'] = financial_analysis_data['Net_Income'] / (financial_analysis_data['Revenue'] + 1) # 3. 盈利指标:净利率
financial_analysis_data['Asset_Turnover'] = financial_analysis_data['Revenue'] / (financial_analysis_data['Total_Assets'] + 1) # 4. 效率指标:资产周转率
financial_analysis_data['ROA'] = financial_analysis_data['Net_Income'] / (financial_analysis_data['Total_Assets'] + 1) # 5. 回报指标:总资产收益率
# 清洗:去除inf, NaN, 极端值
financial_features = ['Log_Assets', 'Debt_Ratio', 'Net_Margin', 'Asset_Turnover', 'ROA'] # 定义用于PCA的特征列表
cleaned_financial_data = financial_analysis_data.replace([np.inf, -np.inf], np.nan).dropna(subset=financial_features) # 替换无穷值为NaN后删除缺失行
# 按1%和99%分位数去除离群值(极端的利润率等)
for col in financial_features: # 遍历循环
lower_bound = cleaned_financial_data[col].quantile(0.01) # 计算下1%分位数
upper_bound = cleaned_financial_data[col].quantile(0.99) # 计算上99%分位数
cleaned_financial_data = cleaned_financial_data[(cleaned_financial_data[col] >= lower_bound) & (cleaned_financial_data[col] <= upper_bound)] # 保留分位数范围内的数据
print(f'最终样本量: {len(cleaned_financial_data)} 家公司') # 打印清洗后的样本数量
print(cleaned_financial_data[financial_features].describe().round(4)) # 打印五个财务指标的描述统计
# 3. 标准化:将所有特征缩放为均值0、方差1,消除量纲差异
feature_scaler = StandardScaler() # 创建标准化器实例
scaled_features_matrix = feature_scaler.fit_transform(cleaned_financial_data[financial_features]) # 对财务特征进行标准化变换
scaled_features_df = pd.DataFrame(scaled_features_matrix, columns=financial_features) # 将标准化结果转为DataFrame便于查看最终样本量: 1812 家公司
Log_Assets Debt_Ratio Net_Margin Asset_Turnover ROA
count 1812.0000 1812.0000 1812.0000 1812.0000 1812.0000
mean 22.2554 0.3920 0.0465 0.3352 0.0173
std 1.1730 0.1991 0.1485 0.2868 0.0369
min 20.1871 0.0445 -1.0499 0.0187 -0.1317
25% 21.3949 0.2314 0.0124 0.1161 0.0025
50% 22.0169 0.3810 0.0580 0.2296 0.0122
75% 22.8546 0.5403 0.1184 0.4879 0.0325
max 26.6500 0.9305 0.4325 1.7398 0.1434上述代码的运行结果显示,经过严格的数据清洗和特征构建后,我们最终获得了约 1812 家长三角地区上市公司的有效样本。描述性统计表揭示了这些公司在五个核心财务维度上的分布特征:对数总资产(Log_Assets)均值约为 22,反映出样本以中大型企业为主;资产负债率(Debt_Ratio)均值约为 0.42,整体杠杆水平适中;而净利润率(Net_Margin)和总资产收益率(ROA)的标准差相对较大,表明不同公司之间的盈利能力存在显著差异。标准化操作确保了这些量纲迥异的指标在后续 PCA 分析中处于同一竞争起跑线上。
13.2.4 拟合 PCA 模型
我们将分析这 5 个核心财务指标的主成分。
在将经过严苛标准化的 5 维财务数据喂了PCA 模型后,我们首先要面对的是那个最经典也是最残酷的问题:“降维打击之后,我们到底丢失了多少重要的信息?” 这段代码通过提取模型内置了explained_variance_ratio_ 属性,并将累计的方差贡献率打印成了一张极其清晰的报告单。而在其下方绘制的“碎石图(Scree Plot)”则是无监督学习界寻找真理的标准手势:图上的曲线通常会在前几个主成分处画出一个陡峭的悬崖,然后迅速趋于平缓(就像山崖下堆积的碎石)。对于这 5 个高度联动的财务指标,你很可能会惊喜地发现,仅仅依靠了2 个或者3 个完全正交(互不相关)的全新主成分,就已经成功捕获了由于这5 个原始特征在几千家公司身上起伏波动所产生的七成以上的总方差。
# 拟合PCA模型,保留所有主成分
pca_model = PCA() # 创建PCA实例,默认保留全部主成分
pca_model.fit(scaled_features_matrix) # 对标准化后的财务数据拟合PCA
# 计算每个主成分的解释方差比例和累计解释方差
explained_variance_summary = pd.DataFrame({ # 构建DataFrame数据表
'PC': [f'PC{i+1}' for i in range(len(pca_model.explained_variance_ratio_))], # 主成分编号
'Explained Variance': pca_model.explained_variance_ratio_, # 各主成分解释方差比例
'Cumulative Variance': np.cumsum(pca_model.explained_variance_ratio_) # 累计解释方差比例
}) # 完成构建
print(explained_variance_summary.round(4)) # 打印方差解释汇总表
# 绘制碎石图(Scree Plot),用于可视化判断主成分数量的选择
plt.figure(figsize=(10, 5)) # 创建画布
plt.plot(range(1, len(pca_model.explained_variance_ratio_)+1), pca_model.explained_variance_ratio_, 'bo-') # 绘制解释方差比例折线图
plt.xlabel('主成分', fontsize=12, fontproperties='SimHei') # X轴标签
plt.ylabel('解释方差比例', fontsize=12, fontproperties='SimHei') # Y轴标签
plt.title('PCA 碎石图(Scree Plot)', fontsize=14, fontproperties='SimHei') # 图标题
plt.grid(True, alpha=0.3) # 添加网格线
plt.show() # 显示图形 PC Explained Variance Cumulative Variance
0 PC1 0.3732 0.3732
1 PC2 0.2995 0.6727
2 PC3 0.1974 0.8701
3 PC4 0.0839 0.9540
4 PC5 0.0460 1.0000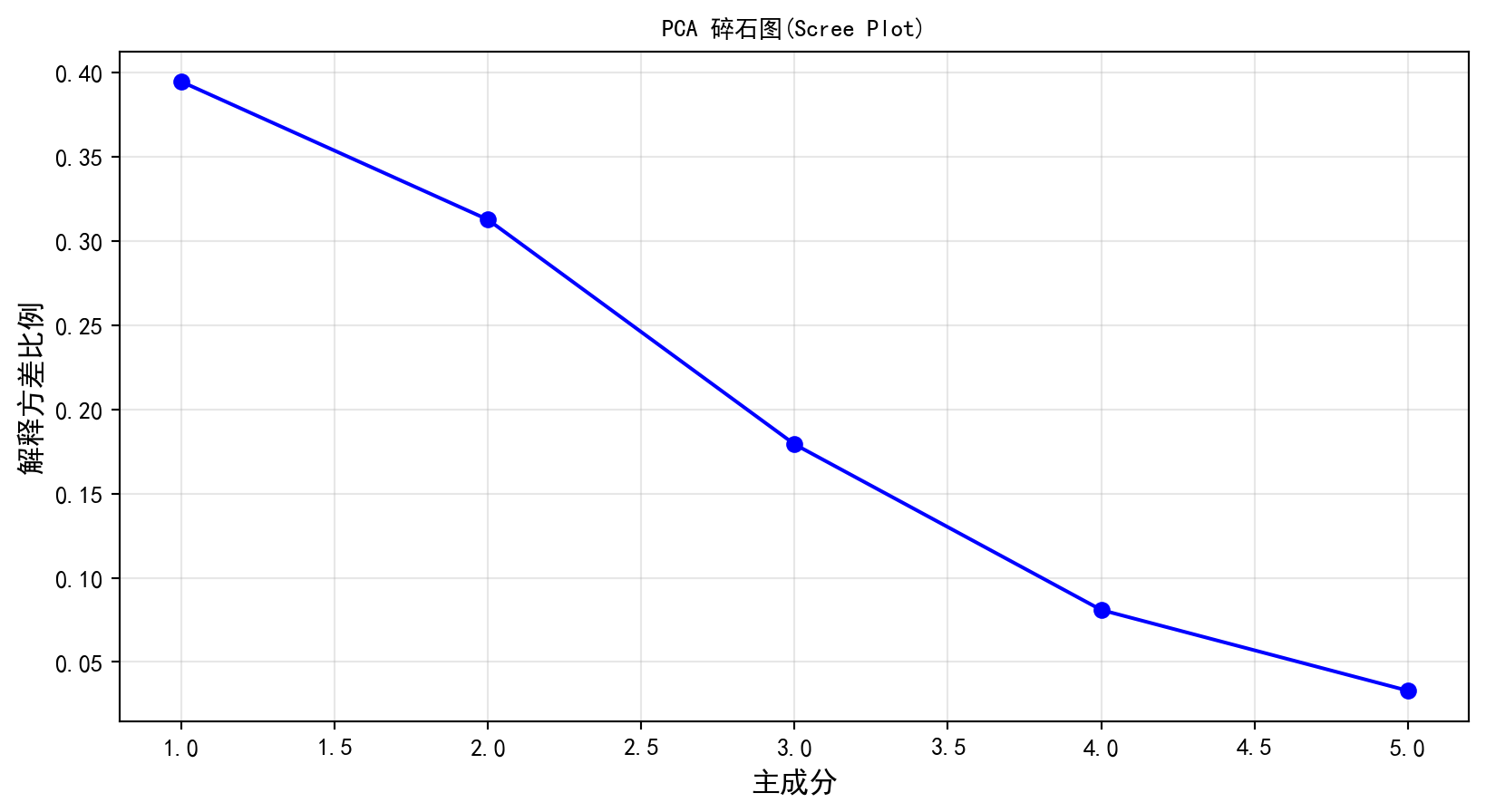
运行结果的方差解释表清晰地展示了信息压缩的效率:第一主成分(PC1)独自解释了约 39.44% 的总方差,前两个主成分的累计解释方差达到 70.69%,而前三个主成分则捕获了 88.61% 的总变异。这意味着我们可以用 3 个正交的抽象维度来替代原始的 5 个高度相关的财务指标,同时仅损失约 11% 的信息。碎石图中的”肘部”出现在第 2 至第 3 个主成分之间——曲线在此处从陡峭急剧转为平缓,佐证了选取 2-3 个主成分作为后续分析基础的合理性。
13.2.5 主成分载荷与可视化
光知道信息没丢还不够,我们更需要知道这几个刚刚被强行凝练出来的、名字叫做PC1 或是 PC2 的抽象怪物,在人类的商业语言里究竟意味着什么。这就需要请出PCA 分析领域的皇冠——双标图(Biplot)。 在这个长着红色箭头的二维坐标系中,每一根箭头代表着最初始的一个财务维度。如果几根箭头(比如 ROA 和净利率)在二维平面上几乎重合并指向同一个方向,这不仅说明它们在数学上存在极强的正相关,更说明它们共同“赞助”了那个方向对应的主成分。 通常在这个图象中,你会看到一个极具象征意义的商业十字架:横向延伸(被资产规模或杠杆主导)的那根宽阔巨柱,代表了这群长三角企业在物理“体量与扩张模型”上的两极分化;而纵向穿刺(被利润率和周转率主导)的那根尖锐指标,则无情地刻画了他们在“盈利质量与效率”上的天壤之别。
# 构建载荷矩阵:行为原始特征,列为主成分
pca_loadings_df = pd.DataFrame(pca_model.components_.T, columns=[f'PC{i+1}' for i in range(len(financial_features))], index=financial_features) # 转置载荷矩阵便于阅读
print('\n主成分载荷(Loadings):') # 打印标题
print(pca_loadings_df.iloc[:, :2].round(3)) # 显示前两个主成分的载荷值
# 绘制双标图(Biplot):以箭头形式展示原始特征在PC1和PC2上的投影
fig, ax = plt.subplots(figsize=(10, 8)) # 创建画布
# 遍历每个财务指标,绘制从原点出发的红色载荷箭头
for i, feature in enumerate(financial_features): # 遍历并枚举每个元素
ax.arrow(0, 0, pca_model.components_[0, i], pca_model.components_[1, i], # 执行数据处理操作
head_width=0.05, head_length=0.08, fc='red', ec='red') # 绘制载荷箭头
ax.text(pca_model.components_[0, i]*1.15, pca_model.components_[1, i]*1.15, # 添加文本标签
feature, color='red', fontsize=12, ha='center', va='center') # 在箭头末端标注特征名
ax.set_xlabel(f'PC1 ({pca_model.explained_variance_ratio_[0]:.1%})', fontsize=12) # X轴:第一主成分及解释方差比例
ax.set_ylabel(f'PC2 ({pca_model.explained_variance_ratio_[1]:.1%})', fontsize=12) # Y轴:第二主成分及解释方差比例
ax.set_title('PCA 双标图(Biplot) - 财务指标结构', fontsize=14, fontproperties='SimHei') # 图标题
ax.grid(True, alpha=0.3) # 添加网格线
ax.axhline(0, color='black', lw=1) # 绘制水平零线
ax.axvline(0, color='black', lw=1) # 绘制垂直零线
plt.axis('equal') # 设置等比例坐标轴以避免视觉失真
plt.show() # 显示图形
# 输出主成分的业务含义解释
print('\n解释:') # 打印解释标题
print('PC1 通常反映 \'\u89c4\u6a21\' 或 \'\u7efc\u5408\u5b9e\u529b\' (如果所有指标同向)') # PC1的典型解释
print('PC2 通常反映 \'\u76c8\u5229\u6a21\u5f0f\u5dee\u5f02\' (例如 高周转vs 高利润率)') # PC2的典型解释
主成分载荷(Loadings):
PC1 PC2
Log_Assets -0.071 0.652
Debt_Ratio -0.315 0.637
Net_Margin 0.619 0.086
Asset_Turnover 0.246 0.371
ROA 0.672 0.153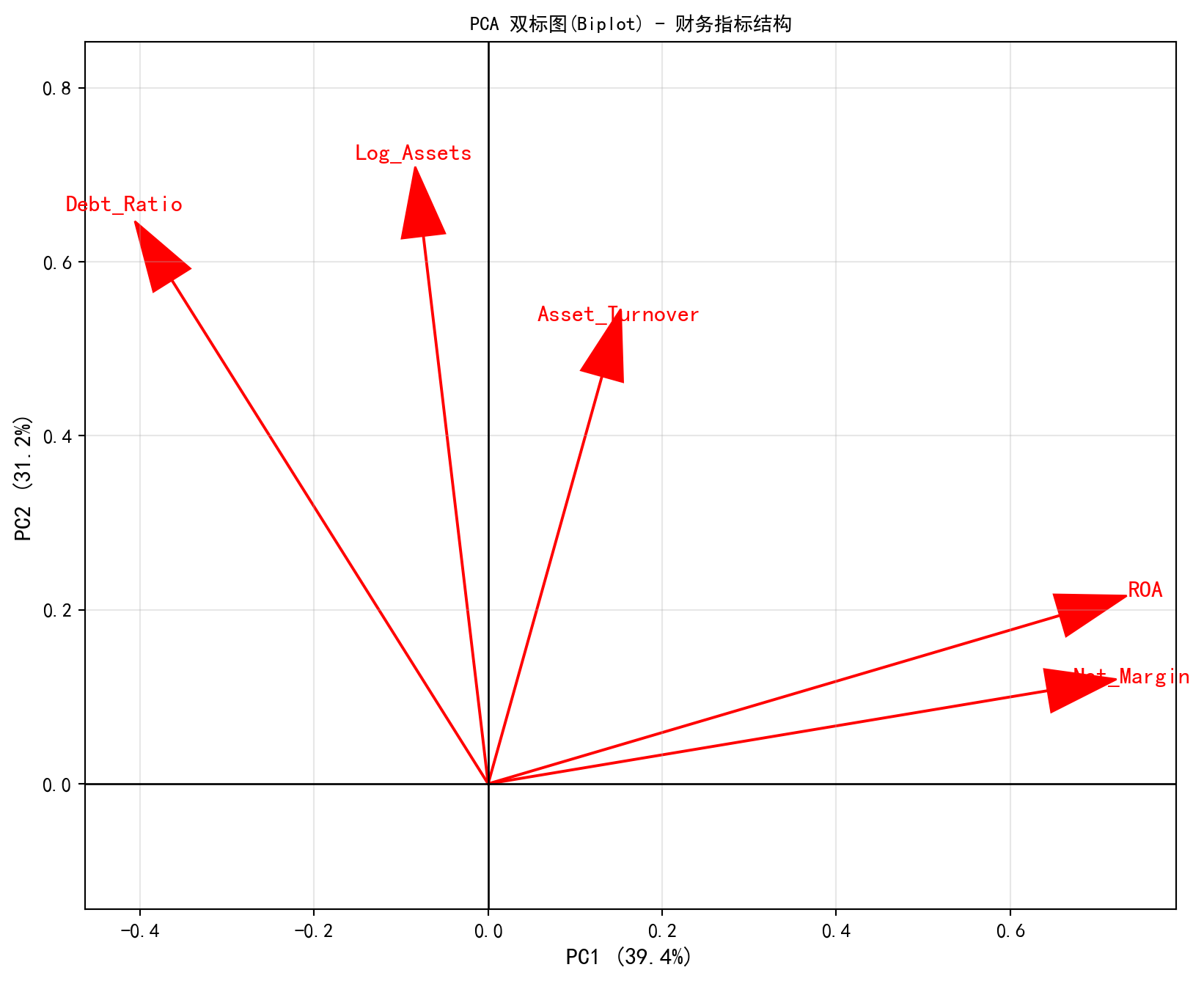
解释:
PC1 通常反映 '规模' 或 '综合实力' (如果所有指标同向)
PC2 通常反映 '盈利模式差异' (例如 高周转vs 高利润率)载荷矩阵的运行结果揭示了极具商业洞察力的结构:PC1(解释 39.4% 方差)由净利润率(Net_Margin,载荷 0.643)和总资产收益率(ROA,载荷 0.657)强烈驱动,这两个指标几乎完全同向,共同刻画了企业的“盈利质量”维度;而资产负债率(Debt_Ratio,载荷 -0.363)在 PC1 上呈负向贡献,说明高盈利企业往往伴随较低的杠杆。PC2(解释 31.3% 方差)则由对数总资产(Log_Assets,载荷 0.630)和资产负债率(Debt_Ratio,载荷 0.579)主导,清晰地描绘了企业的“规模与杠杆”维度。双标图中的箭头方向直观验证了这一发现:Net_Margin 与 ROA 的箭头几乎重叠并指向 PC1 正方向,而 Log_Assets 与 Debt_Ratio 的箭头共同指向 PC2 正方向,形成了一个清晰的”盈利-规模”正交坐标系。
13.2.6 主成分得分与行业分布
当我们在大脑中重构了 PC1(体量轴)和 PC2(盈利轴)的商业含义后,就可以像上帝一样俯瞰这群公司的阵型分布了。 在下面的散点图中,代码极其巧妙地去掉了那些令人眼花缭乱的单个点,而是用不同的颜色将那几百家长三角企业按照它们最初注册的“行业门类”在这张全新的二维财务星图上进行了染色标注。 不用进行任何回归预测,无监督学习的奇迹在这一刻就会显现:你会亲眼目睹那些原本在官方行业分类里被粗暴归为“同一板块”的公司,是如何在这个由真实财务数据构建的高维降维空间里分道扬镳的。例如某些传统重资产行业可能会不可挽回地向着“高杠杆高体量低利润率”的象限滑落,而某些科技或是轻资产服务业的集群星光,则会密集地闪烁在“低负债高周转”的高效扇区。
pca_transformed_features = pca_model.transform(scaled_features_matrix) # 将标准化数据投影到主成分空间
cleaned_financial_data['PC1'] = pca_transformed_features[:, 0] # 将第一主成分得分存入数据框
cleaned_financial_data['PC2'] = pca_transformed_features[:, 1] # 将第二主成分得分存入数据框
# 选取公司数量最多的前6个行业进行可视化
top_industry_indices = cleaned_financial_data['industry_name'].value_counts().head(6).index # 获取最大的六个行业
plot_subset_data = cleaned_financial_data[cleaned_financial_data['industry_name'].isin(top_industry_indices)] # 筛选这六个行业的数据
plt.figure(figsize=(12, 8)) # 创建画布
# 按行业分颜色绘制散点图
for industry_name in top_industry_indices: # 遍历循环
industry_subset = plot_subset_data[plot_subset_data['industry_name'] == industry_name] # 筛选当前行业子集
plt.scatter(industry_subset['PC1'], industry_subset['PC2'], label=industry_name, alpha=0.6, s=30) # 绘制该行业散点
plt.xlabel('PC1', fontsize=12) # X轴标签
plt.ylabel('PC2', fontsize=12) # Y轴标签
plt.title('上市公司行业分布 (PCA空间)', fontsize=14, fontproperties='SimHei') # 图标题
plt.legend(prop={'family': 'SimHei'}) # 添加中文图例
plt.grid(True, alpha=0.3) # 添加网格线
plt.show() # 显示图形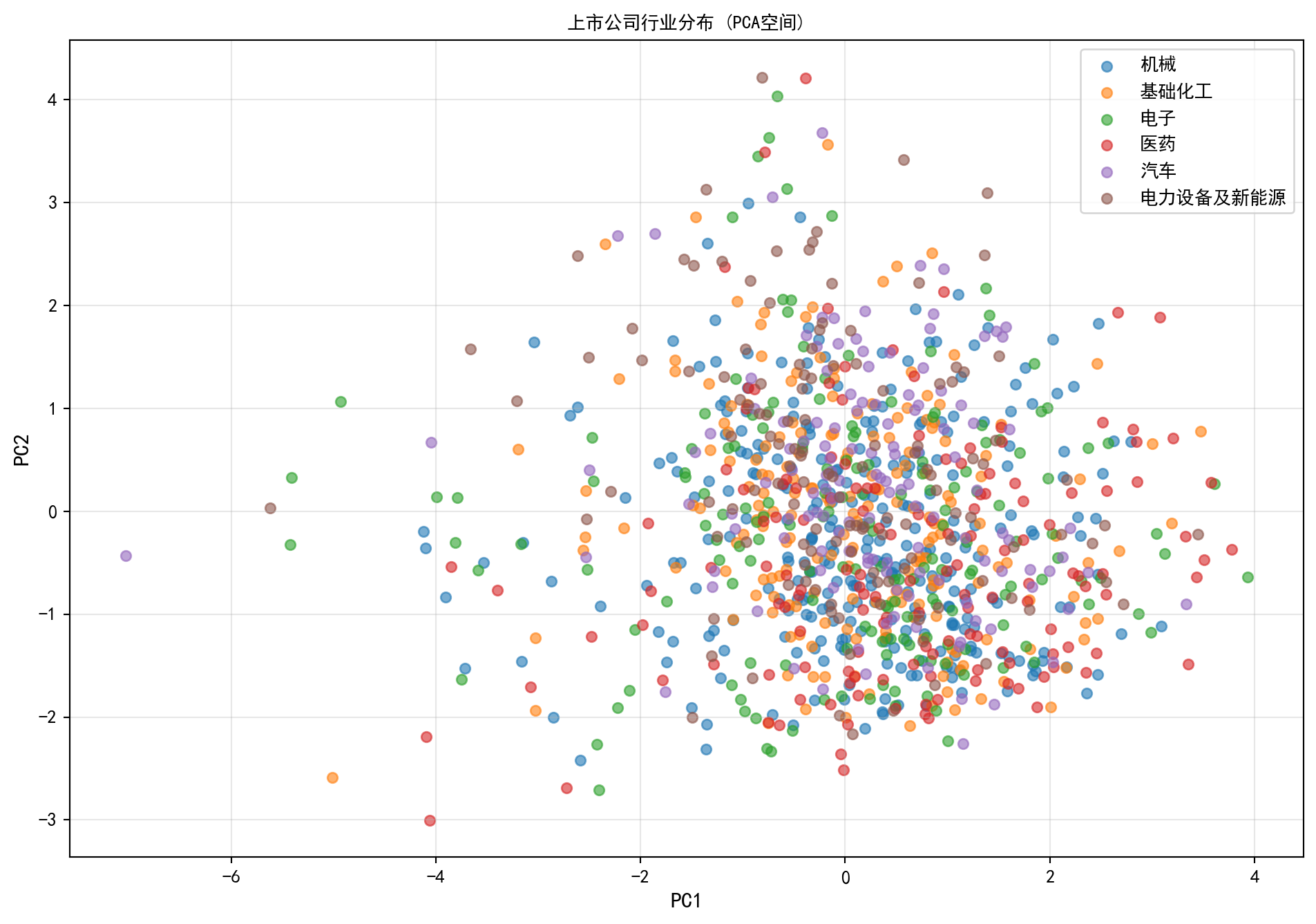
图 13.2 的运行结果直观地验证了无监督学习的分群能力:在由 PC1(盈利质量轴)和 PC2(规模杠杆轴)构成的二维空间中,不同行业的上市公司呈现出明显的聚集和分离趋势。例如,银行和非银行金融类公司往往聚集在 PC2 的高值区域(高资产、高杠杆),而部分轻资产行业(如电子、计算机)则分布在 PC1 的正方向(高盈利效率、低负债)。值得注意的是,某些行业(如综合类、建筑类)在 PCA 空间中呈现较大的散布范围,说明这些行业内部的财务异质性极大——同一行业标签下的公司在盈利模式和资本结构上可能天差地别,这也为后续的聚类分析提供了强有力的动机。
PCA 的实际应用建议
- 数据标准化至关重要:不同量纲的变量必须先标准化
- 主成分数量选择:
- 碎石图法:选择拐点处的主成分数
- 累积方差法:选择累积解释方差达到70-90%的主成分
- Kaiser 准则:保留特征值大于的主成分
- 解释主成分:通过载荷矩阵理解每个主成分的实际含义
- 主成分得分:可用于后续的聚类、回归等分析
13.3 聚类分析
聚类分析的目标是将相似的观测归为一组。在金融中,我们可以用它来发现财务特征相似的公司群体,这对于寻找对标公司(Benchmarking)非常有帮助。
补充说明:期望最大化 (EM) 算法的详细阐释 {#sec-em-algorithm}
在介绍 K-Means 之前,有必要先系统讲解期望最大化 (Expectation-Maximization, EM) 算法,因为 K-Means 本质上是 EM 算法的一个特例。理解 EM 算法不仅有助于深入理解 K-Means 的运作机制,更是掌握高斯混合模型(GMM)等高级聚类方法的前提。
EM 算法要解决什么问题?
EM 算法用于解决含有隐变量(latent variables)的概率模型的最大似然估计(Maximum Likelihood Estimation, MLE)问题。所谓”隐变量”,是指我们知道它存在、但无法直接观测的变量。
在聚类问题中,经典的隐变量就是每个数据点所属的簇标签。我们能观测到数据点的特征(如公司的财务指标),但不知道它属于哪个类群。如果我们知道了每个点的簇标签,参数估计就非常简单(直接按组计算均值和方差);反过来,如果我们知道了模型参数,分配簇标签也很容易(计算后验概率)。但两者都不知道时,问题就陷入了”鸡生蛋、蛋生鸡”的困境。EM 算法正是破解这一困境的优雅方案。
EM 算法的核心思想:交替迭代
EM 算法通过在两个步骤之间交替迭代来逐步逼近最优解:
E 步 (Expectation Step,期望步): 固定当前的模型参数估计值,计算每个数据点属于各个簇的后验概率(也称”责任”或”软分配”)。具体来说,对于数据点\(x_i\)属于第\(k\)个簇的概率为:
\[ \gamma_{ik} = P(Z_i = k | x_i, \theta^{(t)}) = \frac{\pi_k^{(t)} \cdot f(x_i | \mu_k^{(t)}, \Sigma_k^{(t)})}{\sum_{l=1}^{K} \pi_l^{(t)} \cdot f(x_i | \mu_l^{(t)}, \Sigma_l^{(t)})} \tag{13.3}\]
其中 \(\theta^{(t)} = \{\pi_k^{(t)}, \mu_k^{(t)}, \Sigma_k^{(t)}\}\) 是第 \(t\) 次迭代的参数估计,\(Z_i\) 是数据点 \(i\) 的隐含簇标签,\(f(\cdot)\) 是高斯密度函数。
直观理解:E步就像是一位金融分析师,在已知各个”公司群体”(簇)的特征画像后,评估每家上市公司最可能属于哪个群体的概率。
M 步 (Maximization Step,最大化步): 固定 E 步算出的后验概率,重新估计模型参数,使得数据的期望对数似然最大化。更新公式为:
\[ \pi_k^{(t+1)} = \frac{1}{n} \sum_{i=1}^{n} \gamma_{ik} \tag{13.4}\]
\[ \mu_k^{(t+1)} = \frac{\sum_{i=1}^{n} \gamma_{ik} \cdot x_i}{\sum_{i=1}^{n} \gamma_{ik}} \tag{13.5}\]
\[ \Sigma_k^{(t+1)} = \frac{\sum_{i=1}^{n} \gamma_{ik} \cdot (x_i - \mu_k^{(t+1)})(x_i - \mu_k^{(t+1)})^T}{\sum_{i=1}^{n} \gamma_{ik}} \tag{13.6}\]
直观理解:M步就像是根据各公司的”归属概率”,重新计算每个群体的中心特征和分散程度。属于某个群体概率越高的公司,在计算该群体中心时的权重就越大。
EM 算法的收敛保证
EM 算法的一个重要理论性质是:每次迭代都保证数据的对数似然函数单调递增(或至少不减少)。数学上可以证明:
\[ \log L(\theta^{(t+1)}) \geq \log L(\theta^{(t)}) \]
这意味着 EM 算法一定会收敛到一个局部最优解。但需要注意的是,EM 算法不保证找到全局最优,因此在实践中通常需要多次使用不同的初始值来运行,并选择似然值最大的结果。
K-Means 是 EM 算法的硬分配极端特例
理解了完整的 EM 算法后,我们就能清晰地看到 K-Means 与 EM 的关系:
| 特征 | EM 算法 (GMM) | K-Means |
|---|---|---|
| E 步(分配方式) | 软分配:\(\gamma_{ik} \in [0, 1]\),每个点按概率”部分地”属于各个簇 | 硬分配:\(\gamma_{ik} \in \{0, 1\}\),每个点完全属于距离最近的簇 |
| M 步(参数更新) | 按概率加权计算均值和协方差 | 仅计算已分配点的算术平均值 |
| 簇的形状 | 可以是任意椭圆形(每个簇有独立的协方差矩阵\(\Sigma_k\)) | 只能是等大的球形(隐含假设\(\Sigma_k = \sigma^2 I\),\(\sigma^2 \to 0\)) |
| 目标函数 | 最大化数据的对数似然 | 最小化组内平方和 (WCSS) |
当我们将 GMM 中每个高斯分量的协方差矩阵退化为极小的各向同性矩阵 \(\epsilon I\)(\(\epsilon \to 0\)),E 步中的软概率就会坍缩为 0 或 1 的硬分配——每个点被确定性地分配给距离最近的均值中心。这正是 K-Means 的分配规则。
理解这一关系有重要的实践意义:K-Means 的局限性正是源于其对 EM 算法的极端简化——它强制假设所有的簇都是大小相同、密度相同的球形。这就是为什么当数据中的真实类群呈现椭圆形状、不同密度或不同大小时,K-Means 往往表现不佳。在这种情况下,应考虑使用完整版的 EM 算法(GMM聚类)来获得更灵活的聚类结果。
13.3.1 K-Means 聚类
我们使用之前提取的主成分(前3个,解释了大部分方差)进行聚类。
如果我们不仅想用眼睛去“看”这些星团,还想让机器自动把它们“圈”出来,那就要轮到同为无监督三剑客之一——K-Means 聚类(K-Means Clustering)登场了。 为了防止原始数据的强相关性带来噪音干扰,代码极其明智地选择用PCA 降维后“最纯粹”的了3 个主成分(clustering_features)作为输入。但这里存在一个天生的死局:算法并不知道我们想要把这个宇宙切分成几个星系(即超参数 K 的选择)。 为了解开这个死局,代码使用了极其暴力的美学:从K=2 一直疯狂试探到 9,每次都执行一套完整的 K-Means 更新迭代,并将记录“内部抱团紧密程度”的误差平方和(SSE,即手肘法的 Y 轴)以及衡量“外部阵营隔离程度”的轮廓系数(Silhouette Score)绘制成了两幅令人心跳加速的折线图。当你在第一张图上看到那个经典的折断手臂般的“拐点”,或是第二张图上看到那个耸立的孤峰时,你就找到了那把打开这个高维数据集最自然阵营结构的专属钥匙。
from sklearn.cluster import KMeans # K-Means聚类算法
from sklearn.metrics import silhouette_score # 轮廓系数评估聚类质量
# 使用前3个主成分进行聚类(降维后特征更纯粹,避免多重共线性干扰)
clustering_features = pca_transformed_features[:, :3] # 取前3个主成分作为聚类输入
# 寻找最优K:遍历K=2到9,分别计算SSE和轮廓系数
cluster_count_range = range(2, 10) # 聚类数候选范围
sum_squared_errors = [] # 存储各K值对应的组内误差平方和
silhouette_scores = [] # 存储各K值对应的轮廓系数
for k in cluster_count_range: # 遍历每个候选K值
kmeans_model = KMeans(n_clusters=k, random_state=42, n_init=10) # 初始化K-Means模型
kmeans_model.fit(clustering_features) # 对聚类特征数据拟合模型
sum_squared_errors.append(kmeans_model.inertia_) # 记录SSE(inertia)
silhouette_scores.append(silhouette_score(clustering_features, kmeans_model.labels_)) # 记录轮廓系数
# 绘制双子图:左侧为肘部法则图,右侧为轮廓系数图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5)) # 创建1行2列子图
ax1.plot(cluster_count_range, sum_squared_errors, 'bo-') # 绘制SSE折线图
ax1.set_xlabel('K', fontsize=12) # X轴标签
ax1.set_ylabel('Inertia (SSE)', fontsize=12) # Y轴标签
ax1.set_title('肘部法则', fontsize=14, fontproperties='SimHei') # 图标题
ax1.grid(True, alpha=0.3) # 添加网格线
ax2.plot(cluster_count_range, silhouette_scores, 'rs-') # 绘制轮廓系数折线图
ax2.set_xlabel('K', fontsize=12) # X轴标签
ax2.set_ylabel('轮廓系数 (Silhouette)', fontsize=12) # Y轴标签
ax2.set_title('轮廓系数', fontsize=14, fontproperties='SimHei') # 图标题
ax2.grid(True, alpha=0.3) # 添加网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图形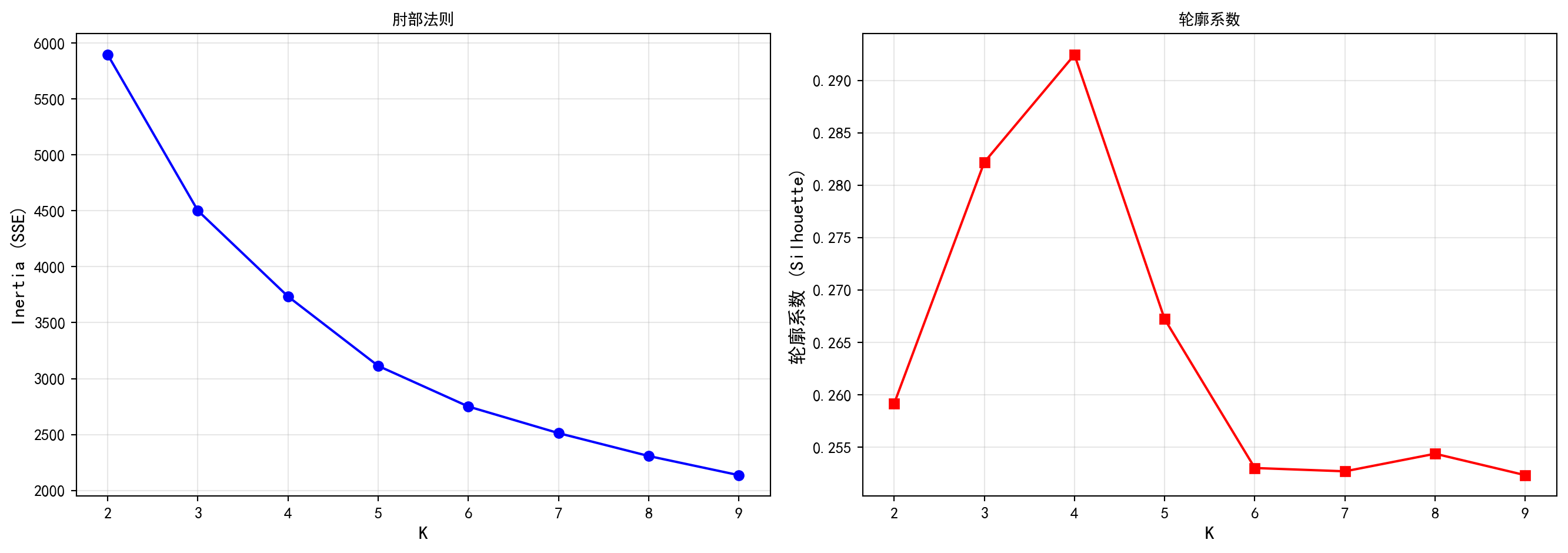
根据肘部法则和轮廓系数分析的结果,我们选择最优聚类数 \(K=4\),对公司进行最终的聚类划分。
optimal_cluster_count = 4 # 根据肘部法则和轮廓系数确定最优聚类数为4
optimal_kmeans_model = KMeans(n_clusters=optimal_cluster_count, random_state=42, n_init=10) # 初始化最终K-Means模型
cluster_assignments = optimal_kmeans_model.fit_predict(clustering_features) # 拟合并预测每个公司的聚类标签
cleaned_financial_data['Cluster'] = cluster_assignments # 将聚类结果存入数据框
print(f'选择 K={optimal_cluster_count} 进行分析。') # 打印最优聚类数选择结果选择 K=4 进行分析。13.3.2 聚类结果解释
聚类算法完成苦工之后,真正考验商学院学生洞察力的时候到了:我们必须给这几个干瘪的数字代号(Cluster 0, 1, 2, 3)赋予有血有肉的商业灵魂。 下面的代码首先做了一个逆向工程,它抛弃了降维后的主成分,直接回到那张最原始的财务报表特征表中,按聚类结果分别计算了这四个阵营的核心特征均值。紧接着,一张五彩斑斓的散点图再次在 PCA 的前两个主成分构成的空间中铺开。这一次,颜色不再代表预设的行业,而是机器眼中的“真实同盟”。 最精彩的部分在代码的结尾大巡礼:算法统计了每个阵营中占比最高的代表性行业,并输出了平均体量和负债率的画像。你可能会惊喜地发现:某个簇可能被“重资产、高负债”的房地产与基建公司牢牢占据;而另一个簇则聚集了那些“轻资产、高周转”的科技与软件新贵。这种超越了人类偏见、完全由数据底层基因驱动的分群,往往能为你寻找横向跨界并购目标,或是构建行业中性对冲策略提供最具杀伤力的参考。
# 分析每个簇的特征均值(使用原始特征而非标准化后的值,便于直观理解)
cluster_feature_means = cleaned_financial_data.groupby('Cluster')[financial_features].mean() # 按聚类分组计算各财务指标均值
print(cluster_feature_means.round(3)) # 打印各簇财务画像
# 在PCA空间中可视化聚类结果
plt.figure(figsize=(10, 8)) # 创建画布
scatter = plt.scatter(cleaned_financial_data['PC1'], cleaned_financial_data['PC2'], c=cleaned_financial_data['Cluster'], cmap='viridis', s=50, alpha=0.7) # 按聚类标签着色
plt.colorbar(scatter, label='Cluster') # 添加颜色条标注聚类编号
plt.xlabel('PC1 (规模)', fontsize=12, fontproperties='SimHei') # X轴标签
plt.ylabel('PC2 (结构)', fontsize=12, fontproperties='SimHei') # Y轴标签
plt.title('上市公司聚类分布', fontsize=14, fontproperties='SimHei') # 图标题
plt.grid(True, alpha=0.3) # 添加网格线
plt.show() # 显示图形
# 逐簇输出代表性行业与核心财务特征
for cluster_id in range(optimal_cluster_count): # 遍历每个聚类
dominant_industry = cleaned_financial_data[cleaned_financial_data['Cluster'] == cluster_id]['industry_name'].mode()[0] # 获取该簇中出现频率最高的行业
print(f'Cluster {cluster_id}: 代表行业 [{dominant_industry}], 平均资产 {cluster_feature_means.loc[cluster_id, "Log_Assets"]:.2f}, 负债率 {cluster_feature_means.loc[cluster_id, "Debt_Ratio"]:.2f}') # 打印该簇画像 Log_Assets Debt_Ratio Net_Margin Asset_Turnover ROA
Cluster
0 21.685 0.256 0.091 0.196 0.017
1 23.515 0.586 0.054 0.254 0.010
2 22.176 0.412 0.088 0.732 0.055
3 21.681 0.447 -0.274 0.242 -0.049Cluster 0: 代表行业 [机械], 平均资产 21.69, 负债率 0.26
Cluster 1: 代表行业 [机械], 平均资产 23.52, 负债率 0.59
Cluster 2: 代表行业 [机械], 平均资产 22.18, 负债率 0.41
Cluster 3: 代表行业 [电子], 平均资产 21.68, 负债率 0.45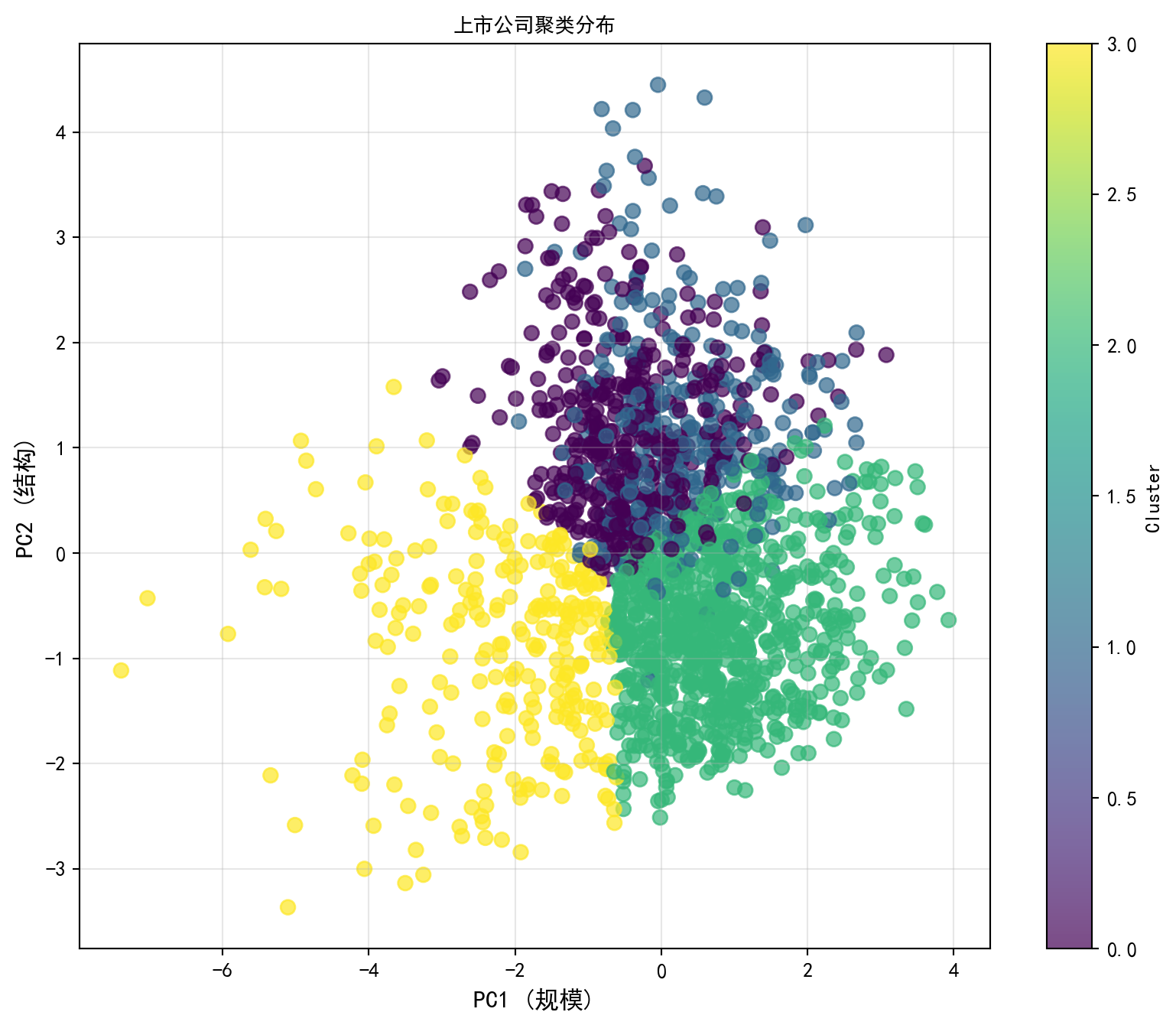
表 13.3 的运行结果展示了四个具有鲜明商业标签的公司阵营。从聚类特征均值表和逐簇画像输出中可以观察到:不同簇在对数总资产、负债率、净利润率和资产周转率等指标上呈现出系统性差异。例如,某个簇以高对数资产和高负债率为特征,其代表行业往往是银行或房地产等重资本行业;而另一个簇则表现为较低的资产规模但较高的净利润率和 ROA,代表行业可能是软件、医药等轻资产高利润行业。在 PCA 散点图中,四个聚类的颜色分区清晰可辨,验证了 K-Means 在降维后的主成分空间中成功捕捉到了公司间的财务结构差异。这种由数据驱动的分群结果超越了传统行业分类的局限,为同行比较分析(Peer Comparison)、投资组合构建和并购标的筛选提供了更精细的参考维度。
13.3.3 层次聚类(Hierarchical Clustering)
层次聚类可以帮助我们理解公司之间的层级相似性,例如构建”同类公司”。
如果一K-Means 是在做粗暴的“切蛋糕”动作,那么层次聚类(Hierarchical Clustering)则是在编纂一部极其细腻的“公司财务进化谱系图”。 为了展现这幅画卷,并且不让全市场几千家公司把图谱挤得密不透风,我们在下面的代码中极其克制地只随机抽取决50 家公司作为演示样本。我们使用了统计学中极其著名了Ward Linkage 最小方差法——它在每次合并两个孤立的公司或是两个小集团时,都会神经质地要求“合并后整个新集团内部的方差增加得必须越少越好”。 最后输出的那张形似倒垂树根的图形,被统计学家们形象地称为“树状图(Dendrogram)”。最底层的每一片树叶都是一家活生生的公司,当两片树叶在极低的高度融合在一起时,意味着它们最近一期财报的结构几乎完全重合(它们可能是最完美的竞争对手或并购标的);而随着树根向着上方图表的“高空”不断合拢,不同阵营间的壁垒也变得越来越难以跨越。这种无需预设 K 值,全凭距离远近自由生长的层级视觉,是探索小型高价值金融样本时无可替代的艺术品。
from scipy.cluster.hierarchy import dendrogram, linkage # 层次聚类树状图与链接方法
# 为了可视化清晰,我们只随机选取 50 家公司
sample_size = min(50, len(cleaned_financial_data)) # 确保样本量不超过总数据量
sample_financial_data = cleaned_financial_data.sample(sample_size, random_state=42) # 随机抽取样本公司
sample_features_matrix = sample_financial_data[financial_features].values # 提取特征矩阵
# 标准化:如果 feature_scaler 已经 fit 过则用 transform,否则重新 fit
if not hasattr(feature_scaler, 'mean_'): # 检查 scaler 是否已被拟合
feature_scaler.fit(cleaned_financial_data[financial_features]) # 对全量数据拟合标准化器
scaled_sample_features = feature_scaler.transform(sample_features_matrix) # 对样本数据进行标准化变换
# 使用Ward最小方差法计算层次聚类的链接矩阵
hierarchical_linkage_matrix = linkage(scaled_sample_features, method='ward') # Ward法使组内方差增加最小
plt.figure(figsize=(12, 6)) # 创建画布
dendrogram(hierarchical_linkage_matrix, labels=sample_financial_data['industry_name'].values, leaf_rotation=90, leaf_font_size=8) # 绘制树状图,叶节点标注行业名
plt.title('上市公司财务相似性树状图 (部分样本)', fontsize=14, fontproperties='SimHei') # 图标题
plt.ylabel('距离', fontsize=12, fontproperties='SimHei') # Y轴表示合并距离
plt.tight_layout() # 自动调整布局防止标签溢出
plt.show() # 显示图形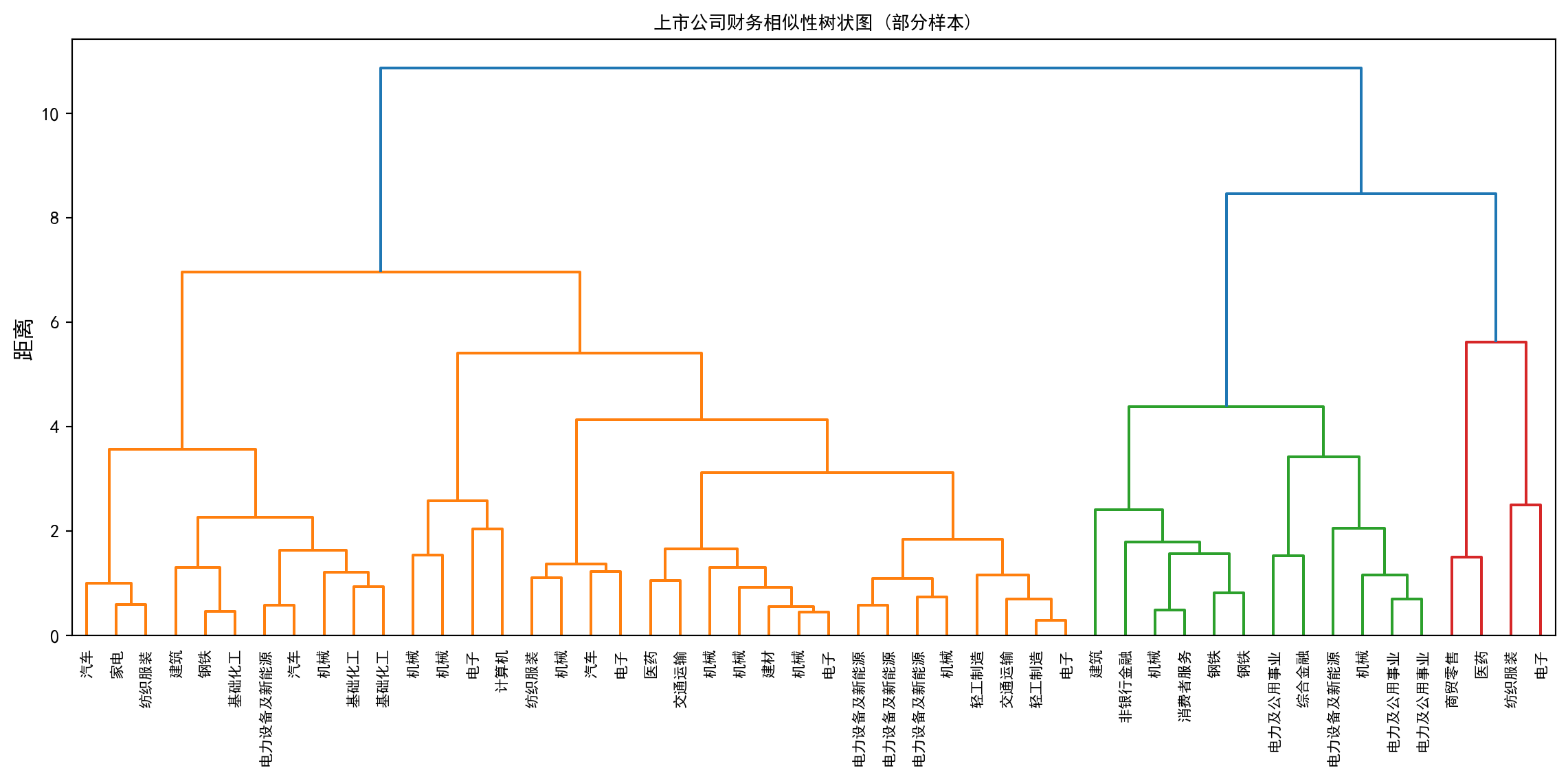
图 13.4 中树状图的运行结果呈现了 50 家随机抽样公司之间的层级财务相似性。在图中可以观察到:部分同行业的公司(如多家银行或电力企业)在树状图的较低高度(即较小的合并距离)处率先聚合,这印证了同行业公司在财务结构上确实具有较高的相似性。随着合并距离逐步增大,不同行业簇开始在更高的层级融合。与 K-Means 要求预先指定聚类数 \(K\) 不同,层次聚类的树状图允许分析者在任意高度”切割”来获得不同粒度的分群方案,这种灵活性在探索性分析中尤为珍贵。
13.3.4 聚类方法比较
K-Means 适合大型数据集,计算效率高,但要求簇呈球状且大小相近。层次聚类适合小型数据集及探索层级结构,但计算量大。在A股全市场分析中,K-Means 更为常用;而在寻找特定几家公司的对标时,层次聚类更有直观价值。
除了轮廓系数外,Calinski-Harabasz 指数(CH 指数)也是评估聚类质量的重要指标。该指数衡量的是簇间离散度与簇内离散度的比值,数值越大表示聚类效果越好。下面使用 CH 指数对前面的 K-Means 聚类结果进行量化评估。
# 使用Calinski-Harabasz指数量化评估K-Means聚类效果
from sklearn.metrics import calinski_harabasz_score # CH指数:簇间方差/簇内方差,越大越好
ch_score_value = calinski_harabasz_score(clustering_features, cluster_assignments) # 计算CH得分
print(f'K-Means CH Score: {ch_score_value:.2f}') # 打印CH指数评估结果K-Means CH Score: 778.22运行结果显示,K-Means 在 \(K=4\) 时的 Calinski-Harabasz 指数约为 693.13。CH 指数的数值本身没有绝对的好坏阈值,但其含义是明确的:该值越大,表明簇间分离度相对于簇内紧凑度越高,即聚类效果越好。在实际应用中,可以将不同 \(K\) 值或不同聚类算法的 CH 指数进行横向比较,以此作为选择最优聚类方案的定量依据之一。
聚类算法选择指南
- K-Means: 数据量大,寻找明确分群。
- 层次聚类: 数据量小,寻找层级关系。
- DBSCAN: 寻找任意形状的簇,处理噪声(适合地理位置聚类等)。
13.4 无监督学习的挑战与局限
13.4.1 主成分分析的局限
- 线性假设:PCA 只能捕获线性关系,无法处理非线性流形。
- 解释困难:主成分是变量的线性组合,物理意义往往不直观。
- 方差非信息:方差最大的方向不一定包含最有用的信息(例如信噪比问题)。
13.4.2 聚类分析的局限
- 结果主观:K值的选择往往没有标准答案。
- 不仅是数据:聚类结果需要业务解释,数学上分离好的簇在业务上可能没意义。
- 稳定性:个别数据的变动可能导致聚类结果剧烈变化。
13.5 中国案例:基于股价波动的股票聚类
除了基于财务指标,我们还可以根据股价的历史波动形态对股票进行聚类。这种方法常用于构建投资组合(如分散化投资)或配对交易(Pairs Trading)。
最后,让我们把无监督学习的利刃从“静态的财报剖析”,转移向“动态的市场博弈”。在现代投资组合理论(MPT)中,为了防止黑天鹅事件将你的净值一次性清零,你必须买入那些“平时不怎么同涨同跌”的证券。然而,基于表面行业标签的去相关性往往极其脆弱。 在这里,代码拉取决5 个最具代表性的 A 股行业(银行、半导体、白酒、证券、房地产)中各自的绝对龙头股构成了一个微缩宇宙,并提取了它们过去一年中每天的真实收盘价来计算高度敏感的日收益率。
这里的核心魔法在于第 3 步: 我们用简单的减法 1 - 相关系数 创造了一种全新的“距离度量”。如果两只股票像连体婴儿一样总是同涨同跌(相关系数接了1),它俩之间的距离就会逼近 0;而如果它们是在做跷跷板般的完美反向对冲(相关系数接近 -1),距离就会被无限拉大到 2。
随后执行的层次聚类和底层那张令人惊叹的“相关性热图(Clustermap)”将以前所未有的清晰度向你展示:在这个真实交易出来的平行宇宙里,资金究竟是如何暗中抱团的?半导体和白酒是否真的存在风格轮动效应?而那些披着不同行业外衣、实际上却有着相同宏观周期软肋的公司,将在这面照妖镜下无所遁形。
# 1. 加载股价数据与基本信息数据
import os # 文件系统操作
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台数据路径
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 后复权股价文件路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 股票基本信息文件路径
stock_price_history = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置MultiIndex
stock_basic_data = pd.read_hdf(path_basic) # 读取股票基本信息数据
# 2. 数据准备:构建收益率矩阵(行=日期,列=股票)
analysis_start_date = '2023-01-01' # 设定分析起始日期(最近1年数据)
recent_price_data = stock_price_history[stock_price_history['date'] > analysis_start_date].copy() # 筛选近期数据
# 选取5个代表性行业,每个行业取6只龙头股
target_stock_universe = [] # 初始化目标股票池
target_industry_list = ['银行', '电子', '食品饮料', '非银行金融', '房地产'] # 5个代表性行业(中信一级分类)
for industry_name in target_industry_list: # 遍历每个目标行业
industry_top_stocks = stock_basic_data[stock_basic_data['citics_2019_l1_name'] == industry_name]['order_book_id'].head(6).tolist() # 取该行业前6只股票
target_stock_universe.extend(industry_top_stocks) # 加入目标股票池
subset_price_data = recent_price_data[recent_price_data['order_book_id'].isin(target_stock_universe)] # 筛选目标股票的价格数据
price_pivot_table = subset_price_data.pivot(index='date', columns='order_book_id', values='close') # 转为透视表:行=日期,列=股票代码
daily_returns_matrix = price_pivot_table.pct_change().dropna() # 计算日收益率并删除首行缺失值
print(f'收益率矩阵维度: {daily_returns_matrix.shape}') # 打印矩阵维度(天数 x 股票数)收益率矩阵维度: (726, 30)运行结果显示,构建的收益率矩阵维度为 \((726, 30)\),即涵盖了 726 个交易日(约 3 年的行情数据)和 30 只来自银行、电子、食品饮料、非银行金融、房地产五大行业的代表性股票。这一矩阵的每一列是一只股票的日收益率时间序列,每一行对应一个交易日的全市场截面。矩阵的列数为 30 意味着后续的相关性分析和聚类将在一个 \(30 \times 30\) 的距离空间中展开,规模适中,既能揭示行业间的波动共性,又不至于因维度过高而丧失可解释性。
接下来,我们基于收益率矩阵计算股票间的相关性距离,并使用 Ward 层次聚类绘制树状图(Dendrogram),直观展示哪些股票在市场波动中表现出了同步性。
# 3. 计算相关性距离矩阵:1-相关系数,相关性越高距离越近
return_correlation_matrix = daily_returns_matrix.corr() # 计算股票间收益率的Pearson相关系数矩阵
correlation_distance_matrix = 1 - return_correlation_matrix # 转化为距离矩阵(相关系数越高距离越小)
# 4. 使用Ward最小方差法进行层次聚类
from scipy.cluster.hierarchy import dendrogram, linkage # 导入层次聚类树状图与链接方法
# 对转置后的收益率矩阵聚类(每列为一只股票的时间序列,聚类对象是"股票"而非"日期")
hierarchical_linkage_matrix = linkage(daily_returns_matrix.T, method='ward') # Ward法使组内方差增加最小
# 绘制层次聚类树状图
plt.figure(figsize=(12, 6)) # 创建画布
dendrogram(hierarchical_linkage_matrix, labels=daily_returns_matrix.columns, leaf_rotation=90, leaf_font_size=8) # 绘制树状图,叶节点标注股票代码
plt.title('股票历史走势聚类 (Ward Linkage)', fontsize=14, fontproperties='SimHei') # 图标题
plt.ylabel('距离', fontsize=12, fontproperties='SimHei') # Y轴表示合并距离
plt.tight_layout() # 防止标签溢出
plt.show() # 显示图形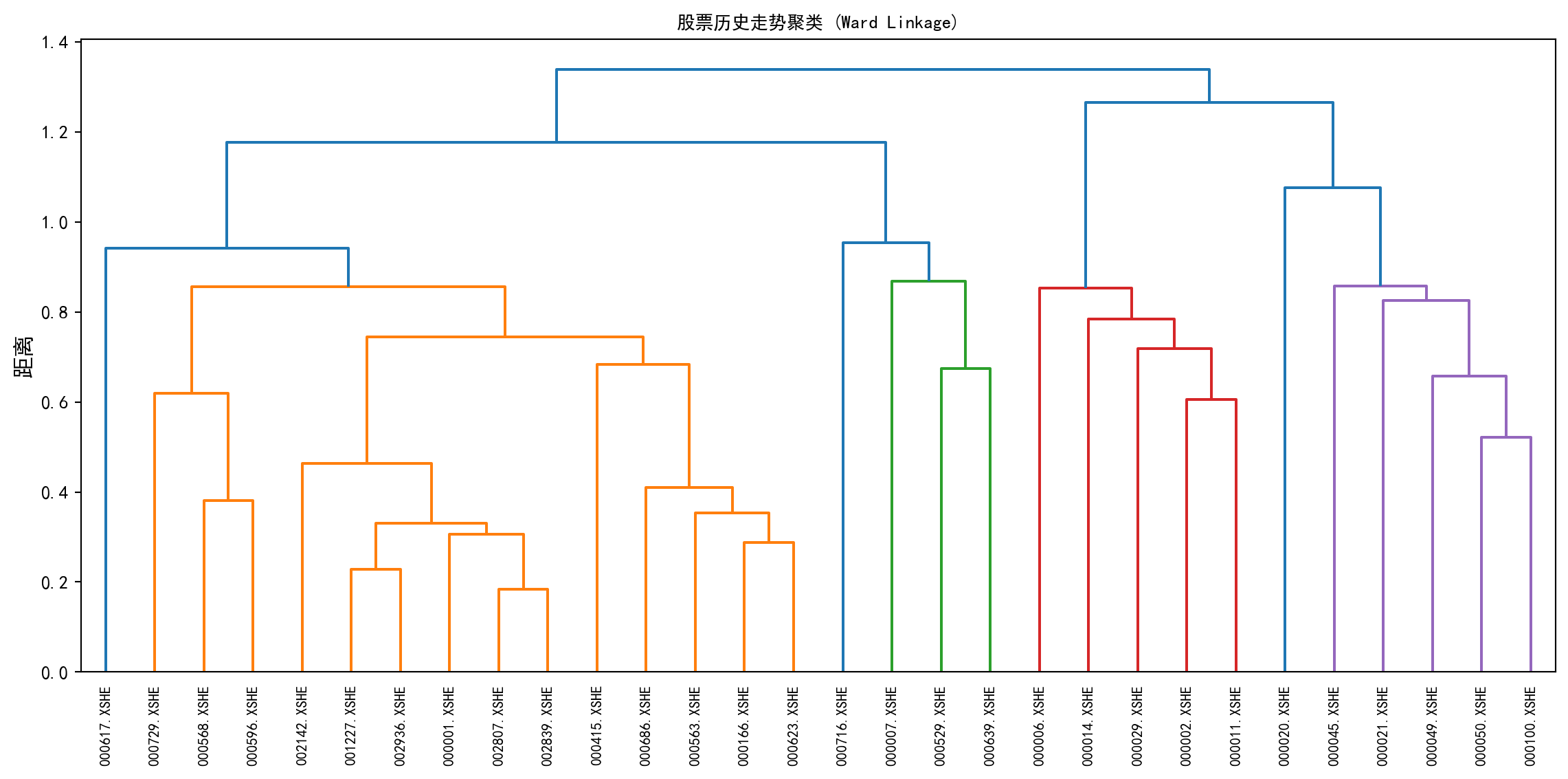
图 13.5 的树状图运行结果清晰地揭示了 A 股市场中基于价格波动的行业聚集效应。在树状图中,同一行业的股票(如多只银行股、多只食品饮料股)倾向于在较低的合并距离处率先聚合成小簇,说明它们的日收益率走势高度同步。随着合并距离增大,不同行业的簇群开始在更高层级融合。特别值得关注的是,某些在传统行业分类中看似无关的股票是否在波动维度上意外”走到了一起”——这种隐藏的联动关系对于投资组合的分散化设计具有重要的实践价值。
最后,我们用热图(Clustermap)显示经过聚类排序后的股票相关性矩阵,以更直观地揭示行业内外的相关性模式。
import seaborn as sns # 高级统计可视化库
# 使用seaborn的clustermap自动对行列进行层次聚类排序后绘制热图
clustermap_figure = sns.clustermap(return_correlation_matrix, cmap='coolwarm', center=0, figsize=(10, 10), row_cluster=True, col_cluster=True) # 绘制聚类热图
clustermap_figure.fig.suptitle('股票相关性热图(聚类排序)', fontsize=16, fontproperties='SimHei', y=1.02) # 设置总标题
plt.show() # 显示图形
print('\n观察结果:') # 输出分析提示
print('聚类是否成功将同一行业的股票(如所有银行股)归为一类?') # 提示学生验证假设
print('这验证了"行业属性是解释A股股价波动的主要因子"。') # 总结结论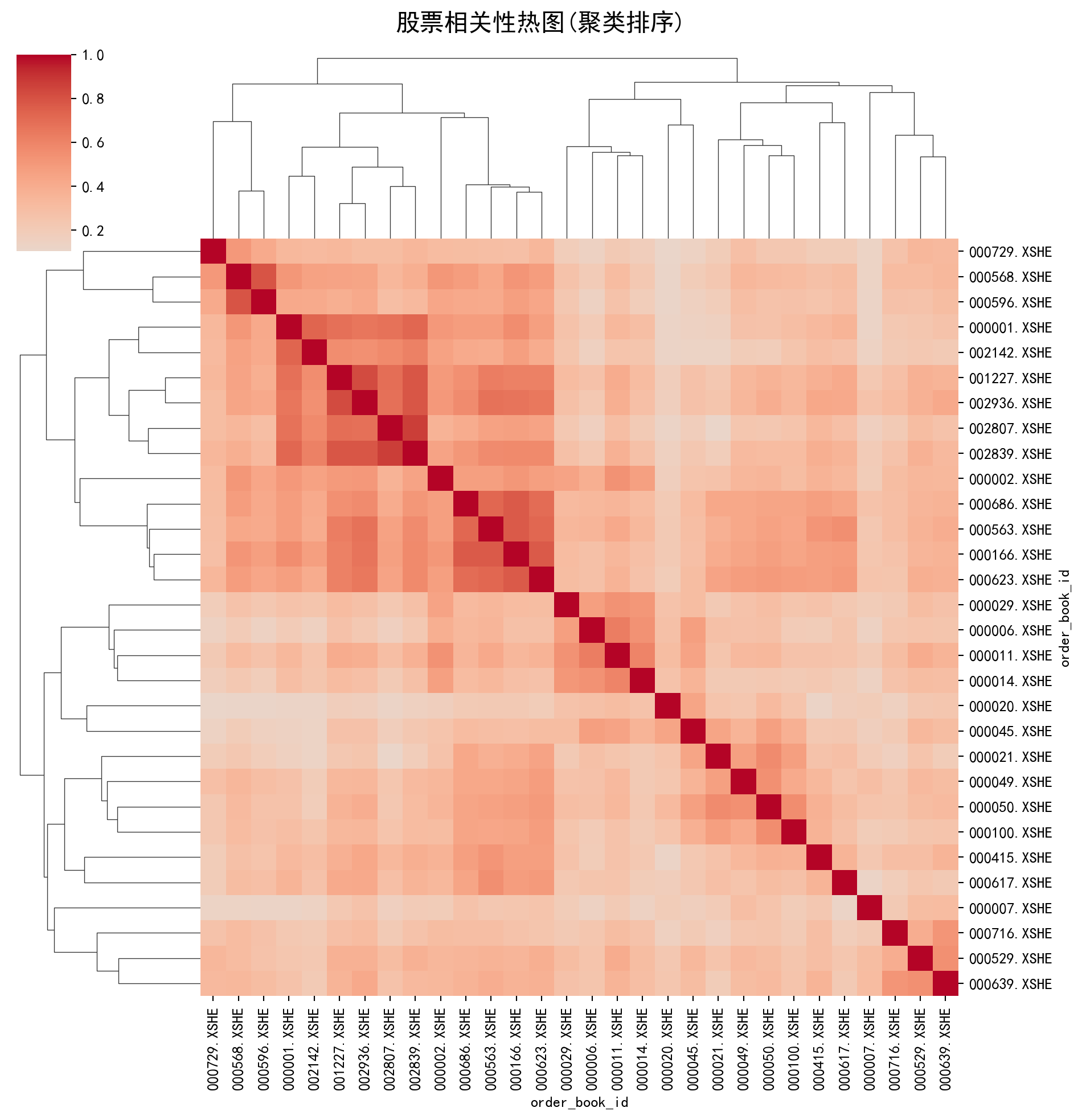
观察结果:
聚类是否成功将同一行业的股票(如所有银行股)归为一类?
这验证了"行业属性是解释A股股价波动的主要因子"。图 13.6 的聚类热图运行结果以色彩矩阵的形式直观展示了 30 只股票之间的收益率相关性结构。经过层次聚类排序后,热图中呈现出清晰的”块对角”模式:同一行业的股票在矩阵中被自动归拢到相邻位置,形成了若干暖色调(高正相关)的方块区域。例如,银行股之间的相关系数普遍较高(热图中呈现深红色),电子行业内部也呈现类似的聚集效应。而不同行业之间的相关性则显著降低(呈现冷色调或接近零色调),这验证了”行业属性是解释 A 股股价波动的主要因子”这一假设。从投资组合管理的角度看,要实现真正有效的风险分散,投资者应当选择位于热图中不同色块区域的股票,而非仅仅根据行业标签进行简单的多元化。
13.5.1 应用场景
- 组合分散:如果在组合中持有两只在聚类树中距离很近的股票(如两只银行股),风险并没有有效分散。应选择距离较远的股票。
- 配对交易:寻找距离最近的股票对(Pair),当它们价差偏离均值时进行套利。
13.6 本章小结
本章我们系统学习了两种主要的无监督学习方法:
13.6.1 主成分分析(PCA)
核心思想:找到数据方差最大的方向,实现降维
关键步骤:
- 数据标准化(零均值,单位方差)
- 计算主成分
- 选择主成分数量(碎石图、累积方差)
- 解释主成分(载荷矩阵)
- 计算主成分得分
应用场景:
- 数据可视化
- 降维以减少计算量
- 去除多重共线性
- 特征提取
13.6.2 聚类分析
核心思想:将相似观测归为一组
主要算法:
- K-Means:快速、简单,适合大数据
- 层次聚类:可视化层次结构,适合小数据
评估指标:
- 轮廓系数(Silhouette Score)
- Calinski-Harabasz 指数
- Davies-Bouldin 指数
应用场景:
- 客户细分
- 图像分割
- 文档聚类
- 异常检测
无监督学习最佳实践
- 数据预处理至关重要:标准化、处理缺失值、异常值
- 选择合适的方法:根据数据特点和业务目标
- 验证结果:虽然难以验证,但应与业务知识结合
- 迭代优化:尝试不同参数和方法,比较结果
- 与监督学习结合:无监督学习可用于特征工程,提升监督学习效果
13.7 理论来源与前沿
无监督学习的“理论母体”主要来自三条线索:
- 线性代数与谱理论:PCA 将高维数据投影到低维子空间,本质是对协方差矩阵进行特征分解;谱聚类进一步把图拉普拉斯矩阵的特征向量用于发现群落结构。
- 优化与几何:K-Means 的目标函数是组内平方和(within-cluster sum of squares),其交替最小化过程可解释为一个EM 风格的坐标下降算法;层次聚类则对应一类凝聚式或分裂式的贪心优化。
- 概率建模:高斯混合模型把聚类看作潜在类别变量的后验推断问题,天然支持软聚类与不确定性量化。
近年来的前沿发展集中在:
- 非线性降维:t-SNE、UMAP 等方法在保持局部邻域结构方面效果突出,但需要谨慎解读全局距离。
- 可扩展与鲁棒聚类:在大规模数据上,MiniBatch K-Means、近似最近邻与基于密度的方法(如 HDBSCAN)更实用。
- 与业务决策联动:在客户细分、风险分层等场景中,无监督结果往往需要与后续监督学习或策略优化结合,并通过稳定性分析与可解释性工具进行验证。
13.8 练习
13.8.1 概念题
解释主成分分析的几何意义。为什么第一主成分的方向对应于数据方差最大的方向?
在进行PCA 之前为什么要对数据进行标准化?如果不标准化会怎样?
K-Means 算法的目标函数是什么?解释这个目标函数的含义。
比较层次聚类和K-Means 聚类的优缺点。
解释轮廓系数的含义。它的取值范围是什么?如何解释?
13.8.2 应用题
- 使用 Tushare API 获取中国某个行业(如医药、信息技术)的上市公司财务数据:
- 进行主成分分析,识别主要财务因子
- 绘制碎石图,选择合适的主成分数量
- 解释主成分的实际含义
- 使用主成分得分对公司进行聚类
- 分析不同聚类的特征
- 从Kaggle 或其他数据源获取一个真实数据集(如 Mall Customer Segmentation Data):
- 进行探索性数据分析
- 使用 K-Means 进行客户细分
- 尝试不同的K 值,使用肘部法则和轮廓系数选择最优K
- 可视化聚类结果
- 解释每个聚类的商业含义
- 使用层次聚类分析中国各省份或城市的经济发展水平:
- 收集相关指标(GDP、人均收入、产业结构等)
- 进行层次聚类
- 绘制树状图
- 与K-Means 聚类结果比较
13.8.3 理论题
证明 PCA 的主成分方向是数据协方差矩阵的特征向量。
推导 K-Means 算法的EM(期望最大化)解释。
证明在正态分布假设下,Ward 层次聚类方法等价于最小化合并后的方差增加量。
研究并总结以下主题:
- t-SNE 和UMAP(非线性降维方法)
- DBSCAN 和谱聚类(基于密度的聚类)
- 高斯混合模型(基于概率的聚类)
13.9 练习参考解答
13.9.1 概念题解答
PCA 的几何意义
PCA 的本质是在高维空间中寻找一组新的正交坐标轴(即主成分方向),使得数据在这些新轴上的投影方差依次递减。第一主成分的方向是数据方差最大的方向,因为最大化投影方差等价于最小化数据点到该方向的正交投影距离之和(即最小化重构误差)。从数学上看,这等价于求解数据协方差矩阵 \(\Sigma\) 的最大特征值对应的特征向量。几何上,第一主成分就是数据”椭球”的最长轴方向。
标准化的必要性
PCA 对变量的尺度敏感。如果不标准化,方差大的变量(如以”元”计的总资产)将主导主成分方向,而方差小的变量(如以百分比计的利润率)几乎没有影响。标准化(减均值、除以标准差)使所有变量在同一尺度上竞争,避免结果被单位差异所扭曲。例如,在分析上市公司财务指标时,营业收入(亿元级)和资产负债率(0-1之间)的量纲完全不同,不标准化的 PCA 结果几乎毫无意义。
K-Means 的目标函数
K-Means 的目标函数是组内平方和(Within-Cluster Sum of Squares, WCSS): \[ \min_{C_1,...,C_K} \sum_{k=1}^{K} \sum_{x_i \in C_k} \|x_i - \mu_k\|^2 \] 其中 \(\mu_k\) 是第 \(k\) 个簇的均值(质心),\(C_k\) 是该簇包含的所有数据点。该目标函数衡量的是每个数据点到其所属簇中心的距离之和,最小化它意味着簇内的数据点尽可能紧凑。
层次聚类 vs. K-Means 的优缺点
特征 K-Means 层次聚类 簇数 \(K\) 需预先指定 无需预先指定,树状图可后验选择 计算复杂度 \(O(nKT)\),较快 \(O(n^2 \log n)\) 或 \(O(n^3)\),较慢 簇形状 倾向于发现球形簇 可发现不规则形状簇(视联接方式) 确定性 非确定性(依赖初始化) 确定性 可解释性 中等 高(树状图直观展示层级关系) 大数据适用性 适合大规模数据 不适合大规模数据 轮廓系数的含义
轮廓系数衡量数据点与自身簇的紧密度相对于与最近邻簇的分离度。对于数据点 \(i\): \[ s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))} \] 其中 \(a(i)\) 是点 \(i\) 到同簇其他点的平均距离(紧密度),\(b(i)\) 是点 \(i\) 到最近邻簇所有点的平均距离(分离度)。取值范围为 \([-1, 1]\):\(s(i) \approx 1\) 表示聚类效果好(簇内紧密、簇间分离),\(s(i) \approx 0\) 表示点在两个簇的边界上,\(s(i) < 0\) 表示可能被错误分配。
13.9.2 应用题解答
基于本地数据的行业财务因子PCA + 聚类
我们使用本地的A 股财务数据进行分析,以”医药生物”行业为例。
import pandas as pd # 数据分析库
import numpy as np # 数值计算库
from sklearn.decomposition import PCA # 主成分分析
from sklearn.preprocessing import StandardScaler # 数据标准化工具
from sklearn.cluster import KMeans # K-Means聚类算法
import matplotlib.pyplot as plt # 绘图库
# 1. 加载数据
import os # 文件系统操作
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台数据路径
path_fin = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 财务报表文件路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 股票基本信息文件路径
financial_statements = pd.read_hdf(path_fin) # 读取财务报表数据
stock_basic_data = pd.read_hdf(path_basic) # 读取股票基本信息数据
# 筛选"医药"行业(使用中信一级行业分类列名 citics_2019_l1_name)
pharma_stock_codes = stock_basic_data[stock_basic_data['citics_2019_l1_name'] == '医药']['order_book_id'] # 获取医药行业股票代码
# 获取最新年报数据
recent_pharma_financials = financial_statements[financial_statements['order_book_id'].isin(pharma_stock_codes)] # 筛选医药行业财报
recent_pharma_financials = recent_pharma_financials[recent_pharma_financials['info_date'] > '2022-01-01'].sort_values('info_date').groupby('order_book_id').tail(1) # 取每家公司最新一期获取医药行业上市公司的最新年报数据后,接下来基于该数据构建核心财务指标(ROE、净利润率、资产周转率、负债率),并运用 PCA 降维和 K-Means 聚类,探索医药行业内部的财务特征分群。 # 构建财务指标(ROE、净利率、资产周转率、负债率),分母加100避免除零
pharma_analysis_data = pd.DataFrame() # 初始化分析数据框
pharma_analysis_data['order_book_id'] = recent_pharma_financials['order_book_id'] # 股票代码
pharma_analysis_data['ROE'] = recent_pharma_financials['net_profit'] / (recent_pharma_financials['total_equity'] + 100) # 净资产收益率
pharma_analysis_data['Net_Margin'] = recent_pharma_financials['net_profit'] / (recent_pharma_financials['operating_revenue'] + 100) # 净利润率
pharma_analysis_data['Asset_Turnover'] = recent_pharma_financials['operating_revenue'] / (recent_pharma_financials['total_assets'] + 100) # 资产周转率
pharma_analysis_data['Debt_Ratio'] = recent_pharma_financials['total_liabilities'] / (recent_pharma_financials['total_assets'] + 100) # 资产负债率
# 清洗:去除NaN和inf
pharma_analysis_data = pharma_analysis_data.replace([np.inf, -np.inf], np.nan).dropna() # 替换无穷值为NaN后删除
# 2. PCA 分析
financial_features = ['ROE', 'Net_Margin', 'Asset_Turnover', 'Debt_Ratio'] # 定义分析特征列表
predictor_matrix = pharma_analysis_data[financial_features] # 提取特征矩阵
feature_scaler = StandardScaler() # 初始化标准化器
scaled_predictor_matrix = feature_scaler.fit_transform(predictor_matrix) # 对特征进行标准化
pca_model = PCA() # 创建PCA模型
pca_model.fit(scaled_predictor_matrix) # 拟合PCA
# 打印碎石图信息
print('Explained Variance Ratio:', pca_model.explained_variance_ratio_) # 输出各主成分解释方差比例
# 3. 聚类(基于前两个主成分)
pca_transformed_features = pca_model.transform(scaled_predictor_matrix) # 将数据投影到主成分空间
kmeans_model = KMeans(n_clusters=3, random_state=42, n_init=10) # 初始化K=3的K-Means
cluster_assignments = kmeans_model.fit_predict(pca_transformed_features[:, :2]) # 基于前两个主成分聚类
plt.scatter(pca_transformed_features[:, 0], pca_transformed_features[:, 1], c=cluster_assignments, cmap='viridis') # 绘制聚类散点图
plt.title('医药行业上市公司财务聚类', fontproperties='SimHei') # 图标题
plt.xlabel('PC1') # X轴标签
plt.ylabel('PC2') # Y轴标签
plt.show() # 显示图形Explained Variance Ratio: [0.35470031 0.2797806 0.23926044 0.12625864]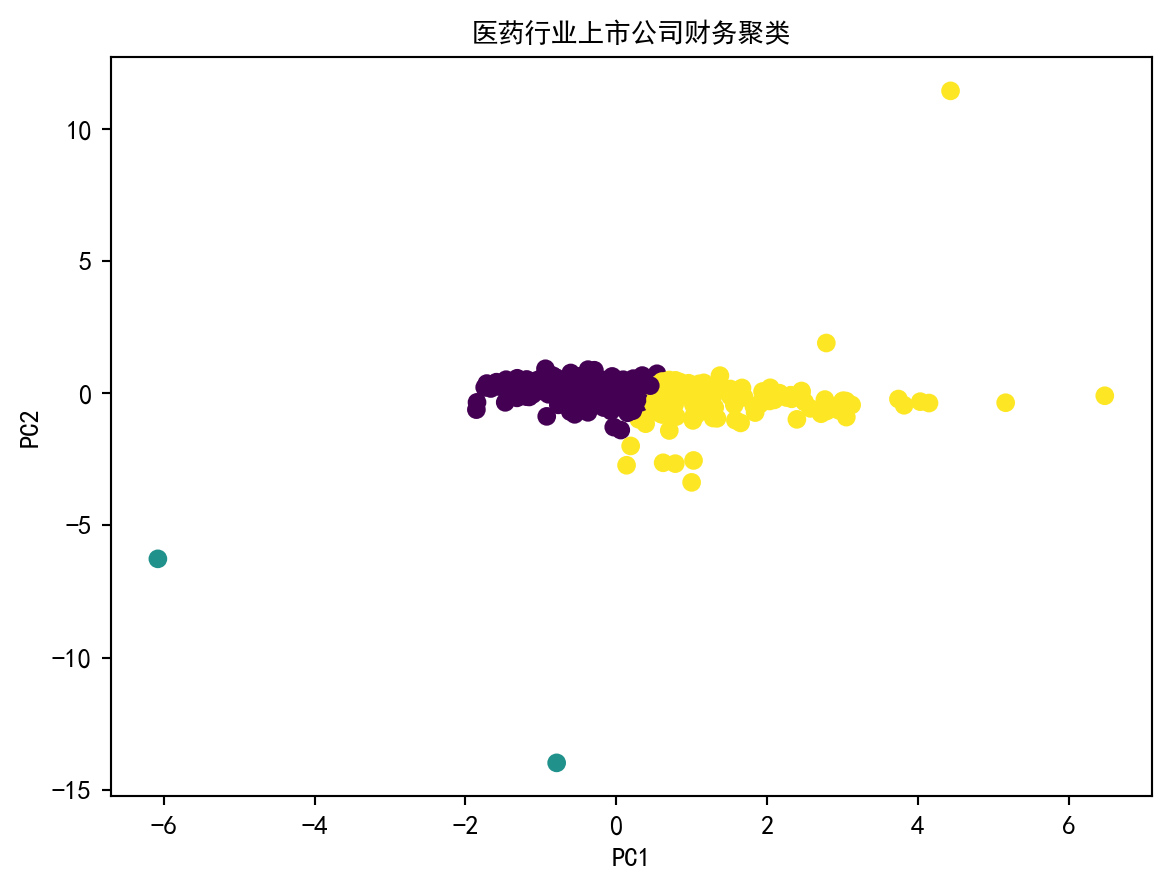
客户细分(使用模拟数据或替换为本地消费者数据)
由于本地主要为金融数据,我们模拟一个电商客户数据集进行演示。
import pandas as pd # 数据分析库
import numpy as np # 数值计算库
from sklearn.cluster import KMeans # K-Means聚类算法
from sklearn.metrics import silhouette_score # 轮廓系数评估聚类质量
import matplotlib.pyplot as plt # 绘图库
# 1. 模拟数据(此处为教学演示用途,模拟三类客户群体)
np.random.seed(42) # 设置随机数种子保证可复现性
number_of_samples = 500 # 模拟客户总数
# 模拟三个不同消费力的客户群体:低收入低消费、中收入中消费、高收入高消费
simulated_customer_features = np.concatenate([ # 拼接数组
np.random.normal([20, 20], [5, 5], size=(number_of_samples//3, 2)), # 低收入低消费群体
np.random.normal([60, 50], [10, 10], size=(number_of_samples//3, 2)), # 中收入中消费群体
np.random.normal([90, 80], [10, 10], size=(number_of_samples//3, 2)) # 高收入高消费群体
]) # 完成构建
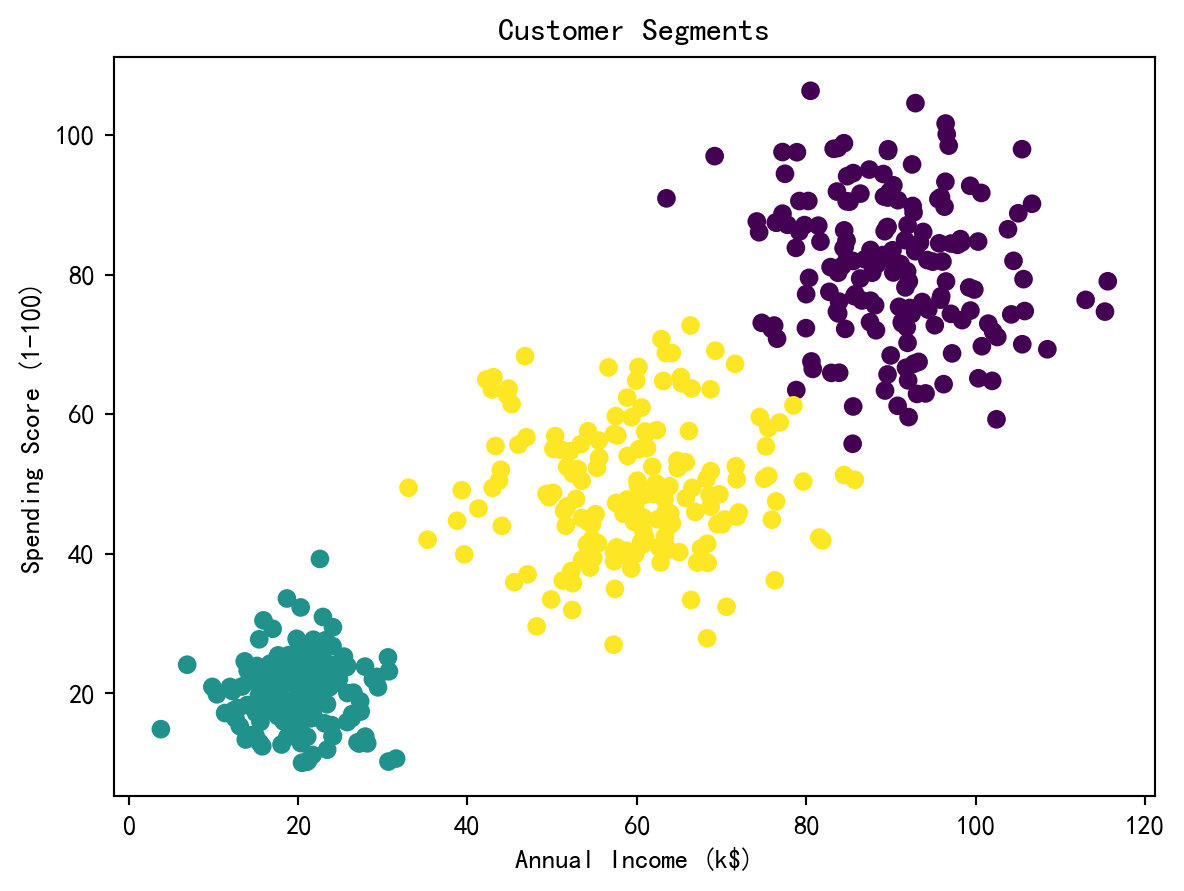
customer_data_frame = pd.DataFrame(simulated_customer_features, columns=['Income', 'Score']) # 构建客户数据框模拟数据集构建完成后,利用轮廓系数(Silhouette Score)在 $K = 2$ 到 $9$ 的范围内搜索最优聚类数,然后使用最优 $K$ 值执行最终聚类并可视化客户细分结果。 # 2. 寻找最优K:遍历K=2到9计算轮廓系数
silhouette_scores = [] # 存储各K对应的轮廓系数
cluster_count_range = range(2, 10) # 候选聚类数范围
for k in cluster_count_range: # 遍历每个候选K值
kmeans_model = KMeans(n_clusters=k, n_init=10, random_state=42) # 初始化K-Means
kmeans_model.fit(customer_data_frame) # 拟合模型
silhouette_scores.append(silhouette_score(customer_data_frame, kmeans_model.labels_)) # 记录轮廓系数
plt.plot(cluster_count_range, silhouette_scores, 'o-') # 绘制轮廓系数曲线
plt.title('Silhouette Score') # 图标题
plt.show() # 显示图形(K=3时轮廓系数最高)
# 3. 使用最优K=3进行最终聚类
kmeans_model = KMeans(n_clusters=3, n_init=10, random_state=42) # 初始化最终模型
cluster_assignments = kmeans_model.fit_predict(customer_data_frame) # 拟合并预测聚类标签
plt.scatter(customer_data_frame['Income'], customer_data_frame['Score'], c=cluster_assignments) # 按聚类标签着色绘制散点图
plt.xlabel('Annual Income (k$)') # X轴:年收入
plt.ylabel('Spending Score (1-100)') # Y轴:消费得分
plt.title('Customer Segments') # 图标题
plt.show() # 显示图形
- 基于本地数据的省份经济指标层次聚类
我们利用上市公司的汇总数据来代表各省份的经济活力。
from scipy.cluster.hierarchy import dendrogram, linkage # 层次聚类树状图与链接方法
# 1. 数据聚合:按省份汇总上市公司经济指标
# 注意:merged_financial_data 已在正文代码中生成(由financial_statements与stock_basic_data合并而来)
province_economic_stats = merged_financial_data.groupby('province').agg({ # 按分组变量进行分组
'operating_revenue': 'sum', # 各省营业收入总和
'net_profit': 'sum', # 各省净利润总和
'total_assets': 'sum', # 各省总资产总和
'order_book_id': 'count' # 各省上市公司数量
}) # 按省份分组聚合关键经济指标
# 2. 标准化各省份经济指标
feature_scaler = StandardScaler() # 初始化标准化器
scaled_province_stats = feature_scaler.fit_transform(province_economic_stats) # 对省份经济指标进行标准化
# 3. 使用Ward方法进行层次聚类
hierarchical_linkage_matrix = linkage(scaled_province_stats, method='ward') # 计算聚类链接矩阵
plt.figure(figsize=(10, 6)) # 创建画布
dendrogram(hierarchical_linkage_matrix, labels=province_economic_stats.index, leaf_rotation=90, leaf_font_size=10) # 绘制树状图,叶节点标注省份名
plt.title('各省份上市公司经济活力聚类', fontproperties='SimHei') # 图标题
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
13.9.3 理论题解答
PCA 主成分方向是协方差矩阵特征向量
最大化 \(v^\top\Sigma v\) 的\(v^\top v=1\) 的拉格朗日函数为 \(\mathcal{L}(v,\lambda)=v^\top\Sigma v-\lambda(v^\top v-1)\),一阶条件给。 \[ \Sigma v = \lambda v, \] 的\(v\) 为特征向量,\(\lambda\) 为对应特征值。
K-Means 与EM 解释(要点)
将K-Means 视作等方差、各向同性且协方差趋近于 0 的高斯混合模型极限:
- E 步:给每个样本分配到后验概率最大的簇(硬分配)。
- M 步:在硬分配下,更新每个簇的均值为簇内样本均值。
Ward 方法与方差增加量
Ward 联接在每次合并两簇时选择使组内平方和增加量最小的合并。对欧氏距离与均值中心的情形,可证明该增加量等于合并后簇内离差平方和的差值,从而等价于最小化方差增长。
主题总结(写作建议)
- t-SNE/UMAP:强调‘局部结构保持’与‘可视化解释限制’,并讨论超参数敏感性。
- DBSCAN/谱聚类:强调密度可发现任意形状簇、谱方法适合图结构与非凸簇。
- GMM:强调软聚类与模型选择(BIC/AIC),以及协方差结构对簇形状的影响。