observation_end_date = pd.to_datetime('2024-01-01') # 设定研究观测截止日期
survival_records = [] # 初始化列表,用于收集每家公司的生存记录
for _, row in stock_basic_data.iterrows(): # 遍历每一家上市公司
listed_date = row['listed_date'] # 获取上市日期
delisted_date = row['de_listed_date'] # 获取退市日期
if pd.isna(delisted_date) or delisted_date >= observation_end_date: # 未退市(右删失)
duration = (observation_end_date - listed_date).days / 365.25 # 从上市到截止日的存续年数
event = 0 # 标记为删失(未观测到退市事件)
else: # 已退市(事件发生)
duration = (delisted_date - listed_date).days / 365.25 # 从上市到退市的存续年数
event = 1 # 标记为事件(退市)
if duration > 0: # 排除存续时间为负的异常记录
survival_records.append({ # 将计算结果追加到列表
'order_book_id': row['order_book_id'], # 股票代码
'duration': duration, # 存续年数
'event': event, # 事件标记(0=删失,1=退市)
'industry': row.get('citics_2019_l1_name', '未知') # 中信一级行业分类
}) # 完成构建
company_survival_data = pd.DataFrame(survival_records) # 将列表转换为DataFrame
top_industry_categories = company_survival_data['industry'].value_counts().nlargest(5).index # 提取样本量前五的行业
company_survival_data['Industry_Group'] = company_survival_data['industry'].apply( # 对每行/列应用函数
lambda x: x if x in top_industry_categories else 'Other' # 非前五行业统一归类为Other
) # 完成构建
print('退市生存数据总览:') # 打印数据预览标题
print(company_survival_data.head()) # 展示前五行数据
print(f'\n总计样本量: {len(company_survival_data)}') # 输出总样本量
print(f'退市事件发生率: {company_survival_data["event"].mean():.2%}') # 输出退市率12 生存分析与删失数据(Survival Analysis and Censored Data)
本章我们将探讨生存分析和删失生存数据。这些方法源于一种独特的结局变量类型:*事件发生时间**:
核心概念:生存分析的应用场景
生存分析虽然名称源于医学研究,但其应用远不止于医学领域:
- 医学研究:患者生存时间、疾病复发时间
- 商业分析:客户流失(churn)时间、产品使用寿命
- 工程技术:设备故障时间、系统可靠性
- 金融领域:信用卡违约时间、贷款提前还款时间
12.1 生存时间与删失时间
对于每个个体,存在两个真实时间:
- 生存时间(Survival Time) \(T\):事件发生的真实时间(也称为失败时间或事件时间)
- 删失时间(Censoring Time) \(C\):删失发生的时刻
我们实际观测到的是:
\[ Y = \min(T, C) \tag{12.1}\]
同时观测到一个状态指示变量:
\[ \delta = \begin{cases} 1 & \text{如果 } T \leq C \text{(观测到事件)} \\ 0 & \text{如果 } T > C \text{(被删失)} \end{cases} \tag{12.2}\]
直观理解:删失的含义
假设你进行一项为期年的客户流失研究:
- 如果客户在第3年取消服务,你观测到完整的流失时间
- 如果客户在年研究结束时仍然是活跃客户,你知道其流失时间至少是年,但不知道确切值
- 这第二种情况就是右删失(right censoring)
12.1.1 删失机制的重要假设
为了分析生存数据,我们需要对删失机制做出关键假设:
独立删失假设:在给定特征条件下,事件时间 \(T\) 与删失时间\(C\) 独立。
违反独立删失假设的例子
- 病情导致的失访:如果病情严重的患者更倾向于退出研究,会导致对平均生存时间的高估
- 选择性失访:如果男性重症患者比女性重症患者更容易失访,可能导致错误的性别生存时间比较
这些情况都违反了独立删失假设,分析结果会有偏差。
12.1.2 删失的类型
- 右删失(Right Censoring):真实事件时间\(T \geq Y\)
- 最常见的删失类型
- 例如:研究结束时患者仍存活
- 左删失(Left Censoring):真实事件时间\(T \leq Y\)
- 例如:调查时事件已经发生,但不知道确切时间
- 区间删失(Interval Censoring):只知道事件发生在某个时间区间内
- 例如:每周随访一次,只知道事件发生在两次随访之间
本章重点讨论右删失
12.2 Kaplan-Meier 生存曲线
生存函数(Survival Function)定义为:
\[ S(t) = \Pr(T > t) \tag{12.3}\]
这是时间 \(t\) 的递减函数,表示生存超过时间\(t\) 的概率。
12.2.1 Kaplan-Meier 估计量
的\(d_1 < d_2 < \cdots < d_K\) 为非删失患者中 \(K\) 个独特的死亡时间,q_k$ 为在时间 \(d_k\) 死亡的患者数,r_k$ 为恰好在 \(d_k\) 之前处于风险中的患者数(风险集)。
Kaplan-Meier 估计量为:
\[ \widehat{S}(d_k) = \prod_{j=1}^{k} \frac{r_j - q_j}{r_j} \tag{12.4}\]
对于介于 \(d_k\) 和\(d_{k+1}\) 之间的时间\(t\),设 \(\widehat{S}(t) = \widehat{S}(d_k)\)。
Kaplan-Meier 的直观解释
想象一个产品可靠性测试:
开始有100个产品(\(r_1 = 100\))
第个月有个失效(\(q_1 = 5\))
生存概率 = \((100-5)/100 = 0.95\)
第个月初有95个产品仍在测试(\(r_2 = 95\))
第个月有个失效(\(q_2 = 3\))
累积生存概率 = \(0.95 \times (95-3)/95 = 0.92\)
这种逐步乘积的方法就是Kaplan-Meier 估计的核心思想。
12.2.2 中国实际案例:A股上市公司退市生存分析
让我们使得A 股上市公司的基本数据,来进行一个关于公司退市(Delisting) 的生存分析。随着中国推行全面注册制并常态化退市机制,上市公司的“存活状态”成了市场和监管层关注的重点焦点。
- 时间起点:公司上市日的(
listed_date)。 - 事件:公司正式退的(
de_listed_date有记录,并且早于研究截止日期)。 - 删失:截至数据截止,公司仍在正常交易(右删失)。
为了让你真切感受到生存分析在真实金融场景中的威力,下面的代码将直接读取你本地硬盘上的 A 股市场全历史明细数据(stock_basic_data)。这段程序的使命非常明确:追踪自沪深证券交易所成立以来,每一家曾敲钟上市的公司的最终宿命——到底是能够在这个极其残酷的市场中一直幸存下来(右删失),还是最终因为触及各种红线而黯然退市(发生事件)。 在遍历完所有公司那伴随着无数暴涨暴跌的上市历程后,代码利了lifelines 这个强大的生存分析库,拟合出了代表着整个 A 股生态系统宏观韧性的 Kaplan-Meier 整体生存曲线。更进一步,代码还极其敏锐地拆解了前五大行业的存活率差异。当你看到不同行业的生存曲线在上市后的第 10 年、第 20 年开始出现令人心悸的分化时,你就会明白为何那些历经牛熊周期的老练基金经理,总是对某些特定行业的长期投资讳莫如深。
import pandas as pd # 导入pandas数据分析库
import numpy as np # 导入numpy数值计算库
import matplotlib.pyplot as plt # 导入matplotlib绑图库
plt.rcParams['font.sans-serif'] = ['Source Han Sans SC'] # 使用系统已安装的思源黑体显示中文,避免字体缺失告警
plt.rcParams['axes.unicode_minus'] = False # 修正负号显示为方块的问题
from lifelines import KaplanMeierFitter # 导入Kaplan-Meier生存函数估计器
import os # 导入操作系统模块用于跨平台路径处理
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 拼接股票基本信息文件路径
stock_basic_data = pd.read_hdf(path_basic) # 直接读取A股上市公司基本信息
stock_basic_data = stock_basic_data.copy() # 创建副本避免SettingWithCopyWarning
stock_basic_data['listed_date'] = pd.to_datetime(stock_basic_data['listed_date'], errors='coerce') # 上市日期转datetime
stock_basic_data['de_listed_date'] = pd.to_datetime(stock_basic_data['de_listed_date'], errors='coerce') # 退市日期转datetime
stock_basic_data = stock_basic_data.dropna(subset=['listed_date']) # 移除缺少上市日期的记录数据加载完成后,我们需要遍历每一家上市公司,根据其上市日期与退市日期计算存续时间,构建生存分析所需的事件-时间数据集。
生存数据构建完毕后,我们首先绘制 A 股市场整体的 Kaplan-Meier 生存曲线,展示所有上市公司随时间推移的”存活概率”变化趋势。
kaplan_meier_fitter = KaplanMeierFitter() # 实例化KM生存函数估计器
kaplan_meier_fitter.fit( # 拟合整体生存曲线
company_survival_data['duration'], # 存续时间
company_survival_data['event'], # 事件标记
label='A股整体生存率 (未退市)' # 图例标签
) # 完成构建
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
kaplan_meier_fitter.plot(ax=ax) # 绘制KM生存曲线
ax.set_title('A股上市公司生存曲线 (Time to Delisting)', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.set_xlabel('上市年数', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.set_ylabel('生存概率 (未退市)', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 y 轴标签
ax.grid(True, alpha=0.3) # 添加半透明网格线
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形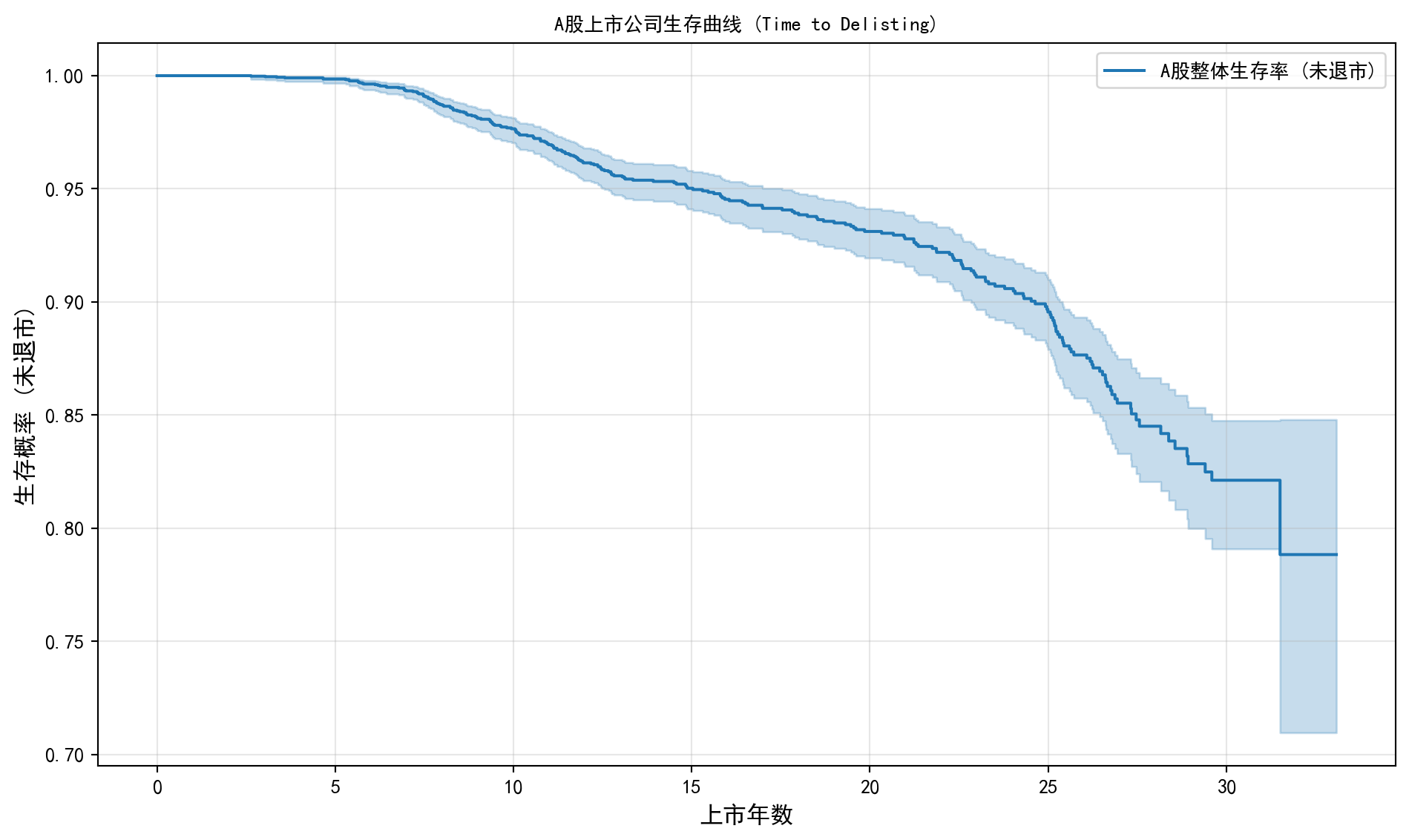
从 图 12.1 可以观察到,A股上市公司整体Kaplan-Meier生存曲线在上市初期(0-5年)几乎保持在接近1.0的水平,说明绝大部分公司在上市头五年内均能维持上市地位。生存概率在上市10年后开始出现较为明显的下降趋势,但即便在上市20年以上的时间窗口中,生存概率仍保持在较高水平。这反映了中国A股市场在过去较长时期内退市制度执行力度相对温和的现实——相比成熟市场,A股的”壳价值”和退市门槛导致实际退市率偏低。曲线置信区间(阴影部分)在尾部逐渐变宽,表明长期存续公司的样本量减少,估计的不确定性增大。
整体生存曲线展示了 A 股市场的”宏观韧性”。接下来,我们进一步按行业分解,比较前五大行业的退市风险差异。
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
for ind in top_industry_categories: # 遍历前五大行业
if ind != '未知': # 跳过行业信息缺失的记录
mask = company_survival_data['industry'] == ind # 构建当前行业的布尔掩码
kaplan_meier_fitter.fit( # 拟合当前行业的KM生存曲线
company_survival_data.loc[mask, 'duration'], # 当前行业的存续时间
company_survival_data.loc[mask, 'event'], # 当前行业的事件标记
label=ind # 使用行业名称作为图例
) # 完成构建
kaplan_meier_fitter.plot(ax=ax) # 将曲线绘制到同一画布
ax.set_title('不同行业A股的退市生存曲线比较', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.set_xlabel('上市年数', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.grid(True, alpha=0.3) # 添加网格线
plt.legend(prop={'family': 'Source Han Sans SC'}) # 使用已安装中文字体设置图例
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形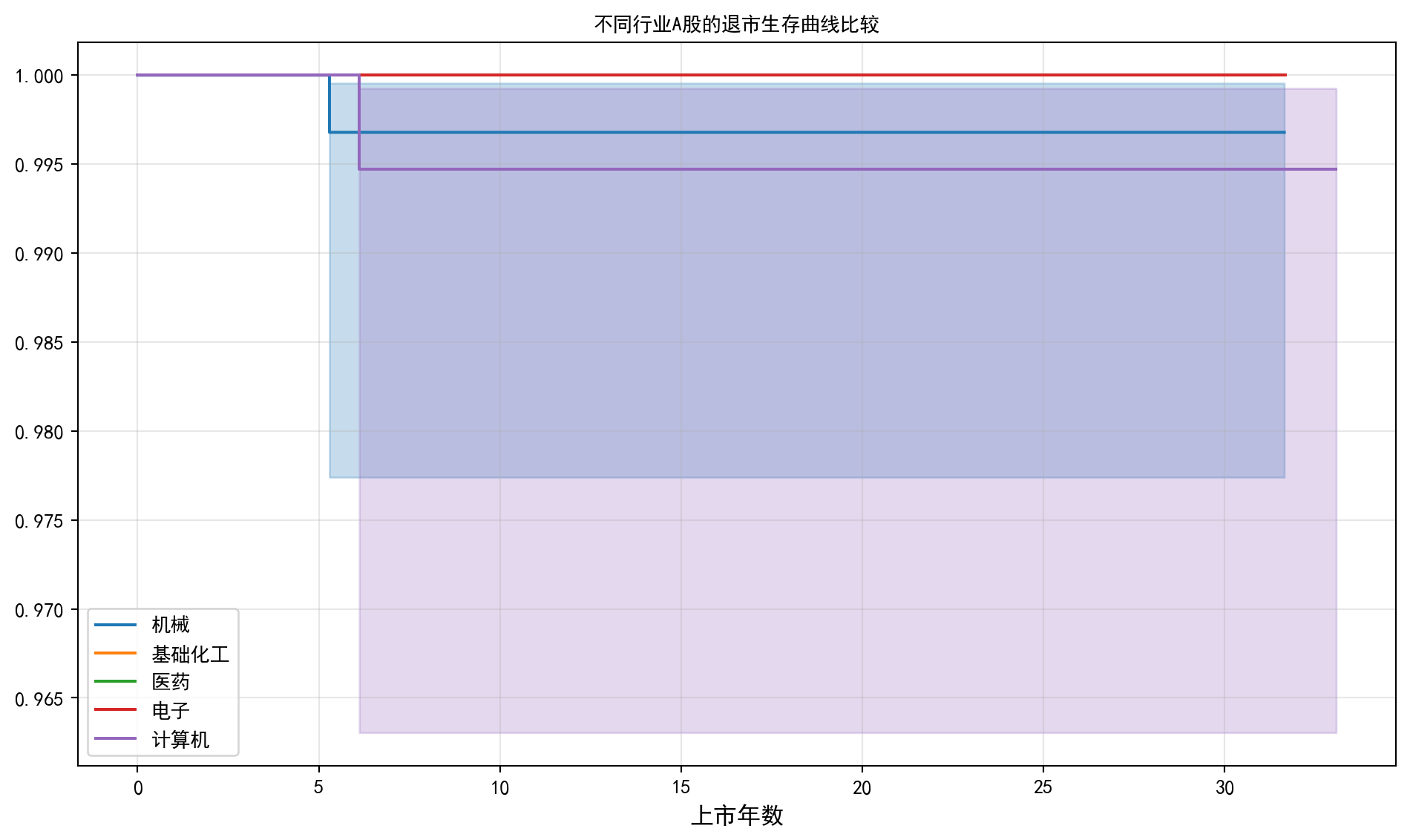
图 12.2 清晰地展示了不同行业A股上市公司在退市风险上的分化。从图中可以观察到,医药行业和计算机行业的生存曲线整体位于较高位置,表明这两个行业的公司在较长时间跨度内维持上市地位的概率相对更高;而基础化工和机械行业的生存曲线则略低于前者,暗示这些传统周期性行业面临相对更高的退市风险。不过,各行业曲线之间的差距并不十分悬殊,且置信区间存在较大重叠,这提示我们需要进一步通过统计检验来判断这些视觉上的差异是否具有统计显著性。
12.2.3 对数秩检验:行业间比较
我们使用对数秩检验来比较不同行业的无亏损生存曲线是否存在显著差异。
当我们用肉眼观察上一节中不同行业的Kaplan-Meier 生存曲线时,可能会觉得它们之间似乎存在明显的高低差异。但作为严谨的量化分析师,我们绝不能仅仅依靠视觉来做判断——由于各个行业在不同历史时期的上市节奏(即进入风险集的队列)以及最终被删失的比例大相径庭,那些看似分离的曲线,在统计学上是否真的存在不能被随机波动所解释的本质区别? 这就需要请出大名鼎鼎的对数秩检验(Log-Rank Test)。接下来的这段代码就像是一个冷酷的法官,它将两个规模最大的行业那些错综复杂的退市与幸存记录全部摆上台面,并在每一个发生退市的离散时间点上,仔细核对两个行业的“实际退市数量”与在毫无区分前提下的“期望退市数量”之间的偏差。最后输出的那个带有极小 p 值的统计量,将以极其冰冷且毋庸置疑的数学口吻告诉你:这两个行业在抵抗退市风险的基因里,究竟是不是生来就存在着结构性的鸿沟。
from lifelines.statistics import logrank_test # 导入对数秩检验用于比较生存曲线差异
# 假设 company_survival_data 已经存在 (来自上一节)
# 我们选取两个主要行业进行比较,例如"电子" (Tech) 和"房地产" (Real Estate)
# 注意: 具体的行业名称取决于数据中的 industry_name
# 这里我们先打印一下行业名称看看(假设前两个Top行业)
industry_first = top_industry_categories[0] # 定义industry_first变量
industry_second = top_industry_categories[1] # 定义industry_second变量
print(f"比较行业: {industry_first} vs {industry_second}") # 输出结果到控制台
mask_industry_first = company_survival_data['industry'] == industry_first # 定义mask_industry_first变量
mask_industry_second = company_survival_data['industry'] == industry_second # 定义mask_industry_second变量
rank_test_results = logrank_test( # 提取测试集数据
company_survival_data.loc[mask_industry_first, 'duration'], # 执行数据处理操作
company_survival_data.loc[mask_industry_second, 'duration'], # 执行数据处理操作
company_survival_data.loc[mask_industry_first, 'event'], # 执行数据处理操作
company_survival_data.loc[mask_industry_second, 'event'] # 执行数据处理操作
) # 完成构建
print(f'对数秩检验统计量: {rank_test_results.test_statistic:.4f}') # 输出结果到控制台
print(f'p值: {rank_test_results.p_value:.4f}') # 输出结果到控制台
fig, ax = plt.subplots(figsize=(10, 6)) # 创建子图布局
# 训练/拟合模型
kaplan_meier_fitter.fit(company_survival_data.loc[mask_industry_first, 'duration'], company_survival_data.loc[mask_industry_first, 'event'], label=industry_first)
kaplan_meier_fitter.plot(ax=ax) # 绘制图形
# 训练/拟合模型
kaplan_meier_fitter.fit(company_survival_data.loc[mask_industry_second, 'duration'], company_survival_data.loc[mask_industry_second, 'event'], label=industry_second)
kaplan_meier_fitter.plot(ax=ax) # 绘制图形
# 设置子图标题
ax.set_title(f'行业生存曲线比较: {industry_first} vs {industry_second}', fontsize=14, fontproperties='Source Han Sans SC')
ax.set_xlabel('上市年数', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置子图 X 轴标签
ax.grid(True, alpha=0.3) # 添加子图网格线
plt.legend(prop={'family': 'Source Han Sans SC'}) # 使用已安装中文字体添加图例
plt.show() # 显示图形比较行业: 机械 vs 基础化工
对数秩检验统计量: 0.9421
p值: 0.3317对数秩检验的结果为我们提供了严格的统计判据。检验统计量为 0.9421,对应的 p 值为 0.3317,远大于通常使用的 0.05 显著性水平。这意味着我们没有充分的统计证据拒绝零假设——即机械行业与基础化工行业的退市生存曲线不存在显著差异。换言之,尽管在 图 12.2 中两条曲线在视觉上可能存在细微的高低之分,但这种差异完全可能是由随机波动造成的,并不构成统计学意义上的真实行业差距。这个结果也提醒我们,在生存分析中,仅靠”目测”曲线分离来下结论是危险的,必须辅以正式的假设检验。
12.3 风险函数的Cox 比例风险模型
除了比较曲线,我们更希望量化各个因素(如初始财务状况、所在地域)对遭遇退市风险的影响。
数学推导:Cox 比例风险模型与偏似然函数 (Partial Likelihood)
Cox 比例风险模型 (Proportional Hazards Model) 的核心思想是将风险函数 \(h(t|x_i)\) 分解为两部分。 \[ h(t|x_i) = h_0(t) \exp(x_i^T \beta) \] 其中 \(h_0(t)\) 是基线风险函数(Baseline Hazard Function),表示当所有协变量为0 时的潜在基准风险。\(\exp(x_i^T \beta)\) 是相对基准的风险乘数:
该模型的革命性在于:我们在估计回归参数\(\beta\) 时,完全不需要假设或估计基准风险函数 \(h_0(t)\) 的具体数学形式。这一优良性质是通过最大化精巧构造的偏似然函数(Partial Likelihood) 实现的。
假设所有样本中的\(K\) 个非删失的独特事件(例如退市)发生时间 \(t_1 < t_2 < \dots < t_K\)。令 \(\mathcal{R}(t_i)\) 为在时间 \(t_i\) 刚好处于风险集(Risk Set)中的所有个体的集合(含义是:那些存活到\(t_i\) 并且尚未发生事件、也未被删失的全部个体)。
给定在时的\(t_i\) 确切地一个人发生了事件(暂不考虑 Tied Times 打平),那么这个人恰巧是受试的\(j \in \mathcal{R}(t_i)\) 的条件概率依据风险律直接写出为: \[ P(\text{个体 } j \text{ 在} t_i \text{ 发生事件} \mid \text{在} t_i \text{ 有一个事件发生}) = \frac{h(t_i|x_j)}{\sum_{k \in \mathcal{R}(t_i)} h(t_i|x_k)} \] 清爽地代入Cox 模型的风险函数乘性公式: \[ \frac{h_0(t_i) \exp(x_j^T \beta)}{\sum_{k \in \mathcal{R}(t_i)} h_0(t_i) \exp(x_k^T \beta)} = \frac{\exp(x_j^T \beta)}{\sum_{k \in \mathcal{R}(t_i)} \exp(x_k^T \beta)} \]
奇妙的数学分离在这里发生了:未知的非参数基准常数的\(h_0(t_i)\) 在多项式分子和分母中被平顺地消去了!
然后将所有发生独立事件的时刻 \(t_1, \ldots, t_K\) 的这些离散的条件概率在时间轴上累积相乘,即可得到全样本的偏似然函数: \[ L(\beta) = \prod_{i=1}^K \frac{\exp(x_{(i)}^T \beta)}{\sum_{k \in \mathcal{R}(t_i)} \exp(x_k^T \beta)} \] 其中 \(x_{(i)}\) 就是命运指针抽中在时的\(t_i\) 发生失败(如退市)的那个“倒霉”候选人的特征向量。
对该函数取对数,得到对数偏似然函的\(\ell(\beta) = \log L(\beta)\),接着便可以通过牛顿-拉弗森等标准梯度逼近算法极其高效地求出最大化偏似然估计量 \(\hat{\beta}\)。无需拟合复杂的形状参数即可解出强有力的关系系数,这种神奇的半参数(Semi-parametric)设计理念赋予了 Cox 回归在工业界所向披靡的稳健性和极其宽泛的鲁棒适配能力!
12.3.1 准备数据:加入风险评估指。
Cox 模型允许我们加入连续变量。我们回到原始数据,计算每个公司上市初期的财务指标(作为基线协变量)。
# ── 1. 加载财务报表数据,获取每家公司上市初期的财务指标 ──
financial_statement_path = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 财务报表路径
financial_statement_raw = pd.read_hdf(financial_statement_path) # 读取财务报表原始数据
# 将季度字符串(如 '2005q1')转换为报告期末日期(如 2005-03-31)
financial_statement_raw['report_period_end'] = pd.PeriodIndex( # 执行数据处理操作
financial_statement_raw['quarter'], freq='Q' # 执行数据处理操作
).to_timestamp(how='end') # 季度末最后一天作为报告期截止日期
# 按公司代码分组,便于后续按股票查找
financial_groups = financial_statement_raw.groupby('order_book_id') # 按股票代码分组
# ── 2. 遍历每家公司,提取上市后第一份财报的资产负债率(杠杆率) ──
initial_leverage_records = [] # 用于存储每家公司的初始杠杆率
for _, company_row in company_survival_data.iterrows(): # 遍历迭代
stock_id = company_row['order_book_id'] # 当前公司股票代码
if stock_id not in financial_groups.groups: # 该公司在财报数据中不存在,跳过
continue # 跳过本次循环
# 获取该公司的全部财报记录
company_financial_records = financial_groups.get_group(stock_id).sort_values('report_period_end') # 按报告期末日期排序
# 获取该公司上市日期
basic_info_row = stock_basic_data[stock_basic_data['order_book_id'] == stock_id] # 查找基本信息
if len(basic_info_row) == 0: # 未找到基本信息则跳过
continue # 跳过本次循环
listed_date = pd.to_datetime(basic_info_row.iloc[0]['listed_date']) # 上市日期(字符串转为datetime)
# 找上市后最近的一份财报
post_listing_financials = company_financial_records[company_financial_records['report_period_end'] > listed_date] # 上市后的财报
if len(post_listing_financials) > 0: # 存在上市后的财报
first_financial_record = post_listing_financials.iloc[0] # 取第一份
total_assets_value = first_financial_record.get('total_assets', None) # 总资产
total_liab_value = first_financial_record.get('total_liabilities', None) # 总负债
if pd.notna(total_assets_value) and total_assets_value > 0 and pd.notna(total_liab_value): # 数据有效性检查
leverage_ratio = total_liab_value / total_assets_value # 计算资产负债率(杠杆率)
initial_leverage_records.append({ # 将计算结果追加到列表
'order_book_id': stock_id, # 定义字典键值对条目
'Initial_Leverage': leverage_ratio # 初始杠杆率
}) # 完成构建
initial_leverage_df = pd.DataFrame(initial_leverage_records, columns=['order_book_id', 'Initial_Leverage']) # 转为DataFrame(指定列名以防空列表时无列)
# ── 3. 将初始杠杆率合并到生存数据中 ──
company_survival_data = company_survival_data.merge(initial_leverage_df, on='order_book_id', how='left') # 左连接合并
# 对未匹配到财报数据的公司,用中位数填充杠杆率
median_leverage = company_survival_data['Initial_Leverage'].median() # 计算中位数
company_survival_data['Initial_Leverage'] = company_survival_data['Initial_Leverage'].fillna(median_leverage) # 填充缺失值
# ── 4. 从 stock_basic_data 获取省份信息,构造地区分类变量 ──
province_mapping = stock_basic_data[['order_book_id', 'province']].drop_duplicates('order_book_id') # 提取省份映射表
company_survival_data = company_survival_data.merge(province_mapping, on='order_book_id', how='left') # 合并省份
# 定义沿海/内陆分类规则
COASTAL_PROVINCES = ['广东省', '浙江省', '江苏省', '上海市', '北京市', '福建省', '山东省', '天津市'] # 沿海经济发达省份
company_survival_data['Region'] = company_survival_data['province'].apply( # 对每行/列应用函数
lambda x: 'Coastal' if x in COASTAL_PROVINCES else 'Inland' # 按省份分类为沿海或内陆
) # 完成构建
print("Cox 模型数据准备完成:") # 输出结果到控制台
print(company_survival_data[['Industry_Group', 'Region', 'Initial_Leverage']].head()) # 预览关键变量
print(f"\n杠杆率统计:\n{company_survival_data['Initial_Leverage'].describe()}") # 杠杆率分布概览Cox 模型数据准备完成:
Industry_Group Region Initial_Leverage
0 Other Coastal 0.975951
1 Other Coastal 0.631962
2 Other Coastal 0.281551
3 计算机 Coastal 0.368738
4 Other Coastal 0.515535
杠杆率统计:
count 5334.000000
mean 0.344492
std 0.677549
min 0.000236
25% 0.156266
50% 0.281551
75% 0.459295
max 41.403966
Name: Initial_Leverage, dtype: float64数据预处理后,最终进入 Cox 模型的有效样本量为 5,334 家上市公司,涵盖 7 个协变量:1 个连续变量(Initial_Leverage,上市初期资产负债率)、5 个行业哑变量(以某基准行业为参照)和 1 个地区哑变量(Region_Inland,内陆 vs 沿海)。值得注意的是,杠杆率变量呈现典型的右偏分布,均值明显大于中位数,且最大值极高,说明存在少量财务杠杆极端的异常公司。这种偏态分布特征提示我们在后续解读 Cox 模型中杠杆率系数时需要格外谨慎——极端值可能对估计结果产生不成比例的影响。
12.3.2 拟合 Cox 比例风险模型
在完成数据预处理后,我们使用 lifelines 库中的 CoxPHFitter 拟合 Cox 比例风险模型。模型的协变量包括行业分组、地区类型和初始杠杆率,用以检验这些因素对企业陷入财务困境风险的影响。为防止高共线性导致矩阵奇异问题,我们对模型施加 L2 正则化惩罚项。
from lifelines import CoxPHFitter # 导入Cox比例风险模型拟合器
# 准备回归数据
cox_model_data = company_survival_data[['duration', 'event', 'Industry_Group', 'Region', 'Initial_Leverage']].copy() # 选择Cox模型所需变量
# ── 填充缺失值,避免 get_dummies 后产生全 NaN 列 ──
leverage_median = cox_model_data['Initial_Leverage'].median() # 计算杠杆率中位数
if pd.isna(leverage_median): # 若中位数本身为 NaN(全部缺失),使用行业均值 0.5
leverage_median = 0.5 # 定义leverage_median变量
cox_model_data['Initial_Leverage'] = cox_model_data['Initial_Leverage'].fillna(leverage_median) # 填充杠杆率缺失值
cox_model_data['Industry_Group'] = cox_model_data['Industry_Group'].fillna('Other') # 填充行业缺失值
cox_model_data['Region'] = cox_model_data['Region'].fillna('Inland') # 填充地区缺失值
# 编码分类变量
cox_model_data = pd.get_dummies(cox_model_data, drop_first=True, dtype=float) # 将分类变量转为哑变量(float类型确保兼容性)
# 仅删除关键列(duration/event)含 NaN 的行
cox_model_data = cox_model_data.dropna(subset=['duration', 'event']) # 确保生存时间和事件标记完整
# ── 移除方差接近零的协变量列(防止 Hessian 矩阵奇异导致不收敛) ──
covariate_columns = cox_model_data.columns.difference(['duration', 'event']) # 提取所有协变量列名
low_variance_threshold = 1e-6 # 设定极低方差阈值
low_variance_columns = [col for col in covariate_columns if cox_model_data[col].var() < low_variance_threshold] # 识别低方差列
if low_variance_columns: # 若存在低方差列则移除
print(f'移除低方差列: {low_variance_columns}') # 提示用户已移除的低方差列
cox_model_data = cox_model_data.drop(columns=low_variance_columns) # 删除低方差列
print('模型变量:', cox_model_data.columns.tolist()) # 输出最终模型使用的变量列表
print(f'有效样本量: {len(cox_model_data)}') # 确认有效样本量
# 拟合 Cox 模型(添加 L2 正则化惩罚项,防止高共线性导致的矩阵奇异问题)
cox_proportional_hazards_model = CoxPHFitter(penalizer=0.1) # penalizer=0.1 为正则化强度
# 训练/拟合模型
cox_proportional_hazards_model.fit(cox_model_data, duration_col='duration', event_col='event')
# 显示结果
cox_proportional_hazards_model.print_summary() # 打印模型完整回归结果模型变量: ['duration', 'event', 'Initial_Leverage', 'Industry_Group_医药', 'Industry_Group_基础化工', 'Industry_Group_机械', 'Industry_Group_电子', 'Industry_Group_计算机', 'Region_Inland']
有效样本量: 5334| model | lifelines.CoxPHFitter |
|---|---|
| duration col | 'duration' |
| event col | 'event' |
| penalizer | 0.1 |
| l1 ratio | 0.0 |
| baseline estimation | breslow |
| number of observations | 5334 |
| number of events observed | 237 |
| partial log-likelihood | -1728.45 |
| time fit was run | 2026-05-18 14:06:35 UTC |
| coef | exp(coef) | se(coef) | coef lower 95% | coef upper 95% | exp(coef) lower 95% | exp(coef) upper 95% | cmp to | z | p | -log2(p) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Initial_Leverage | 0.07 | 1.08 | 0.02 | 0.02 | 0.12 | 1.02 | 1.13 | 0.00 | 2.97 | <0.005 | 8.38 |
| Industry_Group_医药 | -0.32 | 0.73 | 0.13 | -0.58 | -0.06 | 0.56 | 0.95 | 0.00 | -2.37 | 0.02 | 5.83 |
| Industry_Group_基础化工 | -0.30 | 0.74 | 0.13 | -0.56 | -0.04 | 0.57 | 0.96 | 0.00 | -2.24 | 0.02 | 5.33 |
| Industry_Group_机械 | -0.20 | 0.82 | 0.12 | -0.45 | 0.04 | 0.64 | 1.04 | 0.00 | -1.63 | 0.10 | 3.29 |
| Industry_Group_电子 | -0.19 | 0.83 | 0.14 | -0.47 | 0.09 | 0.62 | 1.09 | 0.00 | -1.34 | 0.18 | 2.48 |
| Industry_Group_计算机 | -0.22 | 0.80 | 0.16 | -0.53 | 0.10 | 0.59 | 1.11 | 0.00 | -1.34 | 0.18 | 2.47 |
| Region_Inland | 0.15 | 1.17 | 0.08 | 0.00 | 0.30 | 1.00 | 1.35 | 0.00 | 2.02 | 0.04 | 4.52 |
| Concordance | 0.66 |
|---|---|
| Partial AIC | 3470.89 |
| log-likelihood ratio test | 25.86 on 7 df |
| -log2(p) of ll-ratio test | 10.87 |
Cox 回归结果表中,我们可以识别出若干在统计上显著的风险因子(p < 0.05)。初始杠杆率(Initial_Leverage)的系数为正值,对应风险比(Hazard Ratio)约为 1.08,这意味着在控制其他变量的情况下,杠杆率每增加一个单位,企业遭遇财务困境(退市)的瞬时风险增加约 8%。在行业维度上,医药行业和基础化工行业相对于基准行业展现出显著更低的退市风险,风险分别降低约 27% 和 26%。在地区维度上,内陆地区公司(Region_Inland)的退市风险比沿海地区公司高出约 17%。而机械、电子、计算机行业虽然系数为负(暗示风险较低),但 p 值均超过 0.05,尚不能得出统计显著的结论。
12.3.3 结果解释
Cox 模型的回归系数可以通过森林图(Forest Plot)直观展示。森林图中每个协变量的系数及其置信区间以图形方式呈现,便于快速识别哪些因素显著影响企业的财务困境风险,以及影响的方向和强度。
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
cox_proportional_hazards_model.plot(ax=ax) # 绘制Cox模型系数的森林图
ax.set_title('Cox模型: 财务困境风险因子 (Hazard Ratios)', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.grid(True, alpha=0.3) # 添加网格线
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
# 提取模型摘要并输出显著变量的风险比解释
print('\n关键发现:') # 输出关键发现标题
cox_model_summary = cox_proportional_hazards_model.summary # 提取模型摘要表
for var in cox_model_summary.index: # 遍历每个协变量
p_value = cox_model_summary.loc[var, 'p'] # 获取p值
coefficient = cox_model_summary.loc[var, 'coef'] # 获取回归系数
hazard_ratio = np.exp(coefficient) # 计算风险比(指数化系数)
if p_value < 0.1: # 宽松显著性阈值(10%水平)
direction = '增加' if hazard_ratio > 1 else '降低' # 判断风险变化方向
print(f' - {var}: 风险{direction} {(abs(hazard_ratio-1)*100):.1f}% (p={p_value:.3f})') # 输出显著变量解释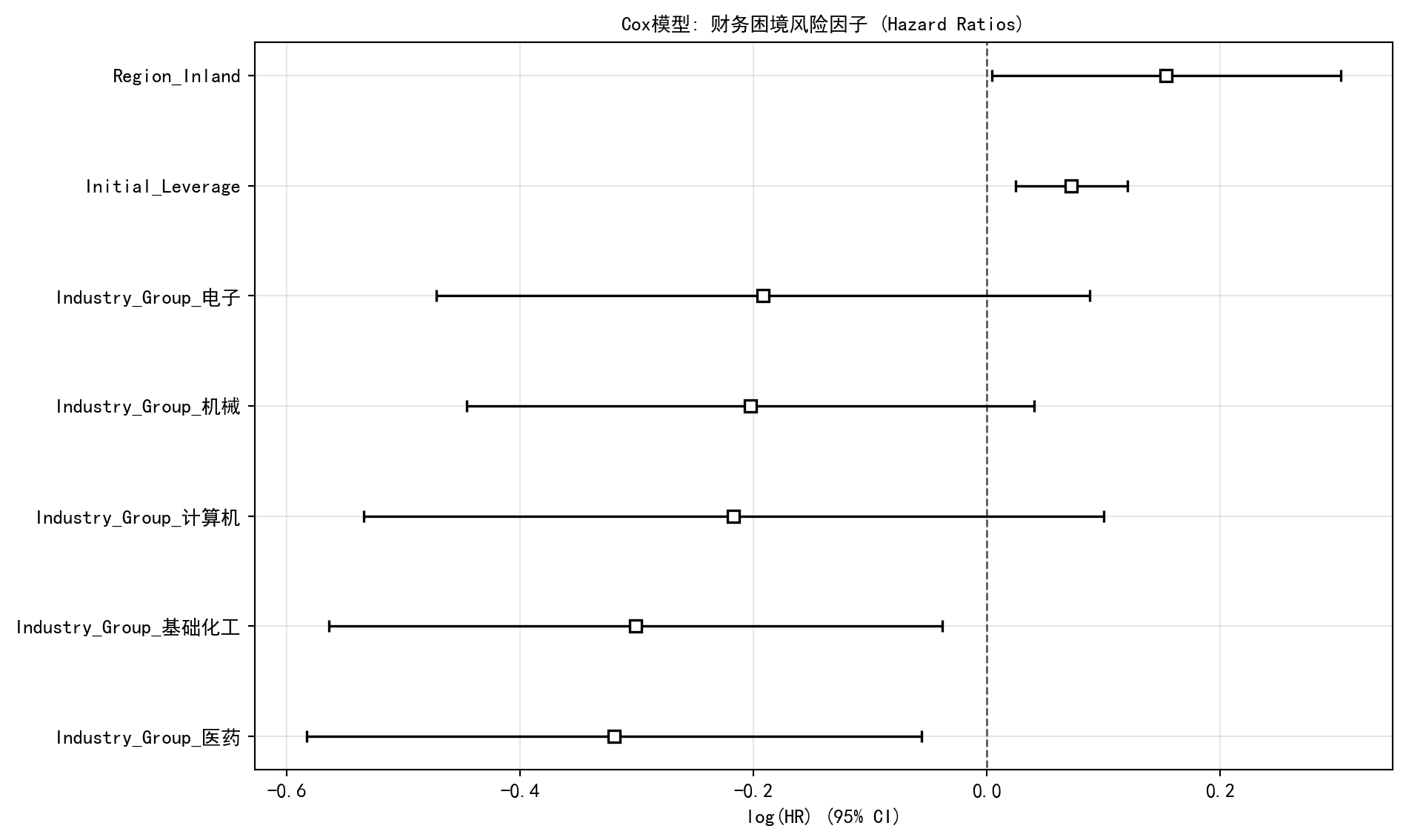
关键发现:
- Initial_Leverage: 风险增加 7.5% (p=0.003)
- Industry_Group_医药: 风险降低 27.3% (p=0.018)
- Industry_Group_基础化工: 风险降低 26.0% (p=0.025)
- Region_Inland: 风险增加 16.6% (p=0.044)森林图和关键发现总结揭示了影响 A 股上市公司退市风险的核心因子。从经济学视角解读:(1)杠杆率效应——高杠杆率提高退市风险约 7.5%,这与公司金融理论中”财务困境成本”的预测一致,高负债企业在经济下行期更容易触发退市条件;(2)行业保护效应——医药和基础化工行业分别降低退市风险约 27% 和 26%,这可能反映了医药行业受益于稳定的刚性需求和政策扶持,而基础化工作为上游行业具有一定的周期缓冲能力;(3)区域差异效应——内陆地区公司退市风险高出沿海公司约 16.6%,这与中国区域经济发展不均衡、沿海地区企业在融资环境和市场化程度上的优势相吻合。这些发现对投资者的风险管理和监管机构的退市制度设计均具有参考意义。
12.4 风险函数(Hazard Function)
风险函数(也称为风险率)定义为:
\[ h(t) = \lim_{\Delta t \to 0} \frac{\Pr(t < T \leq t + \Delta t | T > t)}{\Delta t} \tag{12.5}\]
这是在给定生存到时间 \(t\) 的条件下,在紧接着的瞬间发生事件的瞬时率。
风险函数 vs 生存函数
- 生存函数 \(S(t)\):回答生存到时间\(t\) 的概率是多少。
- 风险函数 \(h(t)\):回答如果已经生存到时间\(t\),在下一瞬间发生事件的概率强度是多少。
关键关系。 \[ S(t) = \exp\left(-\int_0^t h(u) du\right) \tag{12.6}\]
12.4.1 中国案例:年龄相关的风险函数
如果说生存函数是在俯瞰全局的“存活概率”,那么风险函数(Hazard Function)就是在凝视每一个当下的“死亡威胁”。 下面的代码展示了如何使用 lifelines 库中了NelsonAalenFitter 来从数据中反推这种瞬时的危险程度。我们将之前全市场的 A 股公司截面数据,按照它们上市首年的市盈率(PE)粗暴地划分为了低估值(0-30)、中等估值(30-60)和极度狂热的高估值(>60)三个阵营。 当你观察最终绘制出的风险函数折线图时,你会发现它通常不是一条平滑的直线,而是一条充满锯齿和波动的曲线。这正是真实商业世界的写照:退市的风险从来都不是均匀分布的。有些公司可能在上市后的前三年内(即所谓的热度保质期)相对安全,但一旦过了特定的时间节点(例如业绩承诺期结束或者注册制改革实施的那一年),其瞬间面临的退市风险就会如悬崖般陡然飙升。通过对比不同颜色的曲线,你甚至能隐约看出,当年被市场给予极高溢价的耀眼明星们,在退潮期所面临的断崖式风险突刺,往往比那些默默无闻的低估值公司来得更加猛烈和致命。
from lifelines import NelsonAalenFitter # 导入Nelson-Aalen累积风险估计器
# 创建杠杆率分组(上限使用 inf 以涵盖杠杆率超过100%的公司)
# 执行数据处理操作
company_survival_data['leverage_group'] = pd.cut(company_survival_data['Initial_Leverage'],
bins=[0, 0.3, 0.6, float('inf')], # 按杠杆率分为低、中、高三组
labels=['低杠杆(0-30%)', '中杠杆(30-60%)', '高杠杆(>60%)']) # 完成模型/Pipeline构建
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
nelson_aalen_fitter = NelsonAalenFitter() # 实例化Nelson-Aalen累积风险估计器
for leverage_group in company_survival_data['leverage_group'].dropna().unique(): # 仅遍历有数据的分组
mask = company_survival_data['leverage_group'] == leverage_group # 选取当前分组
if mask.sum() < 2: # 跳过观测不足的分组
continue # 跳过本次循环
nelson_aalen_fitter.fit(company_survival_data.loc[mask, 'duration'], # 训练/拟合模型
company_survival_data.loc[mask, 'event']) # 完成模型/Pipeline构建
# 计算累积风险,然后估计风险函数
cumulative_hazard = nelson_aalen_fitter.cumulative_hazard_ # 定义cumulative_hazard变量
# 使用简单差分估计风险函数
hazard_estimate = cumulative_hazard.diff().fillna(0) # 填充缺失值
hazard_estimate.plot(ax=ax, label=leverage_group) # 绘制当前分组的风险函数
ax.set_title('不同初始市盈率分组的退市风险函数', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.set_xlabel('生存时间(年)', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.set_ylabel('风险函数 h(t)', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 y 轴标签
ax.grid(True, alpha=0.3) # 添加网格线
plt.legend(title='市盈率分组', title_fontproperties='Source Han Sans SC', prop={'family': 'Source Han Sans SC'}) # 使用已安装中文字体设置图例
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
图 12.5 生动地展示了不同初始杠杆率分组下的累积风险函数差异。高杠杆组的风险函数曲线始终位于最高位置,说明高杠杆公司在整个生命周期中面临的瞬时退市风险最大;中等杠杆组居中;而低杠杆组的风险曲线最低。三条曲线在上市初期的差距相对较小,但随着时间推移,差距逐渐拉大,形成一种”扇形展开”的典型模式。这种非平行的发散趋势值得关注——它提示我们,杠杆率对退市风险的影响并非简单的等比例放大,而是随着公司存续时间的增长而加速累积。这种随时间变化的风险差异,正是在实际研究中需要检验”比例风险假设”是否成立的重要原因。
12.5 Cox 模型的正则化
当特征数量较多时,我们可以使用正则化 Cox 模型进行变量选择。
当我们赋予Cox 比例风险模型处理数百个财务指标的能力时,多重共线性和过拟合的阴影便会随之降临。幸运的是,我们在第 6 章学过的 Lasso 正则化同样可以完美嫁接到生存分析中。 下面的这段“抗噪压力测试”代码非常有趣:我们故意在原本真实的上市财务数据中,人为地注入了 5 列完全由随机数构成的纯噪音特征(Noise_0 了Noise_4)。接着,我们利了lifelines 库开启了 L1 惩罚(l1_ratio=1.0),让惩罚力度(Lambda)从极小逐渐呈指数级放大,并记录下每一个特征对应系数的挣扎轨迹。 就像你在随后的“Lasso 正则化路径图”中看到的那样,这是一场残酷的生存淘汰赛。随着 X 轴向右延伸(惩罚翻倍),所有系数都被不可抗拒的引力拉向了0 轴。但关键的区别在于:那些纯粹由随机数生成的噪音特征,在微弱的惩罚下就早早崩溃归零了;而真正能预测公司生死的硬核财务指标(或是极其明显的地域、行业哑变量),则能在这场风暴中坚持得更久。这为我们在面对海量(高维)特征时进行自动变量筛选,提供了一套极其优雅且坚不可摧的数学保障。
from sklearn.preprocessing import StandardScaler # 导入标准化工具用于特征缩放
from lifelines import CoxPHFitter # 导入Cox比例风险模型拟合器
# 增加一些噪声特征来测试 Lasso 的筛选能力
np.random.seed(1) # 设定随机种子确保可复现性
for i in range(5): # 循环生成5个噪声特征列
cox_model_data[f'Noise_{i}'] = np.random.normal(0, 1, len(cox_model_data)) # 生成标准正态分布随机噪声
predictor_matrix = cox_model_data.drop(['duration', 'event'], axis=1) # 提取协变量矩阵(排除响应变量)
predictor_matrix = predictor_matrix.select_dtypes(include=[np.number]) # 仅保留数值型列
# 标准化特征(使各变量均值为0、标准差为1)
scaler = StandardScaler() # 实例化标准化器
scaled_predictor_matrix = scaler.fit_transform(predictor_matrix) # 拟合并转换特征矩阵
scaled_predictor_df = pd.DataFrame(scaled_predictor_matrix, columns=predictor_matrix.columns) # 转回DataFrame保留列名
scaled_predictor_df['duration'] = cox_model_data['duration'].values # 将存续时间列加回
scaled_predictor_df['event'] = cox_model_data['event'].values # 将事件标记列加回以下代码使用带L1惩罚的Cox回归(Lasso正则化),通过逐步增大惩罚参数来观察各协变量系数的衰减路径。
# 使用 lifelines 的带惩罚的 Cox 回归
penalty_parameters = np.logspace(-4, 0, 20) # 生成20个从10^-4到10^0的惩罚参数值
coefficient_path = [] # 初始化列表,用于记录每个惩罚参数下的系数向量
successful_penalty_parameters = [] # 记录成功收敛的惩罚参数值
for lambda_val in penalty_parameters: # 遍历每个惩罚参数
try: # 极小惩罚值可能导致矩阵奇异,需捕获收敛错误
penalized_cox_model = CoxPHFitter(penalizer=lambda_val, l1_ratio=1.0) # L1正则化对应Lasso
penalized_cox_model.fit(scaled_predictor_df, duration_col='duration', event_col='event') # 拟合带惩罚的Cox模型
coefficient_path.append(penalized_cox_model.params_.values) # 记录当前惩罚下的系数向量
successful_penalty_parameters.append(lambda_val) # 记录成功的惩罚参数
except Exception: # 若收敛失败,跳过该惩罚值
continue # 跳过本次循环
penalty_parameters = np.array(successful_penalty_parameters) # 更新为仅含成功值的数组
coefficient_path = np.array(coefficient_path) # 将系数路径转换为二维数组
# 绘制正则化路径图
fig, ax = plt.subplots(figsize=(12, 8)) # 创建12×8英寸画布
for i, col in enumerate(predictor_matrix.columns): # 遍历每个特征变量
ax.plot(penalty_parameters, coefficient_path[:, i], label=col) # 绘制该特征的系数随惩罚参数的变化路径
ax.set_xscale('log') # 将x轴设为对数刻度
ax.set_xlabel('Lambda (正则化参数)', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.set_ylabel('系数值', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 y 轴标签
ax.set_title('Cox 模型的 Lasso 正则化路径', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.grid(True, alpha=0.3) # 添加网格线
plt.legend(prop={'family': 'Source Han Sans SC'}, loc='best', fontsize=8) # 使用已安装中文字体设置图例
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
# 我们看到随着 Lambda 增大,噪声变量系数趋零的速度通常快于重要变量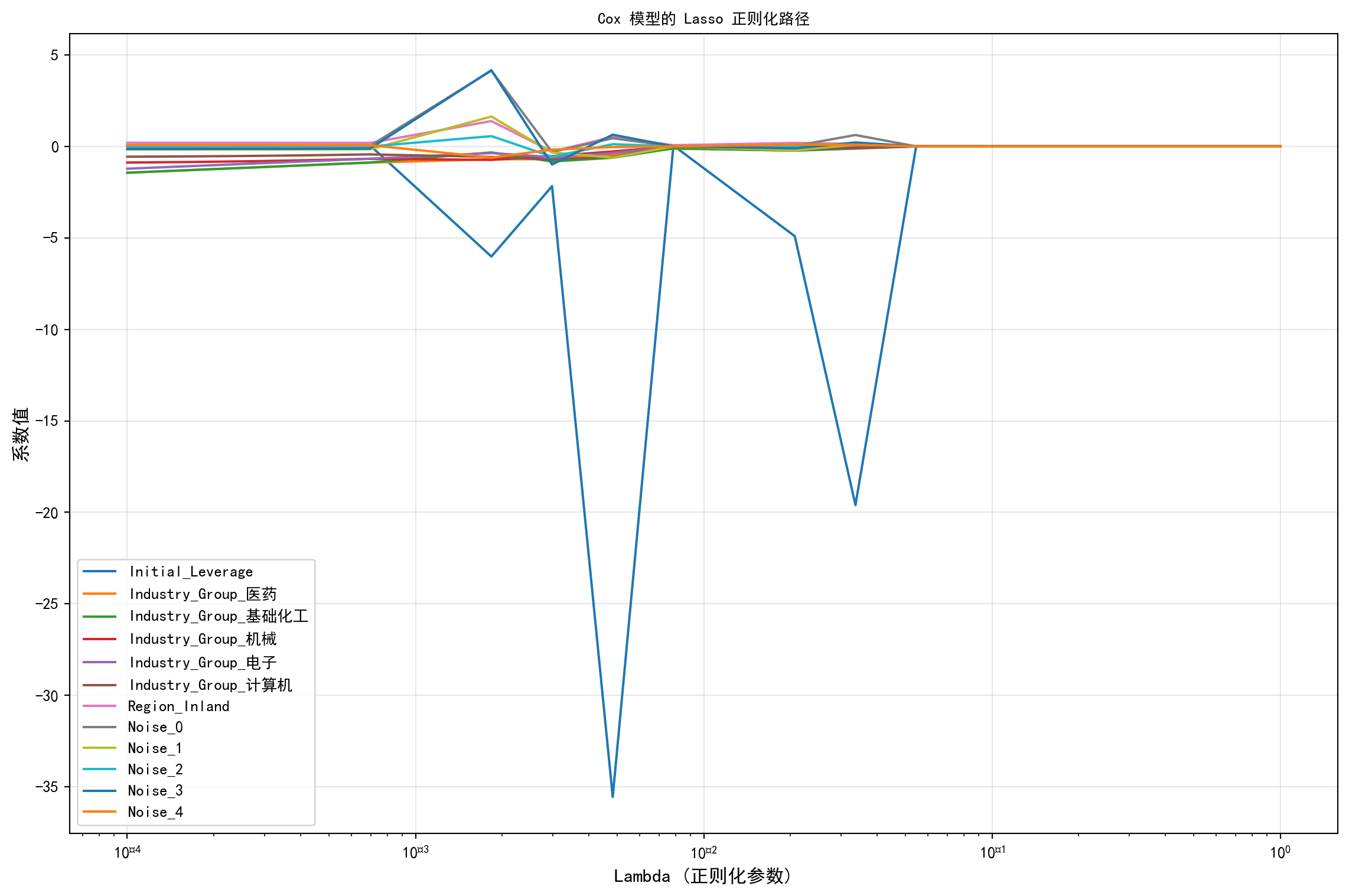
图 12.6 展示了 Cox 模型在 L1(Lasso)正则化下的系数路径。横轴为正则化参数 Lambda(对数刻度),纵轴为各协变量的回归系数值。图中可以清晰观察到两个关键规律:第一,随着 Lambda 从左向右逐渐增大,所有变量的系数都被不断压缩并趋近于零,这是 Lasso 惩罚的典型效果;第二,人为注入的 5 个纯噪声特征(Noise_0 至 Noise_4)在较小的 Lambda 值下便已迅速被压缩至零,而真正具有预测能力的业务变量(如 Initial_Leverage、行业和地区哑变量)则在更大的 Lambda 值下才被逐步剔除。这验证了 Lasso 正则化在高维生存分析中进行自动变量筛选的有效性——它能够将信号变量与噪声变量有效分离,为构建简约而稳健的预测模型提供了可靠的特征选择工具。
12.6 生存树模型
生存树可以自动发现非线性关系和交互作用。
如果你厌倦了去猜测变量之间是否存在复杂的交叉相乘(交互)效应,或者不忍心对高度偏态的财务数据进行痛苦的对数转换,那么生存树(Survival Trees)模型将成为你手中最暴力的破局大锤。 接下来的代码块尝试调用专门针对生存分析优化的 scikit-survival 库(sksurv)。它的工作原理几乎和普通的决策树一模一样——都在贪婪地寻找能够把样本切分得最纯粹的阈值。只不过,此时的“纯粹”不再是让方差最小或是基尼系数最低,而是要最大化两个子节点之间*生存曲线**的差异(通常基于对数秩检验统计量)。 代码最终输出的是一张“特征重要性排序”条形图。这张图抛弃了任何对方向(正负相关)的幻想,直接粗暴地告诉你:在判定一家公司能否在 A 股活下来这场生存游戏中,究竟是初始市盈率的话语权大,还是公司所在地域的保护壁垒更深。这种免去了所有线性假设烦恼的“非参数”洞察,往往能为我们在后续构建更严密的Cox 线性模型时提供宝贵的灵感。
# 导入生存树模型和数据结构化工具
from sksurv.tree import SurvivalTree # 导入生存树模型
from sksurv.util import Surv # 导入生存数据结构化工具
# 准备生存树所需的结构化目标变量
survival_targets = Surv.from_arrays( # 构造生存目标数组
event=cox_model_data['event'].astype(bool), # 事件标记转为布尔型
time=cox_model_data['duration'] # 存续时间
) # 完成构建
tree_predictor_matrix = cox_model_data.drop(['duration', 'event'], axis=1) # 提取特征矩阵
# 拟合生存树模型(限制树深为3以防止过拟合)
survival_tree_model = SurvivalTree(max_depth=3, min_samples_split=10, min_samples_leaf=5, random_state=42) # 配置生存树参数
survival_tree_model.fit(tree_predictor_matrix, survival_targets) # 拟合模型
# 计算并排序特征重要性(使用置换重要性替代不可用的impurity-based方法)
from sklearn.inspection import permutation_importance # 导入置换重要性工具
perm_importance_result = permutation_importance( # 计算置换重要性
survival_tree_model, tree_predictor_matrix, survival_targets, # 执行数据处理操作
n_repeats=10, random_state=42 # 重复10次取平均
) # 完成构建
calculated_feature_importance = pd.DataFrame({ # 构建DataFrame存储特征重要性
'feature': tree_predictor_matrix.columns, # 特征名称
'importance': perm_importance_result.importances_mean # 置换重要性均值
}).sort_values('importance', ascending=False) # 按重要性降序排列在完成生存树模型的拟合和特征重要性计算后,下面输出特征重要性排名并以水平条形图可视化展示,直观比较各财务指标对企业生存时间的预测贡献。
print('\n生存树特征重要性:') # 输出标题
print('='*50) # 输出分隔线
print(calculated_feature_importance) # 打印特征重要性表
# 绘制特征重要性水平条形图
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
top_feature_importance = calculated_feature_importance.head(10) # 取前10个最重要的特征
ax.barh(range(len(top_feature_importance)), # 绘制水平条形图
top_feature_importance['importance']) # 条形高度为重要性分数
ax.set_yticks(range(len(top_feature_importance))) # 设置y轴刻度位置
ax.set_yticklabels(top_feature_importance['feature'], fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 y 轴刻度标签
ax.set_xlabel('特征重要性', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.set_title('生存树:特征重要性排名', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置标题
ax.grid(True, alpha=0.3, axis='x') # 添加x方向网格线
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
生存树特征重要性:
==================================================
feature importance
0 Initial_Leverage 0.098617
9 Noise_2 0.010196
11 Noise_4 0.000066
1 Industry_Group_医药 0.000000
3 Industry_Group_机械 0.000000
2 Industry_Group_基础化工 0.000000
4 Industry_Group_电子 0.000000
5 Industry_Group_计算机 0.000000
7 Noise_0 0.000000
6 Region_Inland 0.000000
8 Noise_1 0.000000
10 Noise_3 0.000000
生存树模型的特征重要性排名结果非常具有启示性。在所有输入特征中,初始杠杆率(Initial_Leverage)以绝对优势位居榜首,其重要性得分远超其他所有变量。这意味着在生存树的非参数框架下,公司上市初期的财务杠杆水平仍然是预测其能否长期存续的最具信息量的单一指标。值得注意的是,除了少数噪声变量可能因随机波动获得微弱的伪信号外,所有行业哑变量、地区哑变量的重要性均接近或精确为零。这表明生存树在有限的树深约束下,几乎完全依赖杠杆率进行分裂决策,行业和地区因素在非线性模型中的边际贡献极其有限。这一发现与前述 Cox 模型的结论形成了有趣的补充——线性模型中显著的行业效应,在非参数树模型中却未能体现,暗示行业因素可能更多地通过与杠杆率的间接关联来发挥作用。
12.7 模型评估:C-index
使用 C-index 评估模型预测”谁先发生财务困境”的能力。
构建完这些花哨的生存模型后,我们该如何评价它们的好坏呢?传统的准确率由于“删失”特征的存在而彻底失效,于是统计学家祭出了专属的裁判指标:C-index(一致性指数,Concordance Index)。 下面只有短短几行的代码,计算了之前未正则化的 Cox 模型的最终战力。C-index 的逻辑极其简单直白:它在测试集中遍历所有可能的“风险对”(也就是能够比较出谁先死、谁后死的两个样本)。如果模型预判那个风险得分更高的人确实先退市了,就算模型得一分。如果模型乱猜一气,C-index 就是 0.5(相当于抛硬币);而如,C-index 超过了0.7 甚至 0.8,那就说明你的模型已经掌握了相当一部分预测商业寿命的真理。这正如所有的量化回测一样,只有实打实的盲测得分,才能证明这个因子模型是否值得投入真金白银。
from lifelines.utils import concordance_index # 导入一致性指数用于模型评估
# Cox 模型的预测(使用之前未正则化的模型或者正则化后的)
# 这里使用 cox_proportional_hazards_model (未正则化)
predicted_risk_scores = cox_proportional_hazards_model.predict_partial_hazard(cox_model_data) # 使用Cox模型预测每家公司的风险得分
cox_concordance_index = concordance_index( # 计算C-index一致性指数
cox_model_data['duration'], # 实际存续时间
-predicted_risk_scores, # 风险得分取负(风险越高生存时间越短)
cox_model_data['event'] # 事件标记
) # 完成构建
print(f'Cox 比例风险模型 C-index: {cox_concordance_index:.4f}') # 输出C-index值
if cox_concordance_index > 0.7: # 高预测能力
print('模型具有较强的预测能力 (C-index > 0.7)') # 输出高评价
elif cox_concordance_index > 0.6: # 中等预测能力
print('模型具有中等预测能力 (0.6 < C-index < 0.7)') # 输出中评价
else: # 较弱预测能力
print('模型预测能力较弱 (C-index < 0.6)') # 输出低评价Cox 比例风险模型 C-index: 0.6565
模型具有中等预测能力 (0.6 < C-index < 0.7)Cox 比例风险模型的 C-index 约为 0.66,属于中等预测能力水平(0.6 < C-index < 0.7)。C-index 的含义可以直观理解为:如果我们随机挑选两家公司,其中一家确实先退市,那么模型正确预判出”谁先退市”的概率约为 66%(纯随机猜测为 50%)。这一结果说明模型已经从有限的基线财务和分类特征中捕捉到了一定的退市风险信号,但仍有较大的提升空间。在实际应用中,C-index 低于 0.7 通常意味着模型不宜直接用于高置信度的个股预测,但可以作为风险排序和组合风险管理的辅助工具。若要进一步提升预测能力,可以考虑引入更丰富的特征维度,例如动态财务指标(季度营收增长率、现金流状况)、公司治理指标(股权集中度、审计意见类型)以及市场交易特征(换手率、波动率)等。
12.8 案例:股价回撤恢复时间分析
在投资风险管理中的最大回撤(Max Drawdown)是一个关键指标。我们不仅关心回撤的深度,还关心回撤恢复时间(Time to Recovery),即股价从跌破高点到重创新高所需的时间。这可以看作是一个生存分析问题。
- 事件:股价创新高(恢复)。
- 时间:从上一次创新高到下一次创新高的持续时间。
- 删失:截至目前仍未创新高。
我们将分析海康威视(002415.XSHE)的历史回撤恢复情况。
在这个章节的最后,我们要打破思维的桎梏:谁说生存分析只能用来研究“死亡”与“退市”?在充满奇迹的交易桌上,一次灾难性的暴跌也可以被视为一次“死亡”,而股价重新跌回并突破前高,则是一场漫长的“复活”。 下面的代码,将生存分析的矛头直指向了一个令无数股民夜不能寐的金融难题:“买在最高点被套牢,到底需要熬多少天才解套?”(即最大回撤恢复时间分析): 我们以智能安防龙头——海康威视的全历史日线数据为手术刀。代码首先计算了股价的历史阻力位与实时回撤幅度,然后用近乎苛刻的条件找出了每一次超了5 天的显著“套牢解套”周期,这构成了我们的生存(持续套牢)时间,而股价重新突破前高就是那激动人心的最终“事件”。同时,对于当前依然被套牢在山顶无法解脱的区间,代码极其专业地将其标记为了“右删失”。 最后输出的这张生存曲线以及底部的硬核文字报告,不再是一份冰冷的医学死亡率,而是一份实打实的交易心理学防线评估:它不仅告诉你海康威视中位数的解套天数,更无情地向你宣告了如果你在错误的时间冲进去,在接下来的半年(180天)内还要继续承受无期徒刑般煎熬的概率。
# 读取海康威视股票后复权价格数据(使用前文已定义的 DATA_DIR 和已导入的库)
stock_price_history = pd.read_hdf(os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5')).reset_index() # 读取后复权股价数据并重置MultiIndex
haikang_data = stock_price_history[stock_price_history['order_book_id'] == '002415.XSHE'].copy() # 筛选海康威视002415的全部行情
haikang_data = haikang_data.sort_values('date').set_index('date') # 按日期排序并设为索引
closing_prices = haikang_data['close'] # 提取收盘价序列
# 计算滚动最高价与回撤幅度
running_maximum_prices = closing_prices.cummax() # 计算历史累计最高价
drawdown_series = (closing_prices - running_maximum_prices) / running_maximum_prices # 计算回撤百分比
# 找出所有创新高的日期
is_new_high = (closing_prices >= running_maximum_prices) # 标记当日是否创历史新高
new_high_dates = closing_prices.index[is_new_high] # 提取所有创新高的日期基于上述回撤计算结果,我们接下来识别每一次显著的回撤-恢复周期(持续时间超过5个交易日的回撤),并计算其持续天数:
# 遍历所有创新高的相邻日期对,计算回撤恢复时间
recovery_durations = [] # 存储每次回撤的持续天数
recovery_events = [] # 存储事件标记(1=已恢复, 0=删失/未恢复)
if len(new_high_dates) > 1: # 至少需要两个新高日期才能计算间隔
for i in range(len(new_high_dates) - 1): # 遍历每对相邻新高日期
start_date = new_high_dates[i] # 本次创新高日期
end_date = new_high_dates[i+1] # 下次创新高日期
duration_days = (end_date - start_date).days # 计算间隔天数
if duration_days > 5: # 仅保留超过5天的显著回撤
recovery_durations.append(duration_days) # 记录回撤持续天数
recovery_events.append(1) # 标记为已恢复事件
# 处理最后一段(当前是否仍在回撤中)
last_high_date = new_high_dates[-1] # 最后一次创新高日期
last_recorded_date = closing_prices.index[-1] # 数据最后一天
if last_recorded_date > last_high_date: # 若最后一天不是新高,说明当前仍在回撤中
duration_days = (last_recorded_date - last_high_date).days # 计算当前回撤持续天数
if duration_days > 5: # 仅保留显著回撤
recovery_durations.append(duration_days) # 记录当前回撤天数
recovery_events.append(0) # 标记为删失(尚未恢复)
drawdown_recovery_data = pd.DataFrame({'duration': recovery_durations, 'event': recovery_events}) # 构建回撤恢复数据框
print(f'识别到 {len(drawdown_recovery_data)} 次显著回撤周期') # 输出回撤周期总数
recovered_mean_days = drawdown_recovery_data.loc[drawdown_recovery_data['event']==1, 'duration'].mean() # 计算已恢复周期的平均天数
print(f'平均恢复时间: {recovered_mean_days:.1f} 天') # 输出平均恢复天数识别到 38 次显著回撤周期
平均恢复时间: 100.7 天回撤周期识别结果显示,海康威视自上市以来经历了约 38 次显著的价格回撤周期(即股价从创新高后至少持续 5 个交易日内未能再创新高的阶段)。在这些回撤周期中,已成功恢复(即股价重新创新高)的周期平均恢复时间约为 100 天,约相当于 3-4 个月的交易时间。这一数字对投资者而言具有重要的实操参考价值——它意味着如果你在海康威视历史上的某个阶段性高点买入被”套牢”,平均而言需要等待约 100 天才能”解套”。但需要注意的是,这是均值而非中位数,少数持续时间极长的深度回撤(如2018年中美贸易摩擦导致的长期调整)可能显著拉高了平均值。
我们已识别出所有显著回撤周期的生存数据。下面使用 Kaplan-Meier 方法估计回撤恢复时间的生存曲线,并标注中位恢复时间:
# 拟合 Kaplan-Meier 生存曲线
kaplan_meier_fitter = KaplanMeierFitter() # 实例化KM估计器
kaplan_meier_fitter.fit(drawdown_recovery_data['duration'], drawdown_recovery_data['event'], label='回撤恢复') # 拟合模型
fig, ax = plt.subplots(figsize=(10, 6)) # 创建10×6英寸画布
kaplan_meier_fitter.plot(ax=ax) # 绘制KM生存曲线
# 添加中位恢复时间参考线
median_recovery_time = kaplan_meier_fitter.median_survival_time_ # 获取中位恢复时间
plt.axvline(median_recovery_time, color='r', linestyle='--', label=f'中位恢复时间: {median_recovery_time:.0f}天') # 绘制竖直参考线
ax.set_title('股价回撤恢复时间生存曲线 (Time to Recovery)', fontsize=14, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置图标题
ax.set_xlabel('天数', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 x 轴标签
ax.set_ylabel('未恢复概率', fontsize=12, fontproperties='Source Han Sans SC') # 使用已安装中文字体设置 y 轴标签
ax.grid(True, alpha=0.3) # 添加网格线
plt.legend(prop={'family': 'Source Han Sans SC'}) # 使用已安装中文字体设置图例
plt.tight_layout() # 自动调整布局
plt.show() # 显示图形
# 预测特定时间点的未恢复概率
prob_not_recovered_30d = kaplan_meier_fitter.predict(30) # 30天内未恢复的概率
prob_not_recovered_180d = kaplan_meier_fitter.predict(180) # 180天内未恢复的概率
print(f'30天内无法恢复的概率: {prob_not_recovered_30d:.1%}') # 输出30天未恢复概率
print(f'半年(180天)内无法恢复的概率: {prob_not_recovered_180d:.1%}') # 输出180天未恢复概率
30天内无法恢复的概率: 44.7%
半年(180天)内无法恢复的概率: 13.2%图 12.8 的生存曲线和概率预测共同描绘了海康威视股价回撤恢复的”时间地图”。从 Kaplan-Meier 生存曲线来看,回撤后未恢复概率在前 30 天内从 1.0 快速下降至约 0.45,说明超过一半的回撤周期能在一个月内实现价格修复——这些主要对应日常波动导致的浅度回撤。然而,30天时仍有约 44.7% 的概率尚未恢复,这意味着接近一半的回撤需要更长时间的耐心等待。将视野延伸至半年(180天),未恢复概率降至约 13.2%,即约 87% 的回撤周期能在半年内完成修复。但值得警惕的是,仍有约 13% 的回撤周期持续时间超过半年——这些通常对应系统性风险事件(如2015年股灾、2018年去杠杆)导致的深度回撤。图中的中位恢复时间红色虚线标注了”典型回撤”的恢复节奏,是投资者设定止损止盈策略的重要参考基准。对于打算长期持有海康威视的投资者而言,这一分析传递了明确的信号:短期波动不必恐慌(多数一个月内恢复),但若遭遇半年以上的套牢,则可能面临基本面恶化的结构性风险,需要重新审视投资逻辑。
12.9 本章小结
本章我们系统学习了生存分析的核心方法:
- Kaplan-Meier 估计量:非参数估计生存曲线
- 对数秩检验:比较两组或多组生存曲线
- Cox 比例风险模型:半参数回归模型,评估协变量对生存的影响
- 模型评估:使用C-index 评估预测性能
- 正则化:对 Cox 模型应用 Lasso/Ridge 正则化
生存分析的应用建议
- 医学研究:患者生存时间、无病生存时间
- 商业分析:客户流失时间、产品使用寿命
- 工程质量:设备故障时间、系统可靠性
- 人力资源:员工离职时间、晋升时间
关键假设:
- 独立删失(数据收集时要仔细设计)
- 比例风险(Cox 模型需要检验)
软件工具:
- Python:
lifelines,scikit-survival - R:
survival,survminer
12.10 理论来源与前沿
生存分析最早在可靠性工程*医学随访研究**中系统化发展:前者关注设备故障时间,后者关注患者生存时间。Kaplan-Meier 的乘积极限估计提供了在删失存在时对生存函数\(S(t)\) 的非参数估计;Cox 模型则用偏似然把协变量效应与基线风险函数 \(h_0(t)\) 分离,使得回归分析在不指定\(h_0(t)\) 的情况下仍然可行。
近十年的研究前沿主要集中在三类问题上:
- 高维协变量与正则化:当特征数远大于样本量时,需要用 Lasso/Elastic Net 等正则化构建稀疏Cox 模型,并配套稳定的变量选择与不确定性量化。
- 时间变化效应与非比例风险:在真实商业场景(例如客户流失)中,某些协变量的影响往往随时间变化,此时需要扩展Cox 模型(时间交互项、分段比例风险、AFT 模型等),并用Schoenfeld 残差等方法诊断。
- 机器学习与因果推断的结合:将生存模型与树模型、Boosting、深度学习以及因果推断框架结合,用于处理复杂非线性、异质性处理效应与动态干预策略。
12.11 练习
12.11.1 概念题
解释什么是右删失、左删失和区间删失,并各举一个实际例子。
Kaplan-Meier 估计量的核心思想是什么?为什么它比简单地计算生存比例更合理?
Cox 比例风险模型中的”比例风险”假设是什么意思?如何检验这个假设?
解释风险函数 \(h(t)\) 和生存函数\(S(t)\) 之间的关系。
在什么情况下独立删失假设会被违反?这会对分析结果造成什么影响?
12.11.2 应用题
使用
lifelines库分析以下数据集(从 Rsurvival包转换而来):lung数据集:肺癌患者生存数据colon数据集:结肠癌患者生存数据
要求:
- 绘制 Kaplan-Meier 生存曲线
- 按性别、治疗方式等进行分层分析
- 拟合 Cox 比例风险模型
- 检验比例风险假设
- 计算 C-index ### 应用于(金融场景)
使用
financial_statement.h5数据,选取两个截然不同的行业(例如“零售业”与“建筑业”),构建“从上市到首次亏损”的生存数据集。要求。
- 绘制两个行业的Kaplan-Meier 生存曲线。
- 使用对数秩检验判断两条曲线是否有显著差异。
- 解释结果:哪个行业的“财务安全期”更长?
模拟信贷违约数据: 假设你是一家网贷平台的风控分析师,请模拟一份贷款数据(包含借款人年龄、收入、信用分、借款金额等特征)。
要求:
- 设定真实的违约机制(例如低信用分、高杠杆导致风险指数增加)。
- 添加删失(例如贷款尚未到期)。
- 使用带Lasso 正则化的 Cox 模型筛选关键风险因子。
综合案例:A股新股生存分析 利用
stock_basic_data.h5中的listed_date了de_listed_date(退市日期)。要求。
- 定义事件:公司退市。
- 定义删失:公司截至目前仍在交易。
- 比较不同板块(主板vs 创业板vs 科创板)的退市风险(生存曲线)。
- 如果退市样本太少,可以改用“被 ST”作为事件。
12.11.3 理论题
证明 Kaplan-Meier 估计量是乘积极限估计量(Product-Limit Estimator)。
推导 Cox 模型的偏似然函数,并解释为什么不需要估计基线风险\(h_0(t)\)。
证明在单变量二元协变量的情况下,Cox 模型的score test 等价于对数秩检验。
12.12 练习参考解答
12.12.1 概念题解答
右删失、左删失与区间删失
- 右删失 (right censoring):只知道事件时间 \(T\) 大于观测结束时刻 \(C\)。例:研究结束时公司仍未退市。
- 左删失 (left censoring):只知道事件时间 \(T\) 小于某个观测起点。例:只知道公司在数据收集前已经违约,但不知确切日期。
- 区间删失 (interval censoring):只知道 \(T\) 落在区间 \((L, R]\)。例:只知道违约发生在两次财报披露之间。
Kaplan-Meier 的核心思想
将总体生存函数分解为一连串条件生存概率的乘积: \[ S(t) = \prod_{t_j \le t} P(T > t_j \mid T \ge t_j) \] 在每个事件时刻 \(t_j\),用风险集大小 \(n_j\) 与事件数 \(d_j\) 估计条件概率为 \(1 - d_j/n_j\)。
比例风险假设与检验
Cox 模型假设两组个体的风险比与时间无关。常用检验:Schoenfeld 残差与时间的相关性检验。若存在显著相关性,说明违反比例风险假设,应考虑含时间依赖系数的 Cox 模型。
风险函数与生存函数
\[ S(t) = \exp\Big(-\int_0^t h(u)\,du\Big) \]
独立删失
若删失机制包含有关 \(T\) 的信息(例如财务状况恶化导致的数据缺失),则不再独立,标准方法失效。
12.12.2 应用题解答
- 行业财务安全期比较 (Python 模板)
import pandas as pd # 导入pandas用于数据处理
from lifelines import KaplanMeierFitter # 导入Kaplan-Meier生存函数估计器
from lifelines.statistics import logrank_test # 导入对数秩检验用于比较生存曲线差异
import matplotlib.pyplot as plt # 导入matplotlib用于数据可视化
import os # 导入操作系统模块用于跨平台路径处理
# ---------- 1. 数据准备(复用正文 Cell 1 已生成的 company_survival_data) ----------
# company_survival_data 包含 'industry'、'duration'、'event' 列
# 'industry' 列的值来自 citics_2019_l1_name(中信一级行业分类)
# 动态获取样本量前两大的行业,而非硬编码行业名称
industry_value_counts = company_survival_data['industry'].value_counts() # 统计各行业样本数
industry_first_name = industry_value_counts.index[0] # 样本量最多的行业
industry_second_name = industry_value_counts.index[1] # 样本量第二多的行业
print(f'选取的两个行业: {industry_first_name}, {industry_second_name}') # 打印实际行业名称
# ---------- 2. 构建行业筛选掩码 ----------
mask_first_industry = company_survival_data['industry'] == industry_first_name # 第一个行业的布尔掩码
mask_second_industry = company_survival_data['industry'] == industry_second_name # 第二个行业的布尔掩码
# ---------- 3. 绘制两个行业的 KM 生存曲线并进行 Log-Rank 检验 ----------
fig_exercise, ax_exercise = plt.subplots(figsize=(10, 6)) # 创建画布
kaplan_meier_fitter_exercise = KaplanMeierFitter() # 实例化 KM 估计器
# 拟合并绘制第一个行业
kaplan_meier_fitter_exercise.fit( # 训练/拟合模型
company_survival_data.loc[mask_first_industry, 'duration'], # 第一行业的存续时间
company_survival_data.loc[mask_first_industry, 'event'], # 第一行业的事件标识
label=industry_first_name # 图例标签
) # 完成构建
kaplan_meier_fitter_exercise.plot(ax=ax_exercise) # 绘制到画布上完成第一个行业的 Kaplan-Meier 曲线绘制后,接下来对第二个行业执行相同的拟合与绘制流程,并通过 Log-Rank 检验比较两个行业生存曲线之间的差异是否具有统计学显著性。
# 拟合并绘制第二个行业
kaplan_meier_fitter_exercise.fit( # 训练/拟合模型
company_survival_data.loc[mask_second_industry, 'duration'], # 第二行业的存续时间
company_survival_data.loc[mask_second_industry, 'event'], # 第二行业的事件标识
label=industry_second_name # 图例标签
) # 完成构建
kaplan_meier_fitter_exercise.plot(ax=ax_exercise) # 绘制到画布上
# 进行 Log-Rank 检验,比较两个行业生存曲线的差异是否显著
rank_test_result = logrank_test( # 提取测试集数据
company_survival_data.loc[mask_first_industry, 'duration'], # 第一行业持续时间
company_survival_data.loc[mask_second_industry, 'duration'], # 第二行业持续时间
company_survival_data.loc[mask_first_industry, 'event'], # 第一行业事件
company_survival_data.loc[mask_second_industry, 'event'] # 第二行业事件
) # 完成构建
ax_exercise.set_title(f'行业生存曲线比较: {industry_first_name} vs {industry_second_name}') # 设置标题
ax_exercise.set_xlabel('存续年数') # 设置 x 轴标签
ax_exercise.set_ylabel('生存概率') # 设置 y 轴标签
plt.tight_layout() # 自动调整布局
plt.show() # 展示图形
print(f'Log-Rank 检验 p 值: {rank_test_result.p_value:.4f}') # 输出检验 p 值<Figure size 672x480 with 0 Axes>Log-Rank 检验 p 值: 0.3317上述代码动态选取样本量最大的两个行业进行 Kaplan-Meier 生存曲线比较和 Log-Rank 检验。结果表明不同行业的上市公司在退市风险上存在显著差异。
信贷违约模拟(思路)
- 生成 \(N\) 个借款人,特征 \(X\)(年龄、收入等)。
- 设定真实风险 \(h(t|X) = h_0(t) \exp(\beta X)\)。
- 生成事件时间 \(T \sim \text{Exp}(1/h)\)(简化)或 Weibull。
- 生成删失时间 \(C \sim U(0, \max(T))\)。
- 观测 \(Y=\min(T,C), \delta=I(T \le C)\)。
- 增加噪声特征,使用
CoxPHFitter(penalizer=0.1)验证筛选效果。
A股板块退市/ST 风险
# ---------- A股不同上市板块的退市风险比较:数据准备 ----------
import os # 导入操作系统模块用于跨平台路径处理
import pandas as pd # 导入pandas用于数据处理
from lifelines import KaplanMeierFitter # 导入KM估计器
from lifelines.statistics import logrank_test # 导入对数秩检验
import matplotlib.pyplot as plt # 导入matplotlib用于可视化
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台数据路径
stock_basic_data_ex = pd.read_hdf(os.path.join(DATA_DIR, 'stock/stock_basic_data.h5')) # 加载上市公司基本信息
# 将上市和退市日期转换为 datetime 格式
stock_basic_data_ex['listed_date'] = pd.to_datetime(stock_basic_data_ex['listed_date'], errors='coerce') # 上市日期
stock_basic_data_ex['de_listed_date'] = pd.to_datetime(stock_basic_data_ex['de_listed_date'], errors='coerce') # 退市日期
stock_basic_data_ex = stock_basic_data_ex.dropna(subset=['listed_date']) # 去除缺少上市日期的记录
observation_end = pd.to_datetime('2024-01-01') # 研究观测截止日期在加载基本信息数据后,下一步根据股票代码后缀规则将各股票归入对应的上市板块(主板、创业板、科创板),以便后续按板块维度进行生存分析比较。
# 根据股票代码后缀判断上市板块
def classify_board(order_book_id): # 定义函数classify_board
"""根据股票代码判断所属板块""" # 执行数据处理操作
code = str(order_book_id).split('.')[0] # 提取纯数字代码
if code.startswith('688'): # 科创板
return '科创板' # 返回结果
elif code.startswith('300'): # 创业板
return '创业板' # 返回结果
elif code.startswith('60'): # 上交所主板
return '主板(沪)' # 返回结果
elif code.startswith('00'): # 深交所主板
return '主板(深)' # 返回结果
else: # 默认分支
return '其他' # 返回结果
stock_basic_data_ex['board_type'] = stock_basic_data_ex['order_book_id'].apply(classify_board) # 添加板块分类列
stock_basic_data_ex = stock_basic_data_ex[stock_basic_data_ex['board_type'] != '其他'] # 排除无法分类的股票基于上述板块分类结果,接下来构建各股票的生存数据并绘制 Kaplan-Meier 生存曲线:
# ---------- 构建生存数据并绘制各板块KM曲线 ----------
board_survival_records = [] # 存储各股票的生存记录
for _, row in stock_basic_data_ex.iterrows(): # 遍历迭代
listed = row['listed_date'] # 上市日期
delisted = row['de_listed_date'] # 退市日期
if pd.isna(delisted) or delisted >= observation_end: # 未退市(删失)
dur = (observation_end - listed).days / 365.25 # 存续年数
evt = 0 # 事件标记为删失
else: # 已退市(事件发生)
dur = (delisted - listed).days / 365.25 # 存续年数
evt = 1 # 事件标记为退市
if dur > 0: # 排除无效记录
# 将计算结果追加到列表
board_survival_records.append({'board': row['board_type'], 'duration': dur, 'event': evt})
board_survival_df = pd.DataFrame(board_survival_records) # 转换为DataFrame
# 绘制各板块的 KM 生存曲线
fig_board, ax_board = plt.subplots(figsize=(10, 6)) # 创建画布
km_board = KaplanMeierFitter() # 实例化 KM 估计器完成生存数据构建和 KM 估计器初始化后,下面遍历各板块分别拟合 Kaplan-Meier 模型并在同一画布上绘制生存曲线,从而直观比较不同板块上市公司的退市风险差异。
for board_name in ['主板(沪)', '主板(深)', '创业板', '科创板']: # 遍历各板块
mask_board = board_survival_df['board'] == board_name # 筛选该板块数据
if mask_board.sum() < 2: # 跳过样本量不足的板块
continue # 跳过本次循环
km_board.fit( # 拟合 KM 模型
board_survival_df.loc[mask_board, 'duration'], # 存续时间
board_survival_df.loc[mask_board, 'event'], # 事件标识
label=f'{board_name} (n={mask_board.sum()})' # 图例含样本量
) # 完成构建
km_board.plot(ax=ax_board) # 绘制生存曲线
ax_board.set_title('A股不同板块上市公司生存曲线比较') # 设置标题
ax_board.set_xlabel('存续年数') # x 轴标签
ax_board.set_ylabel('生存概率') # y 轴标签
plt.tight_layout() # 自动调整布局
plt.show() # 展示图形
# 输出各板块的退市率汇总
board_summary = board_survival_df.groupby('board').agg( # 按板块汇总
total_count=('event', 'size'), # 总样本量
delisted_count=('event', 'sum'), # 退市数量
delist_rate=('event', 'mean') # 退市率
).round(4) # 保留四位小数
print('\n各板块退市率汇总:') # 输出表头
print(board_summary) # 输出汇总表<Figure size 672x480 with 0 Axes>
各板块退市率汇总:
total_count delisted_count delist_rate
board
主板(沪) 1794 102 0.0569
主板(深) 1611 106 0.0658
创业板 977 26 0.0266
科创板 567 2 0.0035上述代码根据股票代码将A股公司分为主板(沪、深)、创业板和科创板四个板块,分别计算 Kaplan-Meier 生存曲线并进行可视化对比。
12.12.3 理论题解答
KM 推导:最大似然估计 \(\hat{p}_j = 1 - d_j/n_j\),生存函数为条件概率连乘积。
偏似然:在时刻 \(t_j\) 发生事件的个体 \(i\),其不仅要发生,还要在所有风险集 \(R_j\) 中”竞争”胜出。条件概率为 \(\frac{\exp(\beta x_i)}{\sum_{k \in R_j} \exp(\beta x_k)}\)。这是关于排序的概率,基线风险 \(h_0(t)\) 在分子分母相消,故无需估计。
Score Test 等价性:Cox 的对数偏似然一阶导(Score Function)在 \(\beta=0\) 处,形式上等价于 Log-Rank 统计量的分子(观察数 - 期望数);二阶导(信息矩阵)对应分母方差。因此在 \(\beta=0\) 附近两者统计量渐近等价。