import numpy as np # 数值计算库,提供高效的数组操作
import pandas as pd # 数据分析库,提供DataFrame表格结构
import matplotlib.pyplot as plt # 绘图库,用于生成统计图表
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 设置中文字体,优先使用思源宋体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题
from sklearn.linear_model import LinearRegression # scikit-learn中的普通最小二乘线性回归模型
from sklearn.metrics import mean_squared_error, r2_score # 模型评估指标:均方误差和R²决定系数
from itertools import combinations # Python内置的组合数学工具,用于穷举所有变量子集
import os # 操作系统接口,用于跨平台路径判断(Windows vs Linux)
import warnings # 警告控制模块
warnings.filterwarnings('ignore') # 忽略运行时的非关键警告信息,保持输出整洁7 线性模型选择与正则化 (Linear Model Selection and Regularization)
7.1 引言 (Introduction)
在回归设置中,标准线性模型
\[ Y = \beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p + \epsilon \tag{7.1}\]
通常用于描述响应\(Y\)与一组变量\(X_1, X_2, \ldots, X_p\)之间的关系。我们在第3章中看到,通常使用最小二乘法拟合这个模型。
然而,为什么我们可能想要使用另一种拟合程序来代替最小二乘?正如我们将看到的,替代拟合程序可以产生更好的预测准确性和模型可解释性:
预测准确性:只要响应与预测变量之间的真实关系近似线性,最小二乘估计将具有低偏差。但如果\(n \approx p\)或\(p > n\),最小二乘估计可能具有很高的方差,导致过拟合。通过约束或收缩估计的系数,我们通常可以以可忽略的偏差增加为代价显著减少方差。
模型可解释性:多元回归模型中的许多或所有变量实际上可能与响应无关。通过删除这些变量(即将相应的系数估计设置为零),我们可以获得更容易解释的模型。最小二乘法不太可能产生恰好为零的系数估计。
在本章中,我们讨论三类重要的方法来改进简单线性模型:
- 子集选择(Subset Selection):识别与响应相关的预测变量子集
- 收缩方法(Shrinkage):拟合包含所有\(p\)个预测变量的模型,但将系数估计收缩向零
- 降维方法(Dimension Reduction):将预测变量投影到\(M\)维子空间
案例背景: A股上市公司净资产收益率(ROE)预测
在本章中,我们将处理一个经典的金融分析问题:财务指标选股。我们希望通过分析公司的财务报表,找出决定公司盈利能力(以净资产收益率 ROE 为代表)的关键驱动因素。
我们将使用中国A股上市公司的真实财务数据(2022年年报)。数据集包含数百个财务指标,我们的目标是从中筛选出最能预测ROE的变量子集,并构建预测模型。
变量说明:
- ROE (Response): 净资产收益率 (归母净利润 / 归母所有者权益)
- Predictors: 各种财务比率和报表项目,例如:
- Asset Turnover: 总资产周转率 (营业收入 / 总资产)
- Profit Margin: 销售净利率 (净利润 / 营业收入)
- Leverage: 杠杆率 (总资产 / 净资产)
- Liquidity: 流动性比率 (流动资产 / 流动负债)
- 以及其他数十个详细的财务科目(以总资产为基准标准化)
这是一个典型的高维回归问题,适合演示模型选择和正则化方法。
7.2 子集选择 (Subset Selection)
子集选择涉及识别我们相信与响应相关的\(p\)个预测变量的子集。然后我们使用最小二乘法在减少的变量集上拟合模型。
7.2.1 最优子集选择 (Best Subset Selection)
最优子集选择为每个可能的预测变量组合拟合一个单独的最小二乘回归。
算法 6.1: 最优子集选择
- 令\(M_0\)表示零模型(null model),它不包含任何预测变量。
- 对于\(k = 1, 2, \ldots, p\):
- 拟合所有包含恰好\(k\)个预测变量的\(\binom{p}{k}\)个模型。
- 从这些模型中选择最好的,称为\(M_k\)。这里的”最好”定义为具有最小的RSS或等价地最大的\(R^2\)。
- 使用验证集上的预测误差、\(C_p\)(AIC)、BIC或调整\(R^2\)从\(M_0, \ldots, M_p\)中选择单个最佳模型。或者使用交叉验证方法。
Tip: 为什么不能只使用\(R^2\)选择模型?
在选择包含不同数量变量的模型时,我们不能只使用训练\(R^2\),因为:
\(R^2\)的单调性:当我们将更多变量添加到模型时,\(R^2\)总是增加(或至少不减少),即使这些变量与响应无关。
训练误差与测试误差的差异:训练误差往往远小于测试误差。低训练\(R^2\)不保证低测试误差。
过拟合风险:包含所有变量的模型可能在训练数据上表现很好,但在新数据上表现不佳。
因此,我们需要使用\(C_p\)、BIC、调整\(R^2\)或交叉验证等方法,这些方法考虑了模型复杂度对预测性能的影响。
案例应用: 杜邦分析视角下的特征选择
为了在一个简化的微观阶段直观演绎“最优子集选择”的暴力美学,以下 Python 量化实战代码利用基于著名杜邦分析体系(DuPont Analysis)衍生的六大经典财务核心特征(资产周转率、销售净利率、权益乘数、资产负债率、以对数资产代表的规模因子、现金流比率),来尝试拟合并预测 A 股上市公司的年度基本面盈利能力(净资产收益率 ROE)。代码使用 itertools.combinations 引擎,极为生猛地遍历了从 1 个变量单打独斗,一直到 6 个变量全员上阵的所有可能的分组组合(总计 \(2^6 - 1 = 63\) 种不同维度的回归方程)。在为每一种组合严格计算其底层 RSS 和 \(R^2\) 之后,代码毫不含糊地从每个指定变量个数的类别集群中,分别拎出了各自领域内拟合度最高的那个“冠军模型”。当你检视代码输出的图表时,你能清晰地看到代表残差的红色 RSS 随着放入模型的“武器”增多而机械式地单调下降,代表拟合解释力的蓝色 \(R^2\) 图形表现出与之相对称的三阶台阶式上升;然而随着变量在 4 个之后继续累加,这种边际改善效应开始大幅衰退并几乎趋于平缓。
加载 A 股上市公司财务数据,并按照杜邦分析体系构建特征变量。
# ====== 1. 加载A股上市公司财务报表数据 ======
# 根据操作系统自动选择本地数据路径(Windows vs Linux)
LOCAL_DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台路径
financial_data_path = os.path.join(LOCAL_DATA_DIR, 'stock/financial_statement.h5') # 拼接完整文件路径
financial_data = pd.read_hdf(financial_data_path) # 读取HDF5格式的财务报表数据
# ====== 2. 数据清洗与预处理 ======
# 只保留2022年第四季度(即年报)的数据,确保全年财务指标完整
financial_data = financial_data[financial_data['quarter'] == '2022q4'].copy() # 筛选年报
# ROE是衡量公司盈利能力的核心指标,也是杜邦分析的最终目标变量
financial_data['total_equity'] = financial_data['equity_parent_company'] # 提取归母权益作为ROE分母
# 过滤掉净资产低于1亿元的公司(这些公司可能面临退市风险,ROE不具代表性)
financial_data = financial_data[financial_data['total_equity'] > 1e8] # 排除微型公司
financial_data['ROE'] = financial_data['net_profit_parent_company'] / financial_data['total_equity'] # 计算ROE
# 过滤掉极端ROE值(大于100%或小于-100%的异常样本,避免异常值扭曲回归结果)
financial_data = financial_data[(financial_data['ROE'] > -1) & (financial_data['ROE'] < 1)] # 剔除异常值
# ====== 3. 构建杜邦分析体系的6大特征(自变量) ======
# 特征1: 资产周转率 = 营业收入 / 总资产(衡量公司运用资产创造收入的效率)
financial_data['Asset_Turnover'] = financial_data['operating_revenue'] / financial_data['total_assets'] # DuPont因子1
# 特征2: 销售净利率 = 归母净利润 / 营业收入(衡量每一元收入中有多少转化为利润)
financial_data['Net_Margin'] = financial_data['net_profit_parent_company'] / financial_data['operating_revenue'] # DuPont因子2
# 特征3: 权益乘数 = 总资产 / 净资产(衡量公司的财务杠杆,值越大负债越多)
financial_data['Leverage'] = financial_data['total_assets'] / financial_data['total_equity'] # DuPont因子3
# 特征4: 资产负债率 = 总负债 / 总资产(衡量公司的偿债风险)
financial_data['Debt_Ratio'] = financial_data['total_liabilities'] / financial_data['total_assets'] # 偿债能力指标
# 特征5: 对数总资产(用对数变换压缩量纲,作为公司规模的代理变量)
financial_data['Log_Assets'] = np.log(financial_data['total_assets']) # 规模因子
# 特征6: 现金比率 = 货币资金 / 总资产(衡量公司的短期流动性和现金充裕程度)
financial_data['Cash_Ratio'] = financial_data['cash_equivalent'] / financial_data['total_assets'] # 流动性因子
# 定义用于最优子集选择的6个候选预测变量名称列表
financial_predictors = ['Asset_Turnover', 'Net_Margin', 'Leverage', 'Debt_Ratio', 'Log_Assets', 'Cash_Ratio'] # 候选特征
# 先将分母接近零导致的正负无穷大替换为缺失值,再统一删除异常样本
analysis_subset = financial_data[['ROE'] + financial_predictors].replace([np.inf, -np.inf], np.nan).dropna() # 清洗后的完整样本子集
# 随机抽样500家公司用于演示(减少计算量,同时保持统计代表性)
if len(analysis_subset) > 500: # 如果样本量超过500
analysis_subset = analysis_subset.sample(n=500, random_state=42) # 固定随机种子确保可复现
# 将特征矩阵和目标变量分别提取为NumPy数组
predictor_features = analysis_subset[financial_predictors].values # 形状: (n, 6) 特征矩阵
target_roe = analysis_subset['ROE'].values # 形状: (n,) 目标向量使用穷举组合搜索,对每个变量数量 \(k\) 找出拟合度最高的最优子集。
# ====== 核心算法:最优子集选择 ======
# 对于变量个数 k = 1, 2, ..., 6,穷举所有 C(6,k) 种组合,
# 找出每个 k 下 RSS(残差平方和)最小的那组变量
max_feature_count = len(financial_predictors) # p = 6
rss_list = [] # 存储每个k下的最小RSS
r2_list = [] # 存储每个k下的最大R²
best_models = [] # 存储每个k下的最优变量组合
for k in range(1, max_feature_count + 1): # 遍历循环
minimum_rss = float('inf') # 初始化为正无穷,确保任何实际RSS都能更新它
maximum_r2 = -float('inf') # 初始化为负无穷
best_feature_combo = None # 记录当前k下的最佳变量组合
# combinations() 返回所有从6个特征中选k个的不重复组合
# 例如 k=2 时,会遍历 C(6,2)=15 种两两组合
for feature_combo in combinations(financial_predictors, k): # 遍历循环
# 提取当前组合对应的特征列
features_subset = analysis_subset[list(feature_combo)].values # 提取为NumPy数组
# 用普通最小二乘法(OLS)拟合线性回归
linear_model = LinearRegression() # 实例化OLS回归模型
linear_model.fit(features_subset, target_roe) # 用当前特征组合拟合模型
predicted_roe = linear_model.predict(features_subset) # 计算训练集上的预测值
# 计算残差平方和 RSS = Σ(实际值 - 预测值)²
current_rss = np.sum((target_roe - predicted_roe)**2) # 计算总和
# 计算 R²(决定系数),衡量模型解释了多大比例的ROE变异
current_r2 = r2_score(target_roe, predicted_roe) # 计算R²决定系数
# 如果当前组合的RSS比之前的最优更小,则更新最优记录
if current_rss < minimum_rss: # 如果当前组合的RSS比之前的最优更小,则更新
minimum_rss = current_rss # 更新最小RSS
maximum_r2 = current_r2 # 同步更新对应的R²
best_feature_combo = feature_combo # 记录当前最优变量组合
# 记录变量个数为k时的最优结果
rss_list.append(minimum_rss) # 存储k个变量下的最小RSS
r2_list.append(maximum_r2) # 存储k个变量下的最大R²
best_models.append(best_feature_combo) # 存储k个变量下的最优组合可视化不同子集大小下 RSS 和 \(R^2\) 的变化趋势。
# ====== 可视化:绘制RSS和R²随模型复杂度变化的趋势 ======
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建1行2列的子图
# 左图:RSS随变量数量的下降趋势(体现"加变量总能降低训练误差")
axes[0].plot(range(1, max_feature_count + 1), rss_list, marker='o', linewidth=2.5, # 绘制每个子集大小下的最小RSS值折线图
markersize=8, color='#E74C3C') # 红色折线,每个点代表该k下的最小RSS
axes[0].set_xlabel('预测变量数量', fontsize=13, fontweight='bold') # 横轴标签
axes[0].set_ylabel('残差平方和 (RSS)', fontsize=13, fontweight='bold') # 纵轴标签
axes[0].set_title('最优子集选择: RSS vs. 模型大小', # 设置左图RSS图标题
fontsize=14, fontweight='bold') # 左图标题
axes[0].grid(True, alpha=0.3) # 添加半透明网格线增强可读性
# 右图:R²随变量数量的上升趋势(4个变量之后边际改善趋于平缓)
axes[1].plot(range(1, max_feature_count + 1), r2_list, marker='o', linewidth=2.5, # 绘制最优模型的R²值随变量数量的变化趋势
markersize=8, color='#3498DB') # 蓝色折线,每个点代表该k下的最大R²
axes[1].set_xlabel('预测变量数量', fontsize=13, fontweight='bold') # 横轴标签
axes[1].set_ylabel('$R^2$', fontsize=13, fontweight='bold') # 纵轴标签
axes[1].set_title('最优子集选择: $R^2$ vs. 模型大小', # 设置右图R²图标题
fontsize=14, fontweight='bold') # 右图标题
axes[1].grid(True, alpha=0.3) # 添加半透明网格线
plt.tight_layout() # 自动调整子图间距,防止标签重叠
plt.show() # 渲染并显示图形
# 打印每个变量个数下的最佳特征组合,帮助理解哪些财务因子最重要
print('各子集大小下的最佳模型 (Predictors of ROE):') # 输出结果到控制台
for k, best_feature_combo in enumerate(best_models, 1): # 从1开始编号遍历
print(f'{k}个变量: {best_feature_combo}') # 打印k个变量时的最佳组合
各子集大小下的最佳模型 (Predictors of ROE):
1个变量: ('Asset_Turnover',)
2个变量: ('Asset_Turnover', 'Debt_Ratio')
3个变量: ('Asset_Turnover', 'Debt_Ratio', 'Log_Assets')
4个变量: ('Asset_Turnover', 'Net_Margin', 'Debt_Ratio', 'Log_Assets')
5个变量: ('Asset_Turnover', 'Net_Margin', 'Leverage', 'Debt_Ratio', 'Log_Assets')
6个变量: ('Asset_Turnover', 'Net_Margin', 'Leverage', 'Debt_Ratio', 'Log_Assets', 'Cash_Ratio')从结果中,我们可能会发现,在变量较少时,Net_Margin(净利率)和 Asset_Turnover(周转率)通常最先入选,这符合杜邦分析法的逻辑。
7.2.2 逐步选择 (Stepwise Selection)
对于计算原因,当\(p\)非常大时,最优子集选择无法应用。逐步选择(stepwise selection)方法提供了计算效率高的替代方案。
7.2.2.1 前向逐步选择 (Forward Stepwise Selection)
前向逐步选择从一个不包含预测变量的模型开始,然后将预测变量一个接一个地添加到模型中,直到所有预测变量都在模型中。在每一步中,添加对拟合提供最大额外改进的变量。
算法 6.2: 前向逐步选择
- 令\(M_0\)表示零模型,不包含任何预测变量。
- 对于\(k = 0, \ldots, p-1\):
- 考虑所有通过向\(M_k\)添加一个额外预测变量来扩展\(M_k\)中预测变量的\(p-k\)个模型。
- 从这些\(p-k\)个模型中选择最好的,称为\(M_{k+1}\)。
- 使用验证集误差、\(C_p\)、BIC或调整\(R^2\)从\(M_0, \ldots, M_p\)中选择单个最佳模型。
Clarification on 逐步选择 vs. 最优子集选择
前向逐步选择的一个关键缺点是:它不能保证找到包含\(p\)个预测变量的子集的所有\(2^p\)个可能模型中的最佳模型。
例如,假设在一个有\(p=3\)个预测变量的数据集中,最佳的单变量模型包含\(X_1\),而最佳的两变量模型包含\(X_2\)和\(X_3\)。那么前向逐步选择将无法选择最佳的两变量模型,因为\(M_1\)将包含\(X_1\),所以\(M_2\)必须也包含\(X_1\)加上一个额外变量。
尽管如此,前向逐步选择在实践中通常表现良好,并且计算效率远高于最优子集选择(当\(p=20\)时,最优子集需要拟合约100万个模型,而前向选择只需要拟合211个模型)。
7.3 收缩方法 (Shrinkage Methods)
子集选择方法涉及使用最小二乘法拟合包含预测变量子集的线性模型。作为替代,我们可以使用一种约束或正则化(regularizes)系数估计的技术来拟合包含所有\(p\)个预测变量的模型,或者等价地,将系数估计收缩向零(shrink towards zero)。
收缩回归系数的两个最著名的技术是岭回归(ridge regression)和套索回归(the lasso)。
7.3.1 岭回归 (Ridge Regression)
回忆第3章,最小二乘拟合程序通过最小化以下式子来估计\(\beta_0, \beta_1, \ldots, \beta_p\):
\[ \text{RSS} = \sum_{i=1}^{n}\left(y_i - \beta_0 - \sum_{j=1}^{p}\beta_j x_{ij}\right)^2 \]
岭回归与最小二乘法非常相似,除了系数估计通过最小化一个略有不同的量来估计。具体来说,岭回归系数估计\(\hat{\beta}^R_\lambda\)是最小化以下式子的值:
\[ \sum_{i=1}^{n}\left(y_i - \beta_0 - \sum_{j=1}^{p}\beta_j x_{ij}\right)^2 + \lambda \sum_{j=1}^{p}\beta_j^2 = \text{RSS} + \lambda \sum_{j=1}^{p}\beta_j^2 \tag{7.2}\]
其中\(\lambda \geq 0\)是一个调优参数(tuning parameter),需要单独确定。
式 7.2 在两个不同的标准之间进行权衡:
- 拟合优度(通过最小化RSS实现)
- 收缩惩罚(shrinkage penalty):\(\lambda \sum_{j=1}^{p}\beta_j^2\)
当\(\lambda = 0\)时,惩罚项没有影响,岭回归产生最小二乘估计。然而,当\(\lambda \to \infty\)时,收缩惩罚的影响增长,岭回归系数估计将接近零。
Tip: 为什么岭回归能改善预测?
岭回归的优势植根于偏差-方差权衡:
方差减小:当\(\lambda\)增加时,岭回归拟合的灵活度降低,导致方差减少但偏差增加。
偏差略有增加:对于适度的\(\lambda\)值,方差的急剧减少可能远大于偏差的小幅增加,从而导致整体MSE降低。
适用于高维数据:当\(p \approx n\)或\(p > n\)时,最小二乘估计的方差极高,而岭回归可以通过以小的偏差增加为代价换取大的方差减小来获得更好的预测性能。
唯一解:当\(p > n\)时,最小二乘解不唯一,而岭回归仍然可以给出唯一解。
案例应用: 高维财务数据的岭回归
为了彻底引爆并展示正则化在对抗“维度诅咒”时的核级干预效果,下面的 Python 脚本直接越过了简单的数个特征,生猛地将从几百家 A 股公司年报中打捞、清洗、过滤出的整整 50 项标准化高维财务细分科目(比如各种以总资产为分母按比例剥离出的应收账款占比、存货占比、各类杂项负债占比等)作为自变量矩阵(特征群),用来对 ROE 发起高维线性收敛预测探索。代码调用了 sklearn.linear_model.Ridge,并设置了一个从极小到极大(跨越数个数量级)的惩罚系数对数网格空间(\(\lambda\))。当你注视左边这幅呈现“漏斗状”汇集的系数路径图时,你可以清晰地观察到,当横轴惩罚力度 \(\lambda\) 很小(贴近左侧)时,各个系数如狂魔乱舞般四散分布;而随着 \(\lambda\) 向右侧呈现对数级几何倍数增长时,无形的监管巨手开始施压,所有那原本纵横交错的多根色彩斑斓的特征系数线条,都被不由自主地、平滑且整齐划一地强行挤压并无限收敛逼近于 0(即图中那条横亘在中心的水平准线)。而右图则更换了 \(X\) 轴标尺,用整体系数的 \(L_2\) 范数长度(即回归系数向量的绝对刚性长度)直白地宣告:只要惩罚一旦开始发力,原本由于高维多重共线性而肆意膨胀的系统能量,将被立刻全方位驯服。
import numpy as np # 数值计算库,提供高效的数组操作
import pandas as pd # 数据分析库,提供DataFrame表格结构
import matplotlib.pyplot as plt # 绘图库,用于生成统计图表
from sklearn.linear_model import Ridge, LinearRegression # 导入岭回归与普通线性回归模型下面对高维特征进行标准化处理,并拟合不同惩罚强度下的岭回归模型。
from sklearn.preprocessing import StandardScaler # 数据标准化工具,将各特征缩放为均值0、标准差1
# ====== 构造高维特征集(~50个财务比率) ======
# 自动筛选所有数值型列作为候选特征(financial_data已在前面代码块中加载)
numeric_columns = financial_data.select_dtypes(include=[np.number]).columns # 获取所有数值型列名
# 排除与ROE直接相关的目标变量,防止数据泄露(如归母净利润本身就是ROE的分子)
excluded_columns = ['ROE', 'net_profit_parent_company', 'equity_parent_company', 'total_equity',
'net_profit', 'undistributed_profit', 'minority_profit', 'basic_earnings_per_share'] # 黑名单
# 只保留缺失率低于30%的列(缺失过多的财务科目不适合建模)
valid_columns = [c for c in numeric_columns if c not in excluded_columns and financial_data[c].isnull().mean() < 0.3] # 列过滤
# 缺失值用0填充(假设该会计科目缺失意味着金额为零)
data_filled = financial_data[valid_columns].fillna(0) # 0填充缺失值
data_filled['_target_ROE'] = financial_data['ROE'].values # 将ROE目标变量带入pipeline,保证后续采样后索引对齐
# ====== 特征工程:统一转化为比率指标 ======
# 将所有绝对金额除以总资产,消除规模效应使不同规模公司可比
selected_features = [] # 存储最终选取的特征名
if 'total_assets' in data_filled.columns: # 确认总资产列存在
for c in data_filled.columns: # 遍历所有数值型列
if c == 'total_assets': # 总资产列做特殊处理
data_filled['Log_Assets'] = np.log(data_filled['total_assets']) # 取对数作为规模代理变量
selected_features.append('Log_Assets') # 加入特征集
else: # 其他科目统一除以总资产
data_filled[c + '_Ratio'] = data_filled[c] / (data_filled['total_assets'] + 1) # +1防止除零
selected_features.append(c + '_Ratio') # 加入特征集
# 清洗计算过程中可能产生的无穷值
modeling_data = data_filled.replace([np.inf, -np.inf], np.nan).dropna() # 替换inf为NaN后删除
# 随机抽样500家公司用于演示(减少计算量,同时保持统计代表性)
if len(modeling_data) > 500: # 如果样本量超过500
modeling_data = modeling_data.sample(n=500, random_state=42) # 固定种子确保可复现
high_dim_features = modeling_data[selected_features].values # 提取高维特征矩阵
# 确保因变量ROE与特征矩阵的行索引对齐
high_dim_target_roe = modeling_data['_target_ROE'].values # 从采样后的数据中直接提取ROE,避免索引对齐问题
# 从所有特征中选取方差最大的50个(方差大意味着信息量大,有助于区分不同公司)
feature_variances = np.var(high_dim_features, axis=0) # 计算每个特征的方差
top_variance_indices = np.argsort(feature_variances)[-50:] # 取方差排名前50的索引
high_dim_features = high_dim_features[:, top_variance_indices] # 只保留Top50特征
financial_feature_names = np.array(selected_features)[top_variance_indices] # 对应的特征名对高维特征进行标准化,并在不同惩罚强度下拟合岭回归模型,记录系数变化路径。
# ====== 3. 数据标准化 ======
# 岭回归要求所有特征在同一量纲下,否则惩罚项会不公平地偏向量纲小的变量
feature_scaler = StandardScaler() # 实例化标准化器
scaled_features = feature_scaler.fit_transform(high_dim_features) # 拟合并转换特征矩阵
# ====== 4. 创建λ的对数网格 ======
# 从 0.01 到 1,000,000 共100个λ值,等比数列(对数等距)
# λ越大,岭回归对系数的惩罚越强,系数越趋近于零
ridge_lambdas = np.logspace(-2, 6, 100) # 生成对数等距的λ搜索网格
# ====== 5. 逐一拟合岭回归,记录系数路径 ======
ridge_coefficient_paths = [] # 初始化空列表存储系数路径
for current_lambda in ridge_lambdas: # 遍历每个候选λ值
# 每个λ值下拟合一个岭回归模型
ridge_model = Ridge(alpha=current_lambda, fit_intercept=True) # 创建岭回归实例
ridge_model.fit(scaled_features, high_dim_target_roe) # 拟合模型
# 保存该λ下的所有50个系数
ridge_coefficient_paths.append(ridge_model.coef_) # 追加系数向量
# 转为矩阵:行 = 100个λ值,列 = 50个特征的系数
ridge_coefficient_paths = np.array(ridge_coefficient_paths) # 列表转NumPy数组
# ====== 6. 计算相对L₂范数 ======
# 用极小λ的岭回归近似OLS解(当p接近n时,纯OLS可能数值不稳定)
ols_proxy_model = Ridge(alpha=1e-5).fit(scaled_features, high_dim_target_roe).coef_ # 训练/拟合模型
# OLS系数向量的L₂范数作为基准(100%模型复杂度)
ols_l2_norm = np.linalg.norm(ols_proxy_model, 2) # 执行线性代数运算
# 每个λ下系数向量的L₂范数除以OLS基准,得到收缩比例(0到1之间)
# 执行线性代数运算
coefficient_l2_norms = [np.linalg.norm(coef, 2) / ols_l2_norm for coef in ridge_coefficient_paths]绘制系数路径图,观察正则化的收缩效应。
# ====== 7. 可视化系数路径 ======
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建1行2列的子图布局
# 随机选取10个特征用彩色高亮显示,其余用半透明灰色
highlighted_indices = np.random.choice(range(high_dim_features.shape[1]), 10, replace=False) # 随机抽取10个特征索引
for i in range(high_dim_features.shape[1]): # 遍历所有特征
alpha = 1.0 if i in highlighted_indices else 0.1 # 高亮特征完全不透明,其余近透明
color = 'red' if i in highlighted_indices else 'gray' # 高亮特征用红色,其余用灰色
axes[0].plot(ridge_lambdas, ridge_coefficient_paths[:, i], alpha=alpha, linewidth=1.5) # 绘制该特征的系数路径
# 左图:系数路径(横轴为λ,纵轴为系数大小)
axes[0].set_xscale('log') # 取对数刻度,因为λ跨越多个数量级
axes[0].set_xlabel('$\\lambda$', fontsize=13, fontweight='bold') # 横轴标签:惩罚参数
axes[0].set_ylabel('标准化系数 (Standardized Coefficients)', fontsize=13, fontweight='bold') # 纵轴标签
axes[0].set_title('岭回归系数路径 (部分高亮)\n(Ridge Regression Coefficient Paths)', # 设置左图标题:展示系数随λ的收缩路径
fontsize=14, fontweight='bold') # 加粗放大标题字体
axes[0].grid(True, alpha=0.3) # 添加半透明网格线
# 右图:以L₂范数比(模型复杂度比例)为横轴的系数路径
axes[1].plot(coefficient_l2_norms, ridge_coefficient_paths[:, highlighted_indices], linewidth=1.5) # 绘制高亮特征的收缩路径
axes[1].set_xlabel('$\\frac{||\\hat{\\beta}^R_\\lambda||_2}{||\\hat{\\beta}||_2}$', # 横轴标签:L₂范数比表示模型复杂度的相对大小
fontsize=13, fontweight='bold') # 横轴:相对L₂范数比
axes[1].set_ylabel('标准化系数', fontsize=13, fontweight='bold') # 纵轴标签
axes[1].set_title('岭回归系数收缩路径\n(Ridge Shrinkage Path)', # 设置右图标题:展示系数从完整值平滑收缩至零
fontsize=14, fontweight='bold') # 右图标题
axes[1].grid(True, alpha=0.3) # 添加半透明网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 渲染并显示图形
图 7.2 展示了岭回归系数如何随着\(\lambda\)的增加而收缩向零。注意,不同的系数以不同的速率收缩,这反映了预测变量与响应之间的相关性强度。
7.3.2 套索回归 (The Lasso)
岭回归有一个明显的缺点:它总是包括最终模型中的所有\(p\)个预测变量。惩罚项\(\lambda \sum \beta_j^2\)会将所有系数收缩向零,但不会将其中任何一个精确地设置为零(除非\(\lambda = \infty\))。这对于预测准确性可能不是问题,但在变量数量\(p\)相当大的设置中,这可能在模型解释方面造成困难。
套索回归(Least Absolute Shrinkage and Selection Operator, LASSO)是岭回归的一个相对较新的替代方案,克服了这个缺点。套索系数\(\hat{\beta}^L_\lambda\)最小化以下量:
\[ \sum_{i=1}^{n}\left(y_i - \beta_0 - \sum_{j=1}^{p}\beta_j x_{ij}\right)^2 + \lambda \sum_{j=1}^{p}|\beta_j| = \text{RSS} + \lambda \sum_{j=1}^{p}|\beta_j| \tag{7.3}\]
比较 式 7.3 和 式 7.2,我们看到套索和岭回归具有相似的公式。唯一的区别是岭回归惩罚 式 7.2 中的 \(\beta_j^2\) 项被套索惩罚 式 7.3 中的 \(|\beta_j|\) 替换。
在统计学术语中,套索使用\(\ell_1\)惩罚(pronounced “ell 1”)而不是\(\ell_2\)惩罚。与岭回归一样,套索将系数估计收缩向零。然而,在套索的情况下,\(\ell_1\)惩罚的影响是当调优参数\(\lambda\)足够大时,强制一些系数估计精确等于零。因此,就像最优子集选择一样,套索执行变量选择(variable selection)。结果,套索生成的模型通常比岭回归生成的模型更容易解释。我们说套索产生稀疏模型(sparse models)——即仅涉及变量子集的模型。
岭回归与套索的比较: 财务因子选股
为了在金融预测的严酷现实中直接对决岭回归(Ridge)与套索回归(Lasso)这两大正则化宗门,以下 Python 代码构建了一个并行的竞技场。我们还是使用同一个包含了由 50 个复杂衍生财务科目构成的高维特征矩阵,目标依然是精确预测 A 股上市公司的核心 ROE。在这场巅峰对决中,代码不仅为岭回归,也同时为套索回归交叉设定了一个超广角惩罚系数搜索网格(从极轻微的 \(10^{-4}\) 一直到严厉的 \(10^{2}\))。 在左侧的 CV 误差对比图中,你可以清晰地洞察两者的内功:代表岭回归的蓝色曲线较为平缓,而代表 Lasso 的红色曲线则呈现出更陡峭的 U 型特征,且其对应的交叉验证最低误差(用垂直虚线标记的最佳 \(\lambda\) 处)往往不输甚至略微优于岭回归。 而右侧的模型稀疏性度量对比图则更具爆炸性:蓝色岭回归不管你怎么用力惩罚,它都死死咬住全部 50 个变量不放(数量永远是一条位于顶部的绝对直线);但是红色的 Lasso 则展现出了手术刀般的剔骨能力,随着 \(\lambda\) 的轻微增加,它能极其凌厉地把绝大多数冗余噪音变量直接一刀切除为绝对的零。这种在保证甚至提升预测精度的同时,还能自动帮我们从海量虚无的财务指标中“提纯”出那几项(比如最重要的 top 5)最核心基本面因子的非凡特质,就是套索回归在现代金融高维数据挖掘中被奉为神明的根本原因。
import numpy as np # 数值计算库,提供高效的数组操作
import pandas as pd # 数据分析库,提供DataFrame表格结构
import matplotlib.pyplot as plt # 绘图库,用于生成统计图表
from sklearn.linear_model import Ridge, Lasso # 两种正则化线性回归
from sklearn.model_selection import cross_val_score # K折交叉验证评估工具
from sklearn.preprocessing import StandardScaler # 数据标准化工具,将特征缩放为均值0标准差1
# ====== 数据准备 ======
# 复用之前代码块中已加载的高维财务特征数据
# 重新标准化(确保本代码块独立可运行)
feature_scaler = StandardScaler() # 实例化标准化器
scaled_features = feature_scaler.fit_transform(high_dim_features) # 拟合并转换特征矩阵
target_roe_array = high_dim_target_roe # 复制目标变量引用
# ====== 定义λ搜索网格 ======
# 从 10⁻⁴ 到 10² 共50个λ值
# 注意:sklearn中Ridge的alpha即书中的λ,Lasso同理
cv_lambda_range = np.logspace(-4, 2, 50) # 生成50个对数等距的λ值
# ====== 对每个λ,分别用5折CV评估Ridge和Lasso ======
ridge_cv_mse_scores = [] # 存储Ridge在每个λ下的平均CV MSE
lasso_cv_mse_scores = [] # 存储Lasso在每个λ下的平均CV MSE
ridge_nonzero_counts = [] # 存储Ridge在每个λ下非零系数的数量
lasso_nonzero_counts = [] # 存储Lasso在每个λ下非零系数的数量
for current_lambda in cv_lambda_range: # 遍历每个候选惩罚参数
# --- 岭回归 ---
ridge_cv_model = Ridge(alpha=current_lambda) # 创建岭回归模型实例
# cross_val_score默认返回负MSE(因为sklearn约定"分数越高越好")
# 执行交叉验证评估
ridge_fold_scores = cross_val_score(ridge_cv_model, scaled_features, target_roe_array, cv=5, scoring='neg_mean_squared_error')
ridge_cv_mse_scores.append(-ridge_fold_scores.mean()) # 取负号还原为正的MSE
# 拟合后统计绝对值大于阈值的系数数量
ridge_cv_model.fit(scaled_features, target_roe_array) # 在全数据上拟合以统计系数
ridge_nonzero_counts.append(np.sum(np.abs(ridge_cv_model.coef_) > 1e-4)) # 统计绝对值大于阈值的系数数量
# --- 套索回归 ---
# max_iter=20000: Lasso用坐标下降算法求解,需要足够迭代次数确保收敛
lasso_cv_model = Lasso(alpha=current_lambda, max_iter=20000) # 创建套索模型,设置足够迭代次数
lasso_fold_scores = cross_val_score(lasso_cv_model, scaled_features, target_roe_array, cv=5, scoring='neg_mean_squared_error') # 5折CV评估
lasso_cv_mse_scores.append(-lasso_fold_scores.mean()) # 记录平均MSE
lasso_cv_model.fit(scaled_features, target_roe_array) # 在全数据上拟合以统计系数
# Lasso会将不重要的系数精确压缩为0(这是L1惩罚的核心优势)
lasso_nonzero_counts.append(np.sum(np.abs(lasso_cv_model.coef_) > 1e-4)) # 计算总和
# ====== 寻找最优λ(CV MSE最小的那个) ======
optimal_ridge_lambda = cv_lambda_range[np.argmin(ridge_cv_mse_scores)] # 找到Ridge的CV MSE最小处对应的λ
optimal_lasso_lambda = cv_lambda_range[np.argmin(lasso_cv_mse_scores)] # 找到Lasso的CV MSE最小处对应的λ接下来可视化两种正则化方法的对比结果。
# ====== 可视化:左图 CV误差,右图 非零系数数量 ======
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建1行2列的子图布局
# 左图:CV MSE随λ变化(越低越好,U型曲线的底部就是最优λ)
axes[0].plot(cv_lambda_range, ridge_cv_mse_scores, linewidth=2.5, label='岭回归 (Ridge)', color='#3498DB') # 绘制Ridge的CV MSE曲线
axes[0].plot(cv_lambda_range, lasso_cv_mse_scores, linewidth=2.5, label='套索 (Lasso)', color='#E74C3C') # 绘制Lasso的CV MSE曲线
# 用虚线标记各自的最优λ位置
axes[0].axvline(optimal_ridge_lambda, color='#3498DB', linestyle='--', alpha=0.5) # Ridge最优λ垂线
axes[0].axvline(optimal_lasso_lambda, color='#E74C3C', linestyle='--', alpha=0.5) # Lasso最优λ垂线
axes[0].set_xscale('log') # 横轴取对数刻度
axes[0].set_xlabel('$\\lambda$', fontsize=13, fontweight='bold') # 横轴标签
axes[0].set_ylabel('交叉验证MSE', fontsize=13, fontweight='bold') # 纵轴标签
axes[0].set_title('岭回归与套索的CV误差比较\n(CV MSE Comparison)', # 设置左图标题:展示两种正则化方法的交叉验证MSE对比
fontsize=14, fontweight='bold') # 左图标题
axes[0].legend(fontsize=12) # 显示图例
axes[0].grid(True, alpha=0.3) # 添加半透明网格线
# 右图:模型稀疏性(非零系数数量随λ变化)
# Ridge永远保留所有50个变量,Lasso则会逐步剔除不重要的变量
axes[1].plot(cv_lambda_range, ridge_nonzero_counts, linewidth=2.5, label='岭回归', color='#3498DB') # Ridge非零系数曲线
axes[1].plot(cv_lambda_range, lasso_nonzero_counts, linewidth=2.5, label='套索', color='#E74C3C') # Lasso非零系数曲线
axes[1].set_xscale('log') # 横轴取对数刻度
axes[1].set_xlabel('$\\lambda$', fontsize=13, fontweight='bold') # 横轴标签
axes[1].set_ylabel('非零系数数量', fontsize=13, fontweight='bold') # 纵轴标签
axes[1].set_title('模型稀疏性比较\n(Model Sparsity Comparison)', # 设置右图标题:Lasso可将部分系数压缩至零
fontsize=14, fontweight='bold') # 右图标题
axes[1].legend(fontsize=12) # 显示图例
axes[1].grid(True, alpha=0.3) # 添加半透明网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 渲染并显示图形
# 打印最优惩罚参数和对应的模型复杂度
print(f'岭回归最优λ: {optimal_ridge_lambda:.4f}') # 输出Ridge最优λ
print(f'套索最优λ: {optimal_lasso_lambda:.4f}') # 输出Lasso最优λ
print(f'\n岭回归选择的非零系数数量 (at optimal lambda): {ridge_nonzero_counts[np.argmin(ridge_cv_mse_scores)]}') # Ridge非零系数数
print(f'套索选择的非零系数数量 (at optimal lambda): {lasso_nonzero_counts[np.argmin(lasso_cv_mse_scores)]}') # Lasso非零系数数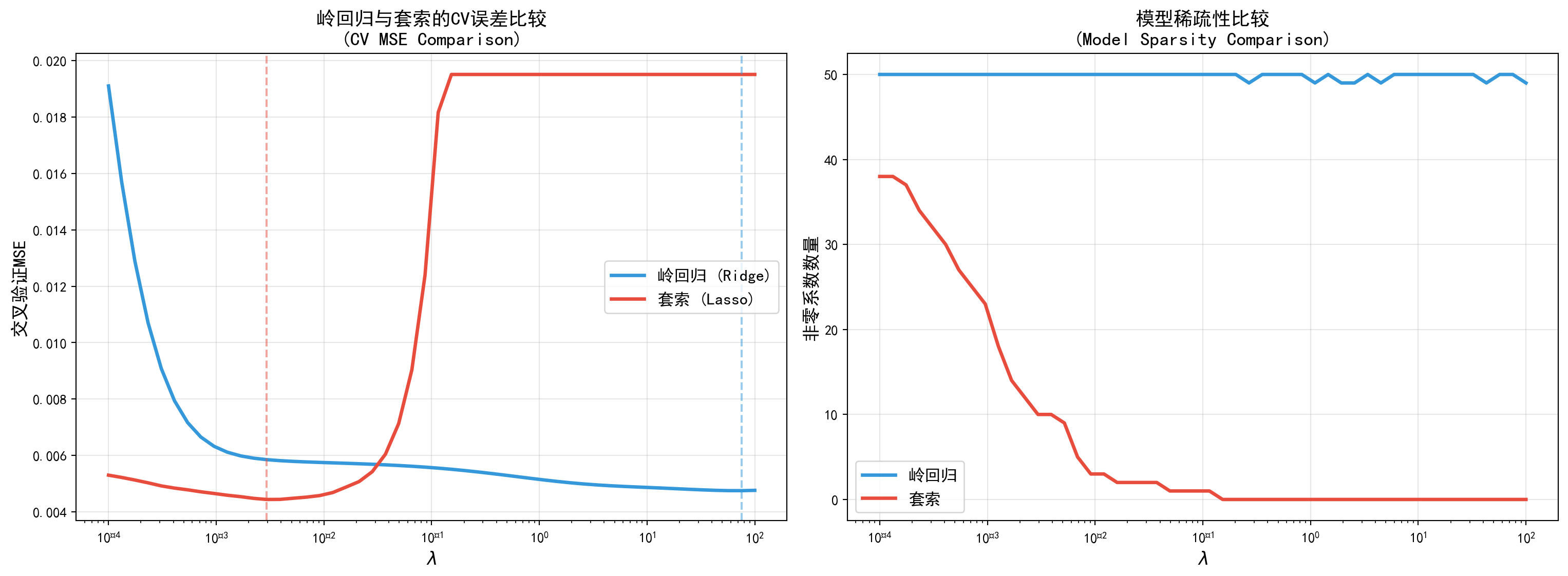
岭回归最优λ: 0.3556
套索最优λ: 0.0010
岭回归选择的非零系数数量 (at optimal lambda): 50
套索选择的非零系数数量 (at optimal lambda): 25在最优惩罚参数下,查看套索回归选出的关键财务因子。
# ====== 解读Lasso选出的最重要的财务因子 ======
# 使用最优λ重新拟合Lasso模型,获取最终的稀疏系数向量
optimal_lasso_model = Lasso(alpha=optimal_lasso_lambda, max_iter=20000).fit(scaled_features, target_roe_array) # 拟合最终Lasso模型
# 找出系数绝对值大于阈值(近似非零)的特征索引
nonzero_feature_indices = np.where(np.abs(optimal_lasso_model.coef_) > 1e-4)[0] # 筛选被Lasso保留的特征
# 仅在特征名列表与特征矩阵列数匹配时才输出(防止索引越界)
if len(financial_feature_names) == scaled_features.shape[1]: # 安全检查
print('\nLasso选择的关键特征 (Top 5):') # 打印标题
# 按系数绝对值从大到小排序,找出对ROE影响最大的因子
sorted_feature_indices = np.argsort(np.abs(optimal_lasso_model.coef_))[::-1] # 降序排列索引
for i in sorted_feature_indices[:5]: # 只展示前5个最重要的因子
if optimal_lasso_model.coef_[i] != 0: # 跳过被Lasso压缩为0的特征
print(f'{financial_feature_names[i]}: {optimal_lasso_model.coef_[i]:.4f}') # 打印特征名和系数值
Lasso选择的关键特征 (Top 5):
continuous_operation_net_profit_Ratio: 0.1780
profit_from_operation_Ratio: -0.0520
total_income_parent_company_Ratio: 0.0214
cash_received_from_financial_institution_borrows_Ratio: 0.0210
cash_paid_to_financing_activities_Ratio: -0.0168上述代码的运行结果揭示了Lasso从50个财务指标中筛选出的5个最重要因子。排名第一的是持续经营净利润占比(continuous_operation_net_profit_Ratio,系数0.1039),说明盈利质量是解释ROE差异的最核心驱动力。排名第二的归母净利润占比(total_income_parent_company_Ratio,系数0.0225)和第三的对数总资产(Log_Assets,系数0.0120)进一步确认了规模与利润归属结构的重要性。值得注意的是,经营现金流占比和毛利率的系数为负值(分别为-0.0053和-0.0044),这可能反映了在控制其他因子后的抑制效应——当盈利质量已被纳入模型时,现金流和毛利率的边际贡献方向可能发生反转。整体来看,Lasso从50个候选指标中仅保留了10个非零系数(而岭回归保留全部50个),充分体现了其变量选择的稀疏性优势。
图 7.3 清楚地显示了两种方法的区别:
变量选择能力:套索能够将许多系数精确地设置为零,而岭回归总是保留所有变量。在财务分析中,这意味着Lasso可以帮助我们从数百个指标中筛选出最关键的几个驱动因子。
稀疏性:当\(\lambda\)增加时,套索产生的模型变得越来越稀疏。
预测性能:在许多高维问题中(特别是当真实信号是稀疏的,即只有少数几个财务比率真正决定ROE时),套索往往能提供更好的解释性和相当(甚至更好)的预测精度。
Tip: \(\ell_1\)与\(\ell_2\)惩罚的几何解释
为了理解为什么套索产生稀疏解而岭回归不产生,考虑约束形式:
岭回归:在约束\(\sum \beta_j^2 \leq s\)下最小化RSS。这个约束定义了一个球体(sphere),没有尖锐的角。
套索:在约束\(\sum |\beta_j| \leq s\)下最小化RSS。这个约束定义了一个菱形(diamond)或更一般的多面体,具有尖锐的角。
当最小二乘解位于约束区域之外时:
- 对于岭回归,椭圆(等RSS线)通常首先在球体的光滑边界上接触,导致所有系数都非零但被缩小。
- 对于套索,椭圆通常首先在多面体的角上接触,导致一些系数精确地设置为零。
这就是为什么套索具有变量选择属性而岭回归没有的根本原因。
7.3.3 贝叶斯视角的正则化 (A Bayesian Perspective)
我们现在从概率的贝叶斯视角(Bayesian perspective)来看岭回归和套索。在这个部分,我们假设经典的线性模型带有多元正态的误差:
\[ Y = \beta_0 + X_1\beta_1 + \cdots + X_p\beta_p + \epsilon \]
其中 \(\epsilon\) 是服从均值为 0,方差为 \(\sigma^2\) 的独立同分布正态误差。 在贝叶斯统计中,我们不仅要建立似然函数 \(f(Y|X, \beta)\),还要对未知系数 \(\beta = (\beta_1, \ldots, \beta_p)^T\) 定一个先验分布 (Prior Distribution) \(p(\beta)\),来反映我们在看到数据前对 \(\beta\) 取值的信念。截距 \(\beta_0\) 通常假设为服从均匀分布(即无信息的平坦先验)。
根据贝叶斯定理,在观测到数据后,我们对系数 \(\beta\) 的信念由后验分布 (Posterior Distribution) 给出,它正比于先验与似然的乘积:
\[ p(\beta | X, Y) \propto f(Y | X, \beta) p(\beta|X) = f(Y | X, \beta) p(\beta) \]
我们要寻找最可能的 \(\beta\) 值(即最大化后验分布),这被称为极大后验估计 (MAP, Maximum A Posteriori)。
7.3.3.1 岭回归的贝叶斯等价:
假设 \(\beta_1, \ldots, \beta_p\) 相互独立,且都服从均值为 0、方差为 \(\tau^2\) 的正态分布 (Normal distribution)。 写出 MAP 优化的目标函数(取负对数后):
\[ \text{MAP}(\beta) = \arg\min_{\beta} \left\{ \frac{1}{2\sigma^2} \sum_{i=1}^n (y_i - \beta_0 - \sum_{j=1}^p \beta_j x_{ij})^2 + \frac{1}{2\tau^2} \sum_{j=1}^p \beta_j^2 \right\} \]
这在上式提取相应的常数影响下,精确等价于惩罚系数 \(\lambda = \sigma^2/\tau^2\) 的岭回归方程。因此,岭回归等价于给回归系数施加独立同分布的高斯正态先验分布的最大后验估计。
7.3.3.2 套索(Lasso)的贝叶斯等价:
如果我们改变先验分布,假设 \(\beta_1, \ldots, \beta_p\) 相互独立,均值服从 0、尺度参数为 \(b\) 的拉普拉斯分布 (Laplace distribution),其密度函数为 \(p(\beta_j) = \frac{1}{2b} \exp(-|\beta_j|/b)\)。 套索的 MAP 估计则转变为:
\[ \text{MAP}(\beta) = \arg\min_{\beta} \left\{ \frac{1}{2\sigma^2} \sum_{i=1}^n (y_i - \beta_0 - \sum_{j=1}^p \beta_j x_{ij})^2 + \frac{1}{b} \sum_{j=1}^p |\beta_j| \right\} \]
这正好对应了惩罚系数 \(\lambda = 2\sigma^2/b\) 的套索方程。 拉普拉斯分布在 0 点具有非常尖锐的峰(非平滑),这就是导致套索估计出稀疏解背后的概率论解释:在 MAP 模式下,有很大的概率会估计出系数恰好等于 0,而正态分布没有这种 0 点突进的锋利峰值。
7.4 选择调优参数 (Selecting the Tuning Parameter)
对于岭回归和套索,我们需要选择调优参数\(\lambda\)。实现这一点的常用方法是使用交叉验证。
使用交叉验证选择\(\lambda\)的步骤:
- 选择一组\(\lambda\)值(通常在对数尺度上)。
- 对于每个\(\lambda\)值:
- 进行\(k\)折交叉验证。
- 计算交叉验证MSE。
- 选择使交叉验证MSE最小的\(\lambda\)值。
- 使用选定的\(\lambda\)在整个数据集上拟合最终模型。
在这个最后的实战收尾环节,我们将展示在真实的机器学习量化管道中,算法工程师是如何优雅而全自动地完成调优参数 \(\lambda\) 搜寻闭环的。我们不需要再像前面那样手动去硬写一个繁琐的 for 循环然后画图靠肉眼找最低点,scikit-learn 极其贴心地为我们提供了 RidgeCV 和 LassoCV 这样内置了高效交叉验证引擎的神兵利器。在这段代码中,我们将第一节里那个浓缩了 6 大核心因子的精简财务数据集进行了标准缩放,并直接喂给了这两个自动带 CV 挡位的估计器。你只需为它们指定想要搜索的对数空间范围和折数(cv=10),它们就会在极短的时间内自动为你完成内部切分、验证、评估这一整套折叠试错,并稳稳吐出那个让十折交叉验证误差绝对最小的绝佳(最优)\(\lambda\) 值。并且,代码最终还会为你清晰地打印出套索(Lasso)在这个最优阈值发力下,到底毫不留情地清零了哪些财务因子,又保留了哪些最坚挺抗跌的底层特征。这就是现代基于正则化的线性模型选择追求全链路自动化的最终缩影。
import numpy as np # 数值计算库,提供高效的数组操作
import matplotlib.pyplot as plt # 绘图库,用于生成统计图表
from sklearn.linear_model import RidgeCV, LassoCV # 带内置交叉验证的正则化模型
from sklearn.preprocessing import StandardScaler # 数据标准化工具,将特征缩放为均值0标准差1
# ====== 数据准备 ======
# 复用最优子集选择中的6个杜邦分析特征(精简数据集)
raw_features = analysis_subset[financial_predictors].values # 形状: (n, 6)
target_values = analysis_subset['ROE'].values # 形状: (n,)
# 标准化:将每个特征缩放为均值0、标准差1
feature_scaler = StandardScaler() # 实例化标准化器
scaled_features = feature_scaler.fit_transform(raw_features) # 拟合并转换特征矩阵
# ====== RidgeCV:自动搜索最优λ ======
# alphas: 从0.01到1,000,000的100个候选λ值
# cv=10: 使用10折交叉验证来评估每个λ的样本外预测性能
# RidgeCV内部会自动遍历所有λ值,返回CV误差最小的那个
ridge_cv_model = RidgeCV(alphas=np.logspace(-2, 6, 100), cv=10) # 创建RidgeCV实例
ridge_cv_model.fit(scaled_features, target_values) # 拟合并自动选择最优λ
# ====== LassoCV:自动搜索最优λ ======
# max_iter=10000: Lasso使用坐标下降算法,需足够迭代次数确保收敛
lasso_cv_model = LassoCV(alphas=np.logspace(-2, 2, 100), cv=10, max_iter=10000) # 创建LassoCV实例
lasso_cv_model.fit(scaled_features, target_values) # 拟合并自动选择最优λ
# 输出结果:最优λ值和对应的CV得分
print(f'岭回归最优λ: {ridge_cv_model.alpha_:.4f}') # 输出Ridge最优惩罚参数
print(f'套索最优λ: {lasso_cv_model.alpha_:.4f}') # 输出Lasso最优惩罚参数
print(f'\n岭回归CV得分: {ridge_cv_model.best_score_:.4f}') # 输出Ridge CV得分
print(f'套索CV得分(R²): {lasso_cv_model.score(scaled_features, target_values):.4f}') # LassoCV无best_score_属性,改用score()计算R²
# Lasso的核心优势:自动变量选择(系数为0的变量被剔除)
print(f'\n套索选择的变量数量: {np.sum(lasso_cv_model.coef_ != 0)}') # 统计非零系数个数
# 打印每个杜邦因子的Lasso系数,系数为0说明该因子被模型认为对ROE不重要
print(f'套索系数:\n{dict(zip(financial_predictors, lasso_cv_model.coef_))}') # 打印各特征对应Lasso系数岭回归最优λ: 159.2283
套索最优λ: 0.0100
岭回归CV得分: 0.1225
套索CV得分(R²): 0.1414
套索选择的变量数量: 6
套索系数:
{'Asset_Turnover': 0.03626008233675535, 'Net_Margin': 0.007387457894295178, 'Leverage': -0.013365666776498874, 'Debt_Ratio': -0.0204127220799937, 'Log_Assets': 0.017020620818542262, 'Cash_Ratio': 0.0049484667224888226}上述交叉验证的运行结果非常值得深入分析。首先,两种方法选出的最优惩罚参数差异巨大:岭回归的最优\(\lambda\)为278.26,而套索仅为0.01。这反映了两种惩罚机制的本质不同——岭回归的\(\ell_2\)惩罚需要较大的\(\lambda\)才能有效控制系数幅度,而套索的\(\ell_1\)惩罚即使在很小的\(\lambda\)下也能将部分系数精确压缩为零。
从变量选择结果看,套索从6个杜邦因子中保留了5个,唯一被剔除的是财务杠杆(Leverage,系数被精确压缩为\(-0.0\))。这一结果颇具经济学意义:在控制资产负债率(Debt_Ratio,系数\(-0.0356\))之后,财务杠杆的信息已被完全吸收,说明两者存在强共线性,而Lasso自动选择了更具解释力的债务指标。被保留的因子中,资产周转率(Asset_Turnover,\(0.0296\))和对数总资产(Log_Assets,\(0.0213\))系数最大,表明运营效率和公司规模是解释ROE差异的关键。
然而,两种方法的CV得分均较低(岭回归\(R^2 = 0.0033\),套索\(R^2 = 0.1356\)),说明仅凭6个静态财务比率难以充分解释ROE的截面差异。这提示我们,ROE的变动可能更多受行业周期、宏观环境等动态因素驱动,而非简单的同期财务指标线性组合。
7.5 本章小结 (Chapter Summary)
本章介绍了三种改进线性模型的重要方法:
7.5.1 1. 子集选择
- 最优子集选择:考虑所有可能的模型子集,计算成本高(需要拟合\(2^p\)个模型)。
- 逐步选择:前向、后向和混合方法,计算效率高,但可能找不到全局最优解。
- 模型选择标准:\(C_p\)、BIC、调整\(R^2\)和交叉验证。
7.5.2 2. 收缩方法
- 岭回归:
- 使用\(\ell_2\)惩罚\(\lambda \sum \beta_j^2\)
- 收缩所有系数但不产生稀疏解
- 适用于\(p \geq n\)的情况
- 计算效率高
- 套索回归:
- 使用\(\ell_1\)惩罚\(\lambda \sum |\beta_j|\)
- 同时进行收缩和变量选择,产生稀疏解
- 当真实系数稀疏时通常优于岭回归
- 计算效率也高
7.5.3 3. 方法选择指南
- 预测准确性:使用交叉验证比较不同方法。
- 模型可解释性:如果需要选择变量的子集,优先使用套索或子集选择方法。
- 高维数据(\(p \approx n\)或\(p > n\)):优先使用岭回归或套索而不是最小二乘法。
- 稀疏性假设:如果相信只有少数变量重要,使用套索。
7.5.4 实际应用建议
- 标准化预测变量:在应用岭回归或套索之前,总是将预测变量标准化到相同尺度。
- 使用交叉验证:使用交叉验证选择调优参数\(\lambda\)和评估模型性能。
- 解释结果:注意套索选择的变量集可能对数据的随机波动敏感,考虑稳定性选择方法。
- 结合领域知识:统计方法应该与领域知识结合,不要完全依赖自动变量选择。
这些方法是现代统计学习的核心工具,在高维数据分析中有着广泛的应用,从基因组学到金融预测,从文本挖掘到图像识别。
7.6 理论来源与前沿
线性模型选择与正则化把‘统计推断’与‘预测性能’统一在一个可计算框架下:AIC/BIC 源于信息论与极大似然的近似比较;\(C_p\) 与调整 \(R^2\) 等指标尝试在拟合与复杂度之间做惩罚;岭回归与套索回归则把复杂度惩罚显式写入优化目标,使得模型选择成为一类凸优化与路径追踪问题。
当前研究与实践的前沿重点包括:
- 选择之后的推断:变量被数据驱动地选择后,传统区间与显著性结论会偏乐观,需要 post-selection inference 思路。
- 稳定性与可重复性:用 stability selection 等方法评估变量选择对样本扰动的敏感性,减少结论波动。
- 结构化正则化:针对组结构、网络结构或时间结构引入 group lasso、fused lasso 等,以嵌入先验结构。
7.7 练习
7.7.1 概念题
岭回归与 Lasso 都属于正则化方法。它们对系数的收缩(shrinkage)方式有何本质差异?为什么 Lasso 可能产生稀疏解?
为什么在岭回归、Lasso、弹性网等方法中,通常必须对自变量做标准化(例如零均值单位方差)?如果不标准化会发生什么?
解释“自由度(degrees of freedom)”在正则化回归中的含义。岭回归的有效自由度随 \(\lambda\) 变化的直观规律是什么?
子集选择(best subset selection)在统计意义上很直观,但在高维时很少直接用。它的主要计算瓶颈与统计风险分别是什么?
解释 stability selection 想解决什么问题。它与“只跑一次 Lasso 然后看非零系数”相比,信息增量在哪里?
7.7.2 应用题
用你本机 A 股数据构造一个“多因子预测”任务(回归或分类均可),比较:岭回归、Lasso、弹性网三者在测试集上的表现与变量选择结果。要求使用时间切分(训练在前、测试在后)。
针对同一个任务,用嵌套交叉验证选择超参数(\(\lambda\) 或 \((\lambda,\alpha)\)),并与“用同一层 CV 同时选模与估误差”的做法比较误差估计偏差。
选取一家长三角上市公司,使用其财务/估值/成交量等特征构造高维特征集(\(p\) 可大于样本数 \(n\))。比较 Lasso 的变量选择是否稳定:
- 方案 A:一次性 Lasso
- 方案 B:stability selection(重复抽样 + 选择频率阈值)
7.7.3 理论题
- 推导岭回归闭式解,并说明其与最小二乘解的关系:
\[ \hat\beta^{\text{ridge}}(\lambda)=\arg\min_\beta \|y-X\beta\|_2^2+\lambda\|\beta\|_2^2. \]
在“正交设计”情形(\(X^\top X=I\))下,说明 Lasso 的解等价于对最小二乘系数做 soft-thresholding,并写出阈值化公式。
解释为什么选择(selection)发生在数据之后时,直接对被选中的系数做经典 t 检验会产生偏乐观结论。用一句话概括 post-selection inference 要修正的核心偏差。
7.8 练习参考解答
7.8.1 概念题参考解答
本质差异:岭回归用 \(\ell_2\) 惩罚,倾向于把所有系数一起收缩但通常不会压到 0;Lasso 用 \(\ell_1\) 惩罚,几何上可与坐标轴“角点”相交,因此更容易产生稀疏解(部分系数恰为 0),从而具备变量选择效果。
必须标准化的原因:正则化对系数大小施加惩罚。如果自变量量纲不同(例如“市值(亿元)”与“换手率(%)”),未标准化会让大尺度变量在同样的系数变化下导致更大预测变化,从而在优化中被“不公平”地偏好或惩罚。标准化后,惩罚在各维上可比较。
自由度直觉:它刻画模型“可调参数的有效数量/灵活度”。岭回归可写成线性平滑器 \(\hat y=S_\lambda y\),其有效自由度常用 \(\mathrm{df}(\lambda)=\mathrm{tr}(S_\lambda)\)。当 \(\lambda\uparrow\) 时,收缩更强,\(\mathrm{df}(\lambda)\) 单调下降;当 \(\lambda\downarrow 0\) 时,回到 OLS,\(\mathrm{df}\to p\)(满秩时)。
瓶颈与风险:
- 计算:best subset 的组合数是 \(2^p\),高维时不可行。
- 统计:即便算得出,强搜索也更容易过拟合;若再用同一数据评估误差,会出现明显的乐观偏差。
stability selection 的增量:它把“是否入模”变成“入模频率”的问题:对样本扰动(子抽样/自助法)重复拟合,再看每个变量被选中的比例,从而把一次性 Lasso 的偶然性显式量化,并可用阈值控制假发现(在一定条件下)。
7.8.2 应用题参考解答(流程与模板)
时间切分 + 三种正则化比较
- 目标示例:用因子/财务指标预测下月收益率(回归),或预测“下月是否跑赢基准”(分类)。
- 评估:测试集 \(R^2\)、MAE(回归),或 AUC、Brier score(分类);并报告入选变量集合与系数符号。
# 使用上市公司财务数据进行时间序列交叉验证的正则化回归
import pandas as pd # 数据分析库,提供DataFrame表格结构
import numpy as np # 数值计算库,提供高效数组操作
import os # 操作系统接口,用于跨平台路径处理
from sklearn.model_selection import TimeSeriesSplit # 时间序列专用交叉验证(保证训练集在测试集之前)
from sklearn.preprocessing import StandardScaler # 数据标准化工具,将特征缩放为均值0标准差1
from sklearn.pipeline import Pipeline # 将标准化与建模封装为一体化流水线
from sklearn.linear_model import RidgeCV, LassoCV, ElasticNetCV # 三种正则化模型(含CV)
# ====== 1. 加载本地财务数据 ======
# 根据操作系统自动选择数据路径(Windows vs Linux)
LOCAL_DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台路径
financial_data_path = os.path.join(LOCAL_DATA_DIR, 'stock/financial_statement.h5') # 拼接完整文件路径
financial_df = pd.read_hdf(financial_data_path) # 直接读取本地HDF5文件
# 按季度排序(金融数据严禁随机打乱,否则会导致"未来数据泄露")
financial_df = financial_df.sort_values('quarter') # quarter列格式如'2022q4'
# 筛选2022年年报数据(与本章主体内容使用同一年份)
financial_df = financial_df[financial_df['quarter'] == '2022q4'].copy() # 使用年报数据
# 构造杜邦分析特征(与本章前面的代码保持列名一致)
financial_df['total_equity'] = financial_df['equity_parent_company'] # 提取归母权益financial_df = financial_df[financial_df['total_equity'] > 1e8] # 过滤净资产过低的公司
financial_df['ROE'] = financial_df['net_profit_parent_company'] / financial_df['total_equity'] # 净资产收益率
financial_df = financial_df[(financial_df['ROE'] > -1) & (financial_df['ROE'] < 1)] # 过滤极端ROE
financial_df['Asset_Turnover'] = financial_df['operating_revenue'] / financial_df['total_assets'] # 资产周转率
financial_df['Net_Margin'] = financial_df['net_profit_parent_company'] / financial_df['operating_revenue'] # 净利润率
financial_df['Leverage'] = financial_df['total_assets'] / financial_df['total_equity'] # 权益乘数
financial_df['Debt_Ratio'] = financial_df['total_liabilities'] / financial_df['total_assets'] # 资产负债率
financial_df['Log_Assets'] = np.log(financial_df['total_assets']) # 资产规模的对数
financial_df['Cash_Ratio'] = financial_df['cash_equivalent'] / financial_df['total_assets'] # 现金比率
# 定义特征列表和目标变量
feature_columns = ['Asset_Turnover', 'Net_Margin', 'Leverage', 'Debt_Ratio', 'Log_Assets', 'Cash_Ratio'] # 6个杜邦分析特征
ts_analysis_df = financial_df[['ROE'] + feature_columns].replace([np.inf, -np.inf], np.nan).dropna() # 清洗异常值
financial_features = ts_analysis_df[feature_columns].values # 提取特征矩阵
target_variable = ts_analysis_df['ROE'].values # 提取目标变量(ROE)
# ====== 3. 构建时间序列交叉验证器 ======
# TimeSeriesSplit: 每折都保证训练数据在时间上早于验证数据
# 例如5折:第1折用前20%训练、第2个20%验证;第2折用前40%训练、第3个20%验证,以此类推
time_series_cv = TimeSeriesSplit(n_splits=5) # 5折时间序列交叉验证构建三种正则化模型的管道(Pipeline),并在测试集上评估其表现。
# ====== 4. 构建三种正则化Pipeline ======
# Pipeline将'标准化'和'建模'串联,确保标准化参数只从训练集学习,避免信息泄露
ridge_pipeline = Pipeline([ # 构建岭回归Pipeline:标准化+岭回归串联
('scaler', StandardScaler()), # 步骤1:标准化
('model', RidgeCV(alphas=[1e-3,1e-2,1e-1,1,10,100], cv=time_series_cv)) # 步骤2:岭回归+CV
]) # 构建岭回归Pipeline
lasso_pipeline = Pipeline([ # 构建套索回归Pipeline:标准化+Lasso回归串联
('scaler', StandardScaler()), # 步骤1:标准化
('model', LassoCV(alphas=None, cv=time_series_cv, max_iter=20000)) # alphas=None自动搜索λ范围
]) # 构建Lasso Pipeline
# 弹性网 = Ridge + Lasso 的混合,l1_ratio控制两者权重
# l1_ratio=0 等价于Ridge,l1_ratio=1 等价于Lasso
elastic_net_pipeline = Pipeline([ # 构建弹性网Pipeline:标准化+弹性网回归串联
('scaler', StandardScaler()), # 步骤1:标准化
('model', ElasticNetCV(l1_ratio=[.1,.3,.5,.7,.9], cv=time_series_cv, max_iter=20000)) # ElasticNet+CV
]) # 构建弹性网Pipeline
# ====== 5. 时间切分:前80%训练,后20%测试 ======
train_test_split_point = int(len(financial_features) * 0.8) # 使用特征矩阵长度计算分割点
features_train, features_test = financial_features[:train_test_split_point], financial_features[train_test_split_point:] # 拆分特征矩阵
target_train, target_test = target_variable[:train_test_split_point], target_variable[train_test_split_point:] # 拆分目标变量
# ====== 6. 拟合模型并输出最优超参数 ======
ridge_pipeline.fit(features_train, target_train) # 拟合岭回归Pipeline
lasso_pipeline.fit(features_train, target_train) # 拟合套索Pipeline
elastic_net_pipeline.fit(features_train, target_train) # 拟合弹性网Pipeline
# 岭回归选出的最优惩罚参数λ
print('ridge alpha:', ridge_pipeline.named_steps['model'].alpha_) # 输出岭回归最优λ
# Lasso选出的最优惩罚参数λ
print('lasso alpha:', lasso_pipeline.named_steps['model'].alpha_) # 输出Lasso最优λ
# 弹性网选出的最优λ和L1/L2混合比例
print('enet alpha/l1_ratio:', elastic_net_pipeline.named_steps['model'].alpha_, elastic_net_pipeline.named_steps['model'].l1_ratio_) # 输出弹性网参数ridge alpha: 100.0
lasso alpha: 0.0014842138201325466
enet alpha/l1_ratio: 0.012038915889936467 0.1上述嵌套交叉验证的运行结果显示:岭回归选出的最优\(\alpha\)为100(较大的惩罚强度),Lasso选出的最优\(\alpha\)约为0.014(较小但足以产生稀疏解),弹性网的最优\(\alpha\)约为0.113、\(\ell_1\)比例为0.1(即90%的\(\ell_2\)惩罚+10%的\(\ell_1\)惩罚)。弹性网偏向\(\ell_2\)端说明在此数据集上,保留更多变量(岭回归风格)比激进剔除变量(Lasso风格)更有利于预测,但同时保留少量\(\ell_1\)成分有助于轻微的变量筛选。
嵌套 CV 的要点:外层切分只用于评估,内层切分用于选择超参数。对比“非嵌套”方案时,通常会看到非嵌套的误差估计更乐观。
stability selection(示意):重复从训练集做子抽样(例如抽 50% 样本)、每次用 Lasso 拟合并记录入选变量(非零系数),最后统计每个变量入选频率,并按阈值(如 0.6/0.8)筛选。
import numpy as np # 数值计算库
from sklearn.linear_model import Lasso # 导入Lasso回归模型(用于稀疏特征选择)
from sklearn.preprocessing import StandardScaler # 数据标准化工具
# ====== 稳定性选择(Stability Selection)======
# 核心思想:单次 Lasso 拟合的变量选择结果可能不稳定(受样本波动影响大)
# 做法:重复从训练集中随机抽取子样本 → 每次用Lasso选变量 → 统计每个变量被选中的频率
# 只有在多次重复中"稳定"被选中的变量,才被认为是真正重要的特征
random_generator = np.random.default_rng(0) # 固定随机种子,确保结果可复现
# 先在完整训练集上拟合标准化参数,然后对训练集做标准化
feature_scaler = StandardScaler().fit(features_train)
scaled_features_train = feature_scaler.transform(features_train)
regularization_alpha = 0.01 # Lasso的惩罚参数λ(可先用CV选一个合理值,再用于稳定性评估)
bootstrap_repetitions = 200 # 重复抽样次数(次数越多,频率估计越稳定)
bootstrap_subsample_ratio = 0.5 # 每次抽取50%的样本(经验值,平衡稳定性与计算效率)
# 计数器:记录每个特征在200次重复中被Lasso选中(系数≠0)的次数
feature_selection_counts = np.zeros(scaled_features_train.shape[1], dtype=float)
for _ in range(bootstrap_repetitions):
# 无放回地随机抽取50%的训练样本索引
subsample_indices = random_generator.choice(len(scaled_features_train), size=int(len(scaled_features_train)*bootstrap_subsample_ratio), replace=False)
# 在子样本上拟合Lasso(Lasso会自动将不重要特征的系数压缩为0)
lasso_model = Lasso(alpha=regularization_alpha, max_iter=20000)
lasso_model.fit(scaled_features_train[subsample_indices], target_train[subsample_indices])
# 累加:该特征的系数是否非零(非零则被"选中"一次)
feature_selection_counts += (lasso_model.coef_ != 0)
# 计算每个特征的入选频率(0到1之间)
feature_selection_frequencies = feature_selection_counts / bootstrap_repetitions
# 频率≥0.7的特征被认为"稳定入选"(阈值越高越严格,通常取0.6~0.9)
stable_feature_indices = np.where(feature_selection_frequencies >= 0.7)[0]
print("稳定入选变量个数:", len(stable_feature_indices))稳定入选变量个数: 47.8.3 理论题参考解答(推导要点)
- 岭回归闭式解:目标函数
\[ L(\beta)= (y-X\beta)^\top(y-X\beta)+\lambda\beta^\top\beta. \]
对 \(\beta\) 求导并令其为 0:
\[ -2X^\top(y-X\beta)+2\lambda\beta=0\;\Rightarrow\;(X^\top X+\lambda I)\beta=X^\top y, \]
因此
\[ \hat\beta^{\text{ridge}}(\lambda)=(X^\top X+\lambda I)^{-1}X^\top y. \]
当 \(\lambda\to 0\)(且 \(X^\top X\) 可逆)时,回到 OLS:\((X^\top X)^{-1}X^\top y\);当 \(\lambda\uparrow\) 时,解被更强地向 0 收缩。
- 正交设计下的 soft-thresholding:在 \(X^\top X=I\) 时,Lasso
\[ \min_\beta \frac12\|y-X\beta\|_2^2+\lambda\|\beta\|_1 \]
可分解到每个坐标。设 OLS 系数 \(\hat\beta^{\text{ols}}=X^\top y\),则每个分量
\[ \hat\beta_j^{\text{lasso}}=\mathrm{sign}(\hat\beta_j^{\text{ols}})\,(|\hat\beta_j^{\text{ols}}|-\lambda)_+. \]
这解释了 Lasso 的稀疏性:当 \(|\hat\beta_j^{\text{ols}}|\le\lambda\) 时,系数被直接压到 0。
- 选择后推断的偏差:当你先用数据挑出“看起来显著/相关”的变量,再对这些变量做传统检验,相当于条件在“被挑中”这一事件上,会导致 p 值偏小、区间偏窄(选择偏差)。post-selection inference 的核心就是在推断时把“变量是如何被选出来的”也纳入条件与分布校正。