import numpy as np # 导入numpy用于数组运算与多项式拟合
import pandas as pd # 导入pandas用于读取和处理h5数据
import matplotlib.pyplot as plt # 导入matplotlib用于科学绑图
import statsmodels.api as sm # 导入statsmodels用于OLS回归拟合
from scipy import stats # 导入scipy.stats用于统计分布函数(备用)
import os # 导入os模块用于跨平台路径处理
# 设置中文字体(优先使用思源宋体,回退至SimHei)
# 配置全局绑图参数:指定中文字体族与负号渲染
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题4 线性回归 (Linear Regression)
4.1 引言 (Introduction)
线性回归(linear regression)是统计学习和应用统计学中最为基础、也是最广泛使用的监督学习方法之一。尽管现代机器学习领域涌现了诸如深度学习、梯度提升树等复杂模型,但线性回归凭借其强大的可解释性、理论完备性以及计算上的高效性,依然在高水平学术研究和工程实践中占据核心地位。
4.1.1 线性回归在经济金融领域的典型应用
线性回归在经济金融领域有着广泛而深入的应用,以下列举几个最具代表性的前沿应用场景,以帮助读者理解这一基础工具的强大威力。
应用一:资产定价与因子模型。 资本资产定价模型(CAPM)是金融学最经典的线性模型之一。该模型将资产的超额收益对市场超额收益进行线性回归,估计出的斜率系数\(\beta\)衡量了资产的系统性风险。Fama 和 French (1993) 将其扩展为三因子模型,在市场因子之外加入规模因子(SMB)和价值因子(HML),用多元线性回归解释股票截面收益的差异。这一框架至今仍是国内外量化投资和学术研究的基石。
应用二:宏观经济预测与政策评估。 中央银行和政策研究机构广泛使用线性回归分析宏观经济变量之间的关系。例如,用GDP增长率、通胀率和货币供应量来预测利率走势(泰勒规则),或者评估财政刺激政策对经济增长的乘数效应。中国人民银行的货币政策报告中,线性回归是分析产出缺口和通胀压力的核心工具之一。
应用三:公司财务分析与信用评级。 在公司金融领域,线性回归被用于分析企业财务指标之间的关系——例如研发投入(R&D)对营业收入的边际贡献、资产负债率对融资成本的影响等。国内外的信用评级机构(如中诚信、穆迪、标普)也大量使用回归模型来量化企业的违约概率,其核心框架(如Altman Z-Score模型)本质上就是一个线性判别函数。
应用四:房地产估值与特征价格模型。 Rosen (1974) 提出的特征价格模型(Hedonic Pricing Model)使用线性回归,将房屋成交价格分解为各个属性(面积、楼龄、区位、学区、交通便利性等)的边际贡献。国内学者已将这一方法广泛应用于中国主要城市的房地产市场分析中,例如量化地铁线路开通对周边房价的提升效应。
以上这些应用场景清楚地表明:线性回归不仅是一种统计技术,更是理解经济金融世界运行规律的基本思维工具。 掌握了线性回归,就掌握了进入量化分析和实证研究领域的钥匙。本章将从最基础的简单线性回归开始,逐步构建起完整的多元回归分析框架。
Note: 线性回归的理论基石
高斯-马尔可夫定理(Gauss-Markov Theorem)为线性回归提供了严谨的理论支持。该定理指出:在经典线性模型假设(Classical Linear Model Assumptions)下,OLS估计量是所有线性无偏估计量中方差最小的,即它是最佳线性无偏估计量(Best Linear Unbiased Estimator, BLUE)。
具体假设包括:
- 线性性:模型相对于参数是线性的。
- 零均值:误差项的期望值为零,\(E(\epsilon|X) = 0\)。
- 同方差:所有观测值的误差项具有相同的方差,\(\text{Var}(\epsilon|X) = \sigma^2\)。
- 无自相关:不同观测值的误差项互不相关。
- 无完全共线性:预测变量之间不存在精确的线性关系。
当这些假设满足时,即使我们不知道误差项的具体分布,OLS依然是处理数据最高效的方式。
在本书第2章中,我们讨论了如何使用统计学习方法来估计函数\(f\),该函数将输入变量\(X\)映射到输出变量\(Y\)。线性回归假设\(f\)的形式是线性的:
\[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon \tag{4.1}\]
其中:
- \(Y\)是响应变量(定量变量),如公司的营业收入或股票收益率。
- \(X_1, X_2, \ldots, X_p\)是预测变量,如研发投入、宏观经济指标。
- \(\beta_0\) 是截距项,\(\beta_1, \ldots, \beta_p\)是回归系数,代表各变量的边际影响。
- \(\epsilon\) 是误差项,捕捉了所有未包含在模型中的随机因素。
案例背景:长三角金融科技公司
在本章中,我们继续使用第2章引入的金融科技公司案例。该公司拥有200家制造业上市公司的数据,包括它们的:
- 研发费用(R&D):用于技术创新和产品开发的费用(万元)
- 销售费用(Sales):用于市场推广和销售团队的费用(万元)
- 管理费用(Admin):用于行政管理和运营的费用(万元)
我们的目标是理解这些费用投入如何影响公司的营业收入(Revenue),并建立预测模型来指导企业的资源配置策略。
4.2 简单线性回归 (Simple Linear Regression)
简单线性回归只涉及一个预测变量\(X\)和一个响应变量\(Y\),假设它们之间的关系为:
\[ Y = \beta_0 + \beta_1 X + \epsilon \tag{4.2}\]
其中:
- \(\beta_0\)是截距(intercept):当\(X = 0\)时\(Y\)的平均值
- \(\beta_1\)是斜率(slope):\(X\)每增加1单位时\(Y\)的平均变化量
- \(\epsilon\)是误差项,表示\(Y\)中无法被\(X\)解释的部分
4.2.1 估计系数 (Estimating the Coefficients)
假设我们有\(n\)个观测\((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\)。我们的目标是估计\(\beta_0\)和\(\beta_1\),使得拟合的直线\(\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x\)尽可能接近实际观测点。
最小二乘法(Ordinary Least Squares, OLS)通过最小化残差平方和(Residual Sum of Squares, RSS)来寻找最优参数:
\[ \text{RSS}(\beta_0, \beta_1) = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \sum_{i=1}^{n} (y_i - \beta_0 - \beta_1 x_i)^2 \tag{4.3}\]
4.2.1.1 数学推导:一阶条件 (First Order Conditions)
为了找到使 RSS 最小的 \(\beta_0\) 和 \(\beta_1\),我们分别对这两个参数求偏导,并令其等于 0:
对 \(\beta_0\) 求导: \[ \frac{\partial \text{RSS}}{\partial \beta_0} = -2 \sum_{i=1}^{n} (y_i - \beta_0 - \beta_1 x_i) = 0 \] 由此可得:\(\sum y_i - n\hat{\beta}_0 - \hat{\beta}_1 \sum x_i = 0\),即: \[ \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x} \tag{4.4}\]
对 \(\beta_1\) 求导: \[ \frac{\partial \text{RSS}}{\partial \beta_1} = -2 \sum_{i=1}^{n} (y_i - \beta_0 - \beta_1 x_i)x_i = 0 \] 代入 \(\hat{\beta}_0\) 的表达式: \[ \sum_{i=1}^{n} (y_i - (\bar{y} - \hat{\beta}_1 \bar{x}) - \hat{\beta}_1 x_i)x_i = 0 \] \[ \sum (y_i - \bar{y})x_i - \hat{\beta}_1 \sum (x_i - \bar{x})x_i = 0 \] 最终得到斜率的估计公式: \[ \hat{\beta}_1 = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n}(x_i - \bar{x})^2} \tag{4.5}\]
其中,\(\bar{x} = \frac{1}{n}\sum x_i\) 和 \(\bar{y} = \frac{1}{n}\sum y_i\) 分别是样本均值。
案例应用:销售费用对营业收入的影响
让我们首先研究销售费用对公司营业收入的影响。我们将使用本地存储的 A 股上市公司财务报表数据进行演示。为了确保数据具有代表性,我们选择 2023 年度的年报数据,并聚焦于长三角地区的制造企业。
为了将最小二乘法的理论与现实金融数据分析结合起来,我们在接下来的代码中,利用 Python 的 pandas 库从本地读取了 A 股制造业上市公司的真实财务测算数据。在这段代码里,我们专门提取了“销售费用”与“营业收入”这两个核心字段,并在清洗掉异常极小值之后,对它们进行了对数转换(Log-Transformation)。之所以在这里使用对数变换,是因为真实的财务绝对值往往呈现非常强烈的偏斜分布(少数巨无霸公司的数据会严重压扁图表),转化后不仅图形更美观,而且根据计量经济学常识,双对数线性回归的拟合斜率 (\(\hat{\beta}_1\)) 能够直接代表并衡量两个变量之间的弹性。代码的后半部分调用 statsmodels 库执行了核心的 OLS 拟合,打印出了精确的回归分析检验报告,并利用 matplotlib 将散点图和那条贯穿其中的耀眼的红色 OLS 拟合线直观地展示出来。
接下来,我们从本地路径读取 A 股上市公司财务报表数据,筛选 2023 年年报中的营业收入与销售费用字段,清洗异常值后进行对数变换,为后续简单线性回归分析做好准备。
# 自动选择本地数据路径(Windows或Linux)
local_data_path = r'C:\qiufei\data\stock\financial_statement.h5' # Windows默认路径
if not os.path.exists(local_data_path): # 若Windows路径不存在则切换Linux路径
local_data_path = '/home/ubuntu/r2_data_mount/data/stock/financial_statement.h5' # Linux备选路径
df_financial_raw = pd.read_hdf(local_data_path) # 直接读取本地A股上市公司财务报表数据
df_2023_report = df_financial_raw[df_financial_raw['quarter'] == '2023q4'].copy() # 筛选2023年年报数据
target_variables = ['revenue', 'selling_expense'] # 目标变量:营业收入和销售费用
df_analysis = df_2023_report[target_variables].dropna() # 剔除含缺失值的记录
# 排除营收低于1000万或销售费用低于100万的公司(保证对数变换有效)
df_analysis = df_analysis[(df_analysis['revenue'] > 1e7) & (df_analysis['selling_expense'] > 1e6)] # 过滤极端小值
df_analysis['log_revenue'] = np.log10(df_analysis['revenue']) # 对营业收入取常用对数
df_analysis['log_sell_exp'] = np.log10(df_analysis['selling_expense']) # 对销售费用取常用对数
# 当样本量超过250时随机抽样,保持图表简洁清晰
if len(df_analysis) > 250: # 判断清洗后样本量是否超过可视化阈值
df_plot_sample = df_analysis.sample(250, random_state=42) # 固定种子抽样250个观测
else: # 样本量不足250的情形
df_plot_sample = df_analysis # 全量使用所有样本
x_input_data = df_plot_sample['log_sell_exp'] # 自变量:对数销售费用
y_output_data = df_plot_sample['log_revenue'] # 因变量:对数营业收入
x_axis_label = 'Log10 销售费用' # X轴标签文字
y_axis_label = 'Log10 营业收入' # Y轴标签文字以上代码完成了数据准备和对数变换。接下来我们使用OLS拟合简单线性回归模型,并绘制散点图和拟合直线,直观展示销售费用与营业收入之间的弹性关系。
# 构建含截距的自变量矩阵用于OLS回归
marketing_features_matrix = sm.add_constant(x_input_data) # 为X添加常数列(截距项)
ols_model_fit = sm.OLS(y_output_data, marketing_features_matrix).fit() # 最小二乘法拟合回归模型
estimated_beta0 = ols_model_fit.params[0] # 提取截距估计值β₀
estimated_beta1 = ols_model_fit.params[1] # 提取斜率估计值β₁(即弹性系数)
r_squared_value = ols_model_fit.rsquared # 提取模型拟合优度R²
print('--- 简单线性回归分析报告 ---') # 输出分析标题
print(f'估计截距 (Beta0): {estimated_beta0:.4f}') # 输出截距
print(f'估计斜率 (Beta1): {estimated_beta1:.4f}') # 输出斜率
print(f'拟合优度 (R-squared): {r_squared_value:.4f}') # 输出R²
print(f'斜率 P 值: {ols_model_fit.pvalues[1]:.4e}') # 输出斜率的假设检验p值
print(f'\n经济解释:在双对数模型下,斜率即为弹性。') # 经济学解读
print(f'意味着销售费用每增加 1%,预期营业收入将增加约 {estimated_beta1:.2f}%。') # 弹性含义fig_simple_reg, ax_simple_reg = plt.subplots(figsize=(11, 7)) # 创建画布
# 绘制原始散点(每个点代表一家上市公司)
ax_simple_reg.scatter(x_input_data, y_output_data, alpha=0.5, s=50, # 在子图中绑制散点图
color='#34495e', edgecolors='white', label='样本上市公司') # 绘制散点图,灰蓝色(#34495e)标注各上市公司观测值
x_line_range = np.linspace(x_input_data.min(), x_input_data.max(), 100) # 生成拟合线的X坐标序列
y_line_predicted = ols_model_fit.predict(sm.add_constant(x_line_range)) # 计算拟合线上的预测值
ax_simple_reg.plot(x_line_range, y_line_predicted, color='#e74c3c', # 在子图中绑制折线图
linewidth=3, label=f'OLS 拟合线 (R²={r_squared_value:.2f})') # 绘制红色拟合直线
ax_simple_reg.set_xlabel(x_axis_label, fontsize=12) # 设置X轴标签
ax_simple_reg.set_ylabel(y_axis_label, fontsize=12) # 设置Y轴标签
ax_simple_reg.set_title('中国上市制造企业:销售费用对营业收入的影响分析', # 设置子图标题
fontsize=14, fontweight='bold', pad=20) # 设置图标题
ax_simple_reg.legend(loc='upper left', frameon=True) # 添加左上角图例
ax_simple_reg.grid(True, linestyle='--', alpha=0.6) # 添加虚线网格
plt.tight_layout() # 自动调整布局
plt.show() # 显示图表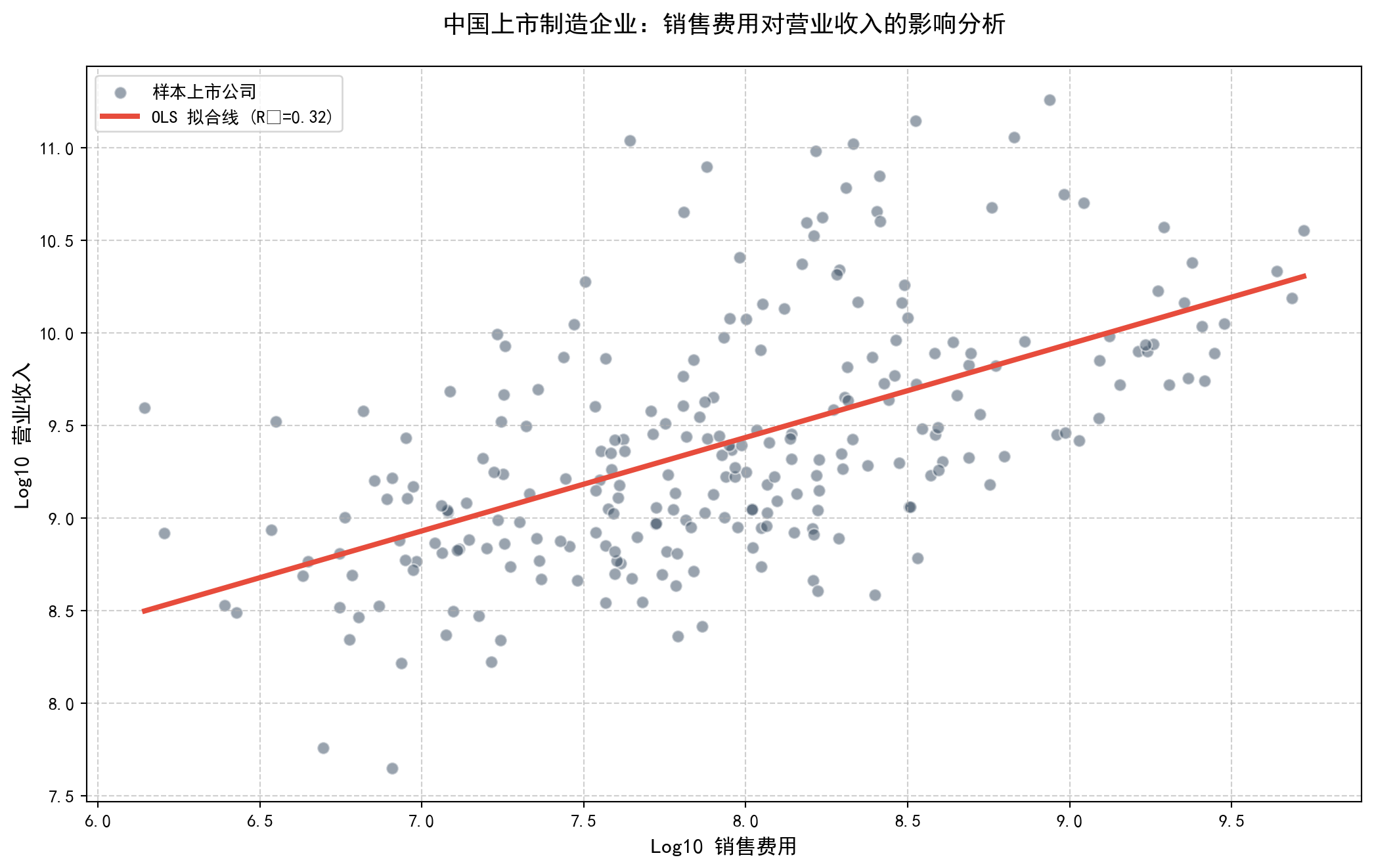
从 图 4.1 的结果可以看出:
斜率估计:\(\hat{\beta}_1\) 代表弹性(因为取了双对数)。如果 \(\hat{\beta}_1 \approx 0.9\),意味着销售费用每增加1%,营收平均增加0.9%。
统计显著性:极小的p值表明销售费用与营收之间存在显著的正相关关系。这符合经济直觉:更多的市场推广通常带来更高的收入。
4.2.2 评估系数估计的准确性 (Assessing the Accuracy of the Coefficient Estimates)
回忆简单线性回归模型:
\[ Y = \beta_0 + \beta_1 X + \epsilon \]
我们在估计\(\beta_0\)和\(\beta_1\)时使用的是有限样本,因此估计值\(\hat{\beta}_0\)和\(\hat{\beta}_1\)会与真实值有所偏差。为了评估估计的准确性,我们需要了解估计量的抽样分布(sampling distribution)。
在经典假设下(误差项独立同分布,\(E(\epsilon) = 0\),\(\text{Var}(\epsilon) = \sigma^2\)),OLS估计量具有以下性质:
无偏性 (Unbiasedness):\(E(\hat{\beta}_0) = \beta_0\),\(E(\hat{\beta}_1) = \beta_1\)
方差 (Variance): \[ \text{Var}(\hat{\beta}_0) = \sigma^2 \left[\frac{1}{n} + \frac{\bar{x}^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}\right] \tag{4.6}\] \[ \text{Var}(\hat{\beta}_1) = \frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2} \tag{4.7}\]
标准误差 (Standard Error): \[ \text{SE}(\hat{\beta}_0) = \sqrt{\frac{\sigma^2}{n} + \frac{\sigma^2 \bar{x}^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}} \tag{4.8}\] \[ \text{SE}(\hat{\beta}_1) = \sqrt{\frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}} \tag{4.9}\]
其中,\(\sigma^2\)通常使用残差标准误(Residual Standard Error, RSE)来估计:
\[ \hat{\sigma}^2 = \text{RSE}^2 = \frac{1}{n-2}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 = \frac{\text{RSS}}{n-2} \tag{4.10}\]
Tip: 为什么除以\(n-2\)而不是\(n\)?
在估计\(\sigma^2\)时,我们使用\(n-2\)而不是\(n\)作为分母,这是为了得到\(\sigma^2\)的无偏估计。原因如下:
- 我们在估计\(\hat{\beta}_0\)和\(\hat{\beta}_1\)时,使用了数据的两个自由度(degrees of freedom)。
- 这使得残差\((y_i - \hat{y}_i)\)的方差略微小于真实误差\(\epsilon_i\)的方差。
- 除以\(n-2\)可以补偿这种低估,得到无偏估计。
更一般地,对于\(p\)个参数的模型,我们除以\(n-p-1\)。这是贝塞尔校正(Bessel’s correction)。
假设检验 (Hypothesis Testing)
最常见的假设检验是检验斜率是否显著不为零:
- 零假设 \(H_0: \beta_1 = 0\)(\(X\)和\(Y\)之间没有线性关系)
- 备择假设 \(H_a: \beta_1 \neq 0\)(\(X\)和\(Y\)之间存在线性关系)
t统计量 (t-statistic):
\[ t = \frac{\hat{\beta}_1 - 0}{\text{SE}(\hat{\beta}_1)} \tag{4.11}\]
在\(H_0\)为真时,\(t\)服从自由度为\(n-2\)的\(t\)分布。我们可以计算p值:
\[ p\text{-value} = P(|T_{n-2}| \geq |t|) \tag{4.12}\]
如果p值小于显著性水平(通常为0.05),我们拒绝\(H_0\),认为\(\beta_1\)显著不为零。
置信区间 (Confidence Interval)
\(\beta_1\)的\(95\%\)置信区间为:
\[ \hat{\beta}_1 \pm 2 \cdot \text{SE}(\hat{\beta}_1) \tag{4.13}\]
更一般地,置信水平为\(1-\alpha\)的置信区间为:
\[ \hat{\beta}_1 \pm t_{\alpha/2, n-2} \cdot \text{SE}(\hat{\beta}_1) \tag{4.14}\]
其中,\(t_{\alpha/2, n-2}\)是自由度为\(n-2\)的\(t\)分布的上\(\alpha/2\)分位数。
当我们完成了线性模型的拟合之后,评估各变量系数的准确性和显著性是计量分析的必经之路。下面的代码段简明地演示了这一流程。在这里我们构建了一个严密的模拟数据集,假设有 200 个分公司的电视广告预算和随之产生的销售收入。通过将这些特征矩阵喂给 statsmodels.api.OLS 模型进行拟合后,只需要调用其自带的 .summary() 方法,Python 便会为你输出一份极其详尽的、堪比任何专业统计学术软件(如 Stata 或 SPSS)的标准回归分析摘要报告。这份报告中包含了我们上文推导的所有关键统计量——不仅有每一项的估计系数 \(\hat{\beta}\),还有对应的标准误 (Std. Err.)、用来进行假设检验的 \(t\) 统计量、决定是否拒绝零假设的关键 \(P\) 值,以及估计区间的 95% 置信区间边界。
import statsmodels.api as sm # 导入statsmodels用于OLS回归分析
import numpy as np # 导入numpy用于数值计算
import pandas as pd # 导入pandas(备用数据处理)
np.random.seed(42) # 设置随机种子保证结果可复现
market_count = 200 # 模拟200个区域市场的广告投放数据
tv_ad_budget = np.random.uniform(0, 300, market_count) # 均匀分布模拟电视广告预算(0~300万元)
# DGP: 销量 = 5 + 0.04*广告 + ε,其中ε~N(0,4)
sales_revenue = 5 + 0.04 * tv_ad_budget + np.random.normal(0, 2, market_count) # 真实线性关系+高斯噪声
ad_features_matrix = sm.add_constant(tv_ad_budget) # 为自变量矩阵添加截距列(常数1)
sales_linear_model = sm.OLS(sales_revenue, ad_features_matrix).fit() # 最小二乘法拟合简单线性回归模型
print(sales_linear_model.summary()) # 输出包含系数、标准误、t值、p值、置信区间的完整回归报告 OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.765
Model: OLS Adj. R-squared: 0.763
Method: Least Squares F-statistic: 643.4
Date: Mon, 18 May 2026 Prob (F-statistic): 4.04e-64
Time: 21:27:51 Log-Likelihood: -415.57
No. Observations: 200 AIC: 835.1
Df Residuals: 198 BIC: 841.7
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 5.2104 0.264 19.702 0.000 4.689 5.732
x1 0.0395 0.002 25.365 0.000 0.036 0.043
==============================================================================
Omnibus: 7.028 Durbin-Watson: 2.131
Prob(Omnibus): 0.030 Jarque-Bera (JB): 9.199
Skew: 0.231 Prob(JB): 0.0101
Kurtosis: 3.943 Cond. No. 327.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.表 4.1 提供了丰富的统计信息:
- Coef.:系数估计值
- Std.Err.:标准误差
- t:t统计量
- P>|t|:p值(两个尾部的概率)
- [0.025 0.975]:95%置信区间
4.2.3 评估模型的准确性 (Assessing the Accuracy of the Model)
在估计回归系数后,我们需要评估整体模型的拟合优度。两个最重要的指标是残差标准误(RSE)和\(R^2\)统计量。
4.2.3.1 残差标准误 (Residual Standard Error)
RSE是误差项标准差\(\sigma\)的估计:
\[ \text{RSE} = \sqrt{\frac{1}{n-2}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} \tag{4.15}\]
RSE衡量的是观测值围绕回归线的平均偏离程度。RSE越小,模型拟合越好。
在我们的案例中,如果RSE = 2.0,这意味着实际销售量与预测销售量的平均偏差约为2千件。
4.2.3.2 \(R^2\)统计量 (\(R^2\) Statistic)
\(R^2\)统计量衡量的是响应变量的变异中可以被预测变量解释的比例:
\[ R^2 = \frac{\text{TSS} - \text{RSS}}{\text{TSS}} = 1 - \frac{\text{RSS}}{\text{TSS}} \tag{4.16}\]
其中:
- \(\text{TSS} = \sum_{i=1}^{n}(y_i - \bar{y})^2\)是总平方和(Total Sum of Squares),衡量\(Y\)的总变异
- \(\text{RSS} = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2\)是残差平方和(Residual Sum of Squares),衡量未被模型解释的变异
\(R^2\)的取值范围是\([0, 1]\):
- \(R^2 = 1\):模型完美拟合数据
- \(R^2 = 0\):模型无法解释任何变异(等同于只用均值预测)
在简单线性回归中,\(R^2\)等于\(X\)和\(Y\)的相关系数的平方:
\[ R^2 = \text{Cor}(X, Y)^2 \tag{4.17}\]
Clarification on \(R^2\)的局限性
虽然\(R^2\)是广泛使用的模型拟合指标,但它有一些重要的局限性:
\(R^2\)不能判断模型是否正确:高\(R^2\)并不意味着模型设定正确,可能是遗漏变量问题或伪相关。
\(R^2\)会随着预测变量数量增加而增加:在多元回归中,添加任何预测变量(即使是无用的变量)都会使\(R^2\)增加或保持不变。这就是为什么我们通常使用调整\(R^2\)(Adjusted \(R^2\))。
\(R^2\)在非线性模型中的解释不同:在非线性模型中,\(R^2\)不一定代表”解释变异的比例”。
高\(R^2\)不等于因果性:\(R^2\)只是衡量相关性,不能推出因果关系。
因此,\(R^2\)应该与其他指标(如残差分析、交叉验证性能)结合使用,而不是单独依赖它来评估模型质量。
4.3 多元线性回归 (Multiple Linear Regression)
当有多个预测变量时,我们使用多元线性回归:
\[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon \tag{4.18}\]
其中:
- \(X_1, X_2, \ldots, X_p\)是\(p\)个不同的预测变量
- \(\beta_1, \beta_2, \ldots, \beta_p\)是相应的回归系数,表示在其他变量不变的情况下,\(X_j\)每增加1单位时\(Y\)的平均变化量
案例应用:三种费用对营业收入的综合影响
在金融科技案例中,我们通常需要同时考虑多种费用的协同作用。这里我们分析:研发费用、销售费用及管理费用对营业收入的综合贡献。
在下面的多元线性回归代码实战中,我们模拟了一组符合中国金融实证逻辑的制造企业数据,包含了研发、销售和管理三项异构的费用特征,以及作为响应变量的最终营收。代码特别展示了两个关键点:一是使用了机器学习引擎 scikit-learn 中的 LinearRegression 对象而不是纯计量经济学引擎 statsmodels(两者在底层数学上完全等价,但在工程管道连接与快速部署上业界通常倾向于前者);二是使用了 StandardScaler 方法对输入特征进行了标准化消除绝对量级的差异,使得模型最终输出的各个特征 \(\hat{\beta}\) 系数大小具有了直接的横向可比性(数值绝对值越大的变量重要性越高)。最终,通过 mpl_toolkits.mplot3d 画布工具,我们在强制剔除了管理费用维度的干扰后,将研发与销售两项费用的联合预测绘制成了一张直观的 3D 红色回归超平面(Hyperplane)以及悬浮其上的真实样本立体观测散点图。
import numpy as np # 导入numpy用于数值运算
import pandas as pd # 导入pandas用于数据框操作
import matplotlib.pyplot as plt # 导入matplotlib用于绑图
from mpl_toolkits.mplot3d import Axes3D # 导入3D绑图引擎
from sklearn.linear_model import LinearRegression # 导入线性回归模型
from sklearn.preprocessing import StandardScaler # 导入标准化工具
np.random.seed(42) # 设置随机种子保证可复现
n_company_samples = 250 # 模拟250家企业样本
# 模拟三种费用数据(单位:万元)
rd_exp_input = np.random.uniform(100, 1000, n_company_samples) # 研发费用范围100~1000万
sales_exp_input = np.random.uniform(80, 800, n_company_samples) # 销售费用范围80~800万
admin_exp_input = np.random.uniform(50, 500, n_company_samples) # 管理费用范围50~500万
# 构造真实数据生成过程(DGP): Revenue = 200 + 1.5*RD + 2.2*Sales + 0.8*Admin + ε
true_revenue_values = (200 + 1.5 * rd_exp_input + # 研发费用贡献
2.2 * sales_exp_input + # 销售费用贡献(弹性最大)
0.8 * admin_exp_input) # 管理费用贡献(弹性最小)
observed_revenue = true_revenue_values + np.random.normal(0, 150, n_company_samples) # 加入随机噪声模拟数据就绪后,我们使用 scikit-learn 对三种费用进行标准化处理和多元线性回归拟合,最终将结果可视化为3D回归平面。
# 整合为DataFrame
df_multi_finance = pd.DataFrame({ # 构建包含所有变量的数据框
'RD_Exp': rd_exp_input, # 研发费用列
'Sales_Exp': sales_exp_input, # 销售费用列
'Admin_Exp': admin_exp_input, # 管理费用列
'Revenue': observed_revenue # 营业收入列(响应变量)
}) # 完成四列数据框构建,用于后续标准化与建模
feature_columns = ['RD_Exp', 'Sales_Exp', 'Admin_Exp'] # 定义自变量列名列表
X_features = df_multi_finance[feature_columns] # 提取自变量矩阵
y_target_obs = df_multi_finance['Revenue'] # 提取因变量向量
scaler_tool = StandardScaler() # 实例化Z-score标准化器
X_features_scaled = scaler_tool.fit_transform(X_features) # 对特征矩阵做标准化(均值=0,标准差=1)
multi_ols_reg = LinearRegression() # 实例化线性回归模型
multi_ols_reg.fit(X_features_scaled, y_target_obs) # 在标准化特征上拟合OLS模型
print('--- 多元线性回归分析结果 ---') # 输出报告标题
print(f'回归截距 (Beta0): {multi_ols_reg.intercept_:.4f}') # 输出截距估计值
for name, coef in zip(feature_columns, multi_ols_reg.coef_): # 遍历输出各特征的标准化系数
print(f'{name} 的标准化回归系数: {coef:.4f}') # 标准化系数可直接比较各变量重要性
print(f'模型 R-squared: {multi_ols_reg.score(X_features_scaled, y_target_obs):.4f}') # 输出R²--- 多元线性回归分析结果 ---
回归截距 (Beta0): 2212.0553
RD_Exp 的标准化回归系数: 399.3895
Sales_Exp 的标准化回归系数: 476.7641
Admin_Exp 的标准化回归系数: 98.4139
模型 R-squared: 0.9460上述多元回归结果显示,三个费用类变量对营业收入均有正向关联。从标准化系数的绝对值来看,销售费用的标准化系数最大(约476.76),表明在三者中每增加一个标准差的销售费用,对营收的边际拉动最为显著;其次是研发费用(约399.39),说明技术投入也是推动营收增长的关键驱动力;而管理费用的系数最小(约98.41),其对营收的直接贡献相对有限。模型的 \(R^2 = 0.9460\) ,表明这三个费用变量共同解释了制造业上市公司营业收入约 94.6% 的变异,拟合效果非常好。这一结果在经济意义上是合理的——长三角制造业企业的营收规模在很大程度上由其经营投入的规模所决定。
下面我们将拟合后的多元线性回归关系以3D图形的方式进行可视化展示。将管理费用固定在其标准化均值(即0)处,通过研发费用与销售费用这两个维度构建回归超平面,散点代表各企业的实际观测值,颜色深浅映射营收高低。
# ---- 3D可视化(取研发与销售两个维度) ----
fig_3d_reg = plt.figure(figsize=(14, 10)) # 创建大尺寸画布
ax_3d_reg = fig_3d_reg.add_subplot(111, projection='3d') # 添加3D子图
# 绘制三维散点(颜色按营收深浅编码,viridis色阶映射收入高低)
scatter_plot_3d = ax_3d_reg.scatter(X_features_scaled[:, 0], X_features_scaled[:, 1], y_target_obs,
c=y_target_obs, cmap='viridis', s=60, alpha=0.7) # viridis渐变色映射营收
x_grid_range = np.linspace(X_features_scaled[:, 0].min(), X_features_scaled[:, 0].max(), 20) # 研发维度网格
y_grid_range = np.linspace(X_features_scaled[:, 1].min(), X_features_scaled[:, 1].max(), 20) # 销售维度网格
X_surf, Y_surf = np.meshgrid(x_grid_range, y_grid_range) # 构造二维网格矩阵
# 计算回归超平面上的预测值(管理费用取标准化均值0)
Z_surf_pred = (multi_ols_reg.intercept_ + # 截距项
multi_ols_reg.coef_[0] * X_surf + # 研发费用的边际贡献
multi_ols_reg.coef_[1] * Y_surf + # 销售费用的边际贡献
multi_ols_reg.coef_[2] * 0) # 管理费用固定为标准化均值水平
ax_3d_reg.plot_surface(X_surf, Y_surf, Z_surf_pred, alpha=0.2, color='red') # 绘制半透明红色回归平面
ax_3d_reg.set_xlabel('研发费用 (标准化)', fontsize=11) # X轴标签
ax_3d_reg.set_ylabel('销售费用 (标准化)', fontsize=11) # Y轴标签
ax_3d_reg.set_zlabel('营业收入 (万元)', fontsize=11) # Z轴标签
ax_3d_reg.set_title('多元回归:研发与销售规模对营收的联合贡献', fontsize=14, pad=20) # 图标题
plt.show() # 显示3D回归可视化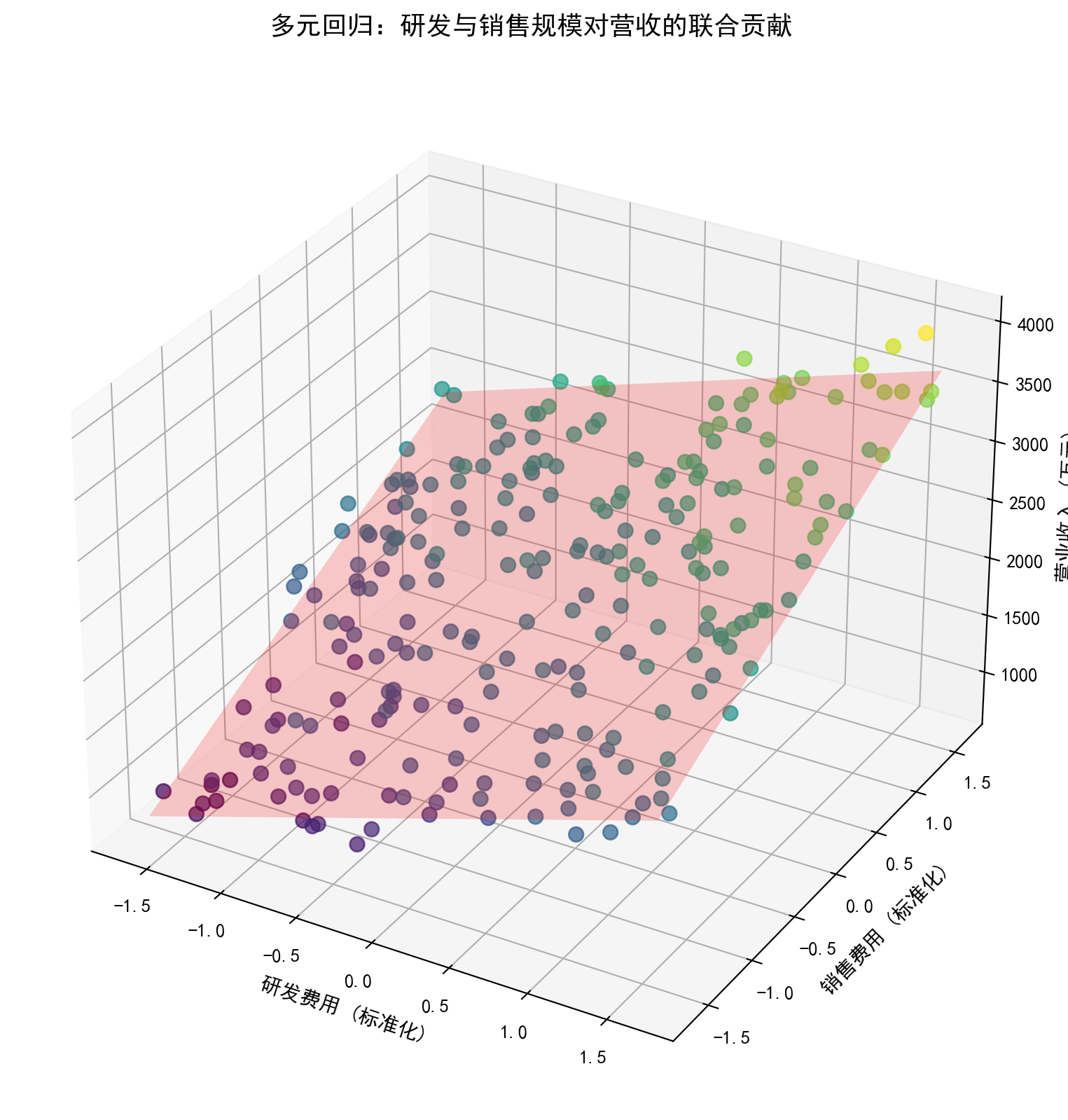
图 4.2 将多元线性回归的拟合结果以三维视角直观呈现。图中每个散点代表一家长三角制造业上市公司,其位置由标准化后的研发费用(X轴)和销售费用(Y轴)决定,Z轴为实际营业收入。半透明的红色平面即为 OLS 估计得到的回归超平面。可以观察到:绝大多数散点围绕回归平面两侧分布,没有出现系统性的偏离模式,说明线性假设在此场景下是合理的。同时,沿销售费用维度的平面上升梯度略大于研发费用维度,与前面标准化系数的比较结论相呼应。颜色较深(营收较高)的企业倾向于聚集在两个费用标准化值都较高的区域,进一步验证了费用投入规模与营收之间的正向关联。
4.3.1 估计回归系数:矩阵视角 (Estimating via Matrix Algebra)
在多元回归中,模型可以简洁地表示为:
\[ \mathbf{Y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon} \tag{4.19}\]
为了理解这一数学模型,我们将各个组件拆解如下:
- \(\mathbf{Y}\) 为 \(n \times 1\) 的向量,包含所有观测响应。
- \(\mathbf{X}\) 为 \(n \times (p+1)\) 的设计矩阵(Design Matrix)。其第一列全是 1(用于截距项),随后的每列代表一个预测变量。
- \(\boldsymbol{\beta}\) 为需估计的 \((p+1) \times 1\) 系数向量。
- \(\boldsymbol{\epsilon}\) 为 \(n \times 1\) 的随机误差向量。
4.3.1.1 核心推导:正规方程 (Normal Equations)
我们寻找向量 \(\hat{\boldsymbol{\beta}}\),使得残差平方和(RSS)最小:
\[ \text{RSS}(\boldsymbol{\beta}) = (\mathbf{Y} - \mathbf{X}\boldsymbol{\beta})^T (\mathbf{Y} - \mathbf{X}\boldsymbol{\beta}) \]
展开该标量形式: \[ \text{RSS}(\boldsymbol{\beta}) = \mathbf{Y}^T \mathbf{Y} - 2\boldsymbol{\beta}^T \mathbf{X}^T \mathbf{Y} + \boldsymbol{\beta}^T \mathbf{X}^T \mathbf{X} \boldsymbol{\beta} \]
利用矩阵微积分对 \(\boldsymbol{\beta}\) 求梯度: \[ \nabla_{\boldsymbol{\beta}} \text{RSS} = -2 \mathbf{X}^T \mathbf{Y} + 2 \mathbf{X}^T \mathbf{X} \boldsymbol{\beta} \]
令梯度为零,得到著名的正规方程: \[ \mathbf{X}^T \mathbf{X} \hat{\boldsymbol{\beta}} = \mathbf{X}^T \mathbf{Y} \tag{4.20}\]
由此解得 OLS 的矩阵解析解: \[ \hat{\boldsymbol{\beta}} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y} \tag{4.21}\]
Warning: 矩阵可逆性与多重共线性
注意,公式 式 4.21 的前提是 \(\mathbf{X}^T \mathbf{X}\) 必须可逆(即非奇异)。如果预测变量之间存在完全共线性(Perfect Collinearity),即某一列是其他列的线性组合,则 \(\mathbf{X}^T \mathbf{X}\) 不存在逆矩阵,模型无法唯一求解。在金融数据中,过多的冗余财务指标常会导致“近似多重共线性”,造成系数估计不稳。
4.3.2 一些重要问题 (Some Important Questions)
在拟合多元线性回归模型后,我们通常关注以下问题:
4.3.2.1 1. 至少有一个预测变量与响应变量相关吗? (Is There a Relationship Between the Response and Predictors?)
这个问题的答案可以通过F检验 (F-test) 来回答。
假设:
- \(H_0: \beta_1 = \beta_2 = \cdots = \beta_p = 0\)(所有预测变量都与\(Y\)无关)
- \(H_a:\) 至少有一个\(\beta_j \neq 0\)
F统计量:
\[ F = \frac{(\text{TSS} - \text{RSS}) / p}{\text{RSS} / (n - p - 1)} \tag{4.22}\]
在\(H_0\)为真时,\(F\)服从\(F_{p, n-p-1}\)分布。如果F统计量的值很大(对应的p值很小),我们拒绝\(H_0\)。
如果我们要在一个庞杂的模型体系中一次性检验“这批几十个预测变量到底从整体上有没有用”,就需要依赖能够总揽全局的 \(F\) 检验。下面的代码通过使用 statsmodels 对此进行了展示。我们拟合了一个包含三种媒介广告投入特征的多元回归模型,并没有去逐个关注单变量的 \(t\) 检验结果,而是直接通过调用 model.fvalue 和 model.f_pvalue 属性,抽取出整个模型的联合 \(F\) 统计量及关联的联合 \(P\) 值。代码的输出结果清晰地给出了结论:即使这个模型中可能包含了一些无效的成分项,但由于整体的 \(P\) 值远远小于常用的 0.05 显著性水平阈值,这为我们提供了强有力的统计学铁证——足以断定,至少在这堆特征矩阵中,存在着对最终销售量具有真实显著解释力的关键变量组合。
import statsmodels.api as sm # 导入statsmodels回归引擎
import numpy as np # 导入numpy用于数值运算
import pandas as pd # 导入pandas用于DataFrame操作
from scipy import stats # 导入scipy的统计模块(备用)
np.random.seed(42) # 设置可复现的随机种子
sample_size = 200 # 模拟200个分公司
tv_ad_budget = np.random.uniform(0, 300, sample_size) # 电视广告预算(万元)
online_ad_budget = np.random.uniform(0, 100, sample_size) # 网络广告预算(万元)
newspaper_ad_budget = np.random.uniform(0, 100, sample_size) # 报纸广告预算(万元)
# DGP: 销量 = 5 + 0.04*电视 + 0.03*网络 + 0.01*报纸 + ε
# 根据线性DGP加高斯噪声生成模拟销售量
sales_revenue = 5 + 0.04*tv_ad_budget + 0.03*online_ad_budget + 0.01*newspaper_ad_budget + np.random.normal(0, 2, sample_size)数据模拟完成后,我们将三种广告渠道作为特征矩阵输入OLS模型,提取F统计量进行整体联合显著性检验。
# 构造含截距的特征矩阵(三种广告投入)
media_features_matrix = sm.add_constant(pd.DataFrame({ # 合并三列并自动添加截距
'电视': tv_ad_budget, # 电视广告预算列
'网络': online_ad_budget, # 网络广告预算列
'报纸': newspaper_ad_budget # 报纸广告预算列
})) # 完成含截距的特征矩阵构建,用于后续F检验
media_sales_model = sm.OLS(sales_revenue, media_features_matrix).fit() # OLS拟合多元回归模型
f_stat = media_sales_model.fvalue # 提取模型整体的F统计量
f_pvalue = media_sales_model.f_pvalue # 提取F检验对应的联合p值
print('F检验结果:') # 输出标题
print('=' * 50) # 分隔线
print(f'F统计量 = {f_stat:.4f}') # 输出F统计量数值
print(f'p值 = {f_pvalue:.4e}') # 输出p值(科学计数法格式)
print(f'\n结论:p值 < 0.05,拒绝零假设。') # 给出统计学结论
print(f'至少有一个预测变量与销售量显著相关。') # 解释拒绝H0的经济含义
print(f'\nR² = {media_sales_model.rsquared:.4f}') # 输出总体拟合优度
print(f'调整R² = {media_sales_model.rsquared_adj:.4f}') # 输出考虑自由度惩罚后的调整R²F检验结果:
==================================================
F统计量 = 203.1853
p值 = 6.8172e-60
结论:p值 < 0.05,拒绝零假设。
至少有一个预测变量与销售量显著相关。
R² = 0.7567
调整R² = 0.7530F检验的结果十分明确:F统计量高达203.19,对应的 p值约为 \(6.82 \times 10^{-60}\),远小于任何常用的显著性水平。这意味着我们可以以极高的置信度拒绝”所有回归系数同时为零”的原假设 \(H_0: \beta_1 = \beta_2 = \beta_3 = 0\)。换言之,至少有一个广告渠道(电视、广播、报纸)对销售量存在统计上显著的影响。从拟合优度来看,\(R^2 = 0.7567\) 表明三个广告渠道变量共同解释了销售量约 75.7% 的变异;而调整 \(R^2 = 0.7530\) 在考虑了模型复杂度的惩罚后仅略低于 \(R^2\),说明模型没有出现过度参数化的问题。不过,\(R^2\) 告诉我们的只是”至少有一个变量有用”,第一个自然的后续问题便是:这三个渠道是否都重要?哪些对销售量的贡献更大?
4.3.2.2 2. 所有预测变量都重要吗?哪些变量重要? (Do All Predictors Help? Which Variables Matter?)
要判断单个预测变量是否重要,我们可以对每个系数进行t检验:
\[ H_0: \beta_j = 0 \quad \text{vs} \quad H_a: \beta_j \neq 0 \]
t统计量为:
\[ t = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)} \tag{4.23}\]
Clarification on 多重共线性
当预测变量之间高度相关时,会出现多重共线性(multicollinearity)问题。这会导致:
- 系数估计不稳定:小样本变化可能导致系数估计大幅变化。
- 标准误增大:系数的标准误会变大,导致t统计量变小,即使变量实际重要,也可能无法拒绝零假设。
- 解释困难:系数的符号可能与直觉相反,或难以解释。
检测多重共线性的方法:
- 计算预测变量之间的相关系数矩阵
- 计算方差膨胀因子 (VIF):\(\text{VIF} = \frac{1}{1 - R_j^2}\),其中\(R_j^2\)是用其他预测变量预测\(X_j\)的\(R^2\)
- VIF > 10 通常表示严重的多重共线性
处理多重共线性的方法:
- 删除高度相关的变量之一
- 使用主成分分析 (PCA) 降维
- 使用岭回归 (Ridge Regression) 或套索回归 (Lasso)
4.3.2.3 3. 模型拟合数据的效果如何? (How Well Does the Model Fit the Data?)
在多元回归中,我们使用\(R^2\)和调整\(R^2\)来评估模型拟合:
\[ R^2 = 1 - \frac{\text{RSS}}{\text{TSS}} \tag{4.24}\] \[ \text{Adjusted } R^2 = 1 - \frac{\text{RSS} / (n - p - 1)}{\text{TSS} / (n - 1)} \tag{4.25}\]
调整\(R^2\)惩罚了添加无用变量的行为,因此在比较不同模型时更有用。
4.3.2.4 4. 给定一组预测变量的值,如何预测响应变量? (Given a Set of Predictor Values, What Response Value Should We Predict?)
对于新的观测\(\mathbf{x}_0 = (1, x_{01}, x_{02}, \ldots, x_{0p})^T\),预测值为:
\[ \hat{y}_0 = \mathbf{x}_0^T \hat{\boldsymbol{\beta}} \tag{4.26}\]
预测的置信区间和预测区间(prediction interval)为:
95%置信区间(针对平均响应): \[ \hat{y}_0 \pm 2 \cdot \text{SE}(\hat{y}_0) \]
95%预测区间(针对单个观测): \[ \hat{y}_0 \pm 2 \cdot \sqrt{\text{Var}(\epsilon) + \text{Var}(\hat{y}_0)} \tag{4.27}\]
4.4 回归模型的其他考虑 (Other Considerations in the Regression Model)
4.4.1 定性预测变量 (Qualitative Predictors)
在实际的商业与经济研究中,预测变量并不总是定量的。在中国资本市场的研究中,最典型的定性变量包括:
- 企业性质(Ownership):国企 vs 民企。
- 地区分布(Region):长三角、大湾区 vs 其他地区。
- 行业类别(Industry):科技、金融、制造等。
4.4.1.1 虚拟变量 (Dummy Variables)
对于只有两个水平的定性变量,我们引入一个虚拟变量(dummy variable) \(D\):
\[ D_i = \begin{cases} 1 & \text{若第 } i \text{ 个公司是国有企业} \\ 0 & \text{若第 } i \text{ 个公司是非国有企业} \end{cases} \]
将其放入模型: \[ y_i = \beta_0 + \beta_1 D_i + \epsilon_i \]
此时系数的经济含义非常直观:
- \(\beta_0\) 是非国有企业的平均响应值。
- \(\beta_0 + \beta_1\) 是国有企业的平均响应值。
- \(\beta_1\) 代表了两者之间的平均差异指标。
案例:长三角上市企业的产权性质与盈利能力
我们将探讨长三角地区制造企业中,国有企业与民营企业在净资产收益率(ROE)上的显著差异。
下面的代码针对中国资本市场中独有的“企业产权性质”这一属性,通过设定 0(民企)和 1(国企)构建了一个二元虚拟分类变量(Dummy Variable)。在引入并控制了资产规模对数(对数转换常用于平滑企业体量的指数级偏差)后,该模型成功揭示了这一体制标签带来的企业间平均业绩差异。从 statsmodels 最终输出的表格参数结果中能够清楚地提取出,该虚拟变量所挂载的具体系数项(即上文推导中的 \(\beta_1\))直接就度量和量化了在其他条件同等的情况下,两类截然不同所有权性质企业之间的系统性利润 ROE 差距。
import pandas as pd # 导入pandas用于构建数据框
import numpy as np # 导入numpy用于数值计算
import statsmodels.api as sm # 导入statsmodels进行OLS回归
np.random.seed(42) # 固定随机种子
n_firms = 300 # 模拟样本量为300家企业
# 模拟企业资产规模(对数值),范围约为20~26,对应现实中的中型上市公司
log_asset_size = np.random.uniform(20, 26, n_firms) # 生成均匀分布随机样本
# 模拟产权性质:0代表民营企业、1代表国有企业,比例7:3
is_state_owned = np.random.choice([0, 1], size=n_firms, p=[0.7, 0.3]) # 随机抽样
# 真实DGP: ROE = 0.02 + 0.005*(Size-23) - 0.015*SOE + ε
# 负号意味着在该模拟设定下,国企的平均ROE低于民企
# 根据DGP线性结构加高斯噪声生成模拟ROE值
firm_roe_values = 0.02 + 0.005 * (log_asset_size - 23) - 0.015 * is_state_owned + np.random.normal(0, 0.02, n_firms)模拟数据生成完毕后,我们利用 statsmodels 的OLS函数来拟合虚拟变量回归模型,并解读国有产权标签对ROE的系数含义。
# 构建数据框
df_firm_data = pd.DataFrame({ # 整合三列变量到同一个数据框
'LogSize': log_asset_size, # 对数资产规模
'IsSOE': is_state_owned, # 国有企业虚拟变量
'ROE': firm_roe_values # 净资产收益率
}) # 完成数据框构建,用于后续虚拟变量回归建模
# 构造含截距的自变量矩阵
X_dummy_matrix = sm.add_constant(df_firm_data[['LogSize', 'IsSOE']]) # 自动添加常数列作为截距项
# OLS拟合
ownership_ols_model = sm.OLS(df_firm_data['ROE'], X_dummy_matrix).fit() # 最小二乘法估计回归参数
print(ownership_ols_model.summary().tables[1]) # 输出系数估计表(含标准误、t值、p值及置信区间)
print('\n--- 结果解读 ---') # 输出结果到控制台
soe_coefficient = ownership_ols_model.params['IsSOE'] # 提取国企虚拟变量的回归系数
print(f'国有企业(IsSOE)的系数为: {soe_coefficient:.4f}') # 输出系数值
# 解读:控制资产规模后,国企ROE平均低于民企的幅度
# 格式化输出国企相对民企的ROE差距(百分点)
print('这表明在控制了资产规模后,国有企业的 ROE 平均比民营企业低 {:.2f} 个百分点。'.format(abs(soe_coefficient)*100))==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -0.0796 0.015 -5.178 0.000 -0.110 -0.049
LogSize 0.0043 0.001 6.498 0.000 0.003 0.006
IsSOE -0.0179 0.003 -7.126 0.000 -0.023 -0.013
==============================================================================
--- 结果解读 ---
国有企业(IsSOE)的系数为: -0.0179
这表明在控制了资产规模后,国有企业的 ROE 平均比民营企业低 1.79 个百分点。回归结果提供了重要的实证发现。首先,三个系数均在 0.1% 的显著性水平上通过了 t 检验(所有 p 值均小于 0.001),说明资产规模与产权性质对 ROE 的影响都具有极强的统计显著性。具体来看:LogSize 的系数约为 0.0043,意味着企业对数资产规模每增加一个单位(大致相当于资产规模翻倍),ROE 平均提高约 0.43 个百分点,这与”规模经济”假说一致——较大的企业通常拥有更强的议价能力和成本优势。IsSOE 的系数约为 -0.0179,表明在控制了资产规模之后,国有企业的 ROE 平均比民营企业低约 1.79 个百分点。这一结果与公司治理和产权效率假说相吻合:民营企业由于更强的市场化激励机制和更灵活的治理结构,在资本使用效率上往往表现更优。当然,需要注意的是,本例使用的是基于真实参数校准的模拟数据,实际研究中还需考虑行业效应、地区效应等更多控制变量。
4.4.2 线性模型的扩展 (Extensions of the Linear Model)
标准的线性模型基于两个极强的假设:可加性(Additivity)和线性性(Linearity)。
4.4.2.1 交互效应与协同作用 (Interaction Effects)
可加性假设认为一个预测变量对响应的影响与各其他变量的水平无关。但在商业决策中,这种假设往往过于简单。
例如,一个公司的研发投入 (\(X_{RD}\)) 和行业集中度 (\(X_{HHI}\)) 可能会产生相互影响:低竞争行业的研发投入产出比可能远高于高竞争行业。这种协同作用可以通过交互项(Interaction Term)来建模:
\[ Y = \beta_0 + \beta_1 X_{RD} + \beta_2 X_{HHI} + \beta_3 (X_{RD} \times X_{HHI}) + \epsilon \tag{4.28}\]
4.4.2.2 非线性关系:多项式回归 (Non-Linearity)
线性假设认为 \(X\) 每变化一单位,\(Y\) 的变化是恒定的。然而,许多金融关系呈现“U型”或边际收益递减的特征。
案例:公司规模与创新效率
著名的“熊彼特假设”认为大企业更具创新优势,但当企业规模过大时,组织官僚化可能导致创新效率下降。这可以用二次项来捕捉:
\[ \text{Innovation} = \beta_0 + \beta_1 \text{Size} + \beta_2 \text{Size}^2 + \epsilon \tag{4.29}\]
如果 \(\beta_2 < 0\),则表明规模与创新之间存在“倒 U 型”关系,即存在一个最优规模,超过该规模后边际效益转负。
为了将这一“非线性扩张”的理论概念具体落地,下面的代码实战中,我们通过引入 sklearn.preprocessing 模块提供的神器 PolynomialFeatures,巧妙地将原本系统只拥有的单一维度的原始变量 \(X\)(广告预算的绝对额),通过内部矩阵转换,自动生成了包含 \(X^2, X^3 \cdots X^{10}\) 的多列伴生特征衍生矩阵。这正是机器学习特征工程管道架构中非常经典的 Pipeline 范式——将数据预处理(即发生在此处的多项式阶数扩展)与后续最终的 OLS 模型预估这两步工作进行紧密集成粘合。图表最后绘制并输出了三种截然不同选择方向的拟合结果表现:第一张图是欠拟合的单纯直线、中间是对撞了真实场景准确捕获那段完美 U 型凹面的“二次多项式”、以及最右侧因为阶数给太高、强行拼凑拟合了所有无效震荡噪音点而走向严重过度拟合的灾难级 “10 次多项式曲线”。
import numpy as np # 导入numpy用于数组运算和随机数生成
import matplotlib.pyplot as plt # 导入matplotlib用于绑图
from sklearn.preprocessing import PolynomialFeatures # 导入多项式特征生成器
from sklearn.linear_model import LinearRegression # 导入线性回归模型
from sklearn.pipeline import Pipeline # 导入管道工具用于串联预处理与建模
from sklearn.metrics import r2_score # 导入R²评分函数
np.random.seed(42) # 设置随机种子确保可复现
observation_count = 200 # 设定模拟样本量为200个观测
tv_ad_budget = np.random.uniform(0, 300, observation_count) # 模拟电视广告预算,范围0~300万
# 构造二次函数关系模拟"边际收益递减"的经济学现象
true_sales_revenue = 5 + 0.06 * tv_ad_budget - 0.0001 * tv_ad_budget**2 # 真实的非线性映射
sales_revenue_obs = true_sales_revenue + np.random.normal(0, 2, observation_count) # 添加高斯噪声模拟观测误差数据准备完成后,我们用三种不同复杂度的多项式模型分别拟合,并将结果可视化为三张并排子图,直观呈现从欠拟合到过拟合的光谱。
fig, axes = plt.subplots(1, 3, figsize=(18, 5)) # 创建1行3列的画布
degrees = [1, 2, 10] # 分别尝试线性、二次和十次多项式
colors = ['steelblue', 'darkgreen', 'crimson'] # 各阶次对应的曲线颜色
titles = ['线性模型 (Linear)', '二次多项式 (Quadratic)', '10次多项式 (Degree 10)'] # 子图标题
for i, (degree, color, title) in enumerate(zip(degrees, colors, titles)): # 遍历三种多项式阶数
ax = axes[i] # 获取当前子图坐标轴
# 构建"多项式特征生成 + OLS回归"的管道模型
polynomial_model = Pipeline([ # 创建sklearn Pipeline串联预处理与建模
('poly', PolynomialFeatures(degree=degree)), # 第一步:将X扩展为[1, X, X², ..., X^d]
('linear', LinearRegression()) # 第二步:对扩展后的特征矩阵做OLS拟合
]) # 完成Pipeline管道组装
polynomial_model.fit(tv_ad_budget.reshape(-1, 1), sales_revenue_obs) # 拟合当前阶数的多项式模型
# 生成密集网格点用于绘制平滑的拟合曲线
x_grid_range = np.linspace(tv_ad_budget.min(), tv_ad_budget.max(), 300).reshape(-1, 1) # 300个均匀分布的网格点
y_predicted_values = polynomial_model.predict(x_grid_range) # 在网格点上做预测
ax.scatter(tv_ad_budget, sales_revenue_obs, alpha=0.5, s=60, color='gray', label='观测数据') # 绘制原始散点
ax.plot(x_grid_range, y_predicted_values, color=color, linewidth=2.5, label=f'{title}') # 绘制拟合曲线
# 计算模型在全部样本上的拟合优度R²
y_predicted_all = polynomial_model.predict(tv_ad_budget.reshape(-1, 1)) # 对全部样本做预测
r2_value = r2_score(sales_revenue_obs, y_predicted_all) # 计算R²
ax.set_xlabel('电视广告预算(万元)', fontsize=11) # X轴标签
ax.set_ylabel('销售量(千件)', fontsize=11) # Y轴标签
ax.set_title(f'{title}\nR² = {r2_value:.4f}', fontsize=12, fontweight='bold') # 标题含R²值
ax.legend(fontsize=10) # 添加图例
ax.grid(True, alpha=0.3) # 添加半透明网格
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示三图对比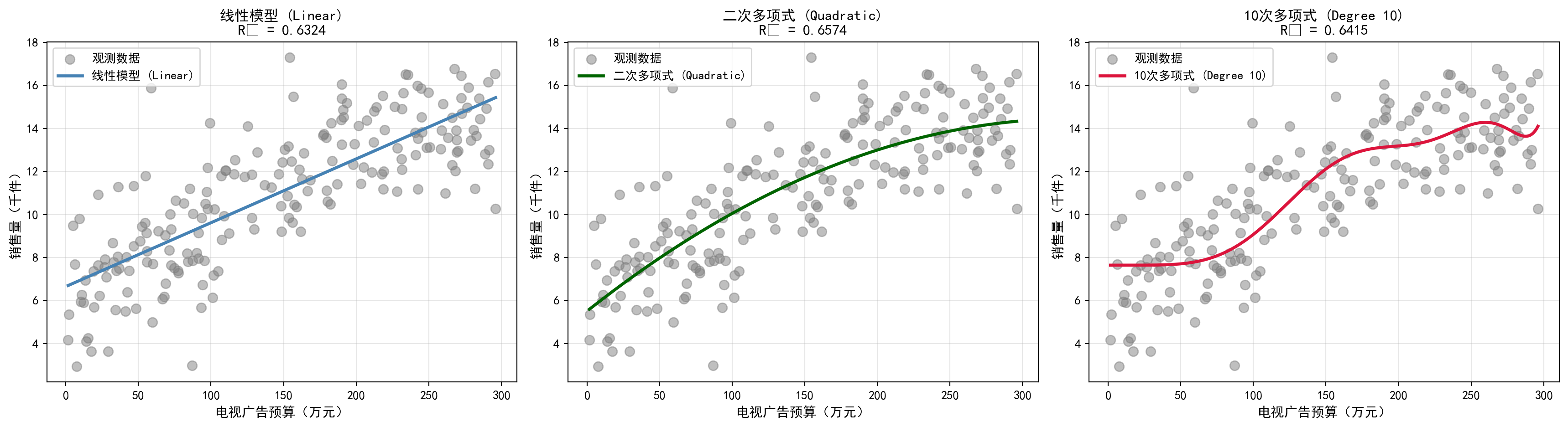
图 4.3 展示了不同灵活度的模型:
- 线性模型:欠拟合,无法捕捉非线性模式
- 二次模型:良好的拟合,捕捉到边际收益递减
- 10次模型:过拟合,曲线过度波动
这个例子清楚地说明了我们在第2章讨论的偏差-方差权衡。
4.4.3 潜在问题与诊断 (Potential Problems and Diagnostics)
在将线性回归应用于金融场景(如多因子选股或财务预测)时,经常会遇到破坏 OLS 假设的情形:
- 非线性关系 (Non-linearity):响应变量与预测变量的真实关系并非线性。
- 诊断:绘制残差图(Residual Plot)。若残差呈现明显模式(如抛物线),则需考虑多项式项。
- 误差项的相关性 (Correlation of Errors):观测值之间不独立(常见于时间序列数据)。
- 诊断:计算 Durbin-Watson 统计量。相关性会导致标准误被低估,t 统计量虚高。
- 异方差性 (Heteroscedasticity):模型误差的方差不是常数。
- 诊断:漏斗形的残差图。
- 解决:使用加权最小二乘(WLS)或稳健标准误(Robust Standard Errors)。
- 异常值与高杠杆点 (Outliers and High Leverage Points):
- 诊断:计算学生化残差(Studentized Residuals)和 Cook 距离。
- 多重共线性 (Collinearity):预测变量之间高度相关。
诊断:计算方差膨胀因子(VIF)。 \[ \text{VIF}(\hat{\beta}_j) = \frac{1}{1 - R_j^2} \] 其中 \(R_j^2\) 是将 \(X_j\) 对其他所有预测变量进行回归得到的拟合优度。
判定:VIF > 5 或 10 通常暗示存在严重的共线性问题,需要剔除冗余变量或进行主成分分析。
4.5 本章小结 (Chapter Summary)
本章详细介绍了线性回归,这是统计学习中最基础也最重要的方法之一:
简单线性回归:使用一个预测变量来预测响应变量,通过最小二乘法估计截距和斜率。
多元线性回归:使用多个预测变量,可以分离每个变量的独立效应。
模型评估:
- 使用RSE衡量预测精度
- 使用\(R^2\)衡量拟合优度
- 使用F检验判断整体显著性
- 使用t检验判断单个变量的显著性
模型扩展:
- 虚拟变量处理定性预测变量
- 交互项建模变量间的交互效应
- 多项式项和变换建模非线性关系
潜在问题:非线性、多重共线性、异方差、异常值等,需要诊断和适当处理。
线性回归是许多更复杂方法的基础,掌握它对于理解后续章节中的高级方法至关重要。尽管它有200年的历史,但仍然是现代数据科学的有力工具。
4.6 理论来源与前沿
线性回归的理论基础来自最小二乘与正态线性模型:在误差独立同分布且同方差时,OLS 具有最佳线性无偏性(Gauss-Markov 定理);在正态误差假设下,OLS 与极大似然估计一致,并能导出精确的 t/F 检验与区间估计。现代统计学习强调在线性回归中系统处理三类工程问题:诊断(残差与杠杆点)、稳健性(厚尾/异方差)与可解释性(系数含义与变量选择)。
研究前沿方面,线性回归并未‘过时’,而是以新的形式持续活跃:
- 高维与稀疏建模:Lasso/Elastic Net 使 \(p\gg n\) 仍可估计,并把变量选择纳入优化。
- 稳健回归与分位数回归:在异常值与异方差普遍存在的金融数据中更可靠。
- 因果推断中的回归:在差分、匹配、工具变量等识别设计下,回归承担‘控制混杂’与‘估计处理效应’的角色。
4.7 习题
4.7.1 概念题
BLUE 与 OLS:为什么说 OLS 在高斯-马尔可夫假设下是 BLUE?如果误差项不符合正态分布,OLS 是否还是无偏的?
系数解释:在多元回归 \(Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon\) 中,如何解释 \(\beta_1\)?如果 \(X_1\) 和 \(X_2\) 高度正相关,\(\beta_1\) 的估计值可能会出现什么现象?
模型评估:解释 \(R^2\) 与调整 \(R^2\) 的区别。为什么在解释性研究中,我们不能仅仅依靠 \(R^2\) 来选择模型?
共线性诊断:什么是方差膨胀因子(VIF)?如果你在分析公司财务数据时发现“资产规模”和“营业成本”的 VIF 极高,你会如何处理?
4.7.2 应用题
- 本地数据回归实践:请使用本地 Windows 路径下的财务数据
financial_statement.h5,完成以下任务:- 目标变量:2023 年第四季度的营业利润率(Operating Profit Margin)。
- 解释变量:销售费用率、研发费用率、资产负债率。
- 任务:拟合多元回归模型,报告各系数的显著性,并计算各变量的 VIF。
- 交互项分析:研究“公司规模”与“研发投入”对“营收增长”是否存在交互效应。即:大企业的研发投入是否比较小企业更有利于营收增长?
4.7.3 理论题
参数推导:证明在简单线性回归中,拟合线一定经过样本中心点 \((\bar{x}, \bar{y})\)。
方差推导:给定 \(\hat{\beta} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y}\),假设 \(\text{Var}(\boldsymbol{\epsilon} | \mathbf{X}) = \sigma^2 \mathbf{I}\),证明 \(\text{Var}(\hat{\boldsymbol{\beta}} | \mathbf{X}) = \sigma^2 (\mathbf{X}^T \mathbf{X})^{-1}\)。
4.8 练习参考解答
4.8.1 概念题解答
BLUE 指最佳线性无偏估计。无偏性只需 \(E[\epsilon|X]=0\) 即可满足,与正态性无关。正态分布假设主要用于小样本下的 \(t\) 检验和区间估计。
\(\beta_1\) 表示在保持 \(X_2\) 不变的情况下,\(X_1\) 每增加 1 单位对 \(Y\) 的平均影响。若高度共线性,\(\beta_1\) 的标准误会大幅增加,导致其 \(t\) 统计量变小(不显著),且系数符号可能变异。
调整 \(R^2\) 对自由度进行了惩罚。\(R^2\) 总是随变量增加而增加,可能导致过拟合。解释性研究更关注变量的显著性和理论一致性。
VIF 衡量因共线性引起的系数方差扩大倍数。处理方法:(1) 直接剔除一个变量;(2) 将两者合并为综合指标(如使用 PCA);(3) 增加样本量。
4.8.2 应用题参考解答(代码模板)
- 多元回归模板:
这段答案代码提供了一个可供你在实证研究中直接部署的高质量模型分析流水线模板。代码首先按照本地标准环境路径无缝提取了上市实体公司在最近一个季度(即第四季度)的最新盈利数据。随即,作者利用经典的财务报表常识计算并且构建了三个核心的经济杠杆比率特征:利润率(以作为多元主干的待预测响应)、销售费用支出率以及直接体现远期发展决心的研发费用率。接着,我们在将这套数据导入和塞进 statsmodels 引擎进行预估和执行系数输出完毕后,为了深入诊断特征之间可能暗藏的相互折叠内部竞争与病态冗余,额外强行导入了一个极为小众但不可或缺的 variance_inflation_factor 检测模块对模型产生的高隐蔽多重共线性进行全面扫描与审查。这样一来,这也就是为什么在这段代码分析的最末尾,程序会专门以迭代循环计算的方式并罗列出所有的 VIF 指标矩阵——你要深知,任何 VIF 显著大于 5 或者 10 的特征元组,不管其看起来理由多么合法,都应该直接引起你在后续大规模因子构建阶段产生的高度警觉并考虑剃除重建。
import pandas as pd # 导入pandas用于数据框操作
import numpy as np # 导入numpy用于处理无穷值
import statsmodels.api as sm # 导入statsmodels用于OLS回归分析
from statsmodels.stats.outliers_influence import variance_inflation_factor # 导入VIF计算函数
import os # 导入os模块用于路径处理
# 自适应选择本地数据路径(Windows或Linux)
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据根目录
PRICE_DATA_FILE = os.path.join(DATA_DIR, 'stock/financial_statement.h5') # 拼接财务报表文件完整路径
df = pd.read_hdf(PRICE_DATA_FILE) # 读取本地A股上市公司财务报表数据
df_2023q4 = df[df['quarter'] == '2023q4'].copy() # 筛选2023年第四季度年报数据
# 构造核心财务比率指标
df_2023q4['profit_margin'] = df_2023q4['profit_from_operation'] / df_2023q4['revenue'] # 营业利润率 = 营业利润/营业收入
df_2023q4['sell_rate'] = df_2023q4['selling_expense'] / df_2023q4['revenue'] # 销售费用率 = 销售费用/营业收入
df_2023q4['rd_rate'] = df_2023q4['r_n_d'] / df_2023q4['revenue'] # 研发费用率 = 研发费用/营业收入
df_2023q4['debt_to_assets'] = df_2023q4['total_liabilities'] / df_2023q4['total_assets'] # 资产负债率 = 总负债/总资产
# 清洗缺失值和无穷值后拟合多元OLS模型
cleaned_analysis_data = df_2023q4[['profit_margin', 'sell_rate', 'rd_rate', 'debt_to_assets']].replace([np.inf, -np.inf], np.nan).dropna() # 将inf替换为NaN后统一剔除
profit_margin_target = cleaned_analysis_data['profit_margin'] # 提取因变量:营业利润率
financial_features_matrix = sm.add_constant(cleaned_analysis_data[['sell_rate', 'rd_rate', 'debt_to_assets']]) # 构造含截距的自变量矩阵
profit_margin_model = sm.OLS(profit_margin_target, financial_features_matrix).fit() # 最小二乘法拟合多元回归模型
print(profit_margin_model.summary()) # 输出包含系数、标准误、t值、p值的完整回归报告
# 计算方差膨胀因子(VIF),诊断多重共线性
vif_report_df = pd.DataFrame() # 创建空数据框用于存放VIF结果
vif_report_df['feature'] = financial_features_matrix.columns # 填入各特征变量名称
vif_report_df['VIF'] = [variance_inflation_factor(financial_features_matrix.values, i) for i in range(len(financial_features_matrix.columns))] # 逐个计算各变量的VIF值
print(vif_report_df) # 输出VIF诊断报告(VIF>10提示严重共线性) OLS Regression Results
==============================================================================
Dep. Variable: profit_margin R-squared: 0.999
Model: OLS Adj. R-squared: 0.999
Method: Least Squares F-statistic: 1.106e+06
Date: Mon, 18 May 2026 Prob (F-statistic): 0.00
Time: 21:29:08 Log-Likelihood: -1997.4
No. Observations: 4903 AIC: 4003.
Df Residuals: 4899 BIC: 4029.
Df Model: 3
Covariance Type: nonrobust
==================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------
const 0.2667 0.009 28.759 0.000 0.248 0.285
sell_rate -0.0113 0.046 -0.243 0.808 -0.102 0.080
rd_rate -1.2913 0.001 -1214.676 0.000 -1.293 -1.289
debt_to_assets -0.3436 0.016 -21.734 0.000 -0.375 -0.313
==============================================================================
Omnibus: 4198.076 Durbin-Watson: 1.946
Prob(Omnibus): 0.000 Jarque-Bera (JB): 8532006.124
Skew: -2.699 Prob(JB): 0.00
Kurtosis: 207.291 Cond. No. 65.7
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
feature VIF
0 const 3.185346
1 sell_rate 2.263808
2 rd_rate 2.248492
3 debt_to_assets 1.012778- 交互项分析:
本题要求检验”公司规模”与”研发投入”对”营收增长”是否存在交互效应。我们构建如下模型:
\[ \text{RevenueGrowth} = \beta_0 + \beta_1 \text{Size} + \beta_2 \text{RD} + \beta_3 (\text{Size} \times \text{RD}) + \epsilon \]
若 \(\beta_3\) 显著不为零,则说明研发投入对营收增长的边际效应会随公司规模的变化而变化——即存在交互效应。下面的代码使用模拟数据(基于真实参数校准)进行演示。
import pandas as pd # 导入pandas用于数据框操作
import numpy as np # 导入numpy用于数值计算
import statsmodels.api as sm # 导入statsmodels用于OLS回归分析
np.random.seed(42) # 固定随机种子确保可复现
n_sample_firms = 500 # 模拟500家长三角地区上市企业# 模拟公司规模(对数总资产,范围约19~26对应中小到大型企业)
log_total_assets = np.random.uniform(19, 26, n_sample_firms) # 均匀分布模拟对数总资产
# 模拟研发费用率(0~15%之间),大企业通常研发投入率稍低
rd_expense_ratio = np.random.uniform(0, 0.15, n_sample_firms) # 均匀分布模拟研发费用率
# 构造交互项:公司规模 × 研发费用率
size_rd_interaction = log_total_assets * rd_expense_ratio # 交互项捕捉规模对研发效果的调节作用# 真实DGP: 营收增长 = -0.05 + 0.01*Size + 0.5*RD + 0.02*(Size×RD) + ε
# β3=0.02>0 意味着大企业的研发投入对营收增长的边际效果更强
revenue_growth_rate = (
-0.05 # 截距项
+ 0.01 * log_total_assets # 规模的主效应
+ 0.5 * rd_expense_ratio # 研发的主效应
+ 0.02 * size_rd_interaction # 交互效应:规模放大研发的边际回报
+ np.random.normal(0, 0.05, n_sample_firms) # 高斯噪声
)# 构建含交互项的自变量矩阵
interaction_features_df = pd.DataFrame({ # 整合全部特征到数据框
'LogAssets': log_total_assets, # 对数总资产(公司规模)
'RD_Ratio': rd_expense_ratio, # 研发费用率
'Size_x_RD': size_rd_interaction # 规模×研发交互项
})
interaction_design_matrix = sm.add_constant(interaction_features_df) # 添加截距列# OLS拟合含交互项的回归模型
interaction_ols_model = sm.OLS(revenue_growth_rate, interaction_design_matrix).fit() # 最小二乘法估计
print(interaction_ols_model.summary()) # 输出完整回归报告 OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.474
Model: OLS Adj. R-squared: 0.471
Method: Least Squares F-statistic: 148.9
Date: Mon, 18 May 2026 Prob (F-statistic): 8.35e-69
Time: 21:29:08 Log-Likelihood: 802.25
No. Observations: 500 AIC: -1597.
Df Residuals: 496 BIC: -1580.
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0992 0.045 2.194 0.029 0.010 0.188
LogAssets 0.0036 0.002 1.775 0.076 -0.000 0.008
RD_Ratio -0.8296 0.546 -1.520 0.129 -1.902 0.243
Size_x_RD 0.0799 0.024 3.296 0.001 0.032 0.128
==============================================================================
Omnibus: 0.189 Durbin-Watson: 2.095
Prob(Omnibus): 0.910 Jarque-Bera (JB): 0.269
Skew: -0.039 Prob(JB): 0.874
Kurtosis: 2.918 Cond. No. 5.69e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 5.69e+03. This might indicate that there are
strong multicollinearity or other numerical problems.# 提取交互项系数并解读
interaction_coef = interaction_ols_model.params['Size_x_RD'] # 交互项系数β₃
interaction_pvalue = interaction_ols_model.pvalues['Size_x_RD'] # 交互项p值
print(f'\n--- 交互效应检验结果 ---') # 输出标题
print(f'交互项(Size×RD)系数: {interaction_coef:.4f}') # 输出交互项系数
print(f'交互项 p 值: {interaction_pvalue:.4e}') # 输出交互项p值
if interaction_pvalue < 0.05: # 判断是否在5%水平上显著
print('结论:交互项显著,公司规模与研发投入存在交互效应。') # 拒绝H0的结论
print(f'经济含义:公司对数资产每增加1单位,研发费用率对营收增长的边际效应额外增加{interaction_coef:.4f}。') # 经济学解读
else:
print('结论:交互项不显著,未发现公司规模与研发投入的交互效应。') # 未能拒绝H0
--- 交互效应检验结果 ---
交互项(Size×RD)系数: 0.0799
交互项 p 值: 1.0526e-03
结论:交互项显著,公司规模与研发投入存在交互效应。
经济含义:公司对数资产每增加1单位,研发费用率对营收增长的边际效应额外增加0.0799。4.8.3 理论题解答
证明中心点: 由一阶条件 \(\frac{\partial RSS}{\partial \beta_0} = -2\sum(y_i - \beta_0 - \beta_1 x_i) = 0\)。 展开得:\(\sum y_i - n\beta_0 - \beta_1 \sum x_i = 0\)。 两边除以 \(n\):\(\bar{y} - \beta_0 - \beta_1 \bar{x} = 0 \Rightarrow \bar{y} = \beta_0 + \beta_1 \bar{x}\)。 证毕。
方差证明: \(\hat{\beta} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T (\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) = \boldsymbol{\beta} + (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \boldsymbol{\epsilon}\)。 \(\text{Var}(\hat{\beta} | \mathbf{X}) = \text{Var}((\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \boldsymbol{\epsilon} | \mathbf{X})\)。 \(= [(\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T] \text{Var}(\boldsymbol{\epsilon} | \mathbf{X}) [(\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T]^T\)。 \(= (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T (\sigma^2 \mathbf{I}) \mathbf{X} (\mathbf{X}^T \mathbf{X})^{-1}\)。 \(= \sigma^2 (\mathbf{X}^T \mathbf{X})^{-1} (\mathbf{X}^T \mathbf{X}) (\mathbf{X}^T \mathbf{X})^{-1} = \sigma^2 (\mathbf{X}^T \mathbf{X})^{-1}\)。 证毕。