本章讨论支持向量机(SVM),这是1990年代在计算机科学界开发的一种分类方法,自那时起其普及度不断增长。SVM在各种设置中都被证明表现良好,通常被认为是最好的”开箱即用”分类器之一。
支持向量机是简单直观的最大间隔分类器 的推广。虽然它优雅且简洁,但我们会看到这个分类器不幸地不能应用于大多数数据集,因为它要求类别可以被线性边界分离。在 小节 10.2 支持向量分类器 ,这是最大间隔分类器的扩展,可以应用于更广泛的情况。小节 10.3 支持向量机 ,这是支持向量分类器的进一步扩展,以适应非线性类别边界。支持向量机旨在二元分类设置,其中有两个类别。在 小节 10.3.3 小节 10.4
人们通常将最大间隔分类器、支持向量分类器和支持向量机统称为支持向量机。为了避免混淆,本章将仔细区分这三个概念。
最大间隔分类器
在本节中,我们定义超平面并引入最优分离超平面的概念。
什么是超平面
在\(p\) 维空间中,超平面是维度为\(p-1\) 的平坦仿射子空间。例如在二维中,超平面是平坦的一维子空间——换句话说是一条线。在三维中超平面是平坦的二维子空间——即一个平面。在\(p > 3\) 维中,很难想象超平面,但\((p-1)\) 维平坦子空间的概念仍然适用。
超平面的数学定义非常简单。在二维中超平面由以下方程定义:
\[
\beta_0 + \beta_1 X_1 + \beta_2 X_2 = 0
\tag{10.1}\]
对于参数\(\beta_0, \beta_1, \beta_2\) 。当我们说 (1) “定义”了超平面,我们的意思是任何满足 (1) 的\(X = (X_1, X_2)^T\) 都是超平面上的一个点。注意 (1) 简单地是一条线的方程,因为在二维中超平面就是一条线。
可以很容易扩展到\(p\) 维设置:
\[
\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p = 0
\tag{10.2}\]
定义了一个\(p\) 维超平面。如果点\(X = (X_1, X_2, \ldots, X_p)^T\) 在\(p\) 维空间中(即长度为\(p\) 的向量满足(式 10.2 ),那么\(X\) 位于超平面上。
现在,假设\(X\) 不满足(式 10.2 );相反, \[ \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p > 0 \tag{10.3}\]
那么这告诉我们\(X\) 位于超平面的一侧。另一方面,如果 \[ \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p < 0 \tag{10.4}\]
那么\(X\) 位于超平面的另一侧。因此我们可以将超平面视为将\(p\) 维空间分成两半。人们可以通过简单地计算(式 10.2 )左侧的符号来轻松确定点位于超平面的哪一侧。
图 10.1 显示了二维空间中的超平面。
为了让你用最直觉的方式理解“超平面”(Hyperplane)这个有些抽象的数学名词,下面的 Python 绘图代码在二维平面上徒手构建了一个最经典的绝对分割场景。在这个二维世界里,“超平面”退化成了一条笔直的黑色实线(由方程 \(1 + 2X_1 + 3X_2 = 0\) 严格定义)。 代码利用 numpy 铺设了一张密集的坐标网格,并对空间中每一个\((X_1, X_2)\) 坐标点进行了极其冷酷的代数审判:如果你将坐标代入方程左侧,计算结果大于0(即在超平面的“上方”),你就会被无情地涂成蓝色;反之,如果结果小于 0(在“下方”),你就会被划入紫色的阵营。这种由于一个线性方程符号的正负,就将整个无垠的特征空间劈成泾渭分明的两大楚河汉界的强大能力,正是支持向量机在处理分类问题时最核心、最原始的底层逻辑起点。
import numpy as np # 导入numpy库用于数值计算 import matplotlib.pyplot as plt # 导入matplotlib库用于数据可视化 'font.sans-serif' ] = ['SimHei' , 'Arial Unicode MS' ] # 设置中文字体优先级 'axes.unicode_minus' ] = False # 解决坐标轴负号显示为方块的问题 = plt.subplots(figsize= (8 , 8 )) # 创建8×8英寸的正方形画布 = np.linspace(- 2 , 2 , 400 ) # 在[-2,2]区间生成400个等距X₁坐标值 = - (1 + 2 * x1) / 3 # 根据超平面方程1+2X₁+3X₂=0解出X₂ # 使用网格点着色表示超平面两侧的区域 = np.meshgrid(np.linspace(- 2 , 2 , 100 ), np.linspace(- 2 , 2 , 100 )) # 生成100×100的二维网格 = 1 + 2 * x1_blue + 3 * x2_blue > 0 # 标记满足1+2X₁+3X₂>0的网格点(蓝色区域) = 'blue' , alpha= 0.3 , s= 10 ) # 绘制蓝色区域的散点 = 1 + 2 * x1_blue + 3 * x2_blue < 0 # 标记满足1+2X₁+3X₂<0的网格点(紫色区域) = 'purple' , alpha= 0.3 , s= 10 ) # 绘制紫色区域的散点 'k-' , linewidth= 3 , label= '超平面: 1 + 2X₁ + 3X₂ = 0' ) # 绘制超平面分界线(黑色实线) - 2 , 2 ) # 设置X轴显示范围 - 2 , 2 ) # 设置Y轴显示范围 'X₁' , fontsize= 12 ) # 设置X轴标签 'X₂' , fontsize= 12 ) # 设置Y轴标签 '二维空间中的超平面' , fontsize= 14 , fontname= 'SimHei' ) # 设置图形标题 = 'upper right' , fontsize= 10 ) # 在右上角显示图例 True , alpha= 0.3 ) # 添加半透明网格线辅助阅读 = 0 , color= 'k' , linewidth= 0.5 ) # 绘制水平参考线(X轴) = 0 , color= 'k' , linewidth= 0.5 ) # 绘制垂直参考线(Y轴) # 自动调整子图布局防止标签被裁切 # 显示图形
使用分离超平面进行分类
现在假设我们有一个\(n \times p\) 的数据矩阵\(X\) ,它由\(p\) 维空间中的\(n\) 个训练观测组成 \[ x_1 = \begin{pmatrix} x_{11} \\ \vdots \\ x_{1p} \end{pmatrix}, \ldots, x_n = \begin{pmatrix} x_{n1} \\ \vdots \\ x_{np} \end{pmatrix} \]
并且这些观测落入两个类别——即\(y_1, \ldots, y_n \in \{-1, 1\}\) ,其中\(-1\) 表示一个类别1表示另一个类别。我们还有一个测试观测即观测特征的\(p\) 向量\(x^* = (x^*_1, \ldots, x^*_p)^T\) 。我们的目标是基于训练数据开发一个分类器,使用其特征测量正确地对测试观测进行分类。
假设可以构造一个超平面,根据其类别标签完美地分离训练观测。我们称这样的超平面为分离超平面 。我们可以将蓝色类别的观测标记为\(y_i = 1\) ,将紫色类别的观测标记为\(y_i = -1\) 。那么分离超平面具有以下性质:
\[
\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} > 0 \quad \text{if} \; y_i = 1
\tag{10.5}\]
\[
\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} < 0 \quad \text{if} \; y_i = -1
\tag{10.6}\]
等价地,分离超平面具有以下性质:
\[
y_i (\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip}) > 0 \quad \text{for all} \; i = 1, \ldots, n
\tag{10.7}\]
如果分离超平面存在,我们可以用它来构造一个非常自然的分类器:测试观测根据它位于超平面的哪一侧来分配一个类别。也就是说,我们根据以下符号对测试观测\(x^*\) 进行分类: \[ f(x^*) = \beta_0 + \beta_1 x^*_1 + \beta_2 x^*_2 + \cdots + \beta_p x^*_p \tag{10.8}\]
如果\(f(x^*)\) 为正,那么我们将测试观测分配给类别\(1\) ;如果\(f(x^*)\) 为负,那么我们将它分配给类别\(-1\) 。我们也可以利用\(f(x^*)\) 的大小。如果\(f(x^*)\) 远离零,那么这意味着\(x^*\) 远离超平面,因此我们可以对\(x^*\) 的类别分配充满信心。另一方面,如果\(f(x^*)\) 接近零,那么\(x^*\) 位于超平面附近,我们对类别分配的确定性较低。
最大间隔分类器
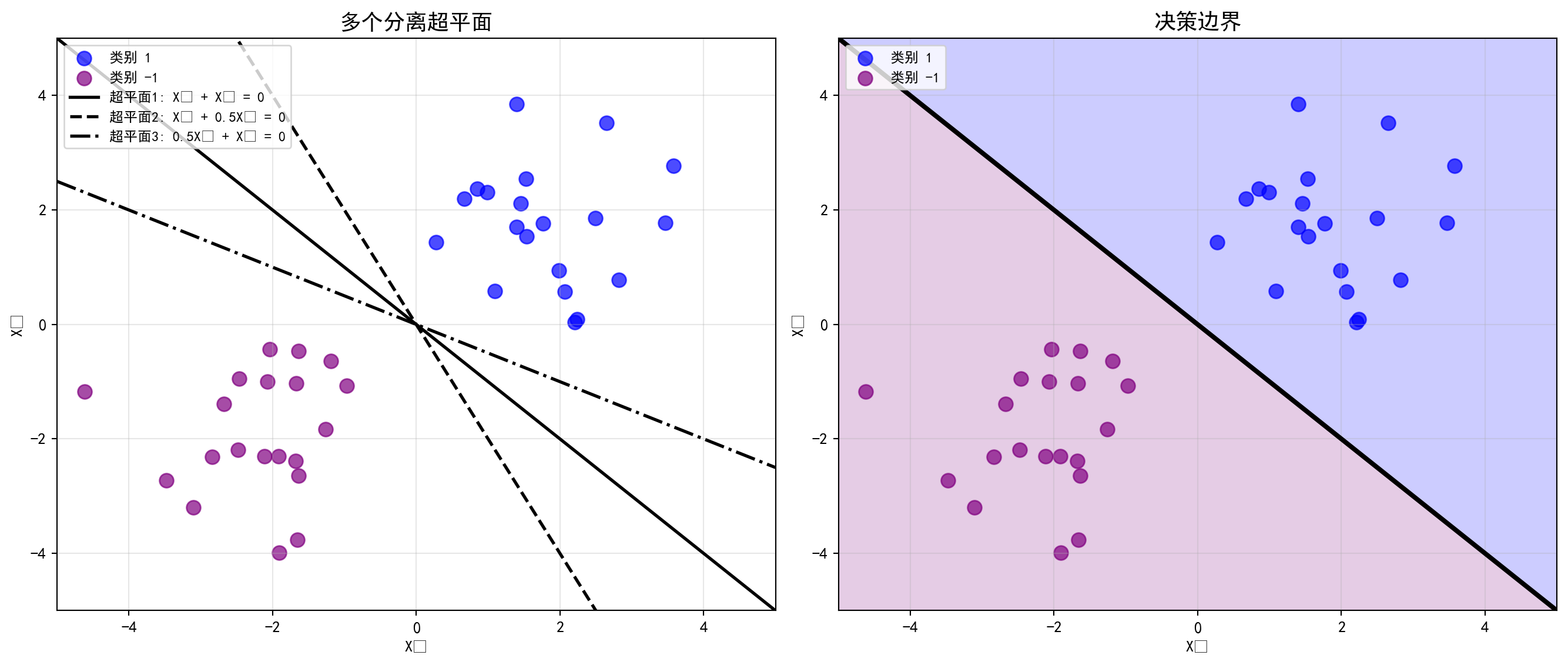
通常,如果我们的数据可以使用超平面完美分离,那么实际上将存在无限多个这样的超平面。这是因为给定的分离超平面通常可以稍微向上或向下移动或旋转而不会与任何观测接触。图 10.2 的左面板显示了三种可能的分离超平面。
为了基于分离超平面构造分类器,我们必须有一种合理的方法来决定使用无限多个可能的分离超平面中的哪一个。一个自然的选择是最大间隔超平面 (也称为最优分离超平面 ),它是距离训练观测最远的分离超平面。也就是说,我们可以计算每个训练观测到给定分离超平面的(垂直)距离;这些距离中最小的就是观测到超平面的最小距离,被称为间隔 。最大间隔超平面是间隔最大的分离超平面——即它具有到训练观测的最远最小距离。然后我们根据测试观测位于最大间隔超平面的哪一侧对其进行分类。这被称为最大间隔分类器 。我们希望训练数据上具有大间隔的分类器在测试数据上也将具有大间隔,从而正确分类测试观测
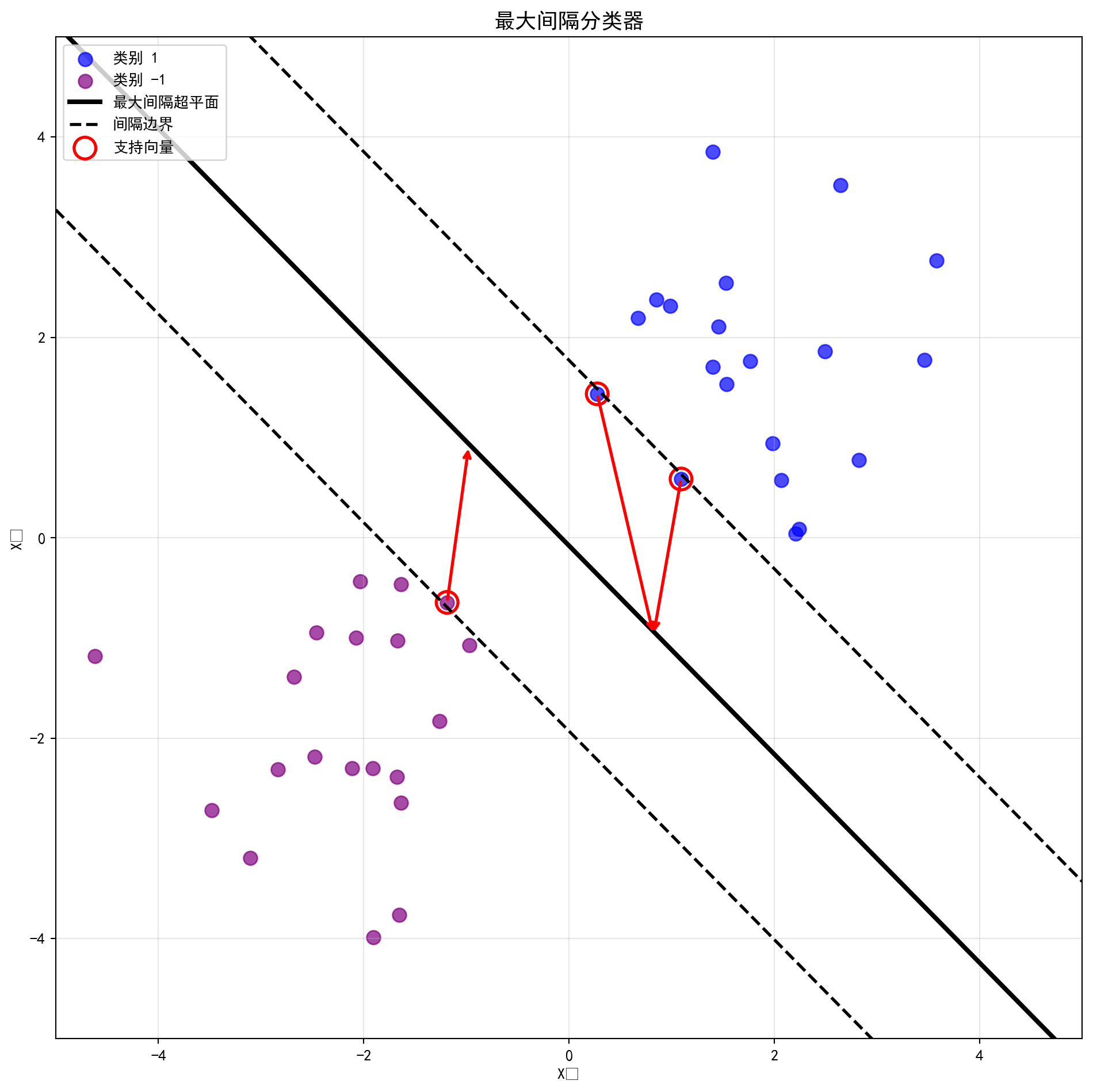
图 10.3 显示了@fig-separating-hyperplanes 数据的最大间隔超平面。比较@fig-separating-hyperplanes 的右面板和@fig-maximal-margin,我们看到 图 10.3 中显示的最大间隔超平面确实导致观测和分离超平面之间的最小距离更大——即更大的间隔。在某种意义上最大间隔超平面代表了我们可以在两个类别之间插入的最宽间隔带的中线。
检查@fig-maximal-margin,我们看到三个训练观测与最大间隔超平面等距,并且沿着指示间隔宽度的虚线。这三个观测被称为支持向量 ,因为它们是\(p\) 维空间中的向量(在 图 10.3 中\(p=2\) ),它们”支持”最大间隔超平面,意思是如果这些点稍微移动最大间隔超平面也会移动。有趣的是最大间隔超平面直接依赖于支持向量而不依赖于其他观测任何其他观测的移动都不会影响分离超平面前提是该观测的移动不会使其越过间隔设置的边界。最大间隔超平面仅直接依赖于观测的一小部分子集这一重要性质将在本章后面讨论支持向量分类器和支持向量机时出现。
然而,当真正的观测数据散落在特征空间中时(如下图左侧的蓝点和紫点),只要它们是线性可分的,能穿插在它们中间并且不碰到任何一个点的“分离超平面”将会有无数个(图中黑色实线、虚线、点划线只是其中三种可能)。 为了在这无数种可能中找出那条“唯一正确”的分割线,统计学家们制定了一个极其严苛且反直觉的筛选规则:最大间隔原则 。 在下方第二段绘制 图 10.3 的代码中,我们正式召唤出了大名鼎鼎的 sklearn.svm.SVC(kernel='linear')。这台精密的线性切割机不仅找到了一条完美的分割线(中间的黑色实线),还向身体两侧疯狂地推挤着两条透明的防线(间隔边界,黑色虚线)。机器在推挤的过程中,直到它的防线死死地撞上了最近的几个数据点(图中被红色圆圈高亮框出的那三个孤独的观测值)才被迫停止。这三个极其特殊的数据点,就是鼎鼎大名的“支持向量”(Support Vectors) 。 在这个令人震撼的机制中,无论是距离超平面远在天边的其他几百个观测点,还是试图在边缘疯狂试探的噪音,只要它们没有越过雷池进入那两条虚线构成的“间隔带”内部,它们就对最终的模型参数没有任何一丝一毫的决策权。整个宏大的分离超平面,仅仅由这三个被红圈死死锁住的“支持向量”用血肉之躯硬生生撑起。这种“只看最危险边缘,无视安全后方”的极度偏执,造就了最大间隔分类器的简洁。
import numpy as np # 导入numpy库用于数值计算 import matplotlib.pyplot as plt # 导入matplotlib用于数据可视化 # 设置随机种子以确保结果可复现 42 ) # 设置随机种子确保结果可复现 # 生成类别1数据点:均值为(2,2)的二维正态分布,20个样本 = np.random.multivariate_normal([2 , 2 ], [[1 , 0 ], [0 , 1 ]], 20 ) # 生成多元正态分布随机样本 # 生成类别-1数据点:均值为(-2,-2)的二维正态分布,20个样本 = np.random.multivariate_normal([- 2 , - 2 ], [[1 , 0 ], [0 , 1 ]], 20 ) # 生成多元正态分布随机样本
利用生成的可分离数据,绘制多个分离超平面及其决策边界区域,如 图 10.2 所示:
# 创建1行2列的子图画布 = plt.subplots(1 , 2 , figsize= (14 , 6 )) # 创建子图布局 # 左图:绘制类别1数据点(蓝色) 0 ], class1[:, 1 ], c= 'blue' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 # 左图:绘制类别-1数据点(紫色) 0 ], class2[:, 1 ], c= 'purple' , label= '类别 -1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 # 生成用于绘制超平面的x坐标序列 = np.linspace(- 5 , 5 , 100 ) # 生成等间隔序列 # 超平面1: X₁ + X₂ = 0(实线) - x, 'k-' , linewidth= 2 , label= '超平面1: X₁ + X₂ = 0' ) # 在子图中绑制折线图 # 超平面2: X₁ + 0.5X₂ = 0(虚线) - 2 * x, 'k--' , linewidth= 2 , label= '超平面2: X₁ + 0.5X₂ = 0' ) # 在子图中绑制折线图 # 超平面3: 0.5X₁ + X₂ = 0(点划线) - 0.5 * x, 'k-.' , linewidth= 2 , label= '超平面3: 0.5X₁ + X₂ = 0' ) # 在子图中绑制折线图 # 设置左图坐标轴标签、范围和标题 set (xlabel= 'X₁' , ylabel= 'X₂' , xlim= (- 5 , 5 ), ylim= (- 5 , 5 )) # 执行数据处理操作 '多个分离超平面' , fontsize= 14 , fontname= 'SimHei' ) # 设置子图标题 = 'upper left' , fontsize= 9 ) # 添加图例 True , alpha= 0.3 ) # 添加半透明网格线 # 右图:绘制类别1和类别-1的数据点 0 ], class1[:, 1 ], c= 'blue' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 0 ], class2[:, 1 ], c= 'purple' , label= '类别 -1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 # 绘制决策边界(X₁ + X₂ = 0) - x, 'k-' , linewidth= 3 ) # 在子图中绑制折线图 # 创建网格用于绘制决策区域的填充色 = np.meshgrid(np.linspace(- 5 , 5 , 100 ), np.linspace(- 5 , 5 , 100 )) # 生成等间隔序列 # 计算决策函数值(X₁ + X₂)用于着色 = xx + yy # 定义decision变量 # 用填充等高线标识两个决策区域 # 在子图中绑制等高线 = [- 100 , 0 , 100 ], colors= ['purple' , 'blue' ], alpha= 0.2 )# 设置右图坐标轴标签、范围和标题 set (xlabel= 'X₁' , ylabel= 'X₂' , xlim= (- 5 , 5 ), ylim= (- 5 , 5 )) # 执行数据处理操作 '决策边界' , fontsize= 14 , fontname= 'SimHei' ) # 设置子图标题 = 'upper left' , fontsize= 9 ) # 添加图例 True , alpha= 0.3 ) # 添加半透明网格线 # 自动调整子图间距 # 显示图形 # 显示图形
在直观理解了线性可分数据的几何结构之后,我们现在使用 sklearn 中的 SVC 类来拟合最大间隔分类器。通过将惩罚参数 \(C\) 设为一个极大的值(1000),我们几乎不允许任何训练样本被误分类,从而近似实现硬间隔分类。
from sklearn.svm import SVC # 导入支持向量分类器 # 将两个类别的数据合并为一个特征矩阵 = np.vstack([class1, class2]) # 垂直堆叠数组 # 创建标签向量:前20个为+1类,后20个为-1类 = np.hstack([np.ones(20 ), - np.ones(20 )]) # 创建全一数组 # 创建线性SVM分类器,C=1000表示几乎不允许误分类(硬间隔) = SVC(kernel= 'linear' , C= 1000 ) # 初始化支持向量机模型 # 在合并数据上拟合最大间隔分类器 # 训练/拟合模型
SVC(C=1000, kernel='linear') In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
基于拟合好的最大间隔分类器,绘制决策边界、间隔带和支持向量,如 图 10.3 所示:
# 创建正方形画布 = plt.subplots(figsize= (10 , 10 )) # 创建子图布局 # 绘制类别1数据点(蓝色) 0 ], class1[:, 1 ], c= 'blue' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 # 绘制类别-1数据点(紫色) 0 ], class2[:, 1 ], c= 'purple' , label= '类别 -1' , s= 80 , alpha= 0.7 ) # 在子图中绑制散点图 # 提取分类器的权重向量w和截距b = clf.coef_[0 ] # 定义w变量 = clf.intercept_[0 ] # 定义b变量 # 生成用于绘制边界线的x坐标序列 = np.linspace(- 5 , 5 , 100 ) # 生成等间隔序列 # 计算决策超平面 w·x + b = 0 对应的x2坐标 = - w[0 ]/ w[1 ] * x - b/ w[1 ] # 定义decision_boundary变量 # 计算间隔宽度 margin = 1/||w|| = 1 / np.sqrt(np.sum (w** 2 )) # 计算平方根 # 计算上间隔边界(w·x + b = +1) = decision_boundary + np.sqrt(1 + np.sum (w** 2 )** 2 ) / np.sum (w** 2 ) # 计算平方根 # 计算下间隔边界(w·x + b = -1) = decision_boundary - np.sqrt(1 + np.sum (w** 2 )** 2 ) / np.sum (w** 2 ) # 计算平方根 # 绘制最大间隔超平面(实线)和两条间隔边界(虚线) 'k-' , linewidth= 3 , label= '最大间隔超平面' ) # 在子图中绑制折线图 'k--' , linewidth= 2 , label= '间隔边界' ) # 在子图中绑制折线图 'k--' , linewidth= 2 ) # 在子图中绑制折线图 # 用红色空心圆标记支持向量的位置 0 ], clf.support_vectors_[:, 1 ], # 在子图中绑制散点图 = 200 , linewidth= 2 , facecolors= 'none' , edgecolors= 'red' , label= '支持向量' ) # 定义s变量 # 从每个支持向量画箭头到决策边界,直观展示间隔距离 for sv in clf.support_vectors_: # 遍历循环 # 计算支持向量在决策边界上的投影点x坐标 = (sv[0 ] + w[1 ]/ w[0 ] * sv[1 ] - b* w[1 ]/ w[0 ]** 2 ) / (1 + (w[1 ]/ w[0 ])** 2 ) # 定义x_proj变量 # 获取投影点对应的y坐标 = decision_boundary[np.argmin(np.abs (x - x_proj))] # 获取最小值的索引 # 绘制从支持向量指向投影点的红色箭头 '' , xy= (x_proj, y_proj), xytext= (sv[0 ], sv[1 ]), # 添加注释标注 = dict (arrowstyle= '->' , color= 'red' , lw= 2 )) # 定义arrowprops变量 # 设置坐标轴标签、范围、标题和图例 set (xlabel= 'X₁' , ylabel= 'X₂' , xlim= (- 5 , 5 ), ylim= (- 5 , 5 )) # 执行数据处理操作 '最大间隔分类器' , fontsize= 14 , fontname= 'SimHei' ) # 设置子图标题 = 'upper left' , fontsize= 10 ) # 在左上角显示图例 True , alpha= 0.3 ) # 添加半透明网格线 # 自动调整布局 # 显示图形
图 10.3 清晰地展示了最大间隔分类器的几何结构。图中黑色实线即为最优分离超平面(在二维情形下表现为直线),它将蓝色方块(类别+1)和红色圆点(类别-1)精确分隔。超平面两侧的黑色虚线标示出间隔带的边界,两条虚线之间的区域即为”间隔”。可以观察到,恰好有三个数据点——每一侧各有若干——紧贴在间隔边界上,这些被红色圆圈高亮标注的点就是”支持向量”。关键洞察在于:超平面的位置和方向完全由这少数几个支持向量决定,远离间隔边界的绝大多数数据点对分类器没有任何影响。连接支持向量到超平面的双向箭头直观地展示了间隔的宽度\(M\) ,这正是优化问题所要最大化的目标。理解这一几何图像对于接下来讨论支持向量分类器和核技巧至关重要。
构造最大间隔分类器
我们现在考虑基于\(n\) 个训练观测\(x_1, \ldots, x_n \in \mathbb{R}^p\) 和关联类别标签\(y_1, \ldots, y_n \in \{-1, 1\}\) 构造最大间隔超平面的任务。简而言之,最大间隔超平面是以下优化问题的解
\[
\max_{\beta_0, \beta_1, \ldots, \beta_p, M} \quad M
\tag{10.9}\]
约束于
\[
\sum_{j=1}^{p} \beta_j^2 = 1
\tag{10.10}\]
\[
y_i (\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_p x_{ip}) \geq M \quad \forall i = 1, \ldots, n
\tag{10.11}\]
这个优化问题实际上比它看起来要简单。首先(式 10.11 )中的约束保证每个观测都在超平面的正确一侧前提是\(M\) 为正。其次注意(式 10.10 )并不是真正对超平面的约束,因为如果\(\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} = 0\) 定义了超平面,那么\(k(\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip}) = 0\) 对于任何\(k \neq 0\) 也是如此。然而(式 10.10 )为(式 10.11 )增加了意义可以证明,有了这个约束,第\(i\) 个观测到超平面的垂直距离由下式给出 \[ y_i (\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_p x_{ip}) \]
因此,约束(式 10.10 )和(式 10.11 )确保每个观测都在超平面的正确一侧并且距离超平面至少为\(M\) 。因此\(M\) 代表我们超平面的间隔,优化问题选择\(\beta_0, \beta_1, \ldots, \beta_p\) 以最大化\(M\) 。这正是最大间隔超平面的定义
不可分离的情况
最大间隔分类器是执行分类的一种非常自然的方法,如果存在分离超平面的话。然而正如我们已经暗示的在许多情况下不存在分离超平面,因此没有最大间隔分类器。在这种情况下优化问题(式 10.9 )没有\(M > 0\) 的解。图 10.4 显示了一个例子。在这种情况下我们不能精确分离这两个类别。
然而正如我们将在下一节中看到的我们可以扩展分离超平面的概念,以开发一个几乎分离类别的超平面使用所谓的软间隔 。最大间隔分类器对不可分离情况的推广被称为支持向量分类器
然而,现实世界中的金融或是商业数据,几乎永远不可能像上图那样被一条绝对的直线完美切开。在这个更贴近现实的双色散点图中(也是由 Python 生成的含有噪声的两个二维正态分布),蓝紫两军不可避免地在中心区域发生了惨烈的近身肉搏和重叠。 面对这种“犬牙交错”的阵地,最大间隔分类器那套“绝对不能有任何一点越界或分类错误”的铁律彻底破产了(数学上表现为那个严苛的拉格朗日优化问题无解)。为了在这个绝望的混沌中找到出路,统计学家们退而求其次,提出了一个无比精妙的妥协方案——允许一部分士兵“牺牲”。这就引出了下一个进阶模型:支持向量分类器(Support Vector Classifier, SVC) 。
42 ) # 设置随机种子确保结果可复现 # 从均值为(0,0)的二维正态分布中采样30个类别1的数据点 = np.random.multivariate_normal([0 , 0 ], [[1 , 0 ], [0 , 1 ]], 30 ) # 生成多元正态分布随机样本 # 从均值为(1,1)的二维正态分布中采样30个类别-1的数据点(与类别1存在重叠) = np.random.multivariate_normal([1 , 1 ], [[1 , 0 ], [0 , 1 ]], 30 ) # 生成多元正态分布随机样本 = plt.subplots(figsize= (10 , 10 )) # 创建10×10英寸的画布 # 绘制类别1的散点(蓝色) 0 ], class1_overlap[:, 1 ], # 在子图中绑制散点图 = 'blue' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 定义c变量 # 绘制类别-1的散点(紫色) 0 ], class2_overlap[:, 1 ], # 在子图中绑制散点图 = 'purple' , label= '类别 -1' , s= 80 , alpha= 0.7 ) # 定义c变量 'X₁' , fontsize= 12 ) # 设置X轴标签 'X₂' , fontsize= 12 ) # 设置Y轴标签 '不可分离的数据' , fontsize= 14 , fontname= 'SimHei' ) # 设置图形标题 = 'upper left' , fontsize= 10 ) # 在左上角显示图例 True , alpha= 0.3 ) # 添加半透明网格线 - 4 , 5 ) # 设置X轴显示范围 - 4 , 5 ) # 设置Y轴显示范围 # 自动调整布局 # 显示图形
支持向量分类器
支持向量分类器概述
在 图 10.4 例子中我们看到属于两个类别的观测不一定可以被超平面分离。事实上,即使分离超平面确实存在也有实例表明基于分离超平面的分类器可能并不理想。基于分离超平面的分类器将必然完美地分类所有训练观测这可能导致对单个观测的敏感性。图 10.5 显示了一个例子。图 10.5 右面板中添加单个观测导致最大间隔超平面的剧烈变化。得到的最大间隔超平面并不令人满意——一方面,它的间隔非常小。这是有问题的因为正如前面所讨论的观测到超平面的距离可以被视为我们对该观测被正确分类的置信度的度量。此外最大间隔超平面对单个观测的变化极其敏感这一事实表明它可能过拟合了训练数据点
在这种情况下,我们可能愿意考虑基于超平面的分类器它不能完美分离两个类别以获得
也就是说,为了更好地对剩余观测进行分类,错误分类少数几个训练观测可能是值得的。支持向量分类器 ,有时称为软间隔分类器 ,正是这样做的。它不是寻求尽可能大的间隔,使每个观测不仅位于超平面的正确一侧,而且还位于间隔的正确一侧;我们允许一些观测位于间隔的错误一侧,甚至位于超平面的错误一侧。间隔是”软的”,因为它可以被一些训练观测违反。
支持向量分类器的细节
支持向量分类器根据测试观测位于超平面的哪一侧对其进行分类。选择超平面以正确地将大多数训练观测分成两个类别但可能会错误分类少数观测。它是以下优化问题的解
\[
\max_{\beta_0, \beta_1, \ldots, \beta_p, \epsilon_1, \ldots, \epsilon_n, M} \quad M
\tag{10.12}\]
约束于
\[
\sum_{j=1}^{p} \beta_j^2 = 1
\tag{10.13}\]
\[
y_i (\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_p x_{ip}) \geq M(1 - \epsilon_i)
\tag{10.14}\]
\[
\epsilon_i \geq 0, \quad \sum_{i=1}^{n} \epsilon_i \leq C
\tag{10.15}\]
其中\(C\) 是一个非负调优参数。如(式 10.14 )所示\(M\) 是间隔的宽度;我们试图使这个量尽可能大。在(式 10.14 )中\(\epsilon_1, \ldots, \epsilon_n\) 是松弛变量 ,允许个别观测位于间隔的错误一侧或超平面的错误一侧。一旦我们解决了(式 10.12 )–(式 10.15 ),我们就像以前一样分类测试观测\(x^*\) ,只需确定它位于超平面的哪一侧。
问题(式 10.12 )–(式 10.15 )似乎很复杂但可以通过一系列简单观察来深入了解其行为。首先松弛变量\(\epsilon_i\) 告诉我们第\(i\) 个观测相对于超平面和间隔的位置。如果\(\epsilon_i = 0\) ,那么第\(i\) 个观测位于间隔的正确一侧。如果\(\epsilon_i > 0\) ,那么第\(i\) 个观测位于间隔的错误一侧,我们说第\(i\) 个观测违反了间隔。如果\(\epsilon_i > 1\) ,那么它位于超平面的错误一侧。
我们现在考虑调优参数\(C\) 的作用。在(式 10.15 )中\(C\) 限制了\(\epsilon_i\) 的总和,因此它决定了我们将容忍的间隔(和超平面)违规的数量和严重程度。我们可以将\(C\) 视为间隔可以被\(n\) 个观测违规的预算。如果\(C = 0\) ,那么没有违规,间隔的预测必须是\(\epsilon_1 = \cdots = \epsilon_n = 0\) ,在这种情况下,(式 10.12 )–(式 10.15 )简单地等于最大间隔超平面优化问题。
对于\(C > 0\) ,不超过\(C\) 个观测可以在超平面的错误一侧因为如果观测在超平面的错误一侧那么\(\epsilon_i > 1\) ,并且(式 10.15 )要求\(\sum_{i=1}^{n} \epsilon_i \leq C\) 。随着预算\(C\) 增加,我们对间隔违规变得更加容忍因此间隔将变宽。相反随着\(C\) 减小,我们对间隔违规的容忍度降低因此间隔变窄。
在实践中,\(C\) 通常被视为通过交叉验证选择的调优参数。正如我们在本书中看到的调优参数\(C\) 控制统计学习技术的偏差-方差权衡。当\(C\) 较小时我们寻求很少被违反的窄间隔这相当于高度拟合数据的分类器,可能具有低偏差但高方差。另一方面,当\(C\) 较大时间隔较宽,我们允许更多的违规这相当于不太努力地拟合数据并获得可能有更高偏差但方差更低的分类器
提示:调优参数C的作用
调优参数\(C\) 控制支持向量分类器的偏差-方差权衡:
大\(C\) :
窄间隔
对违规容忍度低
可能过拟合训练数据低偏差高方差
类似于最大间隔分类器
小\(C\) :
宽间隔
对违规容忍度高
可能欠拟合训练数据高偏差低方差
更鲁棒对新数据泛化更好
在心脏数据上的实际应用中,我们通常使用交叉验证来选择\(C\) 的值使测试误差最小化。
数学推导:支持向量分类器的拉格朗日对偶
为了有效地解决带有不等式约束条件的支持向量分类器优化问题,并在后续自然地引入“核技巧(Kernel Trick)”,我们通常不直接求解原始(Primal)问题,而是求解它的拉格朗日对偶(Lagrangian Dual) 问题。
首先,将原始的支持向量分类器问题写成标准的凸二次规划(Convex Quadratic Programming)形式: \[ \min_{\beta, \beta_0, \epsilon} \frac{1}{2}\|\beta\|^2 + C \sum_{i=1}^n \epsilon_i \] 约束于: \[ y_i(\beta^T x_i + \beta_0) \geq 1 - \epsilon_i, \quad \epsilon_i \geq 0 \quad \forall i \]
我们引入拉格朗日乘子 \(\alpha_i \geq 0\) 对应于主要约束,\(\mu_i \geq 0\) 对应于松弛变量非负约束,构建拉格朗日函数 : \[ L(\beta, \beta_0, \epsilon, \alpha, \mu) = \frac{1}{2}\|\beta\|^2 + C \sum_{i=1}^n \epsilon_i - \sum_{i=1}^n \alpha_i [y_i(\beta^T x_i + \beta_0) - (1 - \epsilon_i)] - \sum_{i=1}^n \mu_i \epsilon_i \]
为了找到对偶函数的极值,我们对\(L\) 分别对\(\beta\) 、\(\beta_0\) 、\(\epsilon_i\) 求偏导并令其为零。 1. \(\frac{\partial L}{\partial \beta} = 0 \Rightarrow \beta = \sum_{i=1}^n \alpha_i y_i x_i\) (这表明法向量\(\beta\) 仅仅是数据点 \(x_i\) 的线性组合) 2. \(\frac{\partial L}{\partial \beta_0} = 0 \Rightarrow \sum_{i=1}^n \alpha_i y_i = 0\) 3. \(\frac{\partial L}{\partial \epsilon_i} = 0 \Rightarrow \alpha_i + \mu_i = C\)
将这三个最优性条件代回拉格朗日函数,消去\(\beta\) 、\(\beta_0\) 和\(\epsilon_i\) 后,我们就得到了拉格朗日对偶优化问题 (仅关于乘子 \(\alpha\) 的最大化任务): \[ \max_{\alpha} \left( \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j \langle x_i, x_j \rangle \right) \] 约束于: \[ 0 \leq \alpha_i \leq C, \quad \sum_{i=1}^n \alpha_i y_i = 0 \]
这个对偶形式的两个至关重要的解析优越性: 1. 预测函数依赖稀疏 :根据卡罗需-库恩-塔克(KKT)互补松弛条件,绝大多数分类正确的非支持向量对应的拉格朗日乘子\(\alpha_i = 0\) 。预测新观测 \(x^*\) 时,决策边界仅依赖于少数支持向量,\(f(x^*) = \sum_{i \in \text{SV}} \alpha_i y_i \langle x^*, x_i \rangle + \beta_0\) 。 2. 内积形式分离 :优化目标函数和最终的决策函数完全不需要直接访问原始特征向量\(x_i\) ,我们需要且仅需要的运算仅仅是样本对之间的内积 \(\langle x_i, x_j \rangle\) 。这为后续处理无限维非线性映射特征空间的“核技巧”直接奠定了最重要的数学基础。
优化问题(式 10.12 )–(式 10.15 )有一个非常有趣的性质:事实证明,只有位于间隔上或违反间隔的观测会影响超平面从而影响获得的分类器。换句话说严格位于间隔正确一侧的观测不影响支持向量分类器!改变该观测的位置不会改变分类器只要其位置保持在间隔的正确一侧。直接位于间隔上或对其类别在间隔错误一侧的观测被称为支持向量 。这些观测确实影响支持向量分类器
支持向量分类器的决策规则仅基于训练观测的潜在小子集支持向量)这一事实意味着它对远离超平面的观测行为相当鲁棒。这一性质与我们前面看到的其他一些分类方法如线性判别分析明显不同。回想一个LDA分类规则依赖于每个类别中所有 观测的均值以及使用所有 观测计算的类内协方差矩阵。
支持向量机
我们首先讨论将线性分类器转换为产生非线性决策边界的分类器的一般机制。然后我们介绍支持向量机,它以自动方式做到这一点。
具有非线性决策边界的分类
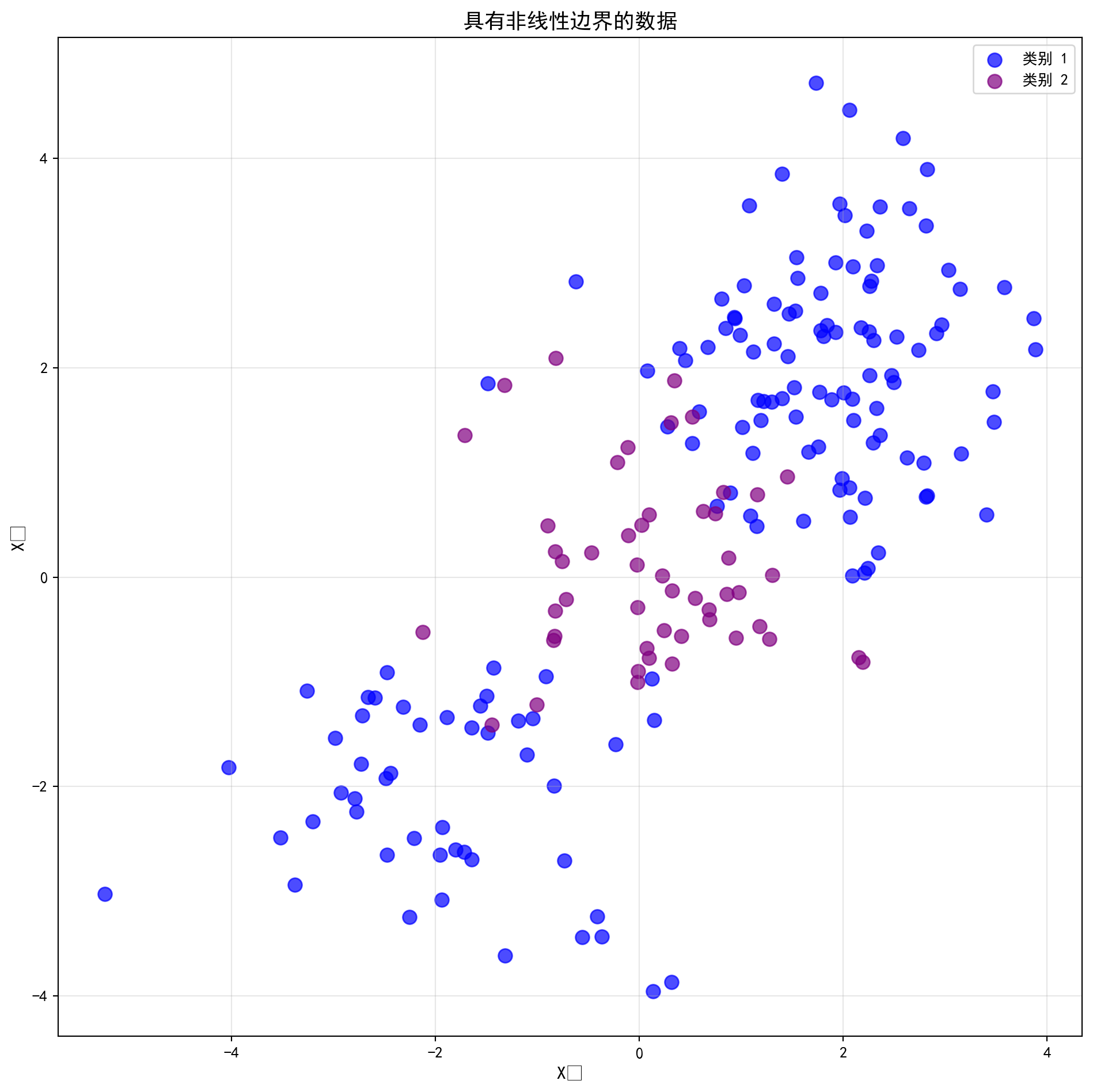
支持向量分类器是二元分类设置中分类的自然方法,如果两个类别之间的边界是线性的。然而在实践中,我们有时面临非线性类别边界。例如考虑 图 10.6 左面板中的数据。显然支持向量分类器或任何线性分类器在这里将表现很差。事实上,图 10.6 右面板中显示的支持向量分类器在这里毫无用处。
在 章节 8
在支持向量分类器的情况下,我们可以通过类似的方式解决类别之间可能存在的非线性边界问题方法是使用二次、三次甚至更高阶多项式的预测变量来扩大特征空间。例如,不是使用\(p\) 个特征\(X_1, X_2, \ldots, X_p\) 拟合支持向量分类器,我们可以使用\(2p\) 个特征\(X_1, X_1^2, X_2, X_2^2, \ldots, X_p, X_p^2\) 拟合支持向量分类器。
在扩大的特征空间的结果分类器的决策边界实际上是线性的。但在原始特征空间中,决策边界的形式为\(q(x) = 0\) ,其中\(q\) 是二次多项式,其解通常是非线性的。
支持向量机
支持向量机 (SVM)是支持向量分类器的扩展,其结果是以特定方式扩大特征空间,使用核 。我们现在讨论这个扩展,其细节有些复杂,超出了本书的范围。然而,主要思想如@sec-non-linear-boundaries 所述,我们可能想要扩大我们的特征空间以容纳类别之间的非线性边界。支持向量机,我们接下来介绍,允许我们以导致有效计算的方式扩大支持向量分类器使用的特征空间。
事实证明,支持向量分类器问题的解仅涉及观测的内积 (而不是观测本身)。两个\(r\) 向量\(a\) 和\(b\) 的内积定义为: \[ \langle a, b \rangle = \sum_{i=1}^{r} a_i b_i \]
因此,两个观测\(x_i\) 和\(x_i'\) 的内积由下式给出:
\[
\langle x_i, x_i' \rangle = \sum_{j=1}^{p} x_{ij} x_{i'j}
\tag{10.16}\]
可以证明,线性支持向量分类器可以表示为
\[
f(x) = \beta_0 + \sum_{i=1}^{n} \alpha_i \langle x, x_i \rangle
\tag{10.17}\]
此外,为了估计参数\(\alpha_1, \ldots, \alpha_n\) 和\(\beta_0\) ,我们需要的只是所有训练观测对之间的内积\(\langle x_i, x_i' \rangle\) 。
注意,在(式 10.17 )中为了评估函数\(f(x)\) ,我们需要计算新点\(x\) 和每个训练点\(x_i\) 之间的内积。然而事实证明,只有支持向量的\(\alpha_i\) 非零。因此如果\(S\) 是这些支持点的索引集合我们可以将任何形式为(式 10.17 )的解函数重写为
\[
f(x) = \beta_0 + \sum_{i \in S} \alpha_i \langle x, x_i \rangle
\tag{10.18}\]
总结起来为了表示线性分类器\(f(x)\) 并计算其系数,我们只需要内积。
现在假设每次内积(式 10.16 )出现在表示(式 10.17 )中或支持向量分类器的解的计算中时,我们用以下形式的内积推广来替换它:
\[
K(x_i, x_i')
\tag{10.19}\]
其中\(K\) 是我们称为核 的函数。核是量化两个观测相似度的函数。例如我们可以简单地取
\[
K(x_i, x_i') = \sum_{j=1}^{p} x_{ij} x_{i'j}
\tag{10.20}\]
这只会给我们带回支持向量分类器。方程@eq-linear-kernel 被称为线性核 ,因为支持向量分类器在特征中是线性的;线性核本质上使用皮尔逊标准)相关系数量化一对观测的相似度。
但人们可以选择(式 10.19 )的另一种形式。例如,人们可以将\(\sum_{j=1}^{p} x_{ij} x_{i'j}\) 的每个实例替换为以下量
\[
K(x_i, x_i') = (1 + \sum_{j=1}^{p} x_{ij} x_{i'j})^d
\tag{10.21}\]
这被称为多项式核 ,其中\(d\) 是正整数。使用\(d > 1\) 的这种核,而不是标准的线性核(式 10.20 ),在支持向量分类器算法中导致更灵活的决策边界。它本质上是在更高维空间中拟合支持向量分类器,该空间涉及\(d\) 次多项式,而不是原始特征空间。当支持向量分类器与非线性的核如(式 10.21 )结合时得到的分类器被称为支持向量机
多项式核(式 10.21 )是可能的非线性核的一个例子但替代方案比比皆是。另一个流行的选择是径向核 ,它采用以下形式
\[
K(x_i, x_i') = \exp\left(-\gamma \sum_{j=1}^{p} (x_{ij} - x_{i'j})^2\right)
\tag{10.22}\]
在(式 10.22 )中,\(\gamma\) 是一个正常数。
理论深度:核函数的充分必要条件(Mercer 定理)
既然我们将内的\(\langle x_i, x_i' \rangle\) 替换为了任意选定的核函数 \(K(x_i, x_i')\) ,那么是否任何二元相似度函数都可以作为核函数?答案是否定的。如果不满足特定条件,前面推导出的拉格朗日对偶凸二次规划问题可能不收敛、具有负的间隔甚至是无解。
默瑟定理(Mercer’s Theorem) 给出了一个函数能够作为支持向量机有效核函数的充分必要条件。 对于任何一个对称函数\(K(x, z) = K(z, x)\) ,它是一个有效的核函数,当且仅当对于任意给定的有限数据集 \(\{x_1, \ldots, x_n\}\) ,由该函数构成的 \(n \times n\) 核矩阵(或者叫 Gram 矩阵 \(\mathbf{K}\) ,其第\((i, j)\) 个元素为\(K(x_i, x_j)\) )始终是半正定矩阵(Positive Semi-Definite Matrix) 。
在代数上,这意味着对于任何非零向量 \(\mathbf{v} \in \mathbb{R}^n\) ,这种对称矩阵的二次型始终非负: \[ \mathbf{v}^T \mathbf{K} \mathbf{v} = \sum_{i=1}^n \sum_{j=1}^n v_i v_j K(x_i, x_j) \geq 0 \]
理论意义 :如果一个函数满足严苛的 Mercer 条件,根据泛函分析理论,就绝对存在一个对应的高维甚至无限维的特征空间映射 \(\phi(x)\) ,使得\(K(x, z)\) 恰好等于在这个高维空间中的内积\(\langle \phi(x), \phi(z) \rangle\) 。
核技巧(Kernel Trick)之所以被称为“trick”,其精妙之处正在于:我们不需要显式地去计算或者甚至根本不需要知道这个极其复杂的特征映射 \(\phi(\cdot)\) 是什么构造 (例如径向基核映射的高斯特征空间是无穷维度的)。我们在计算复杂度受限在原始特征空间的\(\mathbb{R}^p\) )的同时,在数学本质上实现了在无穷维空间里面精确匹配的线性超平面切割。这让看似不可能的大规模高维非线性分类任务在计算上变得轻而易举。
提示:核函数的直观理解
核函数\(K(x_i, x_j)\) 衡量两个观测\(x_i\) 和\(x_j\) 之间的相似度:
线性核 (\(K(x_i, x_j) = \langle x_i, x_j \rangle\) ): 相似度就是向量的点积,相当于标准化相关系数多项式核 (\(K(x_i, x_j) = (1 + \langle x_i, x_j \rangle)^d\) ): 考虑特征之间的多项式交互径向核 (RBF): 相似度随欧氏距离指数衰减
径向核工作原则如果测试观测\(x^*\) 在欧氏距离上远离训练观测\(x_i\) ,那么\(\sum_{j=1}^{p} (x^*_j - x_{ij})^2\) 将很大因此\(K(x^*, x_i) = \exp(-\gamma \sum_{j=1}^{p} (x^*_j - x_{ij})^2)\) 将非常小。这意味着在(式 10.18 )中\(x_i\) 在f(x^*)$中将几乎不起作用。因此径向核具有非常局部的行为,只有附近的训练观测才会影响测试观测的类别标签。
SVM与多类分类
到目前为止我们的讨论仅限于二元分类的情况即二类设置。我们如何将SVM扩展到我们有任意数量类别的更一般情况事实证明,SVM所基于的分离超平面的概念不能自然地适应多于两个类别。尽管已经提出了将SVM扩展到\(K\) 类情况的一些方法,但最流行的两种是一对一 和一对其余 方法。我们在这里简要讨论这两种方法。
一对一分类
假设我们想要使用SVM进行分类,并且有\(K > 2\) 个类别。一对一 或成对 方法构造\(\binom{K}{2}\) 个SVM,每个都比较一对类别。例如,其中一个SVM可能将第\(k\) 个类别编码为\(+1\) ,与第\(k'\) 个类别编码为\(-1\) 进行比较。我们使用\(\binom{K}{2}\) 个分类器中的每一个对测试观测进行分类,并计算测试观测分配给每个\(K\) 类别的次数。最终分类是通过将测试观测分配给它在这些成对分类中最常被分配的类别来执行的。
一对其余分类
一对其余 方法是使用SVM在\(K > 2\) 类情况下的替代程序。我们拟合\(K\) 个SVM,每次将\(K\) 个类别中的一个与剩余的\(K-1\) 个类别进行比较。设\(\beta_0^k, \beta_1^k, \ldots, \beta_p^k\) 表示拟合比较第\(k\) 个类别(编码为\(+1\) )与其他类别(编码为\(-1\) )的SVM得到的结果参数。设\(x^*\) 表示测试观测。我们将观测分配给\(\beta_0^k + \beta_1^k x^*_1 + \beta_2^k x^*_2 + \cdots + \beta_p^k x^*_p\) 最大的类别,因为这相当于对测试观测属于第\(k\) 个类别而不是任何其他类别具有高水平的置信度。
与逻辑回归的关系
当SVM在1990年代中期首次引入时它们在统计和机器学习界引起了相当大的轰动。这部分归功于它们的良好性能、良好的营销,也归功于其潜在方法看起来既新颖又神秘。找到尽可能好地分离数据同时允许一些分离违规的超平面的想法,似乎与用于分类的经典方法(如逻辑回归和线性判别分析明显不同。此外使用核扩大特征空间以容纳非线性类别边界的想法似乎是一个独特而有价值的特征。
然而从那时起,SVM与其他更经典的统计方法之间的深厚联系已经出现。事实证明人们可以重写拟合支持向量分类器的准则,以损失+惩罚”的形式表示
\[
\min_{\beta_0, \beta_1, \ldots, \beta_p} \left\{ \sum_{i=1}^{n} \max[0, 1 - y_i f(x_i)] + \lambda \sum_{j=1}^{p} \beta_j^2 \right\}
\tag{10.23}\]
其中\(\lambda\) 是一个非负调优参数。当\(\lambda\) 较大时\(\beta_1, \ldots, \beta_p\) 较小,对间隔的违规容忍更多,将导致低方差但高偏差的分类器。当\(\lambda\) 较小时对间隔的违规很少发生;这相当于高方差但低偏差的分类器
(式 10.23 )采用我们在本书中反复看到的”损失+惩罚”形式:
\[
\min_{\beta_0, \beta_1, \ldots, \beta_p} \{ L(X, y, \beta) + \lambda P(\beta) \}
\tag{10.24}\]
在(式 10.24 )中,\(L(X, y, \beta)\) 是某个损失函数量化由参数\(\beta\) 参数化的模型对数据\((X, y)\) 的拟合程度,\(P(\beta)\) 是对参数向量\(\beta\) 的惩罚函数,其效果由非负调优参数\(\lambda\) 控制。
对于(式 10.23 ),损失函数采用以下形式: \[ L(X, y, \beta) = \sum_{i=1}^{n} \max[0, 1 - y_i (\beta_0 + \beta_1 x_{i1} + \dots + \beta_p x_{ip})] \]
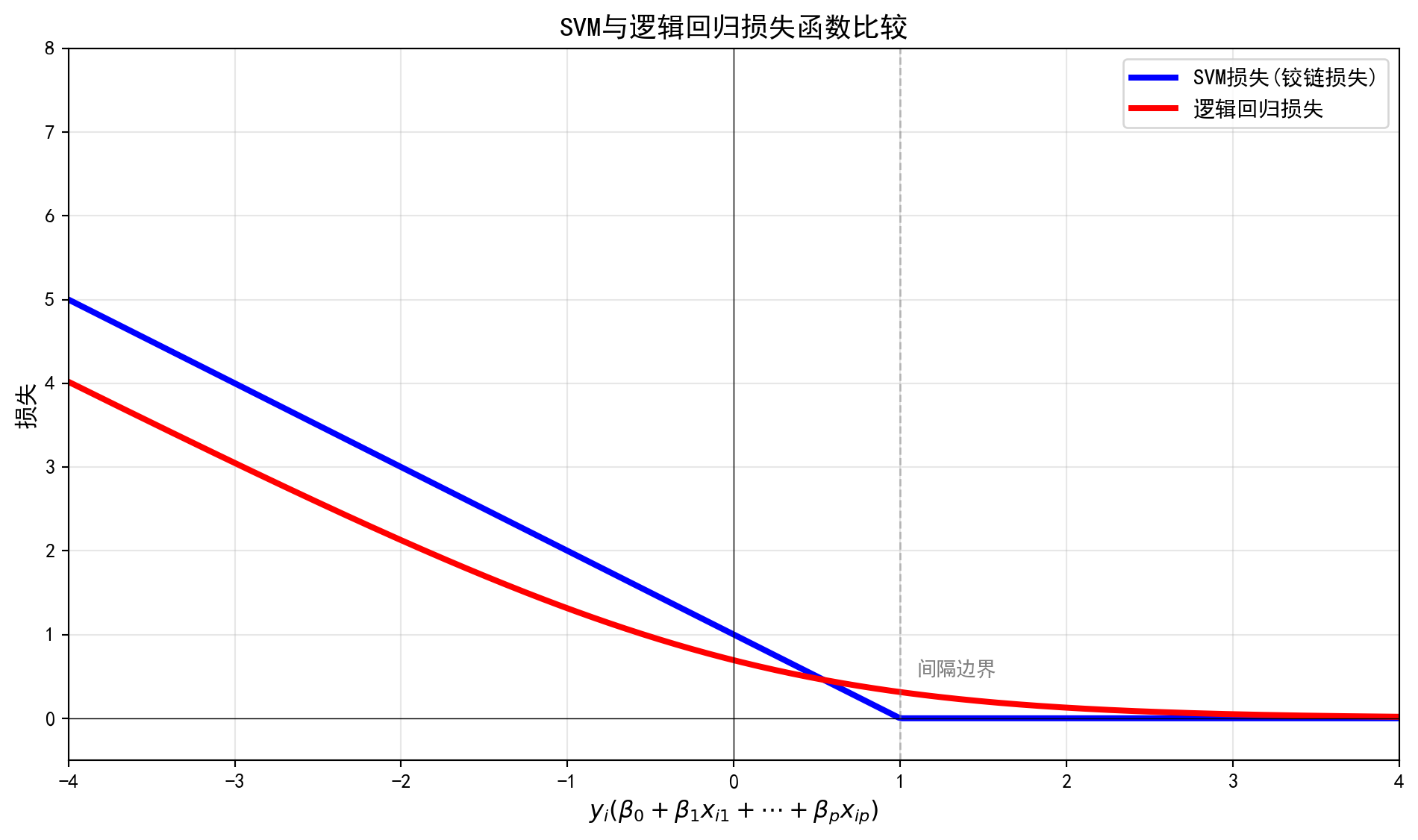
这被称为铰链损失 ,如图所示。然而事实证明,铰链损失函数与逻辑回归中使用的损失函数密切相关。
支持向量分类器的一个有趣特征是只有支持向量在获得的分类器中起作用位于间隔正确一侧的观测不影响它。这是由于图中的损失函数对于\(y_i (\beta_0 + \beta_1 x_{i1} + \dots + \beta_p x_{ip}) \geq 1\) 的观测正好为零这些对应于位于间隔正确一侧的观测。相反逻辑回归的损失函数在任何地方都不为零。但对于远离决策边界的观测来说非常小。由于它们的损失函数相似,逻辑回归和支持向量分类器通常给出非常相似的结果。当类别很好地分离时,SVM往往比逻辑回归表现得更好在更多重叠区域中,逻辑回归通常更受青睐。
图 10.7 比较了SVM(铰链)损失和逻辑回归损失。
当我们剥去支持向量机那华丽的几何与泛函分析外衣,从最朴素的机器学习优化视角(损失函数 + 正则化惩罚项)重新审视它时,会震惊地发现:它和我们早在 章节 5 “铰链损失”(Hinge Loss) 。 你可以清晰地看到两者的行为逻辑简直如出一辙:当模型对于某个样本的正确分类充满信心(即横坐的\(y_i(\beta^T x_i) \gg 0\) ),两者给予的惩罚都极低;而一旦模型出现了严重的南辕北辙(横坐标 \(< 0\) ),两者都会降下极其严厉的线性或超线性惩罚。它们唯一的,同时也是极其关键的区别在于那条蓝色折线在横轴 x=1 处那个干脆利落的“转折点”:对于逻辑回归而言,即使你预测正确了,它依然会贪婪地希望你预测得“更对一点”(红色曲线永远不会真正触底了0);而支持向量机的铰链损失则表现出了一种大师般的豁达——只要样本以足够安全的距离(至少了1)跨过了间隔防线,蓝线便瞬间归零,模型根本不在乎它究竟跑到了防线后的多远。正是铰链损失这种“只要过关就绝不苛求”的零容忍度截断特性,造就了支持向量机模型中那极具稀疏性的决策骨架(绝大多数点对应的拉格朗日乘子\(\alpha_i\) 的0,只有位于边缘的支持向量才能发声)。
import numpy as np # 导入numpy库用于数值计算 import matplotlib.pyplot as plt # 导入matplotlib用于数据可视化 = np.linspace(- 4 , 4 , 400 ) # 在[-4,4]区间生成400个等距点作为函数输入 = np.maximum(0 , 1 - x) # 计算铰链损失: max(0, 1-x) = np.log(1 + np.exp(- x)) # 计算逻辑回归损失: log(1+exp(-x)) = plt.subplots(figsize= (10 , 6 )) # 创建10×6英寸的画布 'b-' , linewidth= 3 , label= 'SVM损失(铰链损失)' ) # 绘制铰链损失曲线(蓝色) 'r-' , linewidth= 3 , label= '逻辑回归损失' ) # 绘制逻辑回归损失曲线(红色) '$y_i ( \\ beta_0 + \\ beta_1 x_ {i1} + \\ cdots + \\ beta_p x_ {ip} )$' , fontsize= 12 ) # 设置X轴标签(LaTeX公式) '损失' , fontsize= 12 ) # 设置Y轴标签 'SVM与逻辑回归损失函数比较' , fontsize= 14 , fontname= 'SimHei' ) # 设置图形标题 = 11 ) # 显示图例 True , alpha= 0.3 ) # 添加半透明网格线 - 4 , 4 ) # 设置X轴显示范围 - 0.5 , 8 ) # 设置Y轴显示范围 = 0 , color= 'k' , linewidth= 0.5 ) # 绘制水平参考线(零损失线) = 0 , color= 'k' , linewidth= 0.5 ) # 绘制垂直参考线(决策边界处) = 1 , color= 'gray' , linewidth= 1 , linestyle= '--' , alpha= 0.5 ) # 绘制间隔边界的垂直虚线 1.1 , 0.5 , '间隔边界' , fontsize= 10 , color= 'gray' ) # 在间隔边界旁添加文字标注 # 自动调整布局 # 显示图形
实验:支持向量机
在本节中,我们使用sklearn.svm库来演示支持向量分类器和支持向量机。
支持向量分类器
我们现在使用sklearn中的SupportVectorClassifier()函数(缩写为SVC())来拟合给定参数\(C\) 值的支持向量分类器。C参数允许我们指定对间隔违规的代价。当cost参数较小时,间隔将很宽,许多支持向量将位于间隔上或违反间隔。当C参数较大时,间隔将很窄,位于间隔上或违反间隔的支持向量很少。
我们使用二维数据集来演示支持向量分类器以便我们可以绘制结果决策边界。
说完了枯燥的理论,让我们马上在代码实验室里把手弄脏! 第一段出场的代码演示了最纯粹的线性支持向量分类器(SVC(kernel='linear')) 。我们在一个二维的画布上随机洒落了代表两个类别的100个点。为了让你深入理解参数\(C\) 的魔力,代码首先用\(C=10\) (一个相对严厉,不怎么容忍错误的“小预算”)拟合了模型,接着马上又放宽标准,用\(C=0.1\) (一个极度宽容,允许大量点越界甚至分错的“大预算”)重新拟合了一次。 当你执行这段代码并在弹出的两张对比图中切换时:在 \(C=10\) 的严苛图景里,中间代表间隔的虚线被挤压得非常窄,只有零星几个点被虚线穿过并且被红色圆圈标记为支持向量。这时的分类器神经紧绷,试图尽可能苛刻地区分每一个点,其潜在的代价是在面对未来的新数据时可能因为过于敏感而过拟合。 而在 \(C=0.1\) 的宽松图景中,那条间隔通道瞬间被无限撑大,大量的蓝色和紫色点直接涌入了缓冲地带,甚至堂而皇之地跨过了中间那条代表生死线的实线(红色圆圈标记的支持向量数量急剧暴增)。这并不是模型崩溃了,而是它在告诉我们:它主动放弃了对局部微小冲突的死缠烂打,转而寻求一条能稳住大局、容错率极高的“宽容之道”。这种高偏差、低方差的设定,往往在面对真实世界中那充斥着噪音的金融数据时,能活得更久。
import numpy as np # 导入numpy库用于数值计算 import matplotlib.pyplot as plt # 导入matplotlib用于数据可视化 from sklearn.svm import SVC # 导入支持向量分类器 # 设置随机种子以确保结果可复现 42 ) # 设置随机种子确保结果可复现 # 生成100个二维标准正态分布的随机数据点 = np.random.randn(100 , 2 ) # 构建特征矩阵 # 创建类别标签:前50个为-1类,后50个为+1类 = np.array([- 1 ] * 50 + [1 ] * 50 ) # 构建NumPy数组 # 将+1类的数据点整体向右上方平移1个单位,制造类别间的偏移 == 1 ] += 1 # 执行数据处理操作 # 使用C=10拟合线性支持向量分类器(较严格的间隔约束) = SVC(C= 10 , kernel= 'linear' ) # 初始化支持向量机模型 # 在二维数据上训练线性SVM模型 # 训练/拟合模型
SVC(C=10, kernel='linear') In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
定义一个通用的SVM决策边界可视化函数,用于展示不同参数下的分类效果:
def visualize_svm_boundary(features, labels, model, title= '支持向量分类器' ): # 定义函数visualize_svm_boundary '''绘制SVM的决策边界、间隔带和支持向量的可视化函数''' # 设置参数 = (10 , 10 )) # 创建正方形画布 # 绘制类别-1的数据点(蓝色) == - 1 ][:, 0 ], features[labels == - 1 ][:, 1 ], # 绑制散点图 = 'blue' , label= '类别 -1' , s= 80 , alpha= 0.7 ) # 定义c变量 # 绘制类别+1的数据点(紫色) == 1 ][:, 0 ], features[labels == 1 ][:, 1 ], # 绑制散点图 = 'purple' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 定义c变量 = plt.gca() # 获取当前坐标轴对象 = ax.get_xlim() # 获取x轴当前范围 = ax.get_ylim() # 获取y轴当前范围 # 在x轴范围内生成300个均匀间隔的网格点 = np.linspace(xlim[0 ], xlim[1 ], 300 ) # 生成等间隔序列 # 在y轴范围内生成300个均匀间隔的网格点 = np.linspace(ylim[0 ], ylim[1 ], 300 ) # 生成等间隔序列 # 创建二维网格矩阵用于计算决策函数值 = np.meshgrid(y_grid, x_grid) # 生成网格坐标矩阵 # 将网格点展平为二维坐标数组 = np.vstack([mesh_x.ravel(), mesh_y.ravel()]).T # 转置矩阵 # 计算每个网格点的决策函数值并重塑为网格形状 = model.decision_function(grid_points).reshape(mesh_x.shape) # 查看数据维度 # 绘制决策边界(实线)和间隔边界(虚线)的等高线 = 'k' , levels= [- 1 , 0 , 1 ], # 在子图中绑制等高线 = 0.5 , linestyles= ['--' , '-' , '--' ]) # 完成模型/Pipeline构建 # 用红色空心圆标记支持向量 0 ], model.support_vectors_[:, 1 ], # 在子图中绑制散点图 = 200 , linewidth= 2 , facecolors= 'none' , edgecolors= 'red' , # 定义s变量 = '支持向量' ) # 设置图例标签文本 'X₁' , fontsize= 12 ) # 设置x轴标签 'X₂' , fontsize= 12 ) # 设置y轴标签 = 14 , fontname= 'SimHei' ) # 设置图形标题 = 10 ) # 显示图例 True , alpha= 0.3 ) # 添加半透明网格线 # 自动调整布局 # 显示图形
使用定义好的可视化函数,分别展示C=10(严格间隔)和C=0.1(宽松间隔)两种参数下的SVM决策边界对比效果:
# 绘制C=10(严格间隔约束)时的决策边界 # 执行数据处理操作 '支持向量分类器 (C=10)' )# 使用C=0.1重新拟合线性SVM(宽松的间隔约束,允许更多违规) = SVC(C= 0.1 , kernel= 'linear' ) # 初始化支持向量机模型 # 在相同数据上训练宽松约束的SVM模型 # 训练/拟合模型 # 绘制C=0.1(宽松间隔约束)时的决策边界 # 执行数据处理操作 '支持向量分类器 (C=0.1)' )
从以上两张图的对比中可以清晰观察到参数\(C\) 对分类器行为的决定性影响。在\(C=10\) 的图中,决策边界两侧的间隔带非常窄,被标记的支持向量数量较少——分类器采取了”严格执法”策略,努力精确分类每一个训练样本。而在\(C=0.1\) 的图中,间隔带显著变宽,大量数据点涌入间隔内部甚至越过决策边界,支持向量数量急剧增加。这意味着分类器为了获得更宽的间隔(即更好的泛化能力),主动容忍了更多的误分类。这正是偏差-方差权衡在SVM中的直观体现:小\(C\) 对应高偏差/低方差(更宽容),大\(C\) 对应低偏差/高方差(更严苛)。在金融市场中处理噪声较大的数据时,较小的\(C\) 值往往能避免过拟合,获得更稳健的预测性能。
支持向量机
为了使用非线性核拟合SVM,我们再次使用SVC()估计器。但是现在我们使用参数kernel的不同值。要拟合具有多项式核的SVM,我们使用kernel='poly',要拟合具有径向核的SVM,我们使用kernel='rbf'。在前一种情况下,我们还使用degree参数指定多项式核的度数这是(式 10.21 )中的\(d\) ),在后一种情况下,我们使用gamma指定径向基核(式 10.22 )的\(\gamma\) 值。
我们首先生成一些具有非线性类别边界的数据点
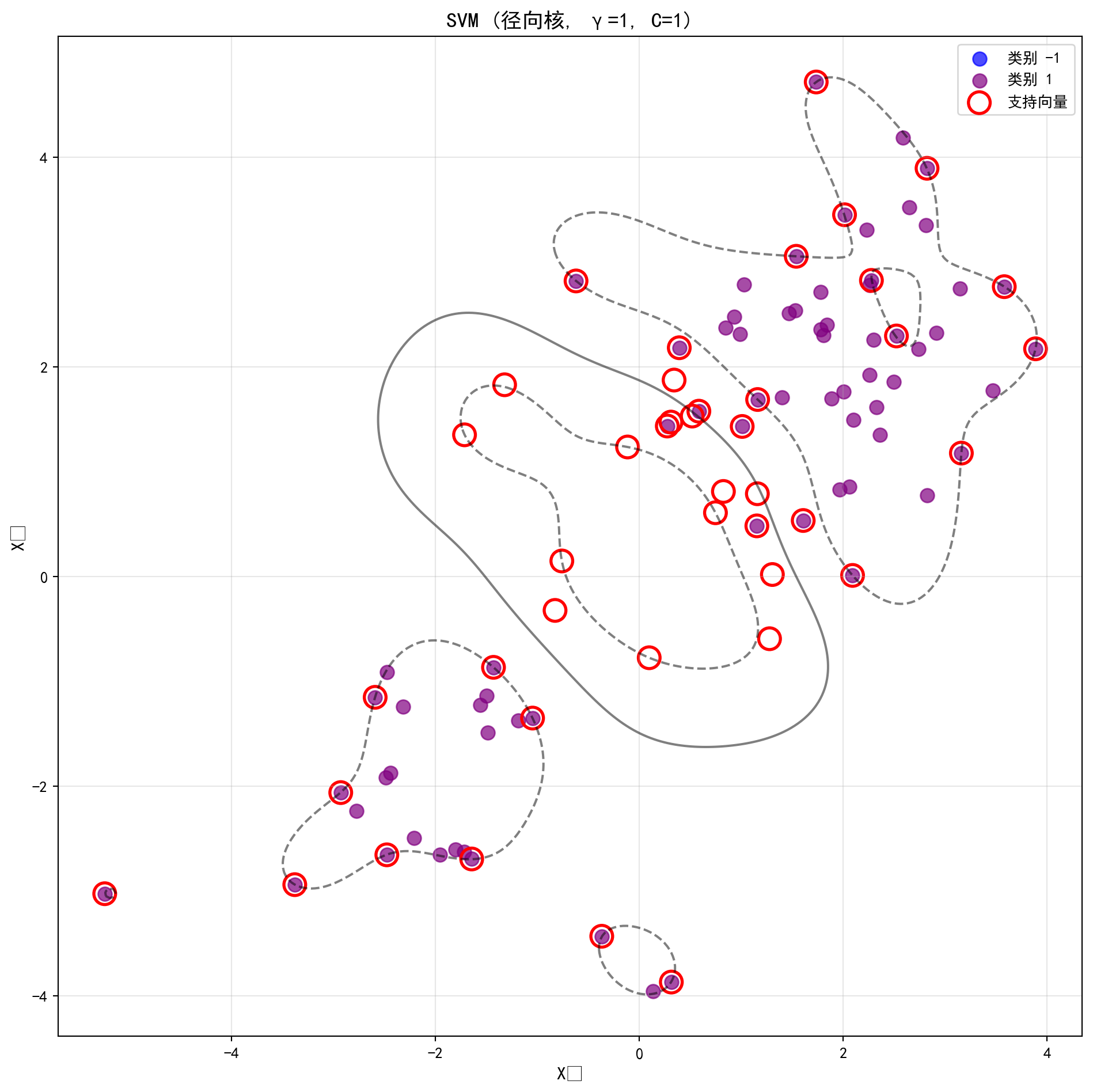
然而,当我们遇到那些天然呈现出“包围”或是“聚类嵌套”结构的非线性数据时(比如代码中我们在画布中心和外围分别生成了两波不同类别的数据簇),任何试图用直线去切分的努力都将沦为笑话。 这时候,支持向量机真正的究极形态——带有非线性核函数(Kernel)的 SVM 终于要登场了。在下面的Python 代码中,我们在实例化 SVC 时,仅仅将参数kernel从'linear'悄悄改成了'rbf'(Radial Basis Function,即传说中能将特征映射到无穷维空间的径向基高斯核)。这个极其微小的参数改动,在数学物理意义上,就好像直接赋予了模型“降维打击”的能力。 当你看到那张原本平坦的二维空间被画出了一个个类似等高线般完美闭合的非线性决策圈时,你才会真正体会到核函数的恐怖之处。为了不让这股强大的力量失控,代码后半部分非常严密地动用了GridSearchCV(网格搜索交叉验证)来对控制核函数复杂度的gamma和控制软间隔预算的C进行二维空间的地毯式扫描,在防止模型把噪音也当作花纹刻进基因里的同时,找到了泛化能力最强的“最佳参数组合”。
42 ) # 设置随机种子确保结果可复现 = np.random.randn(200 , 2 ) # 生成200个二维标准正态分布的随机数据点 100 ] += 2 # 将前100个点向右上方平移2个单位 100 :150 ] -= 2 # 将第101-150个点向左下方平移2个单位 = np.array([1 ] * 150 + [2 ] * 50 ) # 前150个为类别1,后50个为类别2 = (10 , 10 )) # 创建10×10英寸的画布 # 绘制类别1的散点(蓝色) # 绑制散点图 == 1 ][:, 0 ], non_linear_features[non_linear_labels == 1 ][:, 1 ],= 'blue' , label= '类别 1' , s= 80 , alpha= 0.7 ) # 定义c变量 # 绘制类别2的散点(紫色) # 绑制散点图 == 2 ][:, 0 ], non_linear_features[non_linear_labels == 2 ][:, 1 ],= 'purple' , label= '类别 2' , s= 80 , alpha= 0.7 ) # 定义c变量 'X₁' , fontsize= 12 ) # 设置X轴标签 'X₂' , fontsize= 12 ) # 设置Y轴标签 '具有非线性边界的数据' , fontsize= 14 , fontname= 'SimHei' ) # 设置图形标题 = 10 ) # 显示图例 True , alpha= 0.3 ) # 添加半透明网格线 # 自动调整布局 # 显示图形 from sklearn.model_selection import train_test_split, GridSearchCV # 导入数据分割与网格搜索交叉验证工具 # 将数据按50:50比例分割为训练集和测试集 # 划分训练集和测试集 = train_test_split(non_linear_features, non_linear_labels, test_size= 0.5 , random_state= 42 )= SVC(kernel= 'rbf' , gamma= 1 , C= 1 ) # 创建使用RBF径向基核的SVM分类器 # 在训练集上拟合模型 # 调用可视化函数绘制RBF核SVM的决策边界 # 执行数据处理操作 'SVM (径向核, γ=1, C=1)' )
从生成的两张图中可以观察到RBF核SVM的强大能力。第一张散点图展示了原始训练数据的分布:两个类别之间存在明显的非线性边界,数据呈现出环形或簇状的分布特征,这是线性分类器无法有效处理的典型场景。第二张决策边界图展示了RBF核SVM的拟合结果:分类器成功学习了一条光滑的非线性闭合曲线作为决策边界,将两个类别精确地分隔开来。这体现了核技巧的核心思想——通过径向基函数\(K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2)\) 将数据隐式映射到高维特征空间,在高维空间中寻找线性分隔超平面,其在原始空间的投影即呈现为非线性边界。当前参数设置\(\gamma=1\) , \(C=1\) 下,决策边界较为平滑,但是否为最优选择尚待验证。
运用GridSearchCV对RBF核的超参数进行网格搜索,寻找最优的C和gamma组合:
= 5 # 设置5折交叉验证 # 配置网格搜索:在C和gamma的组合空间中寻找最优超参数 = GridSearchCV(rbf_svm_classifier, # 初始化网格搜索交叉验证 'C' : [0.1 , 1 , 10 , 100 , 1000 ], # 设置参数 'gamma' : [0.5 , 1 , 2 , 3 , 4 ]}, # 定义字典键值对条目 = True , # 定义refit变量 = cv_folds, # 定义cv变量 = 'accuracy' ) # 定义scoring变量 # 在训练集上执行网格搜索 print (f'最佳参数 { svm_grid_search. best_params_} ' ) # 输出最优超参数组合 print (f'最佳交叉验证准确率: { svm_grid_search. best_score_:.4f} ' ) # 输出最优交叉验证准确率 = svm_grid_search.best_estimator_ # 提取最优模型用于后续预测 = optimal_rbf_svm.predict(rbf_features_test) # 使用模型进行预测 = np.mean(grid_predictions == rbf_labels_test) # 计算均值 print (f'测试集准确率: { test_accuracy:.4f} ' ) # 输出结果到控制台
最佳参数 {'C': 1, 'gamma': 0.5}
最佳交叉验证准确率: 0.9400
测试集准确率: 0.8700
网格搜索的输出结果揭示了RBF核超参数调优的重要信息。最佳参数组合为\(C=1\) 、\(\gamma=0.5\) ,其在5折交叉验证中的最佳准确率达到94.00%,而在独立测试集上的准确率为87.00%。交叉验证准确率与测试集准确率之间约7个百分点的差距属于合理范围,表明模型具有良好的泛化能力,未出现严重过拟合。\(C=1\) (中等惩罚强度)和\(\gamma=0.5\) (中等核宽度)的最优组合说明:对于这组模拟数据而言,过大的\(C\) (如100、1000)会导致模型过于复杂,过小的\(\gamma\) 则使决策边界过于平滑。这一结果也验证了前述关于RBF核SVM两个超参数共同控制模型复杂度的理论分析。
实验: 股票涨跌预测 (SVM)
作为支持向量机的实际应用,我们尝试预测海康威视股票(002415.XSHE)第二天的涨跌。这是一个非线性分类问题,因为股价走势受多种复杂因素影响。
在这个实验模块的最终章,我们再次踩下油门,直接驶入最残酷的量化预测实战。我们要用支持向量机的这套高维非线性利器,去预测A 股智能安防龙头——海康威视的第二日涨跌。 在这里,影响股价的因素(变量)不再是简单的二维坐标点,而是过去几天复杂的收益率动量积淀、横越过往数整周的波动率脉冲余波,以及当前股价与20日均线之间那如同皮筋般拉扯的偏离度。代码清洗完毕后,我们严格按照时间序列的前引后随顺序进行了切分。 请格外注意代码中的第 4 步(标准化) 。这绝对不是可有可无的过场动画。由于特征之间(比如动量百分比与 20 日均线绝对偏离度)的量级差异可能极其巨大,如果不使用 StandardScaler 进行强制归一,依靠计算空间距离(内积)来决定生死的SVM 会瞬间被那些数值绝对值巨大的特征所彻底蒙蔽。在使用经过严格时间序列切分验证的网格搜索(TimeSeriesSplit GridSearchCV)找到最佳的 RBF 核参数后,你将看到这台精密的高维几何机器在测试集上给出的最终盈利预测报告。
import pandas as pd # 导入pandas库用于数据框操作 from sklearn.svm import SVC # 导入支持向量分类器 from sklearn.model_selection import TimeSeriesSplit, GridSearchCV # 导入时间序列分割与网格搜索工具 from sklearn.preprocessing import StandardScaler # 导入标准化缩放器 from sklearn.metrics import accuracy_score, classification_report # 导入准确率与分类报告评估指标 import os # 导入os模块用于跨平台路径处理 # 根据操作系统自动选择本地数据路径 # 根据操作系统设置数据根目录路径 = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 拼接后复权股价数据文件的完整路径 = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5' ) # 构建数据文件的完整路径 # 直接读取后复权股价数据(本地数据已确认存在) = pd.read_hdf(stock_price_path).reset_index() # 读取后复权数据并重置MultiIndex # 筛选海康威视(002415.XSHE)的历史行情数据 # 创建数据副本避免修改原始数据 = stock_price_history[stock_price_history['order_book_id' ] == '002415.XSHE' ].copy()# 按日期升序排列,保证时间序列顺序正确 = haikang_data.sort_values('date' ) # 按指定列排序
基于海康威视的日频股价数据,构造用于SVM预测的技术指标特征和目标变量:
# 计算日收益率(收盘价的百分比变化) 'Ret' ] = haikang_data['close' ].pct_change() # 计算百分比变化(收益率) # 构造滞后收益率作为动量特征(分别滞后1/2/3/5个交易日) for lag_period in [1 , 2 , 3 , 5 ]: # 遍历循环 f'Lag_ { lag_period} ' ] = haikang_data['Ret' ].shift(lag_period) # 执行数据处理操作 # 计算过去20个交易日收益率的滚动标准差作为波动率特征(滞后1天避免前瞻偏差) 'Vol_20' ] = haikang_data['Ret' ].rolling(20 ).std().shift(1 ) # 计算标准差 # 计算20日均线价格(滞后1天) 'MA_20' ] = haikang_data['close' ].rolling(20 ).mean().shift(1 ) # 计算均值 # 计算收盘价相对于20日均线的偏离度百分比 'Dist_MA20' ] = haikang_data['close' ].shift(1 ) / haikang_data['MA_20' ] - 1 # 执行数据处理操作 # 构造目标变量:当日涨跌方向(1=上涨,-1=下跌) 'Target' ] = (haikang_data['Ret' ] > 0 ).astype(int ) # 转换数据类型 # 将收益率为零或负值的标记为-1(下跌类别) 'Ret' ] <= 0 , 'Target' ] = - 1 # 执行数据处理操作 # 删除因滞后和滚动窗口产生的缺失值行 = haikang_data.dropna() # 删除缺失值 # 若数据量超过2000条,仅保留最近2000条以提高计算效率 if len (haikang_features) > 2000 : # 计算元素数量 = haikang_features.iloc[- 2000 :] # 按索引截取数据子集 # 提取预测变量矩阵:滞后收益率 + 波动率 + 均线偏离度 # 获取列名列表 = haikang_features[[c for c in haikang_features.columns if c.startswith('Lag_' ) or c in ['Vol_20' , 'Dist_MA20' ]]]# 提取目标变量向量 = haikang_features['Target' ] # 提取目标变量
完成特征构造后,按时间序列顺序分割训练集和测试集,进行标准化处理,并使用网格搜索调优RBF核SVM的超参数:
# 按时间序列顺序分割:前80%作为训练集,后20%作为测试集 = int (len (haikang_features) * 0.8 ) # 计算元素数量 # 分割预测变量的训练集和测试集 # 设置haikang_train_x参数 = stock_predictors.iloc[:split_idx], stock_predictors.iloc[split_idx:]# 分割目标变量的训练集和测试集 # 设置haikang_train_y参数 = stock_targets.iloc[:split_idx], stock_targets.iloc[split_idx:]# 初始化标准化器(SVM对特征尺度极其敏感,标准化为必要步骤) = StandardScaler() # 初始化标准化缩放器 # 在训练集上拟合标准化参数(均值和标准差)并执行转换 = feature_scaler.fit_transform(haikang_train_x) # 拟合并转换数据 # 用训练集的参数转换测试集(防止数据泄露) = feature_scaler.transform(haikang_test_x) # 对数据进行转换 # 创建时间序列交叉验证分割器(3折) = TimeSeriesSplit(n_splits= 3 ) # 定义time_series_cv变量 # 定义RBF核SVM的超参数搜索网格 # 定义参数字典 = {'C' : [0.1 , 1 , 10 , 100 ], 'gamma' : [0.001 , 0.01 , 0.1 , 1 ], 'kernel' : ['rbf' ]}# 创建带交叉验证的网格搜索对象 # 初始化网格搜索交叉验证 = GridSearchCV(SVC(), svm_param_grid, cv= time_series_cv, scoring= 'accuracy' , n_jobs= 1 )# 在标准化后的训练集上执行网格搜索 # 训练/拟合模型 # 输出最佳超参数组合 print (f'最佳参数 { svm_stock_grid. best_params_} ' ) # 输出结果到控制台 # 输出训练集交叉验证最佳准确率 print (f'训练集CV准确率 { svm_stock_grid. best_score_:.4f} ' ) # 输出结果到控制台 # 取出最佳模型estimator = svm_stock_grid.best_estimator_ # 定义optimal_stock_svm变量 # 在测试集上进行预测 = optimal_stock_svm.predict(haikang_test_x_scaled) # 使用模型进行预测 # 输出测试集的详细分类报告(精确率、召回率、F1值) print (' \n 测试集分类报告' ) # 输出结果到控制台 print (classification_report(haikang_test_y, stock_predictions)) # 生成分类报告 # 输出测试集整体准确率 print (f'测试集准确率: { accuracy_score(haikang_test_y, stock_predictions):.4f} ' ) # 计算准确率
最佳参数 {'C': 10, 'gamma': 0.1, 'kernel': 'rbf'}
训练集CV准确率 0.5200
测试集分类报告
precision recall f1-score support
-1 0.50 0.82 0.62 201
1 0.47 0.17 0.25 199
accuracy 0.49 400
macro avg 0.48 0.49 0.43 400
weighted avg 0.48 0.49 0.43 400
测试集准确率: 0.4925
模型的分类报告和准确率输出揭示了一个极具启发性的结论。网格搜索找到的最佳超参数为\(C=10\) 、\(\gamma=0.1\) 、核函数为RBF,但交叉验证最佳准确率仅约52%,测试集准确率约49.25%,本质上与随机猜测(50%)无异。更值得关注的是分类报告中的细节:对于”上涨”类(类别1)的召回率极低(约0.17),意味着模型几乎无法正确识别出上涨的交易日。这一结果并非SVM模型本身的”失败”,恰恰相反,它提供了有力的实证证据来支持有效市场假说(EMH)——在一个信息效率较高的市场中,仅凭历史价格衍生的技术指标(动量、波动率、均线偏离度)几乎不可能系统性地预测未来收益方向。即便是具有强大非线性建模能力的RBF核SVM,也无法从这些公开信息中挖掘出持续可利用的预测模式。
案例研究:上市公司财务困境预测 (ST)
我们现在将SVM应用于一个经典的金融问题:预测上市公司是否会陷入财务困境(在A股中通常导致被实施特别处理,即”ST”)。
我们的目标是使用财务比率(如当前比率、负债率、净利率等)来预测一家公司在下一年度是否会亏损(作为财务困境的代理变量)。结果Distress是二元的:Yes表示亏损,No表示盈利。
我们首先拟合LDA和支持向量分类器。图 10.8 显示了测试集预测的ROC曲线。
而在传统的财务预警与风控场景中(例如预测 A 股上市公司是否会被打上“ST”退市风险警示标签),非线性核支持向量机同样大有用武之地。由于真实世界中的破产类公司数据往往只占极少数,为了防止模型变成一个只会预测“大家都很健康”的“睁眼瞎”,代码在构建特征矩阵后,特别使用重抽样(sample)手段制造了一个由 500 家健康企业和 500 家亏损预警企业组成的完美平衡的数据集。 代码的下半部分宛如一场残酷的模型选秀。它将最经典的线性判别分析(LDA)、受限于线性超平面的SVC(Linear),以及挂载了RBF核但采取了不同的\(\gamma\) 敏感度策略的两组非线性SVM(\(\gamma=0.1\) 和\(\gamma=1\) )同时推上了角斗场。最后输出的那张测试集ROC 曲线对决图,不仅是对模型分辨“真假警报”能力(AUC值)的终极检阅,同时也印证了一个深刻的机器学习哲理:在特征维度极少(这里只有4个财务比率)的拥挤空间内,如果强制采用过高的非线性升维映射(极其敏感的\(\gamma=1\) ),反而可能会被复杂的局部噪音所绞杀,导致其泛化评估甚至拼不过简单的线性基线模型。
import numpy as np # 导入numpy库用于数值计算 import pandas as pd # 导入pandas库用于数据框操作 from sklearn.svm import SVC # 导入支持向量分类器 from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 导入线性判别分析模型 from sklearn.model_selection import train_test_split # 导入训练集/测试集分割工具 from sklearn.metrics import roc_curve, auc # 导入ROC曲线与AUC计算函数 from sklearn.preprocessing import StandardScaler # 导入标准化缩放器 import matplotlib.pyplot as plt # 导入matplotlib用于数据可视化 import os # 导入os模块用于跨平台路径处理 # 根据操作系统自动选择本地数据路径 # 根据操作系统设置数据根目录路径 = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 拼接财务报表数据文件的完整路径 = os.path.join(DATA_DIR, 'stock/financial_statement.h5' ) # 构建数据文件的完整路径 # 直接读取A股上市公司财务报表数据(本地数据已确认存在) = pd.read_hdf(financial_path) # 从HDF5文件读取数据
基于原始财务报表数据,构造四个核心财务比率指标作为预测变量,并进行数据清洗与平衡采样:
# 流动比率 = 流动资产 / 流动负债(分母+1避免除零错误) # 执行数据处理操作 'Current_Ratio' ] = financial_statement_history['current_assets' ] / (financial_statement_history['current_liabilities' ] + 1 )# 资产负债率 = 总负债 / 总资产(分母+1避免除零错误) # 执行数据处理操作 'Debt_Ratio' ] = financial_statement_history['total_liabilities' ] / (financial_statement_history['total_assets' ] + 1 )# 销售净利率 = 净利润 / 营业收入(分母+1避免除零错误) # 执行数据处理操作 'ROS' ] = financial_statement_history['net_profit' ] / (financial_statement_history['operating_revenue' ] + 1 )# 资产周转率 = 营业收入 / 总资产(分母+1避免除零错误) # 执行数据处理操作 'Turnover' ] = financial_statement_history['operating_revenue' ] / (financial_statement_history['total_assets' ] + 1 )# 构造目标变量:净利润为负则标记为财务困境(1=困境,0=健康) # 转换数据类型 'Distress' ] = (financial_statement_history['net_profit' ] < 0 ).astype(int )# 仅选取分析所需的列,避免全表dropna导致大量有效样本被误删 = ['Current_Ratio' , 'Debt_Ratio' , 'ROS' , 'Turnover' , 'Distress' ] # 分析所需列 # 删除缺失值 = financial_statement_history[analysis_columns].dropna().replace([np.inf, - np.inf], np.nan).dropna()# 过滤异常值,仅保留合理范围内的财务指标 = valid_financials[ # 定义valid_financials变量 'Current_Ratio' ].between(0 , 10 )) & # 筛选在指定范围内的值 'Debt_Ratio' ].between(0 , 2 )) & # 筛选在指定范围内的值 'ROS' ].between(- 1 , 1 )) # 筛选在指定范围内的值 # 执行数据处理操作 # 对困境样本进行有放回过采样(亏损公司通常远少于盈利公司) # 定义distressed_companies变量 = valid_financials[valid_financials['Distress' ] == 1 ].sample(n= 500 , replace= True , random_state= 42 )# 随机抽取500家健康公司构成负样本 # 定义healthy_companies变量 = valid_financials[valid_financials['Distress' ] == 0 ].sample(n= 500 , random_state= 42 )# 合并正负样本构建平衡数据集 = pd.concat([distressed_companies, healthy_companies]) # 合并多个数据表 # 提取四个财务比率作为预测变量矩阵 # 计算模型预测值 = balanced_financials[['Current_Ratio' , 'Debt_Ratio' , 'ROS' , 'Turnover' ]]# 提取目标变量向量 = balanced_financials['Distress' ] # 提取目标变量
基于清洗后的财务指标数据,进行数据分割、标准化处理,并拟合多个分类模型进行对比:
# 按70:30比例将数据分割为训练集和测试集 # 划分训练集和测试集 = train_test_split(distress_predictors, distress_targets, test_size= 0.3 , random_state= 42 )= StandardScaler() # 创建标准化器(SVM对特征尺度敏感,必须标准化) = feature_scaler.fit_transform(distress_train_x) # 对训练集进行拟合并标准化 = feature_scaler.transform(distress_test_x) # 使用训练集的参数标准化测试集 = LinearDiscriminantAnalysis() # 创建线性判别分析(LDA)模型作为基准 # 在标准化训练数据上拟合LDA = SVC(kernel= 'linear' , C= 1 , probability= True ) # 创建线性核SVM分类器 # 在训练集上拟合线性SVM = SVC(kernel= 'rbf' , gamma= 0.1 , C= 1 , probability= True ) # 创建RBF核SVM(γ=0.1,较平滑) # 在训练集上拟合RBF SVM (γ=0.1) = SVC(kernel= 'rbf' , gamma= 1 , C= 1 , probability= True ) # 创建RBF核SVM(γ=1,较灵活) # 在训练集上拟合RBF SVM (γ=1)
SVC(C=1, gamma=1, probability=True) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
至此,我们已经在标准化后的训练集上拟合了四个分类模型:LDA 作为线性基准方法,线性核 SVM 作为最大间隔线性分类器,以及两个不同 \(\gamma\) 参数的 RBF 核 SVM 用于捕捉可能存在的非线性决策边界。接下来,使用训练好的四个模型在测试集上计算ROC曲线,比较各方法的分类表现:
# 将四个训练好的模型放入字典,便于批量计算ROC曲线 = { # 定义参数字典 'LDA' : distress_lda_model, # 定义字典键值对条目 'SVC (Linear)' : distress_linear_svc, # 定义字典键值对条目 'SVM (RBF, γ=0.1)' : distress_rbf_svc_gamma_01, # 定义字典键值对条目 'SVM (RBF, γ=1)' : distress_rbf_svc_gamma_1 # 执行数据处理操作 # 执行数据处理操作 = (12 , 6 )) # 创建12×6英寸的宽幅画布 for name, model in classification_models.items(): # 遍历每个模型 = model.predict_proba(distress_test_x_scaled)[:, 1 ] # 预测正类概率 = roc_curve(distress_test_y, predicted_probabilities) # 计算ROC曲线的FPR和TPR = auc(false_positive_rate, true_positive_rate) # 计算AUC面积 = 2 , label= f' { name} (AUC = { current_roc_auc:.2f} )' ) # 绘制该模型的ROC曲线 0 , 1 ], [0 , 1 ], 'k--' , linewidth= 1 , label= '随机猜测' ) # 绘制对角线表示随机分类器的基线 '假正率 (1 - Specificity)' , fontsize= 12 ) # 设置X轴标签 '真正率 (Sensitivity)' , fontsize= 12 ) # 设置Y轴标签 '财务困境预测 (Distress): 测试集ROC曲线' , fontsize= 14 ) # 设置图形标题 = 'lower right' , fontsize= 10 ) # 在右下角显示图例 True , alpha= 0.3 ) # 添加半透明网格线 # 自动调整布局 # 显示图形
图 10.8 中四条ROC曲线的对比揭示了若干重要的实践洞察。首先,LDA(红色虚线)与线性SVC(蓝色实线)的ROC曲线几乎完全重合,AUC值也非常接近(均在0.70-0.75区间),这说明在仅有4个财务比率特征的低维空间中,两种线性方法的判别能力基本等价。其次,RBF核SVM在\(\gamma=0.1\) (绿色虚线)时的表现与线性方法大致持平甚至略优,这是因为较小的\(\gamma\) 值使径向基函数的影响范围更广,决策边界更加平滑,接近线性决策面。然而,当\(\gamma\) 增大至1时(紫色实线),ROC曲线反而显著下降,AUC值明显低于其他三个模型。这一反直觉的结果恰好印证了一个深刻的机器学习教训:在特征维度极低的场景中,过高的\(\gamma\) 使得核函数只关注每个训练样本的极小邻域,导致决策边界过度扭曲以拟合训练集中的噪声,从而严重损害泛化性能。对于金融风控中的ST预测实务而言,这意味着简单的线性模型往往是更稳健和可解释的选择。
小结
本章介绍了支持向量机,这是一种强大的分类方法。以下是关键要点:
最大间隔分类器:
寻找具有最大间隔的最优分离超平面
仅在类别线性可分离的情况下工作
对异常值敏感
使用”硬间隔
支持向量分类器
通过允许一些违规软间隔来扩展最大间隔分类器
引入调优参数\(C\) 来控制偏差方差权衡
只依赖于支持向量(位于间隔上或违反间隔的观测
对远离边界的观测鲁棒
支持向量机
通过核函数扩展到非线性决策边界
常用核:线性核、多项式核、径向核(RBF)
核函数允许在更高维空间中有效地工作而无需显式计算
与逻辑回归的比较
SVM和逻辑回归的损失函数非常相似
当类别很好地分离时SVM通常表现更好
在更多重叠区域逻辑回归通常更受青睐
实际应用:
SVM在高维数据(特征数很多)上表现良好
对于小到中等数据集效果最佳
对特征的缩放敏感(需要标准化)
何时使用:
二元或多元分类问题
特征数多于观测数(高维)
存在非线性决策边界
需要对异常值鲁棒
理论来源与前沿
SVM 的理论基础是最大间隔原理与凸优化:通过在所有可分超平面中选择间隔最大的解,可以获得更好的泛化;软间隔与 hinge loss 则让模型在不可分数据下仍可训练。核技巧把非线性分类转化为高维特征空间中的线性分类,并通过对偶问题实现。
尽管深度学习在许多任务上占据主流,SVM 在以下场景仍有优势:
小样本、高维 :例如文本分类、部分生物信息任务。强先验与稳健需求 :最大间隔带来较强的边界稳健性。核方法的现代化 :随机特征、Nyström 近似让核方法在更大规模下可用。
练习
概念题
解释“最大间隔(maximum margin)”与泛化能力之间的直觉联系。为什么更大的几何间隔通常意味着更稳健的分类边界?
对软间隔 SVM,超参数 \(C\) 起什么作用?当\(C\to\infty\) 与\(C\to 0\) 时,模型分别倾向于什么行为?
解释支持向量(support vectors)的含义。为什么只有支持向量会影响决策边界?
为什么SVM 对特征尺度敏感?在核 SVM 中,尺度问题会如何影响核函数(例如RBF 核)的有效作用范围?
核技巧(kernel trick)解决了什么计算问题?它为什么不需要显式构造高维特征?
应用题
用你本机 A 股数据构造一个二分类任务(例如“未来20 个交易日是否出现较大回撤”)。比较:
要求:用时间切分评估,报告AUC 与校准指标,并说明你如何选择/验证 \(C\) 与\(\gamma\) 。
在同一任务上,比较“线性SVM + 手工非线性特征(例如二次项交互项)”与“RBF 核SVM”。讨论:
在样本较少但特征很多(\(p\gg n\) )的设置下,说明你会如何做特征筛选、正则化、核近似,以避免训练时间与过拟合问题。
理论题
写出线性可分情形的硬间隔SVM 原始问题(primal),并给出其对偶问题(dual)的形式,解释拉格朗日乘子与支持向量的关系。
说明 hinge loss \(\ell(y,f)=\max(0,1-yf)\) 为什么是 0-1 损失的一个上界,并据此解释SVM 的经验风险最小化视角。
练习参考解答
概念题参考解答
间隔与稳健性 :间隔大意味着样本点到分割超平面的最小距离更大,在输入有小扰动(噪声、估计误差)时,样本更不容易跨过边界,因此分类更稳健。
\(C\) 的作用\(C\) 控制对违反间隔(松弛变量)的惩罚强度。\(C\to\infty\) 时更强调训练误差(更少容忍错分,可能过拟合);\(C\to 0\) 时更强调大间隔(更强正则化,可能欠拟合)。
支持向量 :它们满足\(y_i(w^\top x_i+b)\le 1\) (硬间隔为等号,软间隔为在间隔上或间隔内的点),只有这些点的拉格朗日乘子 \(\alpha_i>0\) ,对偶表示\(w=\sum_i \alpha_i y_i x_i\) 说明非支持向量(\(\alpha_i=0\) )不影响 \(w\) 。
尺度敏感 :内积与距离会被量纲主导。对 RBF 核\(k(x,x')=\exp(-\gamma\|x-x'\|^2)\) ,若某个特征尺度很大,会让距离变大、核值快速衰减,模型相当于在该维度上“过度敏感”。因此需要标准化。
核技巧 :对偶问题只需要样本间内积 \(\phi(x_i)^\top\phi(x_j)\) ,用核函数直接计算该内积即可,避免显式构造高维\(\phi(x)\) 。
应用题参考解答(模板)
线性vs RBF 核 :建议用 TimeSeriesSplit 做时间序列交叉验证选择超参数,再在最后一段时间做测试。
import pandas as pd # 导入pandas库用于数据框操作 from sklearn.model_selection import TimeSeriesSplit, GridSearchCV # 导入时间序列分割与网格搜索工具 from sklearn.pipeline import Pipeline # 导入管道工具用于组合预处理和模型 from sklearn.preprocessing import StandardScaler # 导入标准化缩放器 from sklearn.svm import SVC # 导入支持向量分类器 from sklearn.metrics import roc_auc_score, brier_score_loss # 导入ROC AUC和Brier损失评估指标 import os # 导入os模块用于跨平台路径处理 = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据路径 = pd.read_hdf(os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5' )).reset_index() # 读取后复权股价数据并重置MultiIndex # 筛选海康威视,构造滞后收益率 = stock_price_history[stock_price_history['order_book_id' ] == '002415.XSHE' ].copy() # 筛选海康威视的数据 = stock_price_history.sort_values('date' ) # 按日期升序排列 'Ret' ] = stock_price_history['close' ].pct_change() # 计算日收益率 for lag in range (1 , 6 ): # 构造1-5期的滞后收益率特征 f'Lag_ { lag} ' ] = stock_price_history['Ret' ].shift(lag) # 将收益率向后平移lag期 'y' ] = (stock_price_history['Ret' ] > 0 ).astype(int ) # 构造二分类标签:收益为正=1,否则=0 = stock_price_history.dropna().iloc[- 1000 :] # 删除缺失值并取最近1000条记录 = stock_price_history[[c for c in stock_price_history.columns if c.startswith('Lag' )]].values # 提取滞后特征矩阵 = stock_price_history['y' ].values # 提取目标变量 = int (len (stock_price_history)* 0.8 ) # 计算训练集分割点(80%训练) = lag_features_matrix[:train_split_index], lag_features_matrix[train_split_index:] # 分割特征 = next_day_direction[:train_split_index], next_day_direction[train_split_index:] # 分割标签 = TimeSeriesSplit(n_splits= 5 ) # 创建5折时间序列交叉验证器 = Pipeline([ # 构建包含标准化和SVM的处理管道 'scaler' , StandardScaler()), # 第一步:特征标准化 'svc' , SVC(probability= True )) # 第二步:SVM分类器(启用概率估计) = {'svc__kernel' : ['linear' ], 'svc__C' : [0.1 , 1 , 10 ]} # 线性核的超参数搜索空间 = {'svc__kernel' : ['rbf' ], 'svc__C' : [0.1 , 1 , 10 ], 'svc__gamma' : [1e-3 , 1e-2 , 1e-1 ]} # RBF核的超参数搜索空间 = GridSearchCV(svm_scaling_pipeline, linear_svm_params, cv= time_series_cv, scoring= 'roc_auc' ) # 配置线性核网格搜索 = GridSearchCV(svm_scaling_pipeline, rbf_svm_params, cv= time_series_cv, scoring= 'roc_auc' ) # 配置RBF核网格搜索 # 执行线性核SVM的网格搜索 # 执行RBF核SVM的网格搜索 for name, current_grid_search in [('linear' , linear_grid_search), ('rbf' , rbf_grid_search)]: # 遍历两种模型 = current_grid_search.best_estimator_.predict_proba(stock_test_features)[:, 1 ] # 用最优模型预测正类概率 print (name, current_grid_search.best_params_, 'AUC=' , roc_auc_score(stock_test_labels, predicted_probabilities), 'Brier=' , brier_score_loss(stock_test_labels, predicted_probabilities)) # 输出模型名称、最优参数、AUC和Brier分数
linear {'svc__C': 0.1, 'svc__kernel': 'linear'} AUC= 0.5 Brier= 0.25
rbf {'svc__C': 1, 'svc__gamma': 0.1, 'svc__kernel': 'rbf'} AUC= 0.5261942994781212 Brier= 0.25144312341911007
手工特征 vs RBF 核 :手工二次交互项把非线性显式化,可能提升线性SVM 表现,同时保留部分可解释性;RBF 核更灵活但更黑箱,且超参数更敏感。两者可用同一时间切分测试集比较。
\(p\gg n\) 的处理
先做标准化与简单过滤(缺失率、近零方差)。
用线性SVM 或L1 正则方法做筛选,再考虑核模型。
对核 SVM 可用 Nyström/随机特征近似,减少计算量。
理论题参考解答(要点)
硬间隔primal/dual :硬间隔 SVM 的primal:
$$ _{w,b};|w|^2y_i(w^x_i+b),;i=1,,n.
$$
其dual 可写为
$$ {}; {i=1}^ni- {i,j}_i_j y_i y_j x_i^x_j _i,;_i_i y_i=0.
$$
KKT 条件给出:若 \(\alpha_i>0\) ,则约束紧(点在间隔上),这些点就是支持向量;并且\(w=\sum_i\alpha_i y_i x_i\) 。
hinge loss 上界 :当 \(yf\le 0\) (错分)时,\(\max(0,1-yf)\ge 1\) ,而0-1 损失为1;当 \(0<yf<1\) (正确但间隔不足)时,-1 损失为0,但 hinge loss 仍为正,起到鼓励更大间隔的作用;当\(yf\ge 1\) 时hinge loss 为0。故 hinge loss 对0-1 损失形成上界,同时更易优化。