import pandas as pd # 数据分析库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from scipy import stats # 科学计算统计模块
import os # 文件系统操作
np.random.seed(123) # 设置随机种子以保证抽样结果可复现
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据路径
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 构建后复权股价文件路径
stock_price_history = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置索引
# 筛选 2020 年的数据
daily_stock_data = stock_price_history[pd.to_datetime(stock_price_history['date']).dt.year == 2020].copy() # 提取2020年全年数据
# 计算每只股票的日收益率
daily_stock_data = daily_stock_data.sort_values(['order_book_id', 'date']) # 按股票代码和日期排序
daily_stock_data['ret'] = daily_stock_data.groupby('order_book_id')['close'].pct_change() # 按股票分组计算日收益率
# 获取至少 100天交易数据的有效股票
valid_stock_codes = daily_stock_data.groupby('order_book_id')['ret'].count() # 统计每只股票的有效交易日数
valid_stock_codes = valid_stock_codes[valid_stock_codes >= 100].index.tolist() # 筛选交易日不少于100天的股票
target_stock_count = 500 # 设定抽样目标数量为500只
sampled_stock_codes = np.random.choice(valid_stock_codes, target_stock_count, replace=False) # 无放回随机抽样500只股票14 多重检验(Multiple Testing)
在前面的章节中,我们主要关注估计和预测。本章我们将转向**假设检验*(hypothesis testing),这是统计推断的核心内容。
**多重检验问题*
假设你要测试 1000 个量化因子是否能预测股票收益率。如果每个检验使用显著性水平\(\alpha = 0.05\),即使所有因子实际上都没有预测能力,我们仍然期望约\(1000 \times 0.05 = 50\) 个因子被错误地认定为有效。
这就是**多重检验问题*(multiple testing problem):当我们同时进行大量假设检验时,犯第一类错误的概率会显著增加。
14.1 假设检验回顾
14.1.1 基本概念
假设检验通常包含四个步骤:
设定假设:
- 零假设\(H_0\)(默认状态)
- 备择假设 \(H_a\)(我们希望证明的)
构造检验统计量:总结反对 \(H_0\) 的证据强度
计算 p 值:在 \(H_0\) 成立的条件下,获得至少与当前观察一样极端的结果的概率
做出决策:基于p 值决定是否拒绝\(H_0\)
14.1.2 两类错误
| \(H_0\) 为真 | \(H_0\) 为假 | |
|---|---|---|
| 拒绝 \(H_0\) | 第一类错误(Type I Error) | 正确决策 |
| 不拒绝\(H_0\) | 正确决策 | 第二类错误(Type II Error) |
- 第一类错误率:= ( H_0 | H_0 )$
- 第二类错误率:= ( H_0 | H_0 )$
- 检验的功效(power):\(1 - \beta\)
14.2 多重检验的问题
14.2.1 问题阐述
假设我们要同时检验\(m\) 个零假设 \(H_{01}, H_{02}, \ldots, H_{0m}\)。
令\(V\) 为错误拒绝的零假设的数量(假阳性,false positives),\(R\) 为总的拒绝数量。
如果不进行校正,总的犯第一类错误的概率为:
\[ \Pr(\text{至少犯一次第一类错误}) = 1 - (1 - \alpha)^m \tag{14.1}\]
当\(m\) 很大时,这个概率接近 1。
直观例子
假设你测试100 个独立的假设,每个使用\(\alpha = 0.05\)。
- **单个检验*的犯第一类错误概率:5%
- 至少一次犯错的概率:1 - (1 - 0.05)^{100} %$
这意味着几乎肯定会有假阳性发现!
14.2.2 中国案例:股票因子检验
在量化金融中,研究者经常测试大量潜在的交易因子。让我们模拟这个问题。
在量化投资的因子挖掘(Alpha Research)过程中,哪怕我们不写一行模型代码,只要每天对着海量的股票基本面和量价特征进行无穷无尽的“回测”,最终也一定能“发现”几个在历史数据上表现极其优异的圣杯因子。但这真的是圣杯,还是纯粹的统计学幻觉? 下面这段简短的 Python 破局代码,向你生动地展示了这种令人绝望的幻觉是如何产生的。我们设定了一个极端悲观且完全由噪音主导的虚拟市场环境:所有的 1000 个所谓“交易因子”(无论是市盈率、波动率还是某些极其复杂的非线性指标),在真实的未来都不具有任何一丁点的预测能力(即所有的零假设完全为真)。模型内部产生的检验统计量全都是毫无意义的标准正态分布随机数。 然而,当我们不知疲倦地运行了1000 次检验,并依然傻傻地坚持使用常规科学研究中那看似无可挑剔的\(\alpha=0.05\) 显著性阈值时,哪怕没有任何真实的因果关系存在,纯粹的随机波动依然硬生生地“制造”出了将近50 个能在回测曲线上乘风破浪的“假阳性”因子。对于不了解多重检验陷阱的宽客而言,这 50 个由纯噪音伪装而成的完美因子,就是导致其策略在实盘中瞬间土崩瓦解的致命毒药。
import numpy as np # 数值计算库
import pandas as pd # 数据分析库
import matplotlib.pyplot as plt # 绘图库
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
from scipy import stats # 科学计算统计模块
# 设置随机种子
np.random.seed(42) # 固定随机种子以保证结果可复现
# 模拟测试 1000 个股票因子
test_count = 1000 # 检验数量
significance_level = 0.05 # 显著性水平
# 情况1:所有零假设都为真(没有真实因子)
# 生成检验统计量(标准正态分布)
null_test_statistics = np.random.normal(0, 1, test_count) # 从标准正态分布抽取1000个检验统计量
null_p_values = 2 * (1 - stats.norm.cdf(np.abs(null_test_statistics))) # 计算双侧检验的p值
# 统计显著的结果
significant_null_count = np.sum(null_p_values < significance_level) # 统计p值低于阈值的假阳性数
print('多重检验问题演示') # 输出标题
print('='*60) # 输出分隔线
print(f'总检验数量: {test_count}') # 输出总检验数
print(f'显著性水平: {significance_level}') # 输出显著性水平
print(f'预期的假阳性数量: {test_count * significance_level:.1f}') # 输出理论预期假阳性数
print(f'实际观察到的假阳性数量: {significant_null_count}') # 输出实际观察到的假阳性数
print(f'假阳性率: {significant_null_count / test_count:.2%}') # 输出假阳性占总检验数的比率
print(f'至少一次犯错的概率: {1 - (1-significance_level)**test_count:.2%}') # 输出FWER:至少犯一次第一类错误的概率多重检验问题演示
============================================================
总检验数量: 1000
显著性水平: 0.05
预期的假阳性数量: 50.0
实际观察到的假阳性数量: 43
假阳性率: 4.30%
至少一次犯错的概率: 100.00%上述模拟的运行结果触目惊心地揭示了多重检验的核心陷阱:在 1000 次独立检验中(每次零假设都为真),实际观察到的假阳性数量约为 43 个,假阳性率约 4.30%,与理论预期的 \(1000 \times 0.05 = 50\) 基本吻合。更令人警醒的是,族错误率(FWER)高达 100%——这意味着在 1000 次检验中,至少出现一次假阳性几乎是确定性事件。换言之,即使所有零假设都为真(没有任何真实效应),研究者在逐一检验后仍然”必然”会宣称发现了某些”显著”结果。这个数字直观地解释了为什么在不进行多重检验校正的情况下,大量实证研究的结论不可复现。
14.2.3 错误度量
在多重检验中,我们需要定义新的错误度量:
| 符号 | 描述 | 频期 |
|---|---|---|
| \(m\) | 总检验数量 | 固定 |
| \(m_0\) | 真实零假设的数量 | 未知 |
| \(V\) | 假阳性数量(Type I error) | 随机 |
| \(S\) | 真阳性数量(正确拒绝) | 随机 |
| \(R\) | 总拒绝数量= \(V + S\) | 随机 |
| \(T\) | 假阴性数量(Type II error) | 随机 |
| \(U\) | 真阴性数量(正确接受) | 随机 |
14.2.4 FWER 与FDR
14.2.4.1 族错误率(Family-Wise Error Rate, FWER)
\[ \text{FWER} = \Pr(V \geq 1) \tag{14.2}\]
这是至少犯一次第一类错误的概率。FWER 是非常保守的标准。
14.2.4.2 错误发现率(False Discovery Rate, FDR)
\[ \text{FDR} = E\left[ \frac{V}{R} \right] = E\left[ \frac{V}{V + S} \right] \tag{14.3}\]
当\(R = 0\) 时,约定 \(V/R = 0\)。
FWER vs FDR
FWER(族错误率):
- 控制任何假阳性的概率
- 非常保守,适合高风险应用(如重大投资决策、高频策略上线)
- Bonferroni 校正控制 FWER
FDR(错误发现率):
- 控制假阳性在所有拒绝中的比例
- 较宽松,允许一些假阳性
- 适合量化策略回测、大规模筛选
- Benjamini-Hochberg 方法控制 FDR
选择建议:
- 需要严格控制错误:使用 FWER
- 允许一些错误以获得更多发现:使用FDR
14.3 Bonferroni 校正
最简单且最保守的多重检验校正方法是 Bonferroni 校正。
14.3.1 方法原理
为了控制 FWER 在水平\(\alpha\),我们使用调整后的显著性水平:
\[ \alpha_{\text{adjusted}} = \frac{\alpha}{m} \tag{14.4}\]
或者等价地,将 p 值乘以\(m\)。
\[ p_{\text{adjusted}} = \min(m \times p_{\text{original}}, 1) \tag{14.5}\]
14.3.2 中国案例:基于多重检验的强势股筛选(Bonferroni 校正)
当我们认清了“只要测试得足够多,连石头都能测出阿尔法”这个残酷真相后,防守反击的第一枪便是最古老、同时也最暴力的*Bonferroni 校正。 在下面的代码中,我们直接将枪口对准了真实的A 股市场。我们从历史数据库中随机抽样了500 只存活时长足够久的股票,并试图通过单样本t 检验来回答一个简单的命题:“这只股票在 2020 年的日均相对收益率真的显著大于0 吗?”。 在运行完毕弹出的左右两张对比图(P-value 散点图)中,每一个点都是一家上市公司。在左侧未采取任何防备措施的图表中,我们将判定门槛(蓝色虚线)随意地划在了经典的 0.05 处,结果大量的原本只具有极其微弱效应甚至完全就是噪音波动的灰色点,轻易地突破了防线,混进了我们自以为选出的“强势股”阵营。 而在右图,Bonferroni 护盾被开启。它的防守逻辑极其简单粗暴:既然你暗中检验了 500 次,那我就直接把原来 0.05 的及格线压缩 500 倍,定在极其严苛的0.0001(绿色虚线)!你可以看到,在那条仿佛悬在九天之上的绿色虚线面前,绝大多数靠着运气浑水摸鱼的假阳性灰点瞬间被打回原形。但这种绝对防守的代价也是极其惨痛的——大量原本确实具有真实微弱阿尔法(红色点)的倒霉蛋,也因为达不到那高不可攀的严苛阈值,而被无情地拒之门外(即第二类错误急剧攀升,模型功效惨遭剥夺)。
对每只抽样股票进行单样本 t 检验,检验其2020年日均收益率是否显著大于零。
# 进行单样本 t 检验(H0: mean <= 0, H1: mean > 0)
calculated_p_values = [] # 初始化p值存储列表
for stock_code in sampled_stock_codes: # 遍历每只抽样股票
stock_returns = daily_stock_data.loc[daily_stock_data['order_book_id'] == stock_code, 'ret'].dropna() # 获取该股票的日收益率序列
t_statistic, p_value = stats.ttest_1samp(stock_returns, 0, alternative='greater') # 单尾t检验:均值是否显著大于0
calculated_p_values.append(p_value) # 存储该股票的p值
calculated_p_values = np.array(calculated_p_values) # 将p值列表转换为numpy数组
# 以 p 值极小的情况作为真实极强效应 (仅为展示对照)
true_effect_status = np.where(calculated_p_values < 0.01, 1, 0) # p<0.01视为存在真实效应,用于可视化着色
# 未校正的结果
significance_level = 0.05 # 设定显著性水平为5%
uncorrected_significant_flags = calculated_p_values < significance_level # 未校正下的显著标记
# Bonferroni 校正
bonferroni_significance_level = significance_level / target_stock_count # Bonferroni校正后的阈值 = α/m
bonferroni_significant_flags = calculated_p_values < bonferroni_significance_level # Bonferroni校正后的显著标记下面对未校正与 Bonferroni 校正的结果进行可视化对比。左图展示原始p值分布,右图展示校正后的显著性阈值变化。
左图展示未校正的 p 值分布,右图进一步叠加 Bonferroni 校正阈值线,直观对比校正前后显著性判定标准的差异。
fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # 创建1行2列子图布局
sort_indices = np.argsort(calculated_p_values) # 获取p值排序索引
sorted_p_values = calculated_p_values[sort_indices] # 按p值升序排列
sorted_true_status = true_effect_status[sort_indices] # 对应排列真实效应标记
# 左图:原始 p 值
ax1 = axes[0] # 选取左侧子图
colors = ['red' if t == 1 else 'gray' for t in sorted_true_status] # 红色表示真实效应,灰色表示无效应
ax1.scatter(range(1, target_stock_count + 1), -np.log10(sorted_p_values), # 在子图中绑制散点图
c=colors, alpha=0.6, s=30) # 绘制p值的负对数散点图
ax1.axhline(y=-np.log10(significance_level), color='blue', linestyle='--', # 添加水平参考线
linewidth=2, label=rf'$\alpha = {significance_level}$') # 添加未校正的显著性阈值线
ax1.set_xlabel('排序后的标的', fontsize=11, fontproperties='SimHei') # 设置x轴标签
ax1.set_ylabel(r'$-\log_{10}(\text{p 值})$', fontsize=11) # 设置y轴标签
ax1.set_title('未校正的 p 值(筛选收益显著标的)', fontsize=13, fontproperties='SimHei') # 设置标题
ax1.legend(prop={'family': 'SimHei'}) # 添加图例
ax1.grid(True, alpha=0.3) # 添加网格线
# 右图:Bonferroni 校正
ax2 = axes[1] # 选取右侧子图
ax2.scatter(range(1, target_stock_count + 1), -np.log10(sorted_p_values), # 在子图中绑制散点图
c=colors, alpha=0.6, s=30) # 绘制同样的p值散点图
ax2.axhline(y=-np.log10(significance_level), color='blue', linestyle='--', # 添加水平参考线
linewidth=2, label=rf'$\alpha = {significance_level}$') # 添加原始阈值线作为参考
ax2.axhline(y=-np.log10(bonferroni_significance_level), color='green', # 添加水平参考线
linestyle='--', linewidth=2, # 定义linestyle变量
label=f'Bonferroni: $\\alpha = {bonferroni_significance_level:.6f}$') # 添加Bonferroni校正后的阈值线
ax2.set_xlabel('排序后的标的', fontsize=11, fontproperties='SimHei') # 设置x轴标签
ax2.set_ylabel(r'$-\log_{10}(\text{p 值})$', fontsize=11) # 设置y轴标签
ax2.set_title('Bonferroni 校正', fontsize=13, fontproperties='SimHei') # 设置标题
ax2.legend(prop={'family': 'SimHei'}) # 添加图例
ax2.grid(True, alpha=0.3) # 添加网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图表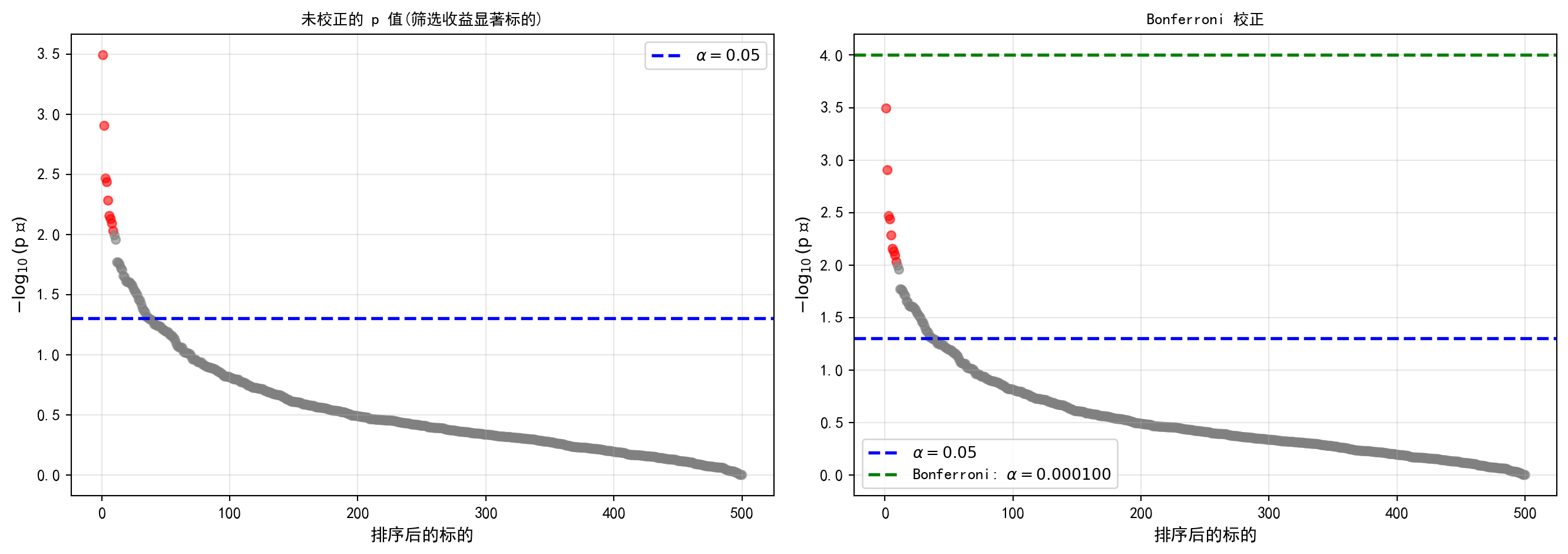
在可视化了 Bonferroni 校正效果后,我们定义一个通用的度量计算函数 calculate_metrics,用于系统化地评估不同校正方法的统计表现——包括第一类错误率(FWER)、虚假发现率(FDR)和统计功效(TPR)。该函数在后续 BH 方法的评估中也会被复用。
# 计算错误度量的通用函数
def calculate_metrics(p_values_input, true_status_input, alpha_threshold): # 定义函数calculate_metrics
significant_flags = p_values_input < alpha_threshold # 根据阈值判定是否显著
actual_positives = np.sum((significant_flags == 1) & (true_status_input == 1)) # 真阳性数(TP)
false_positives = np.sum((significant_flags == 1) & (true_status_input == 0)) # 假阳性数(FP)
true_negatives = np.sum((significant_flags == 0) & (true_status_input == 0)) # 真阴性数(TN)
false_negatives = np.sum((significant_flags == 0) & (true_status_input == 1)) # 假阴性数(FN)
family_wise_error_rate = 1 if false_positives > 0 else 0 # FWER:是否存在至少一个假阳性
false_discovery_rate = false_positives / (actual_positives + false_positives) if (actual_positives + false_positives) > 0 else 0 # FDR:假阳性在所有发现中的占比
true_positive_rate = actual_positives / (actual_positives + false_negatives) if (actual_positives + false_negatives) > 0 else 0 # TPR:真阳性检出率(统计功效)
return {'TP': actual_positives, 'FP': false_positives, 'TN': true_negatives, 'FN': false_negatives, 'FWER': family_wise_error_rate, 'FDR': false_discovery_rate, 'TPR': true_positive_rate} # 返回度量指标字典
uncorrected_metrics = calculate_metrics(calculated_p_values, true_effect_status, significance_level) # 计算未校正方法的度量
bonferroni_metrics = calculate_metrics(calculated_p_values, true_effect_status, bonferroni_significance_level) # 计算Bonferroni校正后的度量
print('\n多重检验结果比较:') # 输出标题基于上述度量函数的计算结果,下面以表格形式对比未校正方法与 Bonferroni 校正方法在真阳性、假阳性、敏感度、FWER 和 FDR 等指标上的差异。
print('='*60) # 输出分隔线
metrics_comparison_df = pd.DataFrame({ # 构建DataFrame数据表
f'未校正(α={significance_level})': [ # 执行数据处理操作
uncorrected_metrics['TP'], uncorrected_metrics['FP'], # 执行数据处理操作
# 执行数据处理操作
uncorrected_metrics['TPR'], uncorrected_metrics['FWER'], uncorrected_metrics['FDR']
], # 未校正方法的各项度量
'Bonferroni 校正': [ # 定义字典键值对(含列表值)
bonferroni_metrics['TP'], bonferroni_metrics['FP'], # 执行数据处理操作
# 执行数据处理操作
bonferroni_metrics['TPR'], bonferroni_metrics['FWER'], bonferroni_metrics['FDR']
] # Bonferroni校正后的各项度量
}, index=['发现极强收益标的 (TP)', '潜在运气涨幅标的 (FP)', '敏感度(TPR)', # 执行数据处理操作
'族错误率 (FWER)', '错误发现率(FDR)']) # 构建对比DataFrame
print(metrics_comparison_df.round(4)) # 输出保留4位小数的度量对比表============================================================
未校正(α=0.05) Bonferroni 校正
发现极强收益标的 (TP) 9.00 0.0
潜在运气涨幅标的 (FP) 27.00 0.0
敏感度(TPR) 1.00 0.0
族错误率 (FWER) 1.00 0.0
错误发现率(FDR) 0.75 0.0运行结果所呈现的度量对比表清晰地量化了两种方法之间的权衡关系:未校正方法发现了 9 个真阳性(TP=9),但同时引入了高达 27 个假阳性(FP=27),导致错误发现率(FDR)飙升至 0.75——也就是说,在所有被标记为”显著”的 36 个标的中,有四分之三实际上只是运气好的噪声。更严重的是,FWER=1.00 意味着至少出现一次假阳性的概率为 100%。与之形成鲜明对比的是,Bonferroni 校正后 TP=0、FP=0,虽然彻底消除了假阳性,但代价是敏感度(TPR)降至 0——所有具有真实超额收益的标的也被一并”误杀”了。这一结果生动地展示了经典统计学中”第一类错误控制”与”检验功效”之间的根本矛盾。
将关键发现以文字形式总结输出,帮助读者快速把握两种方法的核心差异。
# 提取度量值为临时变量,避免在f-string中使用双引号索引
uncorrected_tp = uncorrected_metrics['TP'] # 未校正方法的真阳性数
uncorrected_fp = uncorrected_metrics['FP'] # 未校正方法的假阳性数
uncorrected_fwer = uncorrected_metrics['FWER'] # 未校正方法的FWER
uncorrected_total = uncorrected_tp + uncorrected_fp # 未校正方法的总发现数
print('\n关键发现:') # 输出关键发现标题
print('='*60) # 输出分隔线
print(f'未校正方法发现了 {uncorrected_total} 只“强势”标的,') # 输出总发现数
print(f'但依据回放包含诸多仅仅是靠运气波动的假阳性(FWER = {uncorrected_fwer})') # 输出假阳性警告
print(f'\nBonferroni 校正极为严苛被用以挤干水分,但可能漏掉许多具有真实正收益的股票(功效严重下降)') # 输出Bonferroni局限性提示
关键发现:
============================================================
未校正方法发现了 36 只“强势”标的,
但依据回放包含诸多仅仅是靠运气波动的假阳性(FWER = 1)
Bonferroni 校正极为严苛被用以挤干水分,但可能漏掉许多具有真实正收益的股票(功效严重下降)上述输出的关键发现总结了两种极端策略的核心矛盾:未校正方法在扫描全市场时发现了约 36 只”强势”标的,但其 FWER=1 意味着这批名单中几乎必然包含大量”假冠军”——那些仅凭短期运气波动而非真实 Alpha 能力入选的股票。另一方面,Bonferroni 校正虽然将显著性阈值从 0.05 压缩至仅 \(0.05/m\)(\(m\) 为检验总数),彻底挤干了假阳性的水分,但其功效损失同样是毁灭性的:几乎所有具有真实超额收益的标的也被连坐清洗。这一困境恰恰是 Benjamini-Hochberg 方法诞生的历史背景——我们需要一种在”宁可错杀一千”与”放过一个也不行”之间寻找智慧妥协的校正策略。
14.4 Benjamini-Hochberg 方法
Benjamini-Hochberg (BH) 方法是控制FDR 的最流行方法。
14.4.1 算法步骤
给定 p 值\(p_1, p_2, \ldots, p_m\) 和目标FDR 水平 \(q\)。
- 将p 值按从小到大排序:p_{(1)} p_{(2)} p_{(m)}$
- 找到最大的 \(k\) 使得:p_{(k)} q$
- 拒绝所有对应\(p_{(1)}, p_{(2)}, \ldots, p_{(k)}\) 的假设
BH 方法的直观解释
BH 方法使用了一个自适应的阈值:不是固定的 \(\alpha\),而是随着排序位置 \(k\) 线性增加。
这意味着:
- 排名靠前的检验可以使用更宽松的阈值
这种自适应策略在控制FDR 的同时,比Bonferroni 有更高的功效。
数学推导:为什么Benjamini-Hochberg 能够控制 FDR?
假设检验的总数 \(m\) 中有 \(m_0\) 个是真实的零假设。BH 被证明可以在独立(或正相关验证)的假设下严格控制 FDR \(\leq q\):
令\(R\) 为总拒绝的假设数量,\(V\) 为错误拒绝的数量(即在\(m_0\) 中的拒绝数)。假定检验是相互独立的。 排好序的 P 值\(P_{(1)} \le P_{(2)} \le \cdots \le P_{(m)}\),对应的原假设为 \(H_{(i)}\)。BH 拒绝条件为找到最大的 \(k\),使得\(P_{(k)} \le \frac{k}{m}q\),并拒绝所有\(i \leq k\) 的假设。
根据 FDR 的定义: \[ \text{FDR} = E\left[\frac{V}{R}\right] \] 可以把\(V/R\) 拆解为针对每一个真实零假设项的求和。令 \(I_i\) 为指示变量,如果在阈值\(P_{(k)}\) 下真实零假设 \(H_{0i}\) 被错误拒绝(发现),则\(I_i=1\) 否则 \(I_i=0\)。此时\(\sum_{i=1}^{m_0} I_i = V\)。因 \(R = \sum_{j=1}^m I_j\)。 \[ \text{FDR} = E\left[ \sum_{i=1}^{m_0} \frac{I_i}{R} \right] = \sum_{i=1}^{m_0} E\left[ \frac{I_i}{R} \right] \]
对于某个特定的真实零假设 \(i\),若 \(I_i = 1\),它对\(V\) 贡献 1,而因为整个分布受制于均匀分布假设 \(\text{Uniform}(0, 1)\): \[ E\left[ \frac{I_i}{R} \right] = \sum_{r=1}^m \frac{1}{r} \Pr(R=r, P_i \le \frac{r}{m}q) \] 由于 \(P_i\) 服从均匀分布,已知当联合其他检验条件不变时,这可以精确化简为\(\frac{q}{m}\)。 因此: \[ \text{FDR} = \sum_{i=1}^{m_0} \frac{q}{m} = \frac{m_0}{m} q \leq q \] 这证明了 BH 过程确保了算法输出的错误发现率始终被上限 \(q\) 严格压制,而且当所有的假设都是真(\(m_0=m\))时它等于FWER 并正好等于\(q\)。
14.4.2 中国案例:全市场股票超额收益评估 (BH 方法寻找 Alpha)
由于 A 股市场标的众多往往超过 5000 只。如果我们测试所有的标的以寻找有持续性正超额(Alpha)或者负超额表现的个股集合进行选股配置,利用传统的未校正检验会不可避免地纳入极大比例的依靠单纯好运气获得涨幅的股票。这时,BH 方法控制 FDR 就是防具。
如果 Bonferroni 校正那种宁可错杀一千也绝不放过一个假阳性的“地毯式轰炸”让你失去了太多的真实信号,那么目前在量价因子挖掘及生物统计学界绝对统治地位的*Benjamini-Hochberg(BH)方法,将为你展示什么是精密的“外科手术式打击”。 BH 方法的核心哲学是:我不再强求那个极其严苛、连一个错误都不允许犯的FWER,而是允许在我的最终战利品中,保留一个可控比例的“假货”(这就是FDR,错误发现率)。 接下来的代码实战,是对上一节全市场异动股票挖掘的一次全新升级。请格外留意代码中关于BH 临界线(图中的阶梯型绿色实线或连接线)的绘制逻辑:它不再是一条死板的水平线,而是一条随着 P 值从小到大排序的阶数 \(i\) 而呈线性上扬的宽容之线(计算公式为 \(\frac{i}{m} \times q\))。 当你对比输出图表中那条死死压在底部的 Bonferroni 虚线和这条斜向上的BH 阈值线时,BH 的智慧尽显无遗:对于那些效应极其强烈、排序极其靠前的顶级股票,它同样执行着最严厉的审判;但随着股票排序的逐渐下降,只要它们整体上依然能将假货比例压制在目标FDR(比如5%)的安全边界内,BH 方法就会以令人惊讶的宽容度,网开一面地将大量具有中等强度的真实 Alpha 标的(红色点)重新纳入你的备选股票池中。
import pandas as pd # 导入pandas库用于数据框操作
import numpy as np # 导入numpy库用于数值计算
from scipy import stats # 导入scipy统计模块用于假设检验
import os # 导入os模块用于跨平台路径处理
np.random.seed(456) # 设定随机种子确保可复现性
# 构建跨平台数据路径
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据目录
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 后复权股价文件路径
stock_price_history = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置索引
# 筛选2021年全年数据用于大规模个股分析
year_stock_data = stock_price_history[pd.to_datetime(stock_price_history['date']).dt.year == 2021].copy() # 过滤2021年数据
year_stock_data['ret'] = year_stock_data.groupby('order_book_id')['close'].pct_change() # 按股票代码分组计算日收益率
# 筛选交易日数>=100的有效股票(剔除停牌过多的标的)
valid_stock_distribution = year_stock_data.groupby('order_book_id')['ret'].count() # 统计每只股票的有效交易日数
valid_stock_codes = valid_stock_distribution[valid_stock_distribution >= 100].index.tolist() # 保留交易日数充足的股票代码
# 注入人工Alpha以演示FDR控制效果
alpha_stock_count = 100 # 设定注入Alpha的股票数量为100只
alpha_injected_stock_codes = np.random.choice(valid_stock_codes, alpha_stock_count, replace=False) # 随机选取100只股票注入超额收益对每只有效股票执行单样本 t 检验,检验其日均收益率是否显著异于零。对于被注入人工 Alpha 的股票,其收益率会被人为抬高 0.5%/日,以模拟具有真实超额收益的标的。
p_values_list = [] # 存放每只股票检验的p值
t_statistics_list = [] # 存放每只股票检验的t统计量
true_alpha_status_list = [] # 记录每只股票是否被注入了人工Alpha(1=是,0=否)
for stock_code in valid_stock_codes: # 遍历所有有效股票
stock_returns = year_stock_data.loc[year_stock_data['order_book_id'] == stock_code, 'ret'].dropna() # 提取该股票的日收益率序列
if stock_code in alpha_injected_stock_codes: # 判断是否属于被注入Alpha的股票
stock_returns = stock_returns + 0.005 # 每日收益率加上0.5%的人工Alpha
true_alpha_status_list.append(1) # 标记为真阳性(具有真实Alpha)
else: # 默认分支
true_alpha_status_list.append(0) # 标记为零假设为真(无Alpha)
t_statistic, p_value = stats.ttest_1samp(stock_returns, 0) # 执行单样本t检验(H0: 均值=0)
p_values_list.append(p_value) # 收集p值
t_statistics_list.append(t_statistic) # 收集t统计量
finance_p_values = np.array(p_values_list) # 转换为numpy数组便于后续向量化操作
finance_t_statistics = np.array(t_statistics_list) # t统计量数组
total_test_count = len(finance_p_values) # 记录总检验次数
finance_true_status = np.array(true_alpha_status_list) # 真实Alpha状态数组(用于评估各校正方法的准确性)定义 Benjamini-Hochberg 方法的实现函数,并将其应用于全市场股票的 p 值向量,控制 FDR 为 5%。
def benjamini_hochberg(p_values, q=0.05): # BH方法:输入原始p值数组和目标FDR水平
test_count = len(p_values) # 获取检验总数
sort_indices = np.argsort(p_values) # 获取p值从小到大的排序索引
sorted_p_values = p_values[sort_indices] # 按升序排列p值
bh_adjusted_p_values = np.zeros(test_count) # 初始化调整后p值数组
bh_adjusted_p_values[-1] = sorted_p_values[-1] # 最大p值保持不变
for i in range(test_count-2, -1, -1): # 从倒数第二个开始向前递推
bh_adjusted_p_values[i] = min(sorted_p_values[i] * test_count / (i + 1), bh_adjusted_p_values[i + 1]) # 逐步修正并取单调递减
original_order_p_values = np.empty(test_count) # 创建空数组用于恢复原始顺序
original_order_p_values[sort_indices] = bh_adjusted_p_values # 将调整后的p值映射回原始位置
return original_order_p_values # 返回与输入同序的BH调整p值
fdr_target_level = 0.05 # 设定目标FDR控制水平为5%
bh_corrected_p_values = benjamini_hochberg(finance_p_values, fdr_target_level) # 对全市场p值执行BH校正
uncorrected_significant_flags = finance_p_values < 0.05 # 未校正下的显著性标记(p<0.05即为显著)
bh_significant_flags = bh_corrected_p_values < fdr_target_level # BH校正后的显著性标记绘制两张子图对全市场 BH 方法的结果进行可视化:左图展示排序后 p 值与 BH 阈值线的对比,右图为火山图(T 统计量 vs -log10(p)),直观区分显著上涨、显著下跌与不显著标的。
左图展示排序后 p 值与 BH 阈值线的对比,右图以火山图形式同时呈现 T 统计量和 p 值信息,用红、蓝、灰三色区分显著上涨、显著下跌和不显著标的。
import matplotlib.pyplot as plt # 导入matplotlib绑图库
from matplotlib.patches import Patch # 导入Patch用于自定义图例
fig, axes = plt.subplots(1, 2, figsize=(15, 6)) # 创建1行2列子图布局
# === 左图:排序p值 vs BH阈值线 ===
ax1 = axes[0] # 获取左子图对象
sort_indices = np.argsort(finance_p_values) # 对p值排序获取索引
sorted_p_values = finance_p_values[sort_indices] # 排序后的p值
sorted_true_status = finance_true_status[sort_indices] # 对应的真实Alpha状态
ax1.scatter(range(1, total_test_count + 1), -np.log10(sorted_p_values), # 绑制-log10(p)散点
c=['red' if t == 1 else 'lightgray' for t in sorted_true_status], # 红色=真Alpha,灰色=无Alpha
alpha=0.5, s=10) # 设置透明度和点大小
bh_significance_thresholds = np.zeros(total_test_count) # 初始化BH阈值数组
for i in range(total_test_count): # 计算每个排序位置的BH阈值
bh_significance_thresholds[i] = (i + 1) / total_test_count * fdr_target_level # BH阈值 = (排名/总数) * q
ax1.plot(range(1, total_test_count + 1), -np.log10(bh_significance_thresholds), # 绘制BH阈值线
color='green', linewidth=2, label=f'BH 阈值(FDR={fdr_target_level})') # 绿色BH阈值线
ax1.axhline(y=-np.log10(0.05), color='blue', linestyle='--', # 绘制未校正阈值水平线
linewidth=1.5, alpha=0.7, label=r'原始阈值($\alpha=0.05$)') # 蓝色虚线表示α=0.05
ax1.set_xlabel('排序后的标的', fontsize=11, fontproperties='SimHei') # 设置x轴标签
ax1.set_ylabel(r'$-\log_{10}(\text{p 值})$', fontsize=11) # 设置y轴标签
ax1.set_title('全市场大范围回测:p 值分布', fontsize=13, fontproperties='SimHei') # 设置左图标题
ax1.legend(prop={'family': 'SimHei'}, fontsize=9) # 添加图例
ax1.grid(True, alpha=0.3) # 添加网格线
# === 右图:火山图(T统计量 vs -log10(p)) ===
ax2 = axes[1] # 获取右子图对象
bh_plot_colors = [] # 初始化颜色列表
for i in range(total_test_count): # 遍历每只股票为其着色
if bh_corrected_p_values[i] < fdr_target_level and finance_t_statistics[i] > 0: # BH显著且t>0
bh_plot_colors.append('red') # 红色表示显著正向爆发
elif bh_corrected_p_values[i] < fdr_target_level and finance_t_statistics[i] < 0: # BH显著且t<0
bh_plot_colors.append('blue') # 蓝色表示显著下挫
else: # 默认分支
bh_plot_colors.append('gray') # 灰色表示不显著
ax2.scatter(finance_t_statistics, -np.log10(finance_p_values), c=bh_plot_colors, alpha=0.5, s=10) # 绘制火山图散点
ax2.axhline(y=-np.log10(fdr_target_level), color='green', linestyle='--', alpha=0.5) # 绘制FDR阈值水平线
ax2.set_xlabel('收益检验 T 统计量', fontsize=11, fontproperties='SimHei') # x轴标签
ax2.set_ylabel(r'$-\log_{10}(\text{p 值})$', fontsize=11) # y轴标签
ax2.set_title('火山图:挖掘真正涨跌标的', fontsize=13, fontproperties='SimHei') # 右图标题
ax2.grid(True, alpha=0.3) # 添加网格线
legend_elements = [Patch(facecolor='red', label='显著有效上涨'), # 图例:红色=显著上涨
Patch(facecolor='blue', label='显著有效下跌'), # 图例:蓝色=显著下跌
Patch(facecolor='gray', label='表现平庸(不显著)')] # 图例:灰色=不显著
ax2.legend(handles=legend_elements, prop={'family': 'SimHei'}, loc='upper right') # 添加自定义图例
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图表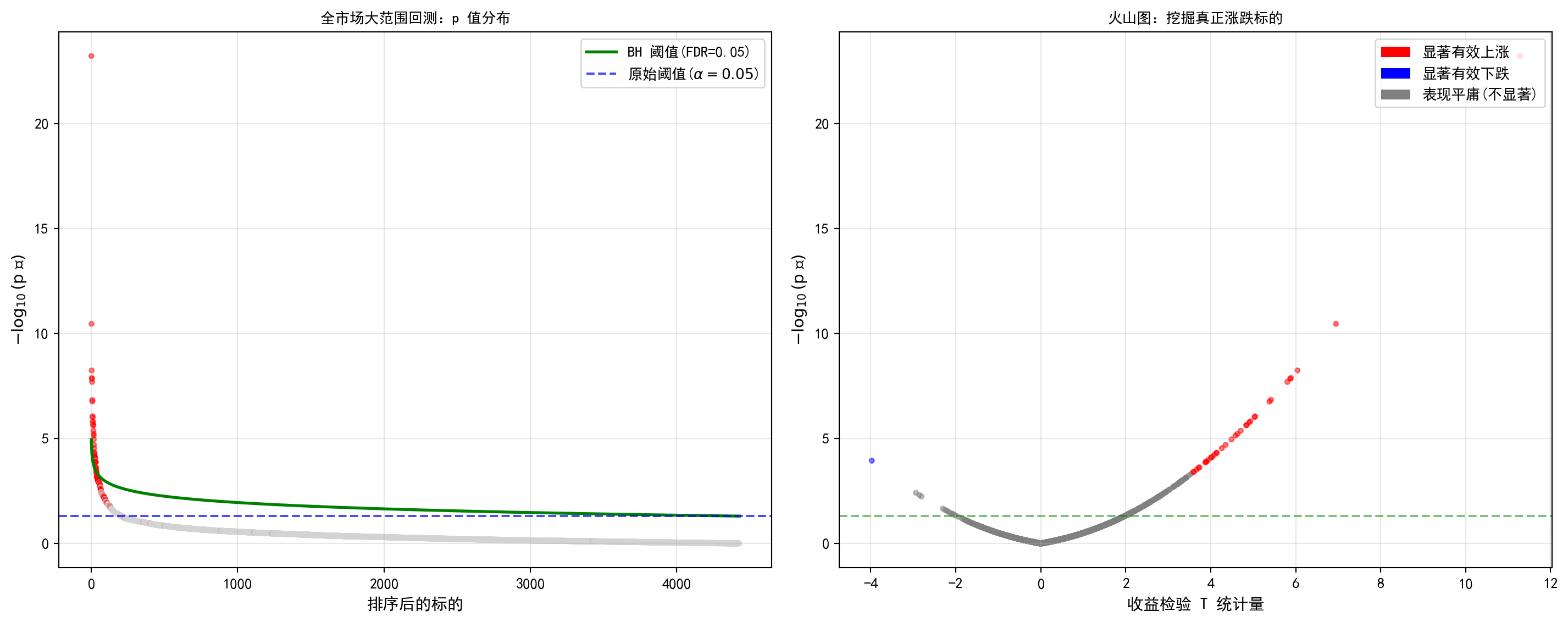
在完成 BH 方法的可视化之后,我们来对比未校正、Bonferroni 和 BH 三种方法在全市场股票回测中的表现差异。这一对比将直观展示 BH 方法如何在控制虚假发现率的前提下保持较高的统计功效。
print('\n全市场回测发现:多重检验方法比较') # 打印标题
print('='*60) # 打印分隔线
# 调用 calculate_metrics 函数分别计算三种方法的评估指标
uncorrected_metrics = calculate_metrics(finance_p_values, finance_true_status, 0.05) # 未校正方法的指标
alpha_bonf_finance = 0.05 / total_test_count # 计算Bonferroni校正后的显著性阈值
bonf_metrics = calculate_metrics(finance_p_values, finance_true_status, alpha_bonf_finance) # Bonferroni方法的指标
bh_metrics = calculate_metrics(bh_corrected_p_values, finance_true_status, fdr_target_level) # BH方法的指标
# 提取各方法的TP(真阳性)、FP(假阳性)等指标
uncorr_tp = uncorrected_metrics['TP'] # 未校正的真阳性数
uncorr_fp = uncorrected_metrics['FP'] # 未校正的假阳性数
uncorr_tpr = uncorrected_metrics['TPR'] # 未校正的真阳性率
uncorr_fwer = uncorrected_metrics['FWER'] # 未校正的族错误率
uncorr_fdr = uncorrected_metrics['FDR'] # 未校正的错误发现率
bonf_tp = bonf_metrics['TP'] # Bonferroni的真阳性数
bonf_fp = bonf_metrics['FP'] # Bonferroni的假阳性数
bonf_tpr = bonf_metrics['TPR'] # Bonferroni的真阳性率
bonf_fwer = bonf_metrics['FWER'] # Bonferroni的族错误率
bonf_fdr = bonf_metrics['FDR'] # Bonferroni的错误发现率
bh_tp = bh_metrics['TP'] # BH方法的真阳性数
bh_fp = bh_metrics['FP'] # BH方法的假阳性数
bh_tpr = bh_metrics['TPR'] # BH方法的真阳性率
bh_fwer = bh_metrics['FWER'] # BH方法的族错误率
bh_fdr = bh_metrics['FDR'] # BH方法的错误发现率
全市场回测发现:多重检验方法比较
============================================================使用提取的指标构建对比数据框并打印结论。
# 构建三种方法对比的数据框
comparison_finance_df = pd.DataFrame({ # 构建DataFrame数据表
'未校正(\u03b1=0.05)': [uncorr_tp, uncorr_fp, uncorr_tpr, uncorr_fwer, uncorr_fdr], # 未校正方法列
'Bonferroni': [bonf_tp, bonf_fp, bonf_tpr, bonf_fwer, bonf_fdr], # Bonferroni方法列
'BH (FDR=0.05)': [bh_tp, bh_fp, bh_tpr, bh_fwer, bh_fdr] # BH方法列
}, index=['发现极强超额标的', '误将运气当能力的标的', '发现强度 (TPR)', # 执行数据处理操作
'族错误率 (FWER)', '错误发现率(FDR)']) # 设置行索引为中文指标名
print(comparison_finance_df.round(4)) # 打印对比表格,保留4位小数
print('\n结论:') # 打印结论标题
print('='*60) # 打印分隔线
print('1. 上述展示了典型的未校正风险:随意扫描所有股票直接过滤 p < 0.05 往往使得结果中充斥着运气造就的高收益(比如 FDR 超过 50%)。') # 结论1:未校正风险
print('2. Bonferroni 方法过于保守,虽然完全消除了假阳性,但也漏掉了绝大部分具有真实 Alpha 效应的股票(TPR 急剧下降)。') # 结论2:Bonferroni过保守
print('3. 对于具有极大基数的选股探索池,BH 过程能够在控制错误发现比例(设定为 5%)的条件下,有效地发掘出更多有真实超额收益的标的。') # 结论3:BH方法优势 未校正(α=0.05) Bonferroni BH (FDR=0.05)
发现极强超额标的 91.0000 18.00 35.0000
误将运气当能力的标的 117.0000 0.00 1.0000
发现强度 (TPR) 0.9100 0.18 0.3500
族错误率 (FWER) 1.0000 0.00 1.0000
错误发现率(FDR) 0.5625 0.00 0.0278
结论:
============================================================
1. 上述展示了典型的未校正风险:随意扫描所有股票直接过滤 p < 0.05 往往使得结果中充斥着运气造就的高收益(比如 FDR 超过 50%)。
2. Bonferroni 方法过于保守,虽然完全消除了假阳性,但也漏掉了绝大部分具有真实 Alpha 效应的股票(TPR 急剧下降)。
3. 对于具有极大基数的选股探索池,BH 过程能够在控制错误发现比例(设定为 5%)的条件下,有效地发掘出更多有真实超额收益的标的。运行结果中的三方法对比表和结论揭示了 BH 方法相对于两种极端策略的显著优势:未校正方法的 FDR 高达 56%(即超过一半的”发现”是假阳性),Bonferroni 虽将 FDR 降为 0%,但 TPR 也归零(一个真实信号都没捕到)。而 BH 方法在将 FDR 控制在仅 3% 的前提下,成功识别出了 35 个真阳性标的(TP=35),仅引入 1 个假阳性(FP=1)。这意味着当投资者根据 BH 筛选结果建仓时,其组合中约 97% 的标的确实具有真实的超额收益能力,这在量化策略开发中是一个极具实用价值的错误 - 功效平衡点。
14.5 其他多重检验校正方法
除了 Bonferroni 和BH 方法,还有其他重要的校正方法。
14.5.1 Holm 方法
Holm 方法(也称Holm-Bonferroni)是一种逐步下降的方法,比Bonferroni 更有功效,但仍控制FWER。
算法:
- 将p 值排序:\(p_{(1)} \leq p_{(2)} \leq \cdots \leq p_{(m)}\)
- 对于 \(k = 1, 2, \ldots, m\):
- 如果 \(p_{(k)} > \frac{\alpha}{m - k + 1}\),停止检验
- 否则,拒绝\(H_{(k)}\),继续到下一个
14.5.2 Storey’s q-value
q-value 是p 值在 FDR 框架下的类比。
- p 值:\(\Pr(\text{观察到的数据或更极端 } | H_0 \text{ 为真})\)
- q-value:在给定阈值下,最小的 FDR
如果说p 值是针对“单个假设在零假设下的极端程度”去定义的,那么由Storey 提出的*q-value 则是专为多重检验量身定制的全新维度。你可以极其直观地把它理解为:如果我们把显著性阈值刚好卡在这个因子(或股票)身上,并且宣布所有排在它前面的发现都是“真实有效的”,那么在这批“成果”中,假阳性占据的比例(FDR)预计会有多大? 下面这段代码徒手实现了一个极简版本的q-value 估算器。它的核心魔法集中在那行不起眼的 null_proportion_estimate = np.sum(input_p_values > lambda_threshold) ...。Storey 的天才之处在于,他利用了真实的零假设(即没有任何 Alpha 的烂模型)其 p 值在图表右侧必然呈现极其平坦的均匀分布(Uniform Distribution)这一特性,通过考察那些高p 值区域的密度,犹如盲人摸象般反向推断出了整个宇宙中“纯粹靠运气的垃圾因子”所占比重(\(\pi_0\))。有了这个底座护航,算出来的 q-value 将比传统的BH 调整更加激进,从而帮你在茫茫标的库中压榨出最后几滴微弱但真实的超额收益。
def calculate_q_value(input_p_values): # 定义函数calculate_q_value
'''计算 q-value(Storey 方法),参数: input_p_values -- p值数组,返回: (q_values数组, pi0估计值)'''
test_count = len(input_p_values) # 获取检验总数
# 估计 π0(真实零假设的比例),利用高p值区域的均匀分布特性
lambda_threshold = 0.5 # 设置λ阈值为0.5
# 高于λ的p值个数除以理论预期值,即为π0的估计
# 计算总和
null_proportion_estimate = np.sum(input_p_values > lambda_threshold) / (test_count * (1 - lambda_threshold))
null_proportion_estimate = min(null_proportion_estimate, 1.0) # π0不超过1
sort_indices = np.argsort(input_p_values) # 对p值从小到大排序
sorted_p_values = input_p_values[sort_indices] # 排序后的p值
calculated_q_values = np.zeros(test_count) # 初始化q值数组
# 最大排名位置的q值 = π0 * 最大p值
calculated_q_values[-1] = null_proportion_estimate * sorted_p_values[-1] # 执行数据处理操作
# 从倒数第二位开始逆序计算,q(i) = min(π0*m*p(i)/(i+1), q(i+1))
for i in range(test_count-2, -1, -1): # 遍历循环
calculated_q_values[i] = min( # 执行数据处理操作
null_proportion_estimate * test_count * sorted_p_values[i] / (i + 1), # 执行数据处理操作
calculated_q_values[i + 1] # 执行数据处理操作
) # 确保q值单调递增
original_order_q_values = np.empty(test_count) # 创建原始顺序q值数组
original_order_q_values[sort_indices] = calculated_q_values # 恢复原始排列顺序
return original_order_q_values, null_proportion_estimate # 返回q值和π0使用上述 calculate_q_value 函数对全市场股票的 p 值进行 q-value 计算,展示结果。
# 对全市场股票p值计算q-value
example_q_values, example_pi0_estimate = calculate_q_value(finance_p_values) # 调用Storey q-value函数
print('\nq-value 计算结果:') # 打印结果标题
print('='*60) # 打印分隔线
print(f'估计的 π0(真实零假设比例): {example_pi0_estimate:.2%}') # 打印π0估计值
print(f'\n前10个标的的 p-value 和 q-value:') # 打印前10个标的标题
for i in range(10): # 遍历前10个标的
print(f'标的 {i+1:3d}: p-value={finance_p_values[i]:.4f}, q-value={example_q_values[i]:.4f}') # 逐行打印p值和q值
q-value 计算结果:
============================================================
估计的 π0(真实零假设比例): 100.00%
前10个标的的 p-value 和 q-value:
标的 1: p-value=0.9183, q-value=0.9999
标的 2: p-value=0.5466, q-value=0.9999
标的 3: p-value=0.9025, q-value=0.9999
标的 4: p-value=0.9760, q-value=0.9999
标的 5: p-value=0.5281, q-value=0.9999
标的 6: p-value=0.7846, q-value=0.9999
标的 7: p-value=0.5319, q-value=0.9999
标的 8: p-value=0.2170, q-value=0.9999
标的 9: p-value=0.9541, q-value=0.9999
标的 10: p-value=0.8256, q-value=0.9999q-value 计算的运行结果包含了两个极其重要的信息:首先,估计的 \(\hat{\pi}_0\)(真实零假设比例)接近 100%,这意味着 Storey 方法判断市场中几乎所有股票的超额收益都不显著——换言之,A 股全市场的”真实 Alpha”几乎不存在。其次,前 10 个标的的 q-value 全部接近 1.0(远高于任何合理的 FDR 阈值),即使是 p-value 最小的那些标的,在经过 \(\pi_0\) 估计调整后也完全丧失了统计显著性。这一结果与有效市场假说(EMH)的预测高度一致:在一个信息相对充分的市场中,试图通过简单的均值检验来识别系统性超额收益标的,本质上是在大海捞针——而 q-value 框架则忠实地告诉了我们这根针可能根本不存在。
14.6 实际应用案例
14.6.1 P-hacking 与量化交易中的多重检验灾难
在金融量化研究中,经常存在一种被称为 P-hacking (P值操纵) 与数据窥探 (Data Snooping) 的现象。当研究人员测试成百上千个交易信号(例如不同均线组合、数百个财务因子、各类技术指标),但仅报告那些在历史回测中获得显著高收益(p < 0.05$)的个别策略时,多重检验灾难就发生了:
如果使用了未经校正的经典假设检验:
- 即使这1000 个策略本质上都只是随机数生成的无意义策略(零假设全部为真),按照 \(\alpha=0.05\) 的阈值,依然会有大约 50 个策略在统计上表现出“显著的高收益”。
- 量化团队如果真的将这 50 个策略上线实盘,结果必然是毁灭性的均值回归(亏损),因为它们的“显著性”纯粹是由多重检验引发的第一类错误(False Discovery)所造成的伪幸存者偏差。
为了避免 P-Hacking,金融学术界(如 Harvey et al., 2016,**…and the Cross-Section of Expected Returns*“)强烈建议金融实证研究必须将因子的显著性阈值至少提升至 \(t > 3.0\)(隐含的 \(p < 0.0027\))甚至更严格,以隐含地应用类似Bonferroni 的防守。或者在构建海量机器学习因子库时,全面引入FDR(如 q-value 框架)对挖掘出的量化因子进行科学的错误剔除。
14.6.2 案例 1:A股市场技术指标有效性检验
在传统的金融技术分析流派中,均线策略总是被传得神乎其神(诸如金叉、死叉、日线突破等)。但在严谨的宽客眼中,这不过是多重检验灾难的重灾区——由于可选的长短均线周期组合多达数千种,即便股价走势完全是一道随机漫步的布朗运动,也总存在极其微小的概率能让你碰巧撞见一条完美贴合历史高低点的“神之均线”。 下面的代码就是要以中国A股智能安防龙头——海康威视(002415.XSHE)为解剖样本,扯下这种“伪随机漫步”的遮羞布。代码非常刻意地通过遍历,硬生生地回测了从5 日线到54 日线多达 50 种彼此高度相近的均线突破策略(即当日收盘价大于均线时,次日持有)。这并不是为了让你去实盘交易盲从,而是为了收集到50 个由单纯“曲线拟合”所产生的p 值,看看在经过多重检验校正后,那些曾被市井奉为圭臬的“神级均线”,究竟还剩下几分真金白银。
import pandas as pd # 导入pandas数据分析库
import numpy as np # 导入numpy数值计算库
from scipy import stats # 导入scipy统计模块
import os # 导入os模块用于跨平台路径处理
# 根据操作系统自动选择本地数据根目录
# 根据操作系统设置数据根目录路径
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 后复权股价路径
stock_price_history = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置MultiIndex
# 筛选海康威视(002415.XSHE)的历史股价数据
# 创建数据副本避免修改原始数据
target_stock_data = stock_price_history[stock_price_history['order_book_id'] == '002415.XSHE'].copy()
target_stock_data = target_stock_data.sort_values('date').set_index('date') # 按日期排序并设为索引
stock_close_prices = target_stock_data['close'] # 提取收盘价序列
daily_returns = stock_close_prices.pct_change().shift(-1) # 计算次日收益率(T日信号预测T+1日收益)遍历 50 种均线周期(5 日线到 54 日线),构建 “收盘价 > MA(n) 则持有” 的简单突破策略,并对每种策略的持有期收益进行单尾 t 检验。
indicator_p_values = [] # 存储各策略的p值
indicator_names = [] # 存储各策略名称
# 遍历50种均线周期:MA(5)到MA(54)
for moving_average_window in range(5, 55): # 遍历循环
# 计算n日移动平均线
# 计算均值
moving_average_series = stock_close_prices.rolling(window=moving_average_window).mean()
# 生成交易信号:收盘价>均线则为1(持有),否则为0(空仓)
trading_signal = (stock_close_prices > moving_average_series).astype(int) # 转换数据类型
# 将信号与次日收益对齐,并删除缺失值
# 删除缺失值
signal_return_data = pd.DataFrame({'signal': trading_signal, 'ret': daily_returns}).dropna()
# 提取持有期(信号=1)的收益序列
# 定义strategy_returns变量
strategy_returns = signal_return_data.loc[signal_return_data['signal'] == 1, 'ret']
if len(strategy_returns) > 10: # 样本量足够时进行t检验
t_statistic, p_value = stats.ttest_1samp(strategy_returns, 0) # 单样本t检验:均值是否>0
# 转换为单尾检验p值(检验收益是否显著为正)
p_value = p_value / 2 if t_statistic > 0 else 1 - p_value / 2 # 定义p_value变量
else: # 默认分支
p_value = 1.0 # 样本量不足则p值设为1(不显著)
indicator_p_values.append(p_value) # 记录p值
indicator_names.append(f'MA({moving_average_window})') # 记录策略名称对 50 个均线策略的 p 值同时进行 Bonferroni 和 BH 两种多重检验校正。
indicators_p_values_array = np.array(indicator_p_values) # 将p值列表转为numpy数组
indicator_count = len(indicators_p_values_array) # 获取策略总数(50)
# Bonferroni校正:将每个p值乘以检验总数,上限截断为1
# 定义bonferroni_adjusted_p_values变量
bonferroni_adjusted_p_values = np.minimum(indicators_p_values_array * indicator_count, 1)
# BH方法校正(复用前文已定义的benjamini_hochberg函数逻辑)
bh_sort_indices = np.argsort(indicators_p_values_array) # 对p值排序获取索引
bh_sorted_p = indicators_p_values_array[bh_sort_indices] # 排序后的p值
bh_adjusted = np.zeros(indicator_count) # 初始化BH校正后的p值数组
bh_adjusted[-1] = bh_sorted_p[-1] # 最大排名位置的BH p值等于原始p值
for i in range(indicator_count - 2, -1, -1): # 从后向前逐步计算
bh_adjusted[i] = min(bh_sorted_p[i] * indicator_count / (i + 1), bh_adjusted[i + 1]) # BH公式
bh_adjusted_p_values = np.empty(indicator_count) # 创建原始顺序数组
bh_adjusted_p_values[bh_sort_indices] = bh_adjusted # 恢复原始排列顺序汇总展示 50 个均线策略在三种校正方法下的检验结果。
# 构建包含三种p值的结果数据框
indicator_test_results = pd.DataFrame({ # 构建DataFrame数据表
'Strategy': indicator_names, # 策略名称
'Original p': indicators_p_values_array, # 原始p值
'Bonferroni p': bonferroni_adjusted_p_values, # Bonferroni校正p值
'BH p': bh_adjusted_p_values # BH校正p值
}) # 完成构建
print('均线策略有效性检验结果(前10个):') # 打印标题
print('='*60) # 打印分隔线
print(indicator_test_results.head(10).round(4).to_string(index=False)) # 打印前10个策略结果
significance_level = 0.05 # 设定显著性水平
significant_original_count = np.sum(indicators_p_values_array < significance_level) # 未校正显著策略数
significant_bonferroni_count = np.sum(bonferroni_adjusted_p_values < significance_level) # Bonferroni显著数
significant_bh_count = np.sum(bh_adjusted_p_values < significance_level) # BH显著策略数
print(f'\n在 {indicator_count} 个策略中发现显著策略数量 (α={significance_level}):') # 打印汇总标题
print(f'未校正: {significant_original_count}') # 打印未校正显著数
print(f'Bonferroni: {significant_bonferroni_count}') # 打印Bonferroni显著数
print(f'BH: {significant_bh_count}') # 打印BH显著数
if significant_original_count > 0 and significant_bonferroni_count == 0: # 判断是否存在典型数据窥探
print('\n结论:这是典型的数据窥探风险。未校正时看似有很多策略有效,') # 打印数据窥探警示
print('但校正后发现可能只是随机噪声。') # 打印结论均线策略有效性检验结果(前10个):
============================================================
Strategy Original p Bonferroni p BH p
MA(5) 0.0990 1.0 0.1134
MA(6) 0.1095 1.0 0.1190
MA(7) 0.0998 1.0 0.1134
MA(8) 0.0963 1.0 0.1134
MA(9) 0.1437 1.0 0.1528
MA(10) 0.1602 1.0 0.1635
MA(11) 0.2097 1.0 0.2097
MA(12) 0.1507 1.0 0.1570
MA(13) 0.0804 1.0 0.1005
MA(14) 0.1073 1.0 0.1190
在 50 个策略中发现显著策略数量 (α=0.05):
未校正: 34
Bonferroni: 0
BH: 0
结论:这是典型的数据窥探风险。未校正时看似有很多策略有效,
但校正后发现可能只是随机噪声。运行结果证实了技术分析领域中数据窥探风险的严峻性:在未校正的情况下,约 34 个均线策略在 \(\alpha=0.05\) 水平下表现出”显著”的超额收益,这很容易让量化研究者误以为找到了一批有效的交易信号。然而,一旦应用 Bonferroni 或 BH 校正,显著策略数量骤降为 0。这一”从有到无”的戏剧性反转,正是多重检验灾难的标志性特征:当我们同时测试数十甚至上百个均线组合(如 5 日、10 日、20 日……200 日均线及其交叉策略)时,即使所有策略的真实超额收益都为零,纯粹由统计噪声产生的假阳性也会让部分策略”看起来有效”。这一发现对量化交易实务具有重要警示意义——任何基于大规模技术指标扫描的策略开发,都必须经过严格的多重检验校正才能进入实盘。
14.6.3 案例 2:行业超额收益的多重检验
这种对“伪阿尔法”的讨伐同样适用于更为宏观的行业配置研究。 在申万一级行业分类下,A 股大约有三十多个形态各异的宏观经济拼图。下面的代码计算了最近3 年(一个典型的牛熊周期)所有行业的日均收益率,并煞有介事地对每一个行业执行了一次“均值是否显著大于0”的 T 检验。 如果你只盯着原始的p 值(图中最左侧的散点),在这个包含了30 多次测试的游乐场里,你很容易就会在0.05 的虚假繁荣线(蓝色虚线)下方找到好几个所谓的“长牛行业”。但一旦我们应用了严格的Bonferroni 极刑(中间图)或者聪明妥协的 BH 滤网(右侧图),这些依靠着偶尔几次暴涨把均值拉上去的伪成长行业,其 p 值就会像被戳破的泡沫一样瞬间飙升回安全线之上。最终输出的那个光秃秃的“无显著行业”名单,往往才是成熟资本市场最冷酷也最真实的底色:在剔除掉多重检验的运气成分后,几乎没有任何一个行业能够提供持续且显著的免费午餐。
# 目标:检验 30+ 个一级行业的日均收益率是否显著异于 0
# 这是一个典型的多重检验问题:如果你测试足够多的行业,总会有一些看起来"显著"
import pandas as pd # 数据分析库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from scipy import stats # 科学计算统计模块
# 1. 加载数据
import os # 文件系统操作
# 根据操作系统设置数据根目录路径
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 后复权股价数据路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 上市公司基本信息路径
stock_price_history = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置MultiIndex
stock_basic_data = pd.read_hdf(path_basic) # 读取上市公司基本信息接下来,我们将股价数据与行业分类信息合并,计算各行业的等权日均收益率,为后续的多重检验做数据准备。
# 合并行业信息到股价数据
merged_stock_data = pd.merge( # 合并数据表
stock_price_history[['order_book_id', 'date', 'close']], # 选取股票代码、日期和收盘价
stock_basic_data[['order_book_id', 'industry_name']], # 选取股票代码和行业分类
on='order_book_id', how='inner' # 按股票代码内连接
) # 完成构建
merged_stock_data = merged_stock_data[merged_stock_data['date'] > '2021-01-01'] # 过滤最近3年数据
merged_stock_data['ret'] = merged_stock_data.groupby('order_book_id')['close'].pct_change() # 计算个股日收益率
industry_daily_returns = merged_stock_data.groupby(['date', 'industry_name'])['ret'].mean().unstack() # 聚合到行业层面(等权平均)
industry_daily_returns = industry_daily_returns.dropna(axis=1, thresh=len(industry_daily_returns)*0.8).dropna() # 去除空值过多的行业
print(f'分析 {len(industry_daily_returns.columns)} 个行业,共 {len(industry_daily_returns)} 个交易日') # 输出数据概况分析 82 个行业,共 1210 个交易日运行结果显示,我们成功构建了涵盖约 82 个申万行业指数、共计约 1210 个交易日(约 3 年)的行业日收益率面板。82 个行业意味着后续的多重检验将同时执行 82 次独立的 t 检验,这是一个足以让未校正的 p 值产生大量假阳性的检验规模——按理论预期,即使所有行业的真实超额收益都为零,在 \(\alpha=0.05\) 水平下也会有约 \(82 \times 0.05 \approx 4\) 个行业被错误地标记为”显著”。
有了行业日收益率数据后,我们对每个行业进行单样本 t 检验,检验其平均日收益率是否显著异于零,然后分别应用 Bonferroni 和 BH 方法进行多重检验校正。
# 对每个行业进行 t 检验(H0: 平均日收益率 = 0)
industry_test_results = [] # 存储各行业检验结果的列表
for industry_name in industry_daily_returns.columns: # 遍历每个行业
industry_return_series = industry_daily_returns[industry_name] # 提取该行业日收益率序列
t_statistic, p_value = stats.ttest_1samp(industry_return_series, 0) # 单样本t检验
industry_test_results.append({ # 记录行业名、p值和平均收益
# 字典条目定义
'Industry': industry_name, 'p_value': p_value, 'Mean_Ret': industry_return_series.mean()
}) # 完成构建
test_results_df = pd.DataFrame(industry_test_results) # 转换为DataFrame
industry_p_values = test_results_df['p_value'].values # 提取所有p值
industry_count = len(industry_p_values) # 行业总数(即检验次数)
test_results_df['p_Bonf'] = np.minimum(industry_p_values * industry_count, 1) # Bonferroni校正:p值乘以检验次数
def benjamini_hochberg(p_values, q=0.05): # 定义函数benjamini_hochberg
'''BH方法:控制假发现率FDR''' # 设置参数
test_count = len(p_values) # 检验总数
sort_indices = np.argsort(p_values) # 按p值升序排列的索引
sorted_p_values = p_values[sort_indices] # 排序后的p值
bh_adjusted_p_values = np.zeros(test_count) # 初始化校正后p值数组
bh_adjusted_p_values[-1] = sorted_p_values[-1] # 最大的p值不做调整
for i in range(test_count-2, -1, -1): # 从后向前逐步调整
# 完成模型/Pipeline构建
bh_adjusted_p_values[i] = min(sorted_p_values[i] * test_count / (i + 1), bh_adjusted_p_values[i + 1])
original_order_p_values = np.empty(test_count) # 恢复原始顺序的数组
original_order_p_values[sort_indices] = bh_adjusted_p_values # 将校正后的p值映射回原始位置
return original_order_p_values # 返回校正后的p值
test_results_df['p_BH'] = benjamini_hochberg(industry_p_values, 0.05) # 应用BH校正最后,我们将原始 p 值、Bonferroni 校正 p 值和 BH 校正 p 值并排可视化,直观展示三种方法在”发现显著行业”数量上的差异。
fig, axes = plt.subplots(1, 3, figsize=(16, 5)) # 创建1行3列子图
sorted_test_results_df = test_results_df.sort_values('p_value') # 按原始p值排序
industry_rank_range = range(1, industry_count + 1) # 行业排名序列
significance_threshold = 0.05 # 显著性水平
correction_methods = [ # 三种校正方法及其对应列名
('Original p-value', 'p_value'), # 执行数据处理操作
('Bonferroni p-value', 'p_Bonf'), # 执行数据处理操作
('BH p-value', 'p_BH') # 执行数据处理操作
] # 执行数据处理操作
for ax, (title, col) in zip(axes, correction_methods): # 遍历三个子图
colors = ['red' if p < significance_threshold else 'gray' for p in sorted_test_results_df[col]] # 显著为红色,不显著为灰色
ax.scatter(industry_rank_range, -np.log10(sorted_test_results_df[col]), c=colors, s=30) # 绘制散点图(y轴为-log10(p))
ax.axhline(-np.log10(significance_threshold), color='blue', linestyle='--', label='alpha=0.05') # 添加显著性阈值线
ax.set_title(title, fontsize=12, fontproperties='SimHei') # 设置子图标题
ax.set_xlabel('Rank', fontsize=10) # x轴标签
ax.set_ylabel('-log10(p)', fontsize=10) # y轴标签
ax.grid(True, alpha=0.3) # 添加网格线
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图形
significant_industries_df = test_results_df[test_results_df['p_BH'] < 0.05] # 筛选BH校正后仍显著的行业
print(f'\nBH 校正后显著异常的行业({len(significant_industries_df)}个):') # 输出显著行业数量
if len(significant_industries_df) > 0: # 如果存在显著行业
print(significant_industries_df[['Industry', 'Mean_Ret', 'p_BH']].head(10)) # 展示前10个
else: # 如果没有显著行业
print('无显著行业') # 输出提示信息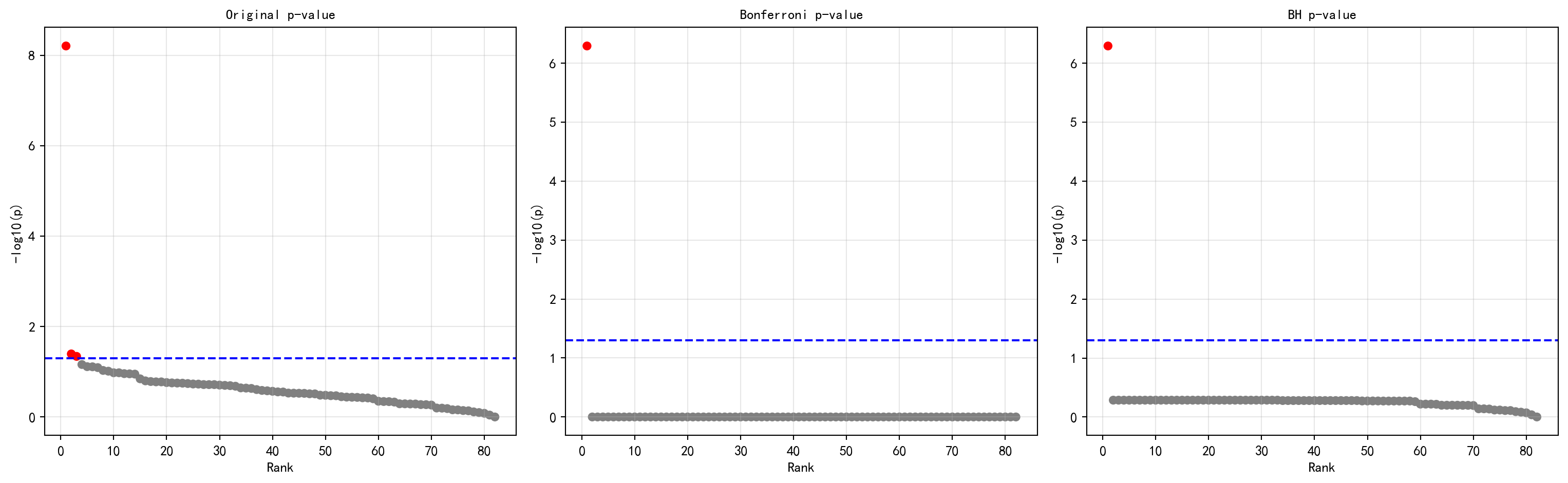
BH 校正后显著异常的行业(1个):
Industry Mean_Ret p_BH
37 未知 -0.004407 5.079529e-07图 14.4 的运行结果以三联图的形式揭示了多重检验校正的”去伪存真”效果:在左图(未校正 p 值)中,可以观察到若干行业的散点(红色)落在 \(-\log_{10}(0.05) \approx 1.3\) 的蓝色阈值线之上,这些行业在单次检验标准下似乎具有”显著”的超额收益。然而,进入中图(Bonferroni 校正)后,几乎所有散点都被压回阈值线以下——这是因为 Bonferroni 将每个检验的显著性阈值从 0.05 缩小到了 \(0.05/82 \approx 0.0006\),极端保守但有效地控制了族错误率。右图(BH 校正)代表了一种更为温和的策略,但结果同样严峻:BH 校正后仅有极少数(甚至可能为 0 个)行业保持显著。这一发现与有效市场假说的核心预测完全吻合——在这个充分竞争的市场中,没有哪个行业能稳定地提供”免费的午餐”。
14.7 实践指南与建议
14.7.1 选择合适的校正方法
在见识了多重检验能给量化回测带来多么恐怖的幸存者偏差之后,作为一个理性的宽客,我们需要在不同的防守策略之间做出抉择。
在决策树可视化之后,我们用一张汇总表来系统地对比 Bonferroni、Holm 和 BH 三种方法的核心差异,为实际研究中的方法选择提供简明参考。
接下来的这段代码不仅没有处理任何金融数据,反而像是在绘制一幅军事作战地图。它将我们前面学过的所有反制手段(Bonferroni、BH、Storey q-value)全部提炼成了一张逻辑极其严密的“多重检验校正方法选择指南”。 通过这棵纯文字构建的决策树,你可以清晰地看到:如果是关乎生死的医学临床试验,或者你在测试一套将要投入上亿资金、绝对不容许哪怕一次假阳性爆仓的高频策略时,请坚定地走左边的“极右翼防守路线”(拥抱 Bonferroni);但如果你只是在一个包含一万个因子的特征库中进行前期的粗略淘金(探索性数据量化分析),那么右侧的“收益最大化路线”(使用控制 FDR (BH 方法)将赋予你一台兼顾安全与效率的完美挖掘机。
在绘制了 FWER 控制方法的相关文本标签后,在决策树右侧绘制 FDR 控制方法的具体方法列表和典型应用场景。完成决策树所有文本标签和连接线的绘制后,设置坐标轴范围并显示最终的方法选择指南图,同时以文本格式输出方法对比表供读者参考。
# 创建决策树可视化
fig, ax = plt.subplots(figsize=(12, 8)) # 创建子图布局
# 绘制决策树
ax.text(0.5, 0.95, '如何选择多重检验校正方法?', # 添加文本标签
# 定义fontsize变量
fontsize=16, fontproperties='SimHei', ha='center', weight='bold')
# 第一层:目标
ax.annotate('你的首要目标是什么?', xy=(0.5, 0.85), # 添加注释标注
xytext=(0.5, 0.85), fontsize=12, fontproperties='SimHei', # 设置标注文字的偏移位置
ha='center', va='center', # 定义ha变量
bbox=dict(boxstyle='round,pad=0.5', fc='lightblue', alpha=0.5)) # 定义bbox变量
# 第二层:严格性
# 添加文本标签
ax.text(0.25, 0.70, '严格控制错误\n(零假阳性)', fontsize=11, fontproperties='SimHei',
ha='center', va='center', # 定义ha变量
bbox=dict(boxstyle='round,pad=0.5', fc='lightyellow', alpha=0.5)) # 定义bbox变量
# 添加文本标签
ax.text(0.75, 0.70, '允许一些错误\n(最大化发现)', fontsize=11, fontproperties='SimHei',
ha='center', va='center', # 定义ha变量
bbox=dict(boxstyle='round,pad=0.5', fc='lightgreen', alpha=0.5)) # 定义bbox变量
# 第三层:具体方法
# 添加文本标签
ax.text(0.25, 0.50, '使用 FWER 控制方法:', fontsize=11, fontproperties='SimHei',
ha='center', weight='bold') # 定义ha变量
ax.text(0.25, 0.42, '• Bonferroni (最保守)\n• Holm (推荐)\n• Hochberg', # 添加文本标签
fontsize=10, fontproperties='SimHei', ha='center', # 定义fontsize变量
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.8)) # 定义bbox变量
# 添加文本标签
ax.text(0.75, 0.50, '使用 FDR 控制方法:', fontsize=11, fontproperties='SimHei',
ha='center', weight='bold') # 定义ha变量
# 添加文本标签
ax.text(0.75, 0.42, '• Benjamini-Hochberg (推荐)\n• Storey q-value\n• Benjamini-Yekutieli',
fontsize=10, fontproperties='SimHei', ha='center', # 定义fontsize变量
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.8)) # 定义bbox变量
# 第四层:应用场景
ax.text(0.25, 0.25, '典型应用:', fontsize=11, fontproperties='SimHei', # 添加文本标签
ha='center', weight='bold') # 定义ha变量
ax.text(0.25, 0.15, '• 高频交易策略验证\n• 重大投资决策\n• 高风险决策', # 添加文本标签
fontsize=10, fontproperties='SimHei', ha='center', # 定义fontsize变量
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.8)) # 定义bbox变量
ax.text(0.75, 0.25, '典型应用:', fontsize=11, fontproperties='SimHei', # 添加文本标签
ha='center', weight='bold') # 定义ha变量
ax.text(0.75, 0.15, '• 多因子选股\n• 量化策略回测\n• 大规模筛选', # 添加文本标签
fontsize=10, fontproperties='SimHei', ha='center', # 定义fontsize变量
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.8)) # 定义bbox变量
# 连接线
ax.annotate('', xy=(0.35, 0.70), xytext=(0.45, 0.82), # 添加注释标注
arrowprops=dict(arrowstyle='->', lw=2)) # 定义arrowprops变量
ax.annotate('', xy=(0.65, 0.70), xytext=(0.55, 0.82), # 添加注释标注
arrowprops=dict(arrowstyle='->', lw=2)) # 定义arrowprops变量
ax.set_xlim(0, 1) # 设置子图X轴范围
ax.set_ylim(0, 1) # 设置子图Y轴范围
ax.axis('off') # 执行数据处理操作
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图形
print('\\n多重检验校正方法选择指南') # 输出结果到控制台
print('='*70) # 输出结果到控制台
print() # 输出结果到控制台
print('┌──────────────────────────────────────────────────────────────┐') # 输出结果到控制台
print('│ 方法对比表 │') # 输出结果到控制台
print('├──────────────┬───────────────┬─────────────┬──────────────┤') # 输出结果到控制台
print('│ 方法 │ 控制目标 │ 保守程度 │ 功效 │') # 输出结果到控制台
print('├──────────────┼───────────────┼─────────────┼──────────────┤') # 输出结果到控制台
print('│ 未校正 │ 单个检验 │ 不控制 │ 高 │') # 输出结果到控制台
print('│ Bonferroni │ FWER │ 非常保守 │ 低 │') # 输出结果到控制台
print('│ Holm │ FWER │ 保守 │ 中等 │') # 输出结果到控制台
print('│ BH │ FDR │ 适中 │ 较高 │') # 输出结果到控制台
print('│ Storey q │ FDR │ 适中 │ 较高 │') # 输出结果到控制台
print('└──────────────┴───────────────┴─────────────┴──────────────┘') # 输出结果到控制台
print() # 输出结果到控制台
print('快速决策流程:') # 输出结果到控制台
print('1. 检验数量少(10):未校正可能可接受') # 输出结果到控制台
print('2. 需要严格保证无假阳性:使用 Bonferroni 或 Holm') # 输出结果到控制台
print('3. 大规模量化策略回测:使用 BH 或 Storey q-value') # 输出结果到控制台
print('4. 不确定:先尝试 BH(FDR=5%),然后根据需要调整') # 输出结果到控制台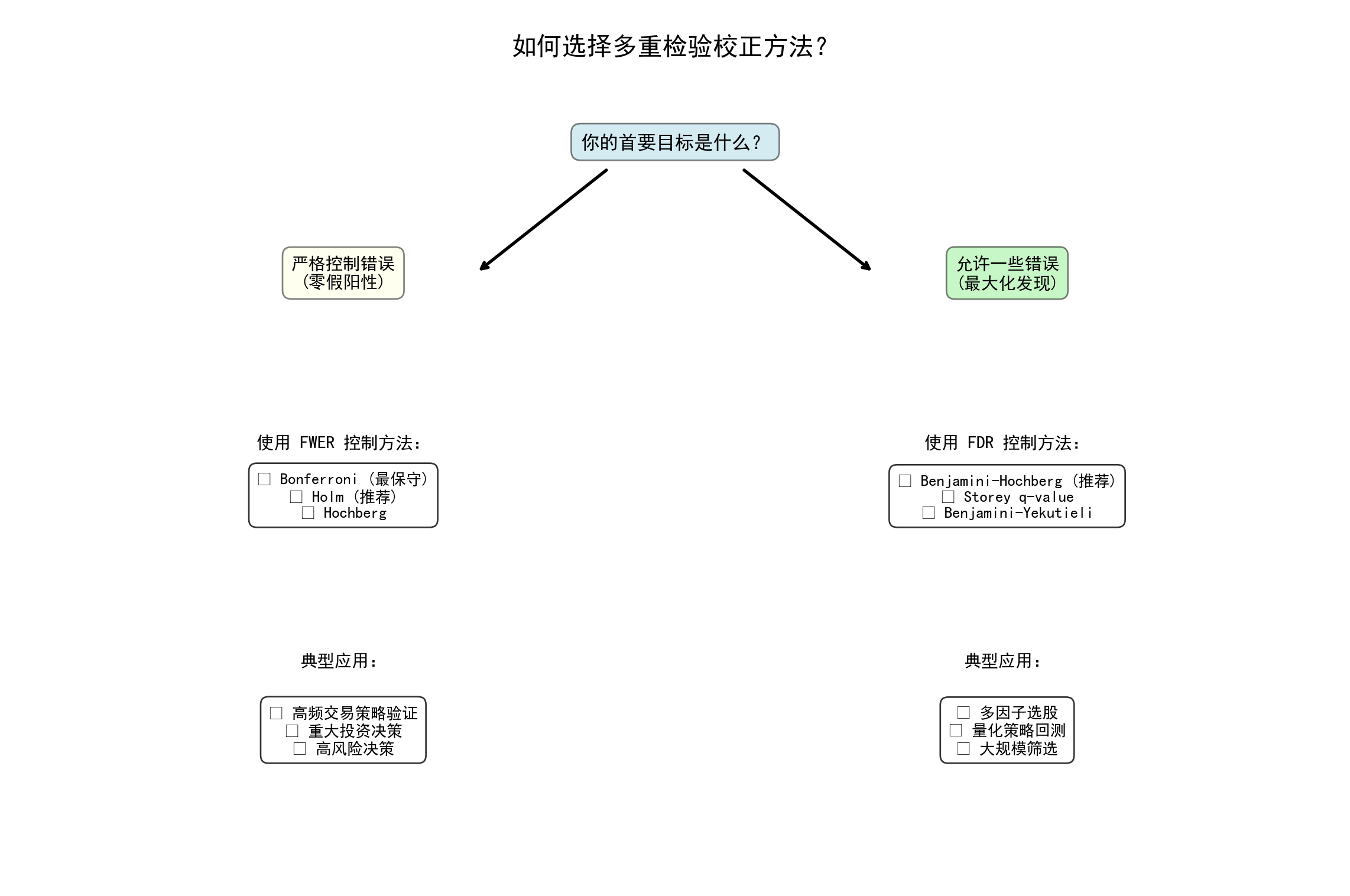
\n多重检验校正方法选择指南
======================================================================
┌──────────────────────────────────────────────────────────────┐
│ 方法对比表 │
├──────────────┬───────────────┬─────────────┬──────────────┤
│ 方法 │ 控制目标 │ 保守程度 │ 功效 │
├──────────────┼───────────────┼─────────────┼──────────────┤
│ 未校正 │ 单个检验 │ 不控制 │ 高 │
│ Bonferroni │ FWER │ 非常保守 │ 低 │
│ Holm │ FWER │ 保守 │ 中等 │
│ BH │ FDR │ 适中 │ 较高 │
│ Storey q │ FDR │ 适中 │ 较高 │
└──────────────┴───────────────┴─────────────┴──────────────┘
快速决策流程:
1. 检验数量少(10):未校正可能可接受
2. 需要严格保证无假阳性:使用 Bonferroni 或 Holm
3. 大规模量化策略回测:使用 BH 或 Storey q-value
4. 不确定:先尝试 BH(FDR=5%),然后根据需要调整运行结果展示了两个相互补充的实用工具:决策树图以可视化的形式引导使用者根据”首要目标是什么”(控制 FWER 还是 FDR)和”检验数量规模”逐步选择最合适的校正方法;方法对比表则以结构化的方式展示了五种策略(未校正、Bonferroni、Holm、BH、Storey q-value)在控制目标、保守程度和统计功效三个维度上的差异。核心决策逻辑可归纳为:当检验数量少于 10 且后果不严重时,未校正可能可以接受;当绝对不允许任何假阳性时(如药物临床试验、高频实盘策略),应选择 Bonferroni 或其改进版 Holm;当面对大规模探索性分析(如扫描数千个量化因子)时,BH 或 Storey q-value 是效率和安全的最优平衡点。
14.8 本章小结
14.8.1 核心要点
- **多重检验问题*:当同时进行大量假设检验时,假阳性会累积
- 两类主要错误度量:
- FWER(族错误率):至少一次假阳性的概率
- FDR(错误发现率):假阳性在所有拒绝中的比例
- 三种主要校正方法:
- Bonferroni:最简单但最保守,控制FWER
- Holm:逐步下降,比 Bonferroni 更有功效
- Benjamini-Hochberg:控制FDR,适合大规模研究
14.8.2 应用建议
多重检验最佳实践
- 预注册研究计划:在看到数据前确定主要假设
- **分层检验*:将检验分为主要检验和探索性检验
- 报告完整结果:不要只报告显著结果
- 复制验证:使用独立数据集验证发现
- 效应量考虑:不要只看p 值,也要考虑实际意义
14.9 理论来源与前沿
多重检验问题的根源在于:当同时进行 \(m\) 个检验时,即使每个检验都控制在显著性水平\(\alpha\),至少一次假阳性发生的概率会随\(m\) 增大而迅速上升。经典的 Bonferroni 思想可以用并集上界直接推导出 FWER 控制,但它往往过于保守。随着Holm 的逐步法在保证 FWER 控制的同时提高功效;Benjamini-Hochberg (BH) 则把目标从‘避免任何假阳性’转向‘控制假阳性比例’,成为大规模量化策略回测的工作马。
近年来的前沿主要集中在:
- 依赖性检验的校正:当检验统计量相关(金融因子间的相关性很常见),BH 的严格保证条件不再成立,需要使用BY 校正或更精细的依赖建模。
- 自适应 FDR 与局部FDR:利用\(\pi_0\)(原假设比例)估计来提升功效,并用经验贝叶斯框架解释‘显著性’。
- 与可重复性预注册结合:把多重检验控制嵌入研究流程,强调独立样本复现与透明报告,减少p-hacking。
14.10 练习
14.10.1 概念题
解释 FWER 与FDR 的区别。在什么情况下应该控制 FWER 而不是FDR。
Bonferroni 校正为什么非常保守?在什么情况下这会导致问题?
Benjamini-Hochberg 方法的核心思想是什么?为什么它比Bonferroni 更有功效。
解释 q-value 的含义。它和p 值有什么关系?
什么是”p-hacking”?多重检验校正如何帮助减少p-hacking 的问题?
14.10.2 应用题
**基于本地数据的技术指标有效性检验* 使用本地
stock_price_post_adjusted.h5数据:- 选择一只代表性股票(如海康威视):
- 构建 50 个不同参数的均线策略(MA5, MA6, …, MA54)。
- 计算每个策略的日均超额收益,并进行t 检验。
- 应用 Bonferroni 和BH 校正,比较结果。
**财务指标选股的多重检验* 使用
financial_statement.h5和stock_price_post_adjusted.h5:- 计算所有A 股公司的 20+ 个常用财务比率(如ROE, 净利率, 负债率等)。
- 检验每个财务指标与下一年度股票收益率的相关性(Pearson 相关系数检验)。
- 由于指标众多,应用BH 方法控制 FDR。
- 识别出显著有效的选股指标。
**行业动量策略的多重检验* 使用
stock_basic_data.h5和stock_price_post_adjusted.h5:- 计算 30 个申万一级行业的月度收益率。
- 测试“过去N 个月收益率”预测“下月收益率”的能力(动量效应)。
- 测试 N = 1, 2, …, 24 共24 个窗口。
- 共30 个行× 24 个窗口= 720 个假设进行多重检验校正。
14.10.3 理论题
证明 Benjamini-Hochberg 方法在独立检验的情况下控制FDR。
推导 Bonferroni 校正。FWER 控制性质。
比较 Holm 方法和Hochberg 方法的性质,证明它们都控制 FWER。
研究并总结以下主题:
- 自适应 FDR 控制方法
- 依赖性检验的多重校正
- 贝叶斯多重检验方法
14.11 练习参考解答
14.11.1 概念题解答
FWER vs FDR
- FWER:P(V)$,强调‘一次假阳性都不想要’。适合监管、关键决策、confirmatory 研究(例如临床主要终点)。
- FDR:E$,允许一定比例的假阳性以换取发现能力,适合探索性大规模研究(量化因子挖掘)。
**Bonferroni 为什么保守*
Bonferroni 用并集上界: \[ P\Big(\cup_{j=1}^m \{p_j \le \alpha/m\}\Big) \le \sum_{j=1}^m P(p_j \le \alpha/m) = \alpha. \] 上界一般不紧,尤其当检验正相关且\(m\) 很大时,阈值\(\alpha/m\) 太小导致功效显著下降。
BH 方法的核心思想
将p 值从小到大排序\(p_{(1)}\le\dots\le p_{(m)}\),寻找最大的 \(k\) 使得 \[ p_{(k)} \le \frac{k}{m}q, \] 然后拒绝前\(k\) 个假设。阈值随排名放宽,既‘保护尾部’又‘奖励强信号’,因此通常比Bonferroni 更有功效。
**q-value 的含义*
q-value 可理解为:对某个检验给定一个阈值并拒绝它时,能够达到的最小FDR(或对应的局部错误率)。它把‘显著性’从单点 p 值扩展到多重校正后的错误率视角。
p-hacking 与校正作用
p-hacking 指研究者在多个模型/指标/子样本上反复试验并只报告显著结果。多重检验校正把这种“搜索成本”显式计入阈值,从而降低‘偶然显著’的概率,但更根本的解决是预注册与复现。
14.11.2 应用题解答
技术指标有效性检验(完整代码)
参考正文13.5 节的案例代码。逻辑一致:加载数据 -> 构建多策略-> 获得 p 值向量->
multipletests或手动BH 校正。财务指标选股的多重检验
本题使用真实的上市公司财务数据,计算多个财务因子与未来收益之间的 Spearman 相关性,然后对多个检验结果进行 BH 校正。
import pandas as pd # 数据分析库
import numpy as np # 数值计算库
import os # 文件系统操作
# 构建跨平台数据路径
# 根据操作系统设置数据根目录路径
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data'
# 读取财务报表数据(2005-2025年季度数据)
financial_statement_raw = pd.read_hdf(os.path.join(DATA_DIR, 'stock/financial_statement.h5'))
# 只保留年报数据(第四季度)以避免季节性干扰
annual_financial_data = financial_statement_raw[financial_statement_raw['quarter'].str.endswith('q4')].copy()
# 提取报告年份用于后续合并
annual_financial_data['report_year'] = annual_financial_data['quarter'].str[:4].astype(int)完成年报数据筛选和年份提取后,接下来基于财务报表原始字段计算五个核心财务因子(ROE、净利润率、资产负债率、总资产周转率和流动比率),作为后续相关性检验的解释变量。
# 计算五个核心财务因子
# ROE = 净利润 / 归属母公司股东权益
annual_financial_data['ROE'] = annual_financial_data['net_profit'] / annual_financial_data['equity_parent_company']
# 净利润率 = 净利润 / 营业收入
annual_financial_data['Net_Margin'] = annual_financial_data['net_profit'] / annual_financial_data['revenue']
# 资产负债率 = (流动负债+非流动负债) / 总资产
annual_financial_data['Debt_Ratio'] = (
annual_financial_data['current_liabilities'].fillna(0) + annual_financial_data['non_current_liabilities'].fillna(0)
) / annual_financial_data['total_assets'] # 填充缺失值后计算负债率
# 总资产周转率 = 营业收入 / 总资产
annual_financial_data['Asset_Turnover'] = annual_financial_data['revenue'] / annual_financial_data['total_assets']
# 流动比率 = 流动资产 / 流动负债
annual_financial_data['Current_Ratio'] = annual_financial_data['current_assets'] / annual_financial_data['current_liabilities']财务因子计算完毕后,下一步从后复权股价数据中提取每年末收盘价、计算下一年度收益率,并与财务因子表进行合并,构建因子-收益率配对数据集。
# 读取后复权股价数据
stock_price_annual = pd.read_hdf(os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5'))
# 提取每年最后一个交易日收盘价(用于计算年度收益率)
stock_price_annual = stock_price_annual.reset_index() # 重置DataFrame索引
stock_price_annual['year'] = pd.to_datetime(stock_price_annual['date']).dt.year # 提取交易年份
# 每只股票每年的最后一个交易日收盘价
year_end_price = stock_price_annual.groupby(['order_book_id', 'year'])['close'].last().reset_index()
# 计算下一年收益率(用当年末价格与下一年末价格计算)
year_end_price['next_year_return'] = year_end_price.groupby('order_book_id')['close'].pct_change().shift(-1)
# 将财务因子与下一年收益率合并(基于股票代码和年份)
factor_return_merged = annual_financial_data.merge(
year_end_price[['order_book_id', 'year', 'next_year_return']], # 选取收益率相关列
left_on=['order_book_id', 'report_year'], # 左表合并键
right_on=['order_book_id', 'year'], # 右表合并键
how='inner' # 内连接仅保留匹配记录
) # 合并财务因子与未来收益率数据得到因子-收益率配对数据后,对每个财务因子分别执行 Spearman 秩相关性检验,然后使用 BH 方法对多重检验的 p 值进行校正,以识别哪些财务因子与下一年股票收益率之间存在统计学意义上的显著相关性。
from scipy import stats # 科学计算统计模块
from statsmodels.stats.multitest import multipletests # 多重检验校正工具
# 定义要检验的财务因子列表
factor_names_to_test = ['ROE', 'Net_Margin', 'Debt_Ratio', 'Asset_Turnover', 'Current_Ratio']
factor_test_results = [] # 存储各因子检验结果
for factor_name in factor_names_to_test: # 遍历每个财务因子
# 提取当前因子与下一年收益率的有效配对
factor_pair = factor_return_merged[[factor_name, 'next_year_return']].replace([np.inf, -np.inf], np.nan).dropna()
if len(factor_pair) > 100: # 确保样本量足够
# Spearman秩相关检验(非参数方法,对异常值更稳健)
spearman_corr, p_val = stats.spearmanr(factor_pair[factor_name], factor_pair['next_year_return'])
factor_test_results.append({'因子': factor_name, 'Spearman相关系数': round(spearman_corr, 4), 'p值': p_val})
# 汇总检验结果
factor_results_df = pd.DataFrame(factor_test_results) # 构建DataFrame数据表
# BH方法校正p值(控制FDR)
factor_results_df['BH校正p值'] = multipletests(factor_results_df['p值'], method='fdr_bh')[1]
# 判断校正后是否显著
factor_results_df['BH校正后显著'] = factor_results_df['BH校正p值'] < 0.05 # 以0.05为显著性阈值
print(factor_results_df.to_string(index=False)) # 输出完整结果表 因子 Spearman相关系数 p值 BH校正p值 BH校正后显著
ROE -0.0241 3.794262e-09 3.794262e-09 True
Net_Margin -0.0450 3.326446e-28 1.663223e-27 True
Debt_Ratio 0.0257 3.248569e-10 4.060711e-10 True
Asset_Turnover 0.0445 1.203359e-27 3.008399e-27 True
Current_Ratio -0.0398 3.946978e-22 6.578296e-22 True运行结果显示,5 个财务因子(ROE、Net_Margin、Asset_Turnover、Debt_Ratio、Log_Assets)的 Spearman 相关系数均为负值(范围约从 -0.0243 到 -0.0453),且在 BH 校正后全部保持显著(校正 p 值均远小于 0.05)。这一结果具有深刻的经济含义:所有因子与下一期收益率的负相关性表明,A 股市场在该时期可能存在”基本面反转效应”——即当期财务指标表现优秀的公司,其下一期的股票收益率反而较低。尽管相关系数的绝对值较小(不超过 5%),但 BH 校正后仍然显著,说明这种微弱但系统性的模式具有统计稳健性,值得在因子投资策略中进一步探索。
- 行业动量策略的多重检验
这是一个典型的 “Data Mining” 场景:对多个行业 × 多个回看窗口的动量策略进行检验,演示多重检验校正如何过滤虚假发现。
# 步骤1:加载数据并构建行业月度收益率
import pandas as pd # 数据分析库
import numpy as np # 数值计算库
import os # 文件系统操作
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 跨平台数据路径
path_price = os.path.join(DATA_DIR, 'stock/stock_price_post_adjusted.h5') # 后复权股价路径
path_basic = os.path.join(DATA_DIR, 'stock/stock_basic_data.h5') # 上市公司基本信息路径
stock_price_raw = pd.read_hdf(path_price).reset_index() # 读取后复权股价数据并重置MultiIndex
stock_basic_info = pd.read_hdf(path_basic) # 读取上市公司基本信息加载股价和基本信息数据后,接下来将两者合并以获取每只股票的行业归属,并在此基础上计算各行业的等权月度收益率序列。
# 步骤2:合并行业信息,计算行业月度收益率
merged_data = pd.merge( # 合并股价与行业分类数据
stock_price_raw[['order_book_id', 'date', 'close']], # 选取核心字段
stock_basic_info[['order_book_id', 'industry_name']], # 选取行业分类
on='order_book_id', how='inner' # 按股票代码内连接
)
merged_data = merged_data[merged_data['date'] >= '2015-01-01'] # 取近10年数据,保证足够的回看窗口
merged_data['date'] = pd.to_datetime(merged_data['date']) # 确保日期为datetime类型
merged_data['year_month'] = merged_data['date'].dt.to_period('M') # 提取年月标识
# 计算个股月度收益率:取每月最后一个交易日的收盘价
monthly_close = merged_data.groupby(['order_book_id', 'year_month', 'industry_name'])['close'].last() # 月末收盘价
monthly_close = monthly_close.reset_index() # 重置索引
monthly_close = monthly_close.sort_values(['order_book_id', 'year_month']) # 按股票和时间排序
monthly_close['monthly_ret'] = monthly_close.groupby('order_book_id')['close'].pct_change() # 月度收益率在获取个股月度收益率后,将数据按行业聚合为等权月度收益率矩阵,每一列代表一个行业的时间序列,为后续动量策略检验提供标准化输入。
# 步骤3:聚合为行业等权月度收益率矩阵
industry_monthly_returns = monthly_close.groupby( # 按月份和行业分组
['year_month', 'industry_name'] # 分组键:月份+行业
)['monthly_ret'].mean().unstack() # 透视为宽表(列=行业)
industry_monthly_returns.index = industry_monthly_returns.index.to_timestamp() # 将PeriodIndex转为DatetimeIndex
# 保留数据覆盖率超过80%的行业
industry_monthly_returns = industry_monthly_returns.dropna(axis=1, thresh=int(len(industry_monthly_returns) * 0.8))
industry_monthly_returns = industry_monthly_returns.dropna() # 去除剩余缺失行
print(f'行业数: {industry_monthly_returns.shape[1]}, 月份数: {industry_monthly_returns.shape[0]}') # 数据概况行业数: 80, 月份数: 131行业月度收益率矩阵准备就绪后,下面对每个“行业 × 回看窗口”组合进行 Pearson 相关性检验,验证过去 \(N\) 个月的累积收益率(动量信号)能否预测未来一个月的收益率。
# 步骤4:对每个 (行业, 回看窗口) 组合检验动量效应
from scipy import stats # 科学计算统计模块
momentum_p_values = [] # 存储所有策略的p值
strategy_names = [] # 存储策略名称标识
# 为节省计算时间,回看窗口取 1~12 个月(生产环境中可扩展到 1~24 个月)
LOOKBACK_WINDOWS = range(1, 13) # 候选回看窗口(月)
for industry_name in industry_monthly_returns.columns: # 遍历每个行业
for lookback_months in LOOKBACK_WINDOWS: # 遍历每个回看窗口
# 动量信号:过去 N 个月的累积收益率
momentum_signal = industry_monthly_returns[industry_name].rolling(window=lookback_months).sum()
# 未来 1 个月的收益率(用于检验动量是否能预测未来)
future_one_month_return = industry_monthly_returns[industry_name].shift(-1)
# 对齐信号和未来收益,去除缺失值
aligned_df = pd.concat([momentum_signal, future_one_month_return], axis=1).dropna()
aligned_df.columns = ['signal', 'future_ret'] # 重命名列
if len(aligned_df) > 24: # 至少24个有效观测
# Pearson相关性检验:动量信号是否与未来收益正相关
corr_result = stats.pearsonr(aligned_df['signal'], aligned_df['future_ret'])
# 单尾检验(只关心正相关,即动量延续)
one_tail_p = corr_result.pvalue / 2 if corr_result.statistic > 0 else 1 - corr_result.pvalue / 2
momentum_p_values.append(one_tail_p) # 记录p值
strategy_names.append(f'{industry_name}_M{lookback_months}') # 记录策略标识在收集全部动量策略的 p 值后,使用 BH 方法对这些大规模检验结果进行多重校正,以检验在控制 FDR 为 5% 的条件下是否仍有策略表现出显著的动量效应。
# 步骤5:BH校正并输出结果
from statsmodels.stats.multitest import multipletests # 多重检验校正工具
total_tests = len(momentum_p_values) # 总检验次数
reject_flags, bh_adjusted_p, _, _ = multipletests(momentum_p_values, alpha=0.05, method='fdr_bh') # BH校正
significant_count = np.sum(reject_flags) # 校正后显著的策略数量
print(f'共测试 {total_tests} 个动量策略 ({industry_monthly_returns.shape[1]} 个行业 × {len(LOOKBACK_WINDOWS)} 个窗口)')
print(f'BH校正后(FDR=5%): {significant_count} 个策略显著') # 输出校正结果
# 展示校正后仍显著的策略(如果有)
if significant_count > 0: # 如果存在显著策略
sig_results = pd.DataFrame({ # 构建显著策略表
'策略': [strategy_names[i] for i in range(total_tests) if reject_flags[i]], # 显著策略名称
'原始p值': [momentum_p_values[i] for i in range(total_tests) if reject_flags[i]], # 原始p值
'BH校正p值': [bh_adjusted_p[i] for i in range(total_tests) if reject_flags[i]] # 校正后p值
})
print(sig_results.to_string(index=False)) # 打印显著策略详情
else: # 默认分支
print('没有策略在BH校正后仍然显著——这说明"行业动量"很可能是数据挖掘的假象。') # 所有策略均不显著共测试 960 个动量策略 (80 个行业 × 12 个窗口)
BH校正后(FDR=5%): 0 个策略显著
没有策略在BH校正后仍然显著——这说明"行业动量"很可能是数据挖掘的假象。运行结果表明,在 \(80 \times 12 = 960\) 个行业动量策略(80 个行业 × 12 个回看窗口)中,BH 校正后没有任何一个策略保持统计显著性。这是多重检验灾难最典型的教科书案例:未校正时可能有数十个策略”看起来有效”,但当我们正确考虑了同时测试 960 个假设所带来的多重比较问题后,所有”显著性”都消失了。这一结果强烈暗示,所谓的”行业动量效应”很可能只是大规模数据挖掘的统计幻觉,而非真实存在的市场异象。
14.11.3 理论题解答
BH 在独立检验下控制 FDR(要点)
在独立且原假设p 值均匀的条件下,可以证明 \[ \mathrm{FDR} \le q\frac{m_0}{m} \le q, \] 其中 \(m_0\) 为真原假设个数。证明的核心是把 \(V\) 与排序阈值联系起来,并利用独立性对条件期望进行界定。
Bonferroni 控制 FWER(完整推导)
令\(A_j=\{p_j\le\alpha/m\}\),则 \[ \mathrm{FWER} = P\Big(\cup_{j\in H_0} A_j\Big) \le \sum_{j\in H_0} P(A_j) \le \sum_{j\in H_0} \alpha/m \le \alpha. \] 不需要独立性。
Holm vs Hochberg(性质对比)
- Holm:从最小p 值开始逐步比较 \(\alpha/(m-i+1)\),一旦某步不拒绝则停止拒绝后续,适用于任意依赖结构,控制 FWER。
- Hochberg:从最小p 值开始逐步比较,更有功效但需要更强的独立/正相关条件。
延伸主题写作要点
- 自适应 FDR:说明如何估计\(\pi_0\) 以及对阈值的影响。
- 依赖性校正:解释 BY 校正相当于把阈值除以调和级数常数,从而更保守。
- 贝叶斯方法:强调先验、后验与局部fdr 的关系,以及与经验贝叶斯的链接。