# ============================================================
# 第一步:导入必需的Python工具库
# ============================================================
import numpy as np # 科学计算库,提供高效的数组运算(类似Excel中的批量公式计算)
import pandas as pd # 数据分析库,提供类似Excel电子表格的DataFrame数据结构
import platform # 系统平台检测库,用于自动识别当前操作系统(Windows/Linux)
import matplotlib.pyplot as plt # 绘图库,用于生成统计图表(类似Excel的图表功能,但更强大)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 设置中文字体,优先使用思源宋体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题
from sklearn.preprocessing import PolynomialFeatures # 将原始特征x扩展为多项式 [1, x, x², ..., x^d]
from sklearn.linear_model import LinearRegression # 最基本的线性回归模型(最小二乘法拟合)
from sklearn.metrics import mean_squared_error # 计算均方误差(MSE),衡量预测精度
from sklearn.model_selection import train_test_split # 将数据随机分为训练集和验证集
np.random.seed(42) # 设置随机种子为42,确保每次运行结果完全一致(科学研究的可复现性要求)6 重采样方法 (Resampling Methods)
6.1 引言 (Introduction)
重采样方法(resampling methods)是现代统计学中不可或缺的工具。它们涉及从训练集中重复抽取样本并对每个样本重新拟合感兴趣的模型,从而获得关于拟合模型的额外信息。例如,为了估计线性回归拟合的变异性,我们可以从训练数据中反复抽取不同的样本,对每个新样本拟合线性回归,然后检查结果拟合的差异。这种方法使我们能够获得仅使用原始训练样本拟合模型一次所无法获得的信息。
重采样方法的计算成本可能很高,因为它们涉及使用训练数据的不同子集多次拟合相同的统计学习方法。然而,由于近年来计算能力的进步,重采样方法的计算需求通常不会成为限制因素。在本章中,我们将讨论两种最常用的重采样方法:交叉验证(cross-validation)和自助法(bootstrap)。这两种方法都是许多统计学习过程实际应用中的重要工具。
Note on 重采样方法的理论起源
重采样方法的理论基础可以追溯到20世纪70年代末和80年代初的统计学研究。自助法(Bootstrap)由Bradley Efron在1979年提出,这是统计学史上最具影响力的方法之一。交叉验证的概念则更早,可以追溯到20世纪中叶的模型选择研究。
这些方法的重要性在于它们提供了一种计算密集型但理论简单的方式来评估统计模型的性能,而不依赖于强分布假设。这使得它们在实际应用中极具价值,尤其是在传统统计推断方法可能失效的情况下。
模型评估与模型选择:
在统计学习中,我们通常关注两个相关但不同的任务:
- 模型评估(Model Assessment):评估一个给定统计学习方法在未见过的数据上的预期表现
- 模型选择(Model Selection):为模型选择适当的灵活度水平
交叉验证可以用来估计给定统计学习方法的测试误差,以评估其性能或选择适当的灵活度水平。而自助法最常用于提供参数估计或给定统计学习方法的准确性度量。
案例背景: A股个股收益率预测
在本章中,我们将使用中国A股市场的真实交易数据来演示各种重采样方法。我们将重点关注海康威视 (002415.XSHE),这是中国智能安防领域的行业龙头企业。
该数据集包含以下变量:
- 收益率(Return):当天的股票收益率(%)
- Lag1:前一天的收益率(%)
- Lag2:前两天的收益率(%)
- Volume:成交量
- Volatility:波动率指标
我们的目标是建立预测模型,试图根据过去的表现预测未来的收益率,并使用重采样方法评估模型的预测准确性。虽然股票市场预测非常困难(根据有效市场假说),但它是演示模型评估技术的绝佳场景。
6.2 交叉验证 (Cross-Validation)
在 章节 3 中,我们讨论了测试误差率(test error rate)和训练误差率(training error rate)之间的区别。测试误差是使用统计学习方法预测新观测(即未用于训练该方法的测量)响应时的平均误差。如果有一个指定的测试集,测试误差很容易计算。然而,通常情况并非如此。
相比之下,训练误差可以通过将统计学习方法用于训练中的观测来轻松计算。但正如我们在 章节 3 中所见,训练误差率通常与测试误差率相当不同,特别是前者可能严重低估后者。
在没有一个非常大的指定测试集可以直接估计测试误差率的情况下,可以使用几种技术利用可用的训练数据来估计这个量。一些方法通过对训练误差率进行数学调整来估计测试误差率。这些方法在 章节 7 中讨论。在本节中,我们考虑一类通过从拟合过程中保留训练观测的子集,然后将统计学习方法应用于那些保留的观测来估计测试误差率的方法。
在 小节 6.2.1 至 小节 6.2.4 中,为了简单起见,我们假设对定量响应进行回归。在 小节 6.2.5 中,我们考虑定性响应的分类情况。正如我们将看到的,无论响应是定量还是定性的,关键概念保持不变。
6.2.1 验证集方法 (The Validation Set Approach)
假设我们想要估计在一组观测上拟合特定统计学习方法的测试误差。验证集方法(validation set approach)是 图 6.1 的一个非常简单的策略。它涉及随机将可用观测集分为两部分:训练集(training set)和验证集(validation set)或保留集(hold-out set)。模型在训练集上拟合,并使用拟合的模型预测验证集中观测的响应。由此产生的验证集误差率——在定量响应的情况下通常使用MSE(均方误差)评估——提供了测试误差率的估计。
案例应用:使用多项式回归拟合海康威视股价收益率
让我们使用海康威视的真实历史数据来说明验证集方法。我们想要研究当天的收益率与前一天收益率之间是否存在非线性关系。
为了用真实市场真金白银的波动验证这个重采样评估过程,以下 Python 代码从本地直接抽取了 A 股长三角地区智能安防龙头企业“海康威视(002415.SZ)”过去 500 个交易日的日度真实收益率时间序列。在此任务中,我们试图用昨天的收益率(Lag1)去拟合并探测今天收益率(Return)可能存在的哪怕是极其微弱的非线性二次或高次多项式组合效应。为了评估这套机制,代码直接采用了最刚性的“验证集方法”:利用 train_test_split 直白地将这 500 天数据随机一分为二。在图表的左半部分,你看到的是“单次”切割后,模型随着多项式复杂阶数增加(1阶到5阶)在那个特定验证子集上计算出的 MSE 评估曲线;而在图表的右半图,代码写了一个 for 循环,并将这种随机对半切割验证整整重复了 10 遍!看着右图满天飞舞、毫无共识的 10 条五颜六色的评估折线,你应该能立刻顿悟验证集方法的阿喀琉斯之踵——它的最终评估结果对“如何划分这刀切在哪”实在太敏感、变异震荡性也太剧烈了。
接下来,我们从本地磁盘读取海康威视的真实股票交易数据,并计算日收益率和滞后收益率,为后续的回归建模做准备。
# ============================================================
# 第二步:从本地磁盘读取海康威视的真实股票交易数据
# ============================================================
# 根据操作系统自动选择正确的数据路径(支持Windows和Linux两个平台)
# 根据操作系统设置数据根目录路径
data_base_path = 'C:/qiufei/data' if platform.system() == 'Windows' else '/home/ubuntu/r2_data_mount/data'
# 拼接完整的数据文件路径(HDF5格式,一种高效的二进制存储格式)
stock_data_path = f'{data_base_path}/stock/stock_price_pre_adjusted.h5' # 拼接前复权股价数据的完整文件路径
# 读取A股所有上市公司2005-2025年的前复权日度行情数据
stock_data = pd.read_hdf(stock_data_path) # 从HDF5文件读取数据
# 从数千只股票中筛选出海康威视(股票代码002415.XSHE,XSHE=深圳证券交易所)
if 'order_book_id' in stock_data.index.names: # 获取索引
# xs方法:从多层索引(order_book_id, date)中按股票代码"切片"提取海康威视数据
stock_data = stock_data.xs('002415.XSHE', level='order_book_id').copy() # 使用cross-section方法提取特定截面数据
else: # 默认分支
# 如果没有多层索引,按列条件筛选
stock_data = stock_data[stock_data['order_book_id'] == '002415.XSHE'].copy() # 创建数据副本避免修改原始数据
stock_data = stock_data.sort_index() # 按日期升序排列,确保时间序列的先后顺序正确
# 计算日收益率(百分比形式):pct_change()计算每天收盘价相对前一天的百分比变化
stock_data['Return'] = stock_data['close'].pct_change() * 100 # 计算百分比变化(收益率)
# 创建"滞后收益率"特征:shift(1)将昨天的收益率作为今天的预测变量
stock_data['Lag1'] = stock_data['Return'].shift(1) # 创建滞后一期特征:将昨日收益率作为今日的预测变量
# 去除含缺失值的行(第一天没有"昨天的收益率",Lag1为NaN)
analysis_data = stock_data[['Return', 'Lag1']].dropna() # 删除缺失值
# 只取最近500个交易日的数据用于演示(iloc[-500:]取最后500行)
analysis_data = analysis_data.iloc[-500:] # 只取最近500个交易日用于演示
# ============================================================
# 第三步:准备建模所需的自变量(X)和因变量(Y)
# ============================================================
# features(特征/自变量):昨天的收益率Lag1(.values转为NumPy数组,sklearn要求矩阵输入)
features = analysis_data[['Lag1']].values # 提取为NumPy数组
# target_returns(目标/因变量):今天的实际收益率,这是我们想要预测的
target_returns = analysis_data['Return'].values # 提取为NumPy数组以上代码完成了海康威视股票数据的加载和预处理。接下来,我们将使用验证集方法评估不同复杂度多项式模型的预测表现,并通过可视化揭示该方法的局限性。
左图展示了单次随机分割的验证结果。但仅靠一次分割可靠吗?接下来我们重复10次不同的随机分割,揭示验证集方法对分割方式高度敏感的致命缺陷。
# 第四步:创建包含两个子图的画布(左右并排)
# ============================================================
# figsize=(16,6):画布宽16英寸、高6英寸
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建子图布局
# ============================================================
# 第五步(左图):单次随机分割 —— 展示验证集方法的基本流程
# ============================================================
# 测试1阶到5阶多项式(即直线、抛物线、三次曲线等)
# 金融数据中信号微弱,太高阶的多项式容易过拟合噪音
degrees = range(1, 6) # 定义待测试的多项式阶数范围(1阶到5阶)
# 用一个空列表来收集每个阶数对应的验证集MSE
validation_mse_list = [] # 初始化空列表,用于存储各阶数的验证集MSE
# 【重要提醒】对于时间序列数据,标准做法应该按时间顺序切分(前80%训练,后20%验证)
# 但这里为了演示"验证集方法的随机性缺陷"(即不同随机切分导致结果差异大),
# 我们故意使用随机打乱切分。金融实务中请务必使用时间顺序切分!
# train_test_split:将500天数据随机对半分成250天训练集 + 250天验证集
# test_size=0.5 表示50%作为验证集;random_state=0 固定这次的随机方式
# 划分训练集和测试集
features_train, features_valid, target_train, target_valid = train_test_split(features, target_returns, test_size=0.5, random_state=0)
# 依次尝试1阶到5阶多项式模型
for degree in degrees: # 遍历循环
# 创建多项式特征转换器:把原始特征x扩展为 [1, x, x², ..., x^degree]
# 例如degree=2时,输入Lag1=3,输出变为 [1, 3, 9],这样线性回归就能拟合二次曲线
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建指定阶数的多项式特征转换器
# fit_transform:先学习训练集的特征范围,再将训练集转换为多项式特征
poly_features_train = polynomial_transformer.fit_transform(features_train) # 拟合并转换训练集特征
# transform:用训练集学到的转换规则来转换验证集(保证训练和验证用同样的标准)
poly_features_valid = polynomial_transformer.transform(features_valid) # 对数据进行转换
# 在训练集的多项式特征上拟合线性回归模型
# 虽然叫"线性回归",但由于输入已经包含了x²、x³等高阶项,实际上拟合的是多项式曲线
linear_model = LinearRegression() # 创建线性回归模型实例
linear_model.fit(poly_features_train, target_train) # 在训练集的多项式特征上拟合模型参数
# 用训练好的模型对验证集进行预测
predicted_returns = linear_model.predict(poly_features_valid) # 使用模型进行预测
# 计算验证集的均方误差MSE = Σ(实际值-预测值)² / 样本数
# MSE越小,说明模型在验证集上的预测越准确
current_mse = mean_squared_error(target_valid, predicted_returns) # 计算均方误差
# 将当前阶数的MSE添加到列表中
validation_mse_list.append(current_mse) # 将当前阶数的MSE添加到列表中
# ---------- 绘制左图 ----------
# 画出MSE随多项式阶数变化的折线图
# marker='o':每个数据点用圆点标记;linewidth=2:线宽2像素
axes[0].plot(degrees, validation_mse_list, marker='o', linewidth=2, markersize=8, # 绘制MSE随阶数变化的折线图
color='#E74C3C', label='验证集MSE') # 设置红色线条和图例标签
# 找出MSE最小的那个阶数(即"最优"模型复杂度)
best_degree = degrees[np.argmin(validation_mse_list)] # 获取最小值的索引
# 在最优阶数处画一条蓝色虚线,便于读者一眼看到最佳选择
axes[0].axvline(best_degree, linestyle='--', color='blue', # 在最优阶数处绘制垂直虚线
alpha=0.5, label=f'最优阶数: {best_degree}') # 设置半透明效果和图例标签
# 设置坐标轴标签和标题
axes[0].set_xlabel('多项式阶数', fontsize=13, fontweight='bold') # X轴标签:多项式阶数
axes[0].set_ylabel('均方误差 (MSE)', fontsize=13, fontweight='bold') # Y轴标签:均方误差
axes[0].set_title('单次随机分割的验证MSE (海康威视收益率)\n(Single Random Split)', fontsize=14, fontweight='bold') # 子图标题
# 显示图例(说明每条线代表什么)
axes[0].legend(fontsize=11) # 显示图例说明
# 添加网格线,alpha=0.3表示透明度30%,让网格线不那么突兀
axes[0].grid(True, alpha=0.3) # 添加半透明网格线辅助读数
# ============================================================
# 第六步(右图):重复10次不同的随机分割 —— 暴露验证集方法的致命缺陷
# ============================================================
# 核心思想:同样的数据,仅仅因为"随机切分方式"不同,得到的MSE曲线就天差地别
# 这说明验证集方法的结论对"切分方式"非常敏感,不够可靠
for i in range(10): # 遍历循环
# 每次用不同的random_state(0到9)来产生不同的随机分割方案
# 划分训练集和测试集
features_train, features_valid, target_train, target_valid = train_test_split(features, target_returns, test_size=0.5,
random_state=i) # 每次使用不同随机种子产生不同分割
# 每次分割都重新计算各阶数的MSE
validation_mse_list_split = [] # 初始化当次分割的MSE列表
for degree in degrees: # 遍历循环
# 构建多项式特征(与左图完全相同的流程)
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建多项式转换器
poly_features_train = polynomial_transformer.fit_transform(features_train) # 拟合并转换训练集特征
poly_features_valid = polynomial_transformer.transform(features_valid) # 用训练集规则转换验证集
# 拟合线性回归并在验证集上预测
linear_model = LinearRegression() # 创建回归模型实例
linear_model.fit(poly_features_train, target_train) # 拟合模型参数
predicted_returns = linear_model.predict(poly_features_valid) # 对验证集进行预测
current_mse = mean_squared_error(target_valid, predicted_returns) # 计算当前阶数的验证MSE
validation_mse_list_split.append(current_mse) # 将该阶数的MSE添加到列表中
# 画出这次分割对应的MSE曲线(alpha=0.4表示半透明,方便观察多条线的重叠)
axes[1].plot(degrees, validation_mse_list_split, alpha=0.4, linewidth=1.5) # 绘制当次分割的MSE曲线(半透明)
# ---------- 绘制右图的坐标轴和标题 ----------
axes[1].set_xlabel('多项式阶数', fontsize=13, fontweight='bold') # X轴标签
axes[1].set_ylabel('均方误差 (MSE)', fontsize=13, fontweight='bold') # Y轴标签
axes[1].set_title('10次不同随机分割的验证MSE\n(Ten Different Random Splits)', # 设置右图标题
fontsize=14, fontweight='bold') # 子图标题
axes[1].grid(True, alpha=0.3) # 添加网格线
# 自动调整子图间距,防止标签重叠
plt.tight_layout() # 自动调整子图间距
# 渲染并显示图形
plt.show() # 显示图形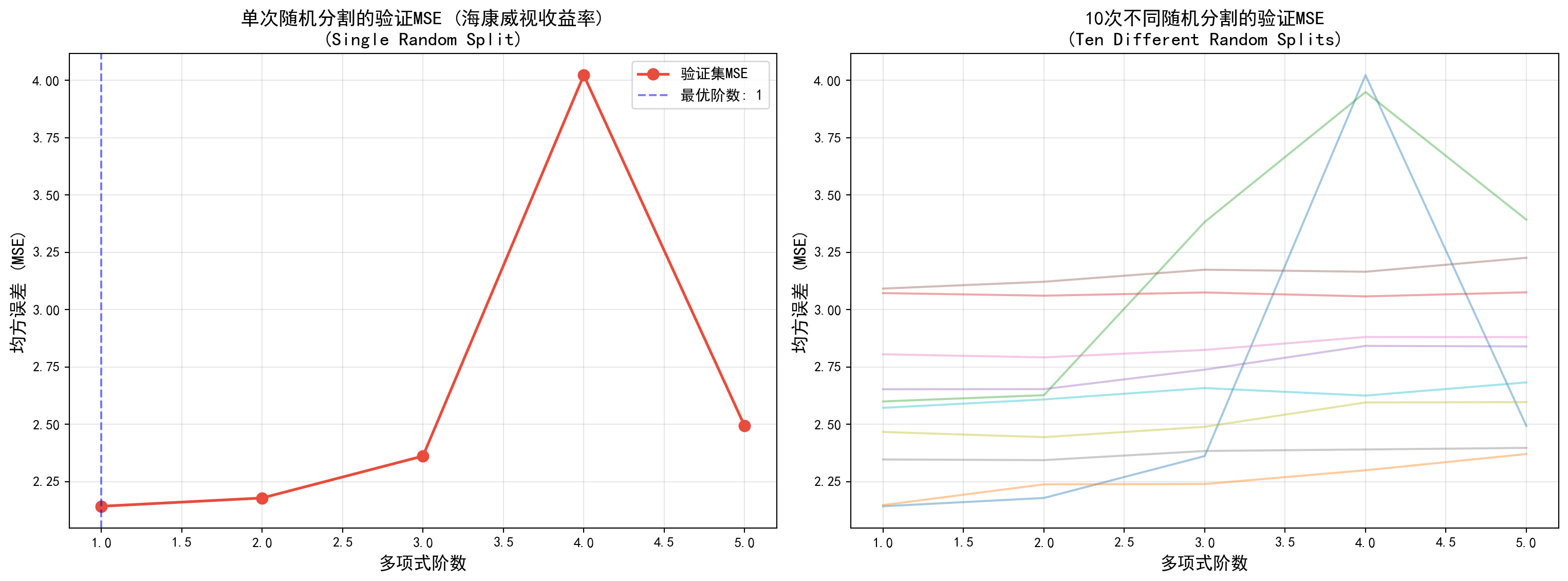
从 图 6.2 的结果可以看出:
结果的随机性:不同的验证集分割导致了MSE曲线的显著差异。有些分割可能显示二次项有帮助,而另一些则显示线性模型最好,甚至没有任何模型比截距项(0阶)更好(考虑到股票收益的不可预测性,这很常见)。
高变异性:这再次证实了验证集方法的一个主要缺点——估计的测试误差具有高变异性。
模型选择的不确定性:依据单次分割的结果来选择模型阶数是不可靠的。
注: 在金融时间序列中,通常我们不会看到像物理定律或模拟数据那样清晰的”U型”误差曲线,这也是真实数据分析的挑战之一。
验证集方法的优点和缺点:
验证集方法在概念上很简单,易于实现。但它有两个潜在缺点:
估计的高变异性:如 图 6.2 的右图所示,测试误差率的验证估计可能具有很高的变异性,这取决于具体哪些观测包含在训练集中,哪些包含在验证集中。
估计的高偏差:在验证方法中,只有包含在训练集中的观测子集(而不是验证集中的那些)被用于拟合模型。由于统计方法在较少观测上训练时往往表现较差,这表明验证集误差率可能会高估在整个数据集上拟合的模型的测试误差率。
在接下来的小节中,我们将介绍交叉验证(cross-validation),这是验证集方法的一种改进,旨在解决这两个问题。
6.2.2 留一交叉验证 (Leave-One-Out Cross-Validation)
留一交叉验证(Leave-One-Out Cross-Validation, LOOCV)与 小节 6.2.1 的验证集方法密切相关,但它试图解决该方法的缺点。
与验证集方法类似,LOOCV涉及将观测集分为两部分。然而,它不是创建两个相当大小的子集,而是使用单个观测\((x_1, y_1)\)作为验证集,其余观测\(\{(x_2, y_2), \ldots, (x_n, y_n)\}\)构成训练集。统计学习方法在\(n-1\)个训练观测上拟合,并对被排除的观测使用其值\(x_1\)进行预测\(\hat{y}_1\)。由于\((x_1, y_1)\)未用于拟合过程,\(\text{MSE}_1 = (y_1 - \hat{y}_1)^2\)提供了测试误差的近似无偏估计。但即使\(\text{MSE}_1\)对测试误差是无偏的,它也是一个较差的估计,因为它高度依赖于单个观测\((x_1, y_1)\)。
我们可以通过选择\((x_2, y_2)\)作为验证数据来重复该过程,在\(n-1\)个观测\(\{(x_1, y_1), (x_3, y_3), \ldots, (x_n, y_n)\}\)上训练统计学习程序,并计算\(\text{MSE}_2 = (y_2 - \hat{y}_2)^2\)。重复此方法\(n\)次将产生\(n\)个平方误差\(\text{MSE}_1, \text{MSE}_2, \ldots, \text{MSE}_n\)。
测试MSE的LOOCV估计是这\(n\)个测试误差估计的平均值:
\[ \text{CV}_{(n)} = \frac{1}{n}\sum_{i=1}^{n}\text{MSE}_i \tag{6.1}\]
图 6.3 展示了LOOCV方法的示意图。
LOOCV与验证集方法的比较:
LOOCV相对于验证集方法有几个主要优点:
偏差更小:在LOOCV中,我们重复使用包含\(n-1\)个观测的训练集来拟合统计学习方法,这几乎与整个数据集中的观测数量一样多。这与验证集方法形成对比,后者训练集通常约为原始数据集大小的一半。因此,LOOCV方法往往不会像验证集方法那样高估测试误差率。
结果确定性:与验证集方法不同,后者由于训练/验证集分割的随机性,重复应用时会产生不同的结果,而多次执行LOOCV将总是产生相同的结果:训练/验证集分割中没有随机性。
Tip: LOOCV的计算捷径
对于最小二乘线性或多项式回归,有一个惊人的捷径可以使LOOCV的成本与单次模型拟合相同!以下公式成立:
\[ ext{CV}_{(n)} = \frac{1}{n}\sum_{i=1}^{n}\left(\frac{y_i - \hat{y}_i}{1 - h_i}\right)^2 \tag{6.2}\]
其中\(\hat{y}_i\)是来自原始最小二乘拟合的第\(i\)个拟合值,\(h_i\)是第\(i\)个观测的杠杆值(leverage)。
这就像普通的MSE,只是第\(i\)个残差除以\(1-h_i\)。杠杆值在\(1/n\)和\(1\)之间,反映了观测对其自身拟合的影响量。因此,高杠杆点的残差在这个公式中被精确地放大了正确的量,以使这个等式成立。
LOOCV是一个非常通用的方法,可以用于任何类型的预测建模。例如,我们可以将其用于逻辑回归或线性判别分析,或在后续章节中讨论的任何方法。然而,“神奇公式”(式 6.2)在一般情况下不成立,在这种情况下,模型必须重新拟合\(n\)次。
6.2.3 k折交叉验证 (k-Fold Cross-Validation)
LOOCV的一个替代方案是k折交叉验证(k-fold CV)。这种方法涉及随机将观测集分为\(k\)个组或折(folds),大小大致相等。第一折被视为验证集,方法在剩余的\(k-1\)折上拟合。然后对保留折中的观测计算均方误差\(\text{MSE}_1\)。该过程重复\(k\)次;每次,不同的一组观测被视为验证集。这个过程产生\(k\)个测试误差估计\(\text{MSE}_1, \text{MSE}_2, \ldots, \text{MSE}_k\)。k折CV估计通过平均这些值计算:
\[ \text{CV}_{(k)} = \frac{1}{k}\sum_{i=1}^{k}\text{MSE}_i \tag{6.3}\]
图 6.4 展示了k折CV方法的示意图。
LOOCV与k折CV的关系:
不难看出,LOOCV是k折CV的特殊情况,其中\(k\)设置为等于\(n\)。在实践中,通常使用\(k=5\)或\(k=10\)执行k折CV。使用\(k=5\)或\(k=10\)而不是\(k=n\)的优点是什么?
最明显的优点是计算上的。LOOCV需要拟合统计学习方法\(n\)次。这可能非常耗时(对于通过最小二乘拟合的线性模型除外,在这种情况下可以使用公式@eq-loocv-shortcut)。但交叉验证是一个非常通用的方法,可以应用于几乎任何统计学习方法。一些统计学习方法的拟合过程计算量大,因此执行LOOCV可能会带来计算问题,特别是当\(n\)非常大时。相比之下,执行10折CV只需要拟合学习过程十次,这可能更可行。
图 6.5 比较了LOOCV和10折CV在海康威视股价预测上的表现。
为了横向对比并彻底明白这两种交叉验证机制在评估模型泛化性能上的内生异同,下面的代码专门运用 sklearn.model_selection 模块构建了一场精彩的“极限切片(LOOCV)”与“10折交叉(10-Fold)”的 PK 测试。对于同一批海康威视的历史收益率序列数据,我们分别施加不同阶次的多项式模型拟合。在图表的左侧,代码毫不妥协地强制执行了理论上最严谨但昂贵的 LOOCV——这意味着底层数据有多少行(例如 300 行),机器学习引擎就雷打不动地硬碰硬从头拟合了 300 次回归模型,最后画出了那条独一无二、毫无随机波动的黑色绝对误差曲线。而在图表的右侧,我们抛弃了这种笨拙,使用了计算代价仅为十分之一的 10折交叉验证,并且故意利用 KFold(shuffle=True) 并在改变随机数种子的情况下将其重复执行了 9 遍,画出了 9 条细细的彩色折线。你只要将目光横向对比左右两图就会惊讶地发现:那些计算极其廉价而又略显散乱的 10折验证曲线群,它们集体勾勒出的 U 型误差低谷趋势和相对凹段位置,竟然与左侧耗费巨额算力才硬生生穷举得到的绝对权威 LOOCV 曲线惊人的重合!这个视觉事实极其有力地揭示和论证了为什么 10折 CV 在保证精度的同时能够兼顾算力,从而成为当今工业界机器学习评估金标准的实战底气。
# ============================================================
# 第一步:导入交叉验证所需的额外工具库
# ============================================================
from sklearn.model_selection import KFold, cross_val_score # KFold:K折数据分割器;cross_val_score:自动化交叉验证
# ============================================================
# 第二步:复用之前代码块已加载的海康威视数据
# ============================================================
# Quarto文档中代码块按顺序执行,前面已加载analysis_data、features、target_returns
# 测试1阶到5阶多项式(金融数据信号微弱,高阶容易过拟合噪音)
degrees = range(1, 6) # 设定多项式阶数范围(1阶到5阶)
# ============================================================
# 第三步:执行LOOCV(留一交叉验证)
# ============================================================
# LOOCV的核心思想:假设有n个数据点,每次留出1个作为验证,剩余n-1个训练
# 重复n次,每次留出不同的点,最后取n次误差的平均值
# 优点:几乎无偏(训练集大小接近全集);缺点:需要训练n次模型,计算量极大
loocv_errors = [] # 存储每个多项式阶数的LOOCV平均误差
# 依次尝试每个多项式阶数,计算对应的LOOCV误差
for degree in degrees: # 遍历循环
# 将原始特征转换为多项式特征(例如degree=3时,Lag1变为[1, Lag1, Lag1², Lag1³])
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建指定阶数的多项式特征转换器
# fit_transform:先学习特征范围,再将特征转换为多项式形式
poly_features = polynomial_transformer.fit_transform(features) # 拟合并转换全部特征
# 关键:n_splits=len(features) 意味着折数等于样本数,即每折只留1个样本——这正是LOOCV的定义
kfold_splitter = KFold(n_splits=len(features), shuffle=True, random_state=42) # 折数等于样本量,实现留一交叉验证
# 创建线性回归模型实例
linear_model = LinearRegression() # 初始化线性回归模型
# cross_val_score自动完成:分折→训练→预测→计算MSE的全部流程
# scoring='neg_mean_squared_error':sklearn约定"越大越好",所以MSE取负值
cv_score_results = cross_val_score(linear_model, poly_features, target_returns, # 执行LOOCV交叉验证评估
cv=kfold_splitter, scoring='neg_mean_squared_error') # 指定LOOCV折数和评价指标
# 取负号将sklearn的"负MSE"还原为正常的MSE值,再取均值后追加到列表
loocv_errors.append(-cv_score_results.mean()) # 计算平均MSE并追加到结果列表
# ============================================================LOOCV计算已完成。接下来,我们将对同一数据执行多次10折交叉验证,并通过可视化对比两种方法的结果,验证10折CV作为LOOCV高效替代品的可靠性。
# 第四步:执行10折CV(重复9次不同的随机分割)
# ============================================================
# 创建包含两个子图的画布(左图LOOCV,右图10折CV)
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建子图布局
# ---------- 左图:绘制LOOCV的MSE曲线 ----------
# 这条曲线是"权威基准":因为LOOCV几乎无偏,是理论上最严格的估计
axes[0].plot(degrees, loocv_errors, marker='o', linewidth=2.5, markersize=8, # 绘制LOOCV误差曲线
color='#E74C3C', label='LOOCV误差') # 红色线条表示LOOCV误差
# 找出LOOCV认为最优的多项式阶数
best_degree_loocv = degrees[np.argmin(loocv_errors)] # 获取最小值的索引
# 用蓝色虚线标记最优阶数
axes[0].axvline(best_degree_loocv, linestyle='--', color='blue', alpha=0.5, # 蓝色虚线标记最优阶数
label=f'最优阶数: {best_degree_loocv}') # 设置图例文本显示最优阶数值
axes[0].set_xlabel('多项式阶数', fontsize=13, fontweight='bold') # X轴标签
axes[0].set_ylabel('均方误差 (MSE)', fontsize=13, fontweight='bold') # Y轴标签
axes[0].set_title('留一交叉验证 (LOOCV)', fontsize=14, fontweight='bold') # 左图标题
axes[0].legend(fontsize=11) # 显示图例
axes[0].grid(True, alpha=0.3) # 添加半透明网格线
# ---------- 右图:9次不同随机种子的10折CV ----------
# 核心目的:展示10折CV虽然每次结果略有波动,但整体趋势与LOOCV高度一致
# 这证明了10折CV是LOOCV的高效替代品(计算量仅为1/n × 10)
for i in range(9): # 遍历循环
kfold_errors = [] # 每次随机分割对应的MSE列表
# n_splits=10:将数据分成10份,每次用9份训练、1份验证
# shuffle=True:打乱数据顺序后再分折(对非时间序列数据)
# random_state=i:不同的i产生不同的分折方案
kfold_splitter = KFold(n_splits=10, shuffle=True, random_state=i) # 初始化K折交叉验证
# 依次尝试每个多项式阶数,计算对应的10折CV误差
for degree in degrees: # 遍历循环
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建多项式转换器
poly_features = polynomial_transformer.fit_transform(features) # 转换原始特征为多项式特征
linear_model = LinearRegression() # 创建线性回归模型实例
# 10折CV:自动重复10次"训练+验证",返回10个负MSE值
# 执行10折交叉验证评估
cv_score_results = cross_val_score(linear_model, poly_features, target_returns,
cv=kfold_splitter, scoring='neg_mean_squared_error') # 指定10折CV和MSE评价指标
kfold_errors.append(-cv_score_results.mean()) # 还原为正常MSE后追加到列表
# 画出这次随机分割对应的MSE曲线(半透明,方便观察9条线的分布)
axes[1].plot(degrees, kfold_errors, alpha=0.4, linewidth=1.5) # 绘制当次分割的MSE曲线
axes[1].set_xlabel('多项式阶数', fontsize=13, fontweight='bold') # X轴标签
axes[1].set_ylabel('均方误差 (MSE)', fontsize=13, fontweight='bold') # Y轴标签
axes[1].set_title('10折交叉验证 (9次不同随机分割)', fontsize=14, fontweight='bold') # 右图标题
axes[1].grid(True, alpha=0.3) # 添加网格线
# 自动调整子图间距
plt.tight_layout() # 自动调整子图间距
# 渲染并显示图形
plt.show() # 显示图形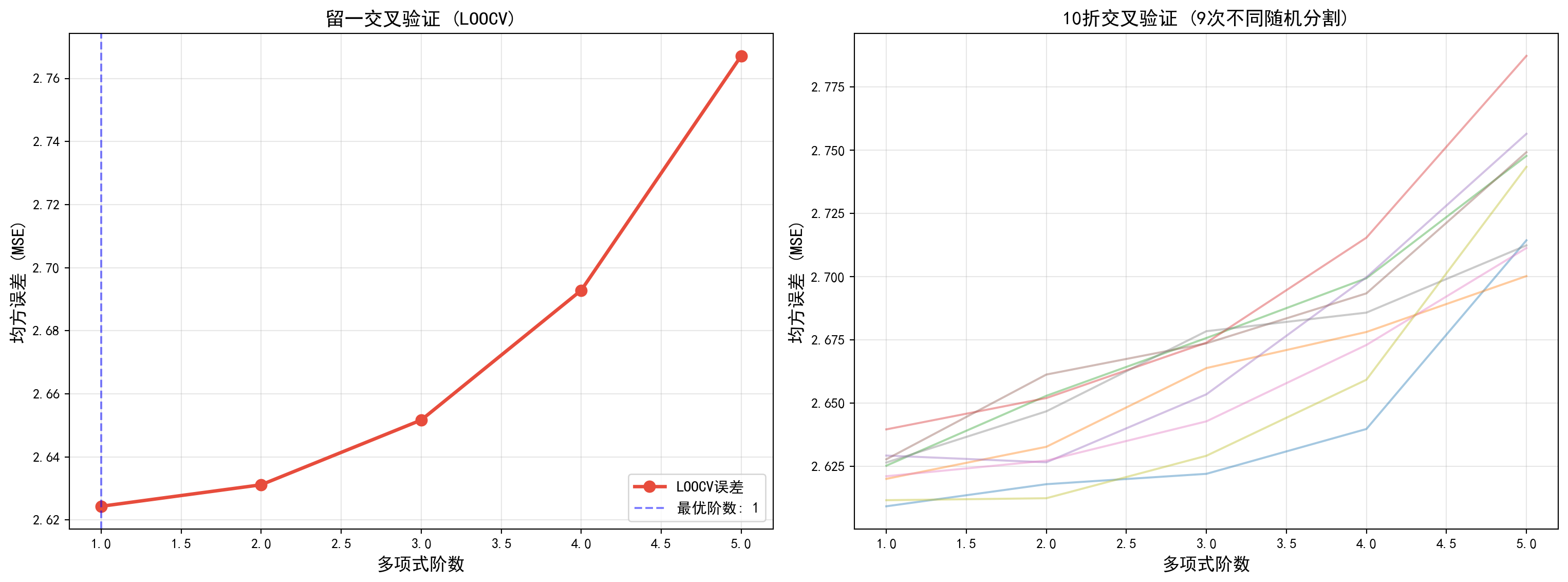
从 图 6.5 可以看出,10折CV估计有一些变异性,这是由于观测如何被分为十折的变异性。但这种变异性通常远小于验证集方法产生的测试误差估计的变异性(图 6.2 的右图)。
k折CV的偏差-方差权衡:
我们提到\(k < n\)的k折CV相对于LOOCV具有计算优势。但抛开计算问题不谈,k折CV有一个不明显但可能更重要的优点,即它往往比LOOCV提供更准确的测试误差率估计。这与偏差-方差权衡有关。
验证集方法可能导致测试误差率的高估,因为在该方法中,用于拟合统计学习方法的训练集仅包含整个数据集的一半观测。使用这个逻辑,不难看出LOOCV将给出测试误差的近似无偏估计,因为每个训练集包含\(n-1\)个观测,这几乎与完整数据集中的观测数量一样多。并且执行\(k=5\)或\(k=10\)的k折CV将导致中等水平的偏差,因为每个训练集大约包含\((k-1)n/k\)个观测——比LOOCV方法少,但比验证集方法多得多。
然而,我们还需要考虑估计过程的方差。LOOCV具有比\(k < n\)的k折CV更高的方差。为什么是这样?当我们执行LOOCV时,我们实际上是在平均\(n\)个拟合模型的输出,每个模型都是在几乎相同的观测集上训练的;因此,这些输出彼此高度(正)相关。相比之下,当我们执行\(k < n\)的k折CV时,我们是在平均\(k\)个拟合模型的输出,这些模型的相关性较低,因为每个模型中训练集之间的重叠较小。
由于许多高度相关量的平均值比许多不那么高度相关的量的平均值具有更高的方差,因此LOOCV产生的测试误差估计往往比k折CV产生的测试误差估计具有更高的方差。
总结起来,在选择k折交叉验证中的\(k\)时存在偏差-方差权衡。通常,考虑到这些因素,使用\(k=5\)或\(k=10\)执行k折交叉验证,因为这些值已被经验证明产生的测试误差率估计既不会受过高的偏差影响,也不会受到很高的方差影响。
6.2.4 交叉验证在时间序列(金融数据)中的特殊性
在经典统计学习中,我们通常假设观测数据是独立同分布(i.i.d)的。然而,在金融领域的实证研究中(例如我们在本章预测海康威视的股票收益),数据通常是具有序列自相关的时间序列(Time Series)。如果我们在时间序列数据上直接使用标准的 k 折交叉验证(即在切分数据前随机打乱观测序列的顺序),会导致严重的数据泄露(Data Leakage)。
数据泄露的原因与后果: 在金融经济学预测中,核心目标是使用历史信息推断未来状态。如果在时间序列数据上实施随机交叉验证,由于随机洗牌,某一折的训练集中不可避免地包含了属于“未来”的观测点,而验证集却在使用“过去”的特征。这打破了时间因果性,使得模型不仅利用了历史规律,还“提前预见”了未来的波动(例如宏观基本面因子的周期性共振)。其后果是,模型在交叉验证阶段评估出的测试误差显得极具吸引力,但一旦引入完全未见过的样本外真实交易中,这种盲目的乐观偏差会导致严重的超额亏损。
前向交叉验证 (Walk-Forward / Time Series Split CV): 为了处理时间序列或投资组合的面板数据,学术界和量化工业界必须采用严格遵循时间先后顺序的重采样验证。常见做法包括:
- 滚动窗口 (Rolling Window):维持一个固定长度的时间窗口(如过去500个交易日)在时间轴上向右滑动,使用窗口内数据重新训练模型,然后在紧随其后的固定交易日度(如未来20天)进行样本外评估。
- 扩张窗口 (Expanding Window):训练集的起点固定,终点随着时间的推移不断向右推进,容纳所有已知的历史观测值,同时在增量时间步的数据上进行验证。
在进行任何金融相关的实证预测模型(从因子暴露的线性回归到复杂的LSTM)时,前向交叉验证是确立模型真实有效性的黄金标准。
6.2.5 分类问题的交叉验证
到目前为止,我们在结果\(Y\)为定量的回归设置中说明了交叉验证的使用,并使用MSE来量化测试误差。但当\(Y\)为定性时,交叉验证也可以在分类设置中成为一个非常有用的方法。在这种情况下,交叉验证的工作方式与本章前面描述的完全相同,只是我们不是使用MSE来量化测试误差,而是使用分类错误观测的数量。
例如,在分类设置中,LOOCV误差率采用以下形式:
\[ \text{CV}_{(n)} = \frac{1}{n}\sum_{i=1}^{n}\text{Err}_i \tag{6.4}\]
其中\(\text{Err}_i = I(y_i \neq \hat{y}_i)\)。k折CV误差率和验证集误差率的定义类似。
案例应用:预测海康威视股价涨跌 (Market Direction)
让我们使用一个二元分类案例来演示交叉验证在分类问题中的应用。我们想要预测海康威视股价明天是上涨还是下跌。
为了在实际的业务沙盘中检验这套机制,接下来的代码段展示了交叉验证如何完美适应于“是”或“否”的定性分类评估场景。我们使用了 A 股海康威视的真实日度收益序列,并以非常简单的标准定义了“涨”(收益率 > 0 作为标签 1)和“跌”(作为标签 0)两种截然对立的二元离散状态。在以昨天(Lag1)和前天(Lag2)的收益率为特征输入体系后,代码左侧部分循环训练了从 1 阶到 5 阶不同复杂程度的逻辑回归多项式边界,并使用了标准的 accuracy_score(分类准确率,并随后将其翻转为错误率,因为我们在寻找最低误差)去刻画模型表现。正如你在图表中所见,左图那条用经典的 10折 CV 计算出来的红棕色验证错误率曲线,同样呈现出了代表过拟合的 U 型底准星;同时,右图直观展示了模型在等高线二维平面上的真实决策防线(Decision Boundary),告诉你单纯的线性边界是多么的无力,而包含二次甚至三次项的高阶曲线又是如何精巧地蜿蜒穿梭于红蓝两军杂乱的数据丛林中。
# ============================================================
# 第一步:导入分类建模所需的Python工具库
# ============================================================
from sklearn.linear_model import LogisticRegression # 逻辑回归分类器,输出"属于某类的概率"(0到1之间)
from sklearn.metrics import accuracy_score # 计算分类准确率 = 正确预测数 / 总样本数
# ============================================================
# 第二步:准备分类数据——定义海康威视股价"涨"与"跌"
# ============================================================
# 将连续的收益率转化为二分类标签:收益率>0(上涨)=1,≤0(下跌或持平)=0
direction_labels = (target_returns > 0).astype(int) # 转换数据类型
# 构造两个特征:Lag1(昨天收益率)和 Lag2(前天收益率)
# 投资直觉:过去两天的表现可能对明天有预测作用
# 从原始stock_data中计算Lag2(shift(2)取前天的收益率)
stock_data['Lag2'] = stock_data['Return'].shift(2) # 生成滞后2期特征(前天收益率)
# 重新构建包含Lag1、Lag2和Return的数据,去除缺失值,取最近500天
full_analysis_data = stock_data[['Return', 'Lag1', 'Lag2']].dropna().iloc[-500:] # 删除缺失值
# direction_features:用于建模的自变量矩阵(每行两个特征:Lag1和Lag2)
direction_features = full_analysis_data[['Lag1', 'Lag2']].values # 提取为NumPy数组
# direction_labels:因变量(涨=1,跌=0),基于full_analysis_data重新计算以对齐行数
direction_labels = (full_analysis_data['Return'] > 0).astype(int).values # 转换数据类型以上代码完成了分类数据的准备工作,将海康威视股票的连续收益率转化为二元涨跌标签。接下来,我们将训练不同复杂度的逻辑回归模型,并通过交叉验证评估其泛化能力。
# 第四步(左图):计算训练误差和10折CV误差
# ============================================================
degrees = range(1, 6) # 测试1阶到5阶多项式
train_errors = [] # 存储每个阶数的训练误差
cv_errors = [] # 存储每个阶数的交叉验证误差
for degree in degrees: # 遍历循环
# 将原始的2个特征(Lag1, Lag2)扩展为多项式特征
# 例如degree=2时:[Lag1, Lag2] → [1, Lag1, Lag2, Lag1², Lag1×Lag2, Lag2²]
# 这使得逻辑回归能够学习非线性的决策边界
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建多项式转换器
poly_features = polynomial_transformer.fit_transform(direction_features) # 将原始特征扩展为多项式特征
# ---------- 计算训练误差 ----------
# LogisticRegression:逻辑回归分类器
# max_iter=1000:最大迭代1000次以确保收敛
# C=100:正则化参数的倒数,C越大正则化越弱(更倾向于拟合训练数据)
logistic_classifier = LogisticRegression(max_iter=1000, C=100) # 初始化逻辑回归模型
# 在全部数据上训练模型
logistic_classifier.fit(poly_features, direction_labels) # 训练/拟合模型
# 用训练好的模型对训练集本身进行预测
train_pred = logistic_classifier.predict(poly_features) # 使用模型进行预测
# 训练误差 = 1 - 准确率(即错误分类的比例)
# 训练误差通常会随模型复杂度增加而持续下降(因为模型在"记忆"训练数据)
train_error = 1 - accuracy_score(direction_labels, train_pred) # 计算准确率
train_errors.append(train_error) # 将当前阶数的训练误差添加到列表
# ---------- 计算10折交叉验证误差 ----------
# 这才是衡量模型真实泛化能力的核心指标
kfold_splitter = KFold(n_splits=10, shuffle=True, random_state=42) # 初始化K折交叉验证
# cross_val_score自动完成:将数据分成10份,轮流用9份训练1份验证
# scoring='accuracy':用分类准确率作为评判标准
cv_score_results = cross_val_score(LogisticRegression(max_iter=1000, C=100), # 执行10折交叉验证评估
poly_features, direction_labels, cv=kfold_splitter, scoring='accuracy') # 指定多项式特征、标签、折数和准确率评价
# CV误差 = 1 - 平均准确率
cv_error = 1 - cv_score_results.mean() # CV误差 = 1 - 平均准确率
cv_errors.append(cv_error) # 将当前阶数的CV误差添加到列表# ============================================================
# 创建画布(左图为误差曲线,右图为决策边界可视化)
# ============================================================
fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # 创建子图布局
# ---------- 绘制左图:误差曲线对比 ----------
# 蓝线:训练误差(会持续下降——模型越复杂,"死记硬背"能力越强)
axes[0].plot(degrees, train_errors, marker='o', linewidth=2.5, markersize=8, # 绘制训练误差曲线
color='#3498DB', label='训练误差') # 蓝色表示训练误差
# 红线:CV误差(通常呈U型——先下降后上升,反映过拟合)
axes[0].plot(degrees, cv_errors, marker='s', linewidth=2.5, markersize=8, # 绘制CV误差曲线
color='#E74C3C', label='10折CV误差') # 红色表示10折CV误差
# 找出CV误差最小的阶数(最佳模型复杂度)
best_degree_cv = degrees[np.argmin(cv_errors)] # 获取最小值的索引
# 用绿色虚线标记最优阶数
axes[0].axvline(best_degree_cv, linestyle='--', color='green', # 绿色虚线标记CV误差最小的最优阶数
alpha=0.5, label=f'最优阶数: {best_degree_cv}') # 设置半透明和图例标签
axes[0].set_xlabel('多项式阶数', fontsize=13, fontweight='bold') # X轴标签
axes[0].set_ylabel('分类误差率', fontsize=13, fontweight='bold') # Y轴标签
axes[0].set_title('逻辑回归的误差曲线 (海康威视涨跌)\n(Error Rates vs. Polynomial Degree)', # 设置左图标题
fontsize=14, fontweight='bold') # 左图标题
axes[0].legend(fontsize=11) # 显示图例
axes[0].grid(True, alpha=0.3) # 添加网格线
# 第五步(右图):可视化不同复杂度模型的决策边界
# ============================================================
# 决策边界就是一条将"涨"和"跌"两类数据分开的曲线
# 线性模型的决策边界是一条直线;二次模型的边界可以是曲线
degrees_to_show = [1, 2] # 展示1阶(线性)和2阶(二次)两个模型的边界
colors = ['#3498DB', '#E74C3C'] # 蓝色和红色分别对应两个模型
labels = ['线性 (Degree 1)', '二次 (Degree 2)'] # 模型标签说明
# 创建二维网格:在Lag1和Lag2的取值范围内生成密集的网格点
# 这样我们可以对每个网格点预测其涨跌概率,从而画出连续的决策边界
x_min, x_max = direction_features[:, 0].min()-0.5, direction_features[:, 0].max()+0.5 # 取最大值
y_min, y_max = direction_features[:, 1].min()-0.5, direction_features[:, 1].max()+0.5 # Lag2的取值范围
# meshgrid:创建100×100的网格,覆盖整个特征空间
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100)) # 生成等间隔序列
# np.c_:将网格的x坐标和y坐标拼成一个矩阵(10000行×2列)
X_grid = np.c_[xx.ravel(), yy.ravel()] # 展平网格并拼接为特征矩阵
# 对每种复杂度的模型分别绘制决策边界
for idx, (degree, color, label) in enumerate(zip(degrees_to_show, colors, labels)): # 遍历每种模型复杂度绘制决策边界
ax = axes[1] # 在右侧子图上绘制
# 对每种复杂度的模型:构建多项式特征 → 训练模型
polynomial_transformer = PolynomialFeatures(degree=degree) # 创建多项式转换器
poly_features = polynomial_transformer.fit_transform(direction_features) # 转换训练特征
logistic_classifier = LogisticRegression(max_iter=1000, C=100) # 创建逻辑回归分类器
logistic_classifier.fit(poly_features, direction_labels) # 拟合模型参数
# 对网格中的每个点预测"上涨概率"
X_grid_poly = polynomial_transformer.transform(X_grid) # 对数据进行转换
# predict_proba返回每个样本属于两个类别的概率,[:, 1]取"上涨"的概率
Z = logistic_classifier.predict_proba(X_grid_poly)[:, 1] # 预测类别概率
# reshape回网格形状(100×100),用于画等高线
Z = Z.reshape(xx.shape) # 查看数据维度
# contour在概率=0.5处画一条等高线,这就是"决策边界"
# 概率>0.5的区域模型预测为"涨",<0.5的区域预测为"跌"
# 在子图中绘制概率=0.5的等高线,即决策边界
ax.contour(xx, yy, Z, levels=[0.5], colors=[color], linewidths=2, linestyles='solid')
# ---------- 绘制实际数据点 ----------
# 绿色圆点:实际下跌的交易日
axes[1].scatter(direction_features[direction_labels==0, 0], direction_features[direction_labels==0, 1], c='green', alpha=0.4, s=30, label='下跌 (Down)') # 绘制下跌数据点(绿色圆点)
# 红色三角:实际上涨的交易日
axes[1].scatter(direction_features[direction_labels==1, 0], direction_features[direction_labels==1, 1], c='red', alpha=0.4, s=30, marker='^',
label='上涨 (Up)') # 绘制上涨数据点(红色三角)
axes[1].set_xlabel('Lag1 Return (%)', fontsize=13, fontweight='bold') # X轴标签
axes[1].set_ylabel('Lag2 Return (%)', fontsize=13, fontweight='bold') # Y轴标签
axes[1].set_title('不同复杂度模型的决策边界\n(Decision Boundaries)', # 设置右图标题
fontsize=14, fontweight='bold') # 右图标题
axes[1].legend(fontsize=10) # 显示图例
# 自动调整子图间距
plt.tight_layout() # 防止标签重叠
# 渲染并显示图形
plt.show() # 输出最终图表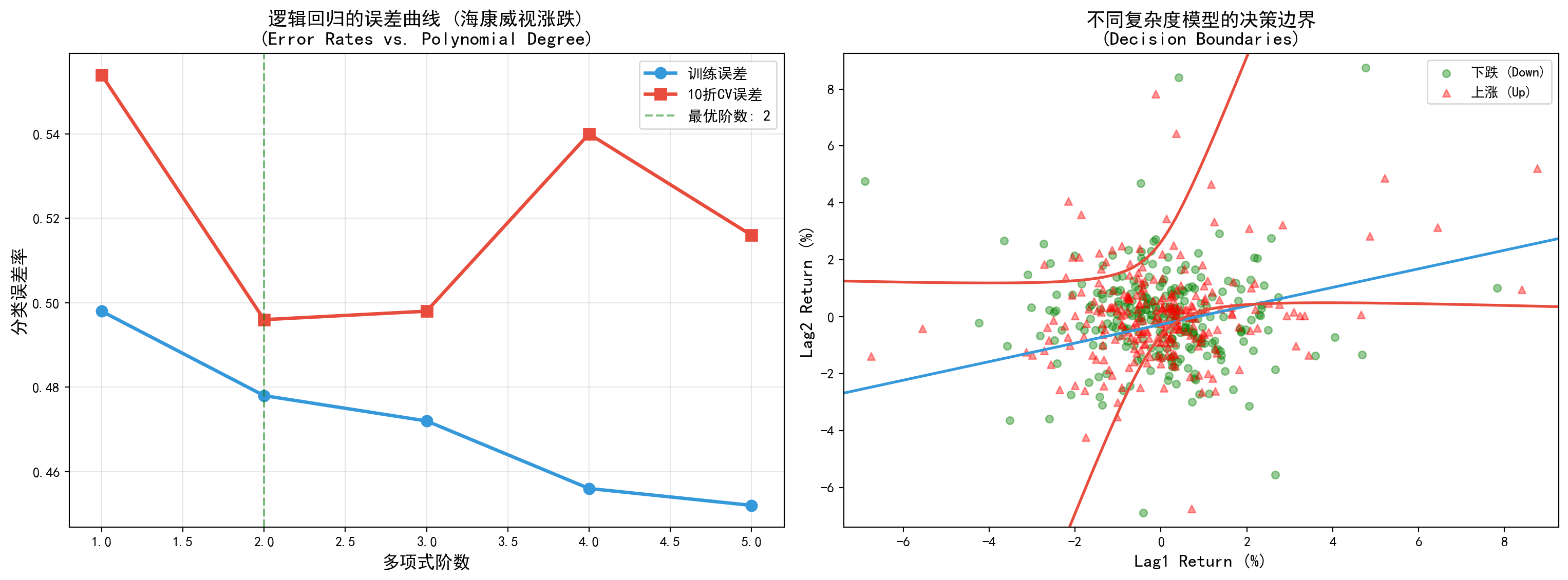
图 6.6 的左图显示了训练误差、10折CV误差随多项式阶数的变化。我们可以看到:
- 训练误差:随着模型灵活度增加,训练误差持续下降(虽然不是完全单调的)。
- CV误差:呈现特征性的U型,先下降后上升,表明过拟合。
- 最优复杂度:CV误差在二次或三次多项式处达到最小,这与真实数据的生成过程一致(真实决策边界是二次的)。
右图展示了不同复杂度模型的决策边界。线性模型显然太简单,无法捕捉数据的非线性模式。二次模型很好地捕捉了决策边界。四次模型虽然拟合训练数据很好,但可能在某些区域出现过度波动。
6.3 自助法 (The Bootstrap)
自助法(bootstrap)是一种广泛适用且极其强大的统计工具,可用于量化与给定估计量或统计学习方法相关的不确定性。作为一个简单的例子,自助法可用于估计线性回归拟合系数的标准误差。在线性回归的特定情况下,这并不是特别有用,因为我们在 章节 4 中看到标准统计软件如R会自动输出此类标准误差。然而,自助法的力量在于它可以轻松应用于广泛的统计学习方法,包括一些难以获得变异性度量且统计软件不会自动输出的方法。
在本节中,我们通过一个简单的例子来说明自助法,在这个例子中,我们希望在一个简单模型下确定最佳投资分配。在 小节 6.3.2 中,我们探索使用自助法来评估线性模型中回归系数的变异性。
6.3.1 投资组合优化案例
假设我们希望将一笔固定金额的资金投资于两种产生收益\(X\)和\(Y\)的金融资产,其中\(X\)和\(Y\)是随机变量。我们将资金的一小部分\(\alpha\)投资于\(X\),剩余的\(1-\alpha\)投资于\(Y\)。由于这两种资产的收益存在变异性,我们希望选择\(\alpha\)来最小化投资的总风险或方差。换句话说,我们想要最小化\(\text{Var}(\alpha X + (1-\alpha)Y)\)。
可以证明,最小化风险的值由下式给出:
\[ \alpha = \frac{\sigma_Y^2 - \sigma_{XY}}{\sigma_X^2 + \sigma_Y^2 - 2\sigma_{XY}} \tag{6.5}\]
其中\(\sigma_X^2 = \text{Var}(X)\),\(\sigma_Y^2 = \text{Var}(Y)\),\(\sigma_{XY} = \text{Cov}(X, Y)\)。
在现实中,量\(\sigma_X^2, \sigma_Y^2\)和\(\sigma_{XY}\)是未知的。我们可以使用包含\(X\)和\(Y\)过去测量值的数据集来计算这些量的估计\(\hat{\sigma}_X^2, \hat{\sigma}_Y^2\)和\(\hat{\sigma}_{XY}\)。然后我们可以使用以下公式估计最小化投资方差的\(\alpha\)值:
\[ \hat{\alpha} = \frac{\hat{\sigma}_Y^2 - \hat{\sigma}_{XY}}{\hat{\sigma}_X^2 + \hat{\sigma}_Y^2 - 2\hat{\sigma}_{XY}} \tag{6.6}\]
使用真实市场数据: 海康威视与宁波银行
让我们使用中国股市的真实数据来演示这个投资组合优化问题。我们将考虑 海康威视(002415.XSHE) 和 宁波银行(002142.XSHE) 这两只具有代表性的股票。
在这个具有标杆意义的实战代码中,我们将展示如何利用 Bootstrapping 这种极其巧妙的重采样技术去直击现代量化投资最核心的命题——用马科维茨的理论去决定“最优投资分配比例 \(\alpha\)”,并给这个估计值打上极其关键的“置信区间”和“不确定性估算”(即标准方差)。我们从中国 A 股的历史洪流中对齐提取了“海康威视”与“宁波银行”两家蓝筹巨头的同期(最近100天)日度真实回报率数据。在经典统计学中,由于金融时间序列极易发生肥尾效应与非正态畸变,要想借助严谨数学公式去强行推导 \(\alpha\) 的标准误通常会面临极大的难度与模型偏误。但这段代码直接绕开了复杂的数学推导,构建了一个循环 300 次的 for 沙盒:它每一次都在这 100 天的历史数据中“有放回地蒙眼抓取”100 天(这就必然导致某天被抓取多次而某些天被遗漏),并在每一次抓取的小宇宙中计算并记录出一个孤立的最优投资比例 \(\hat{\alpha}^{*r}\)。在教学演示中,300 次重采样已经足以稳定展示 Bootstrap 分布的基本形态;若用于正式研究,应进一步提高重采样次数以获得更平滑的估计。
# ============================================================
# 第一步:设置随机种子确保可复现性
# ============================================================
np.random.seed(42) # 固定随机数生成器的起始状态,确保Bootstrap结果可重复
# ============================================================
# 第二步:从本地磁盘读取海康威视和宁波银行的股票数据
# ============================================================
# 拼接前复权股价数据文件的完整路径
stock_data_path = f'{data_base_path}/stock/stock_price_pre_adjusted.h5' # 拼接前复权股价数据文件完整路径
# 读取A股所有上市公司的前复权日度行情数据
stock_market_data = pd.read_hdf(stock_data_path) # 从HDF5文件读取数据
# 分别提取两只股票的收盘价序列
# 海康威视(002415.XSHE):智能安防领域龙头,代表智能安防板块
# 宁波银行(002142.XSHE):城商行优质代表,代表银行板块
if 'order_book_id' in stock_market_data.index.names: # 检查是否含有多层索引
# xs方法从多层索引中按股票代码提取并按日期排序
# 使用cross-section方法提取海康威视的收盘价序列
haikang_price_data = stock_market_data.xs('002415.XSHE', level='order_book_id').sort_index()['close']
# 提取宁波银行的收盘价序列
# 使用cross-section方法提取宁波银行的收盘价序列
ningbo_bank_price_data = stock_market_data.xs('002142.XSHE', level='order_book_id').sort_index()['close']
else: # 默认分支
# 如果没有多层索引,先展平再按条件筛选
stock_data_reset_index = stock_market_data.reset_index() # 展平多层索引为普通列
# 筛选海康威视并以日期为索引
# 设置日期列为索引并提取收盘价
haikang_price_data = stock_data_reset_index[stock_data_reset_index['order_book_id'] == '002415.XSHE'].set_index('date')['close']
# 筛选宁波银行并以日期为索引
# 设置日期列为索引并提取收盘价
ningbo_bank_price_data = stock_data_reset_index[stock_data_reset_index['order_book_id'] == '002142.XSHE'].set_index('date')['close']
# 对齐两只股票的交易日期(join='inner'只保留双方都有交易的日期)
# 合并数据并删除缺失值确保数据完整性
merged_price_data = pd.concat([haikang_price_data, ningbo_bank_price_data], axis=1, join='inner').dropna()
merged_price_data.columns = ['X_Asset', 'Y_Asset'] # X=海康威视,Y=宁波银行接下来,我们计算两只股票的日收益率,并定义计算最优投资比例\(\alpha\)的核心函数——马科维茨最小方差组合公式。
# ============================================================
# 第三步:计算日收益率并准备Bootstrap样本
# ============================================================
# pct_change()自动计算每日收益率 = (今日价格-昨日价格)/昨日价格
daily_returns_df = merged_price_data.pct_change().dropna() # 删除缺失值
# 只使用最近100个交易日(约5个月),模拟"从总体中获得的一个小样本"
observation_count = 100 # 样本量设为100天
daily_returns_df = daily_returns_df.iloc[-observation_count:] # 取最后100行
haikang_returns = daily_returns_df['X_Asset'].values # 海康威视日收益率数组
ningbo_bank_returns = daily_returns_df['Y_Asset'].values # 宁波银行日收益率数组
# ============================================================
# 第四步:定义计算最优投资比例α的函数(马科维茨公式)
# ============================================================
# 这个函数实现了教材中的关键公式:
# α = (σ²_Y - σ_XY) / (σ²_X + σ²_Y - 2σ_XY)
# α表示应该投资在资产X(海康威视)上的比例,1-α投资在资产Y(宁波银行)上
# 该比例能使投资组合的总方差(总风险)最小化
def alpha_func(input_returns_data, sample_indices): # 定义函数alpha_func
# 根据给定索引取出资产X(海康威视)的收益率子集(Bootstrap中同一天可能被多次抽到)
asset_x_subset = input_returns_data.iloc[sample_indices, 0].values # 提取为NumPy数组
# 根据给定索引取出资产Y(宁波银行)的收益率子集
asset_y_subset = input_returns_data.iloc[sample_indices, 1].values # 提取为NumPy数组
# 计算资产X的样本方差(ddof=1使用无偏估计,即除以n-1)
sigma_X2 = np.var(asset_x_subset, ddof=1) # 计算资产X收益率的样本方差
# 计算资产Y的样本方差
sigma_Y2 = np.var(asset_y_subset, ddof=1) # 计算资产Y收益率的样本方差
# 计算两资产收益率的协方差(衡量"同涨同跌"倾向,np.cov返回2×2矩阵,[0,1]为协方差)
assets_covariance = np.cov(asset_x_subset, asset_y_subset, ddof=1)[0, 1] # 计算协方差矩阵
# 代入马科维茨最优投资比例公式:分子=σ²_Y-σ_XY,分母=σ²_X+σ²_Y-2σ_XY
alpha = (sigma_Y2 - assets_covariance) / (sigma_X2 + sigma_Y2 - 2 * assets_covariance) # 计算最小方差组合的最优投资比例
return alpha # 返回最优投资比例α
# ============================================================以上代码完成了数据加载和最优投资比例\(\alpha\)的核心计算函数定义。接下来,我们将运行Bootstrap自助法来估计\(\alpha\)的标准误差,并通过可视化对比自助法分布与模拟”真实”分布的相似性。
# 第四步:用原始完整样本计算α的点估计
# ============================================================
# range(observation_count)表示使用全部100天的数据(不做任何重采样)
estimated_alpha = alpha_func(daily_returns_df, range(observation_count)) # 计算原始完整样本的α点估计
print(f'Original Alpha Estimate: {estimated_alpha:.4f}') # 输出原始估计值
# 这个值告诉我们:为了最小化投资组合风险,应该把约{estimated_alpha*100:.1f}%的资金投给海康威视
# ============================================================
# 第五步:执行Bootstrap(自助法)—— 重采样300次
# ============================================================
# Bootstrap的精髓:我们只有一个100天的样本,无法重新回到市场去收集新数据
# 但我们可以从这100天中"有放回地"反复抽取100天,模拟"如果重新采样会怎样"
# 每次抽取中,某些天会被抽到多次,某些天会被遗漏——这就产生了样本的随机变异
bootstrap_iterations = 300 # 教学演示使用300次Bootstrap采样以控制渲染耗时;正式研究可提高到1000次或更高
bootstrap_alpha_estimates = [] # 存储每次Bootstrap得到的α估计值
# 开始300次Bootstrap重采样循环
for _ in range(bootstrap_iterations): # 遍历循环
# 核心操作:有放回地从0到99中随机抽取100个索引
# replace=True 是关键——它允许同一天被多次抽中
# 例如某次可能抽到 [3, 17, 17, 42, 3, 88, ...],第3天和第17天被重复抽到
# 有放回随机抽取observation_count个索引作为Bootstrap样本
sample_indices = np.random.choice(range(observation_count), size=observation_count, replace=True) # 生成Bootstrap重采样索引
# 在这批"新"样本上重新计算最优投资比例α
current_bootstrap_alpha = alpha_func(daily_returns_df, sample_indices) # 在重抽样数据上计算α
bootstrap_alpha_estimates.append(current_bootstrap_alpha) # 将当次Bootstrap的α估计追加到列表
# 将结果列表转换为NumPy数组,方便数值计算
bootstrap_alpha_estimates = np.array(bootstrap_alpha_estimates) # 构建NumPy数组
# Bootstrap标准误 = 1000个α估计值的标准差
# 这就是我们想要的关键结果:它衡量了α估计的不确定性大小
bootstrap_standard_error = np.std(bootstrap_alpha_estimates, ddof=1) # 计算Bootstrap标准误
print(f'Bootstrap SE: {bootstrap_standard_error:.4f}') # 输出标准误值
# ============================================================
# 第六步:生成"上帝视角"的模拟真实分布(仅用于教学对比)
# ============================================================
# 重要说明:在现实中我们不可能知道总体的真实参数!
# 这里假装我们知道总体参数(用样本的均值和协方差矩阵代替),
# 然后反复从这个"已知总体"中抽取新样本来构建α的"真实"抽样分布
# 目的是让学生直观看到:Bootstrap分布与真实分布非常接近!
population_mean = daily_returns_df.mean() # 用样本均值估计总体均值
population_covariance = daily_returns_df.cov() # 用样本协方差矩阵估计总体参数
simulated_alpha_estimates = [] # 存储每次模拟得到的α
# 从“已知总体”重复抽取300次新样本
simulation_iterations = 300 # 教学演示使用300次模拟抽样以平衡速度与分布展示效果
for _ in range(simulation_iterations): # 遍历循环
# 从"已知总体"的多元正态分布中抽取全新的100天数据
current_simulated_data = np.random.multivariate_normal(population_mean, population_covariance, observation_count) # 从多元正态分布抽取新样本
current_simulated_df = pd.DataFrame(current_simulated_data) # 转换为DataFrame格式
# 在全新数据上计算α
current_simulated_alpha = alpha_func(current_simulated_df, range(observation_count)) # 计算模拟样本的α
simulated_alpha_estimates.append(current_simulated_alpha) # 追加到结果列表
# 将模拟结果转换为NumPy数组
simulated_alpha_estimates = np.array(simulated_alpha_estimates) # 构建NumPy数组
# ============================================================Original Alpha Estimate: 0.3322
Bootstrap SE: 0.0720上述 Bootstrap 自助法运行结果输出了两个关键数值:
- 原始 \(\alpha\) 点估计值:它反映了在当前 100 个交易日样本下、使双资产组合方差最小的海康威视配置比例。若该值约为三分之一,就意味着组合中的大部分权重仍会分配给宁波银行,从而借助两只股票收益协动关系来压低整体波动。
- Bootstrap 标准误:经过多次(此处为 300 次)有放回重采样后,\(\hat{\alpha}\) 的标准差给出了这一最优权重估计的不确定性量级。标准误越大,说明’最优配置比例’对样本抽取越敏感;对基金经理而言,这意味着仅凭 100 天数据作出的配置判断仍存在明显抽样误差,实务上应结合更长样本、稳健约束或滚动估计来辅助决策。
接下来绘制三张对比图,直观展示 Bootstrap 分布与模拟真实分布的高度相似性。
# 第七步:绘制三张对比图
# ============================================================
# figsize=(18,6):宽18英寸×高6英寸的画布,包含3个子图
fig, axes = plt.subplots(1, 3, figsize=(18, 6)) # 创建子图布局
# ---------- 左图:模拟的"真实"抽样分布(上帝视角) ----------
# 这是理论基准:如果我们能反复从总体中取样,α的分布会是什么样
# 绘制模拟抽样分布的直方图(40个bins)
axes[0].hist(simulated_alpha_estimates, bins=40, alpha=0.7, color='#3498DB', edgecolor='black') # 蓝色直方图显示模拟分布
# 用红色虚线标记分布的均值
axes[0].axvline(np.mean(simulated_alpha_estimates), color='red', linestyle='--', label=f'Mean: {np.mean(simulated_alpha_estimates):.3f}') # 红色虚线标记均值
axes[0].set_xlabel('Alpha', fontsize=12, fontweight='bold') # X轴标签
axes[0].set_title('模拟抽样分布 ("True" Sampling Dist)\n(Simulated from Population)', fontsize=13) # 左图标题
axes[0].legend() # 显示图例
axes[0].grid(True, alpha=0.3) # 添加网格线
# ---------- 中图:Bootstrap自助法分布 ----------
# 这是我们在实际中能做到的:从单一样本出发,通过有放回抽样估计α的分布
# 绘制Bootstrap自助法分布的直方图
axes[1].hist(bootstrap_alpha_estimates, bins=40, alpha=0.7, color='#E74C3C', edgecolor='black') # 红色直方图显示Bootstrap分布
# 蓝色实线标记原始样本的α估计值
axes[1].axvline(estimated_alpha, color='blue', linewidth=2, label=f'Original: {estimated_alpha:.3f}') # 蓝色实线标记原始估计值
axes[1].set_xlabel('Alpha', fontsize=12, fontweight='bold') # X轴标签
axes[1].set_title(f'自助法分布 (Bootstrap Dist)\n(SE = {bootstrap_standard_error:.3f})', fontsize=13) # 中图标题
axes[1].legend() # 显示图例
axes[1].grid(True, alpha=0.3) # 添加网格线
# ---------- 右图:箱线图并排比较 ----------
# 箱线图可以直观比较两种方法得到的α分布:
# 中位线(箱子中间的横线)、四分位距(箱子的宽度)、异常值(胡须外的点)
# 绘制两种方法的箱线图进行并排对比
axes[2].boxplot([simulated_alpha_estimates, bootstrap_alpha_estimates], labels=['Simulation', 'Bootstrap'], patch_artist=True,
boxprops=dict(facecolor='lightblue')) # 箱子填充浅蓝色
axes[2].set_title('分布比较 (Comparison)', fontsize=13) # 右图标题
axes[2].grid(True, alpha=0.3, axis='y') # 仅在Y轴方向添加网格线
# 自动调整子图间距
plt.tight_layout() # 自动调整子图间距
# 渲染并显示图形
plt.show() # 显示图形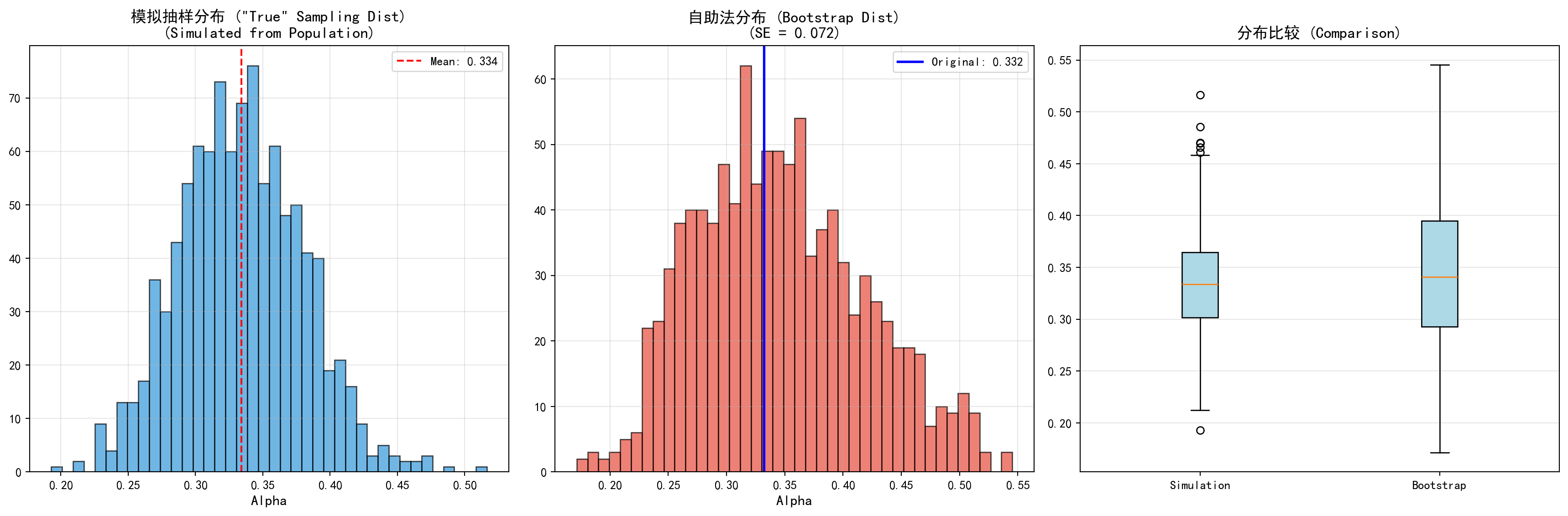
图 6.7 清楚地展示了自助法的核心思想:
左图:显示从真实总体生成1,000个模拟数据集得到的\(\alpha\)估计的分布。这是理想情况,但在实践中无法实现,因为我们无法访问真实总体。
中图:显示从单个数据集的1,000个自助样本得到的\(\alpha\)估计的分布。这个直方图看起来与左图非常相似!
右图:箱线图比较显示,两种方法的分布非常相似,表明自助法可以有效地估计估计量的变异性。
自助法的原理:
在实践中,我们不能从原始总体生成新样本,因此无法应用上述估计\(\text{SE}(\hat{\alpha})\)的过程。然而,自助法方法允许我们使用计算机来模拟获取新样本集的过程,这样我们就可以在不生成额外样本的情况下估计\(\hat{\alpha}\)的变异性。
我们不是从总体重复获得独立的数据集,而是通过重复从原始数据集中有放回地抽样观测来获得不同的数据集。
Tip: 自助法的数学原理
自助法的理论基础是大数定律和Glivenko-Cantelli定理。当样本量\(n\)足够大时,经验分布函数(empirical distribution function)以概率1收敛于真实分布函数。因此,从原始数据中自助抽样近似于从真实总体中抽样。
具体来说,如果\(X_1, \ldots, X_n\)是从分布\(F\)中抽取的独立同分布样本,那么经验分布\(\hat{F}_n\)收敛于\(F\)。从\(\hat{F}_n\)中抽取的样本(即自助样本)的渐近性质与从\(F\)中抽取的样本相同。
这意味着,对于许多统计量,自助法可以提供其抽样分布的一致估计。
数学推导:观测点出现在自助样本中的概率
我们经常提及自助样本大约包含了原始数据中的 \(63.2\%\) 的独特观测,这一性质可以通过简单的概率论来严格证明。假设原始数据集有 \(n\) 个独立观测。在自助抽样中,我们有放回地独立随机抽取 \(n\) 次。
针对第 \(i\) 个特定观测点,在某单次抽取中它没有被选中的概率为 \(1 - \frac{1}{n}\)。 由于这 \(n\) 次抽取是相互独立的,所以在全部 \(n\) 次抽取中,第 \(i\) 个观测点始终未被选中的概率为: \[ P(\text{未被选中}) = \left(1 - \frac{1}{n}\right)^n \]
相应地,该观测点至少被选中一次的概率为: \[ P(\text{被选中}) = 1 - \left(1 - \frac{1}{n}\right)^n \]
根据微积分定理,我们知道自然对数底 \(e\) 的极限定义:\(\lim_{n \to \infty} \left(1 - \frac{1}{n}\right)^n = \frac{1}{e} \approx 0.368\)。 因此,当 \(n\) 较大时,任何特定的原始观测点大约有 \(1 - 1/e \approx 0.632\) (63.2%) 的概率出现在这个自助样本中。
那些未进入当前自助样本的剩余的约 36.8% 的观测,被称为袋外数据 (Out-of-Bag, OOB)。袋外数据极为有用,因为它们可以作为模型的天然验证集,无需像交叉验证那样做显式的数据切分。
6.3.2 自助法的实现步骤
自助法的实现步骤如下:
原始数据集:我们有包含\(n\)个观测的原始数据集\(Z = \{(x_1, y_1), \ldots, (x_n, y_n)\}\)。
创建自助样本:从\(Z\)中有放回地随机选择\(n\)个观测,产生第一个自助数据集\(Z^{*1}\)。有放回抽样意味着同一个观测可以在自助数据集中出现多次。
计算统计量:使用\(Z^{*1}\)计算感兴趣统计量的自助估计(例如,\(\hat{\alpha}^{*1}\))。
重复步骤2-3:将此过程重复\(B\)次(\(B\)是一个较大的数,如1,000或10,000),产生\(B\)个不同的自助数据集\(Z^{*1}, Z^{*2}, \ldots, Z^{*B}\)和\(B\)个相应的估计\(\hat{\alpha}^{*1}, \hat{\alpha}^{*2}, \ldots, \hat{\alpha}^{*B}\)。
计算标准误差:使用以下公式计算这些自助估计的标准误差:
\[ \text{SE}_B(\hat{\alpha}) = \sqrt{\frac{1}{B-1}\sum_{r=1}^{B}\left(\hat{\alpha}^{*r} - \frac{1}{B}\sum_{r'=1}^{B}\hat{\alpha}^{*r'}\right)^2} \tag{6.7}\]
这作为从原始数据集估计的\(\hat{\alpha}\)的标准误差的估计。
Clarification on 自助法的适用性
自助法虽然强大,但也有一些局限性:
对小样本的偏差:当样本量很小时,自助法估计可能有偏差。例如,估计中位数的标准误差在小样本时可能不准确。
对非光滑统计量的挑战:对于非光滑统计量(如中位数、分位数),自助法的一致性可能不成立。
依赖数据质量:自助法假设原始样本能够代表总体。如果原始样本有偏差或有异常值,自助法估计也会受到影响。
计算成本:虽然比重复收集数据便宜,但对于大型数据集和复杂模型,自助法的计算成本仍然可能很高。
6.4 本章小结 (Chapter Summary)
本章详细介绍了两种最重要的重采样方法:交叉验证和自助法。
6.4.1 交叉验证 (Cross-Validation)
- 验证集方法:简单直观,但估计的变异性高且可能高估测试误差。
- 留一交叉验证(LOOCV):偏差小,结果确定,但计算成本高且方差较大。
- k折交叉验证:
- 在偏差和方差之间提供了良好的权衡
- 计算效率高
- 通常使用\(k=5\)或\(k=10\)
- 分类问题的交叉验证:使用分类错误率而不是MSE来评估性能。
6.4.2 自助法 (The Bootstrap)
- 核心思想:通过有放回地从原始数据集抽样来模拟从总体抽样的过程。
- 主要用途:
- 估计参数的标准误差
- 构建置信区间
- 评估统计学习方法的变异性
- 优点:
- 适用范围广,几乎可以用于任何统计方法
- 不依赖强分布假设
- 实现简单
- 局限性:
- 小样本时可能有偏差
- 对某些统计量可能不适用
- 计算成本较高
6.4.3 实际应用建议
- 模型选择:优先使用k折交叉验证(通常k=5或k=10)
- 模型评估:使用独立的测试集或交叉验证
- 不确定性量化:对于标准误差和置信区间,如果解析方法不可用,使用自助法
- 计算效率:对于大型数据集,考虑使用较少的折数或较少的自助重复次数
重采样方法是现代统计学习实践的基础工具,它们使我们能够在没有额外数据的情况下评估模型性能和量化不确定性,是每个数据科学家必须掌握的核心技能。
6.5 理论来源与前沿
交叉验证与自助法的理论根基是用‘重复抽样’逼近‘重复实验’:当我们无法无限次从总体抽样时,就用数据自身构造近似的重复样本来估计泛化误差或统计量的不确定性。Efron 的 bootstrap 把这一思想系统化,并给出了在多类估计问题上的一致性与偏差修正工具。
近年来的研究与实践重点包括:
- 模型选择偏差:当我们用同一套交叉验证同时做模型选择与误差估计时,误差会偏乐观,需要嵌套交叉验证或独立测试集。
- 时间序列与面板数据的重采样:需要 block bootstrap、滚动窗口 CV 等结构化方法以保留相关性。
- 大规模计算下的近似:在算力受限时,用更少折数、分层抽样与并行化来取得工程上可用的近似。
6.6 练习
6.6.1 概念题
比较验证集方法、LOOCV 与 \(k\) 折交叉验证:它们在偏差、方差与计算成本上的主要差异是什么?
为什么在时间序列或金融数据中,随机打乱的交叉验证可能产生严重的数据泄露?给出一个具体例子。
什么是嵌套交叉验证?它解决了什么偏差问题?
bootstrap 估计标准误与置信区间的核心假设是什么?在什么情况下 bootstrap 可能失败?
当模型选择与误差评估使用同一份数据时,为什么测试误差往往被低估?
6.6.2 应用题
- 用你本机 A 股日度数据构造一个预测任务(回归或分类均可),比较:
- 时间切分(训练在前、测试在后)
- 随机切分
报告两者的测试集表现,并解释差异。
- 选择一家长三角上市公司,估计其日收益率均值的 95% 置信区间:
- 方法一:正态近似(用样本均值与标准误)
- 方法二:bootstrap 百分位区间
比较两种区间的长度与稳定性。
- 在一个包含超参数的模型(例如岭回归或 Lasso)上,分别用普通 \(k\) 折 CV 与嵌套 CV 做模型选择,比较得到的测试误差估计是否存在系统偏差。
6.6.3 理论题
在 LOOCV 中,证明每次训练集只少一个样本,因此 LOOCV 的训练集偏差通常较小,但方差可能较大。
给出 bootstrap 百分位区间的定义,并解释为什么它在分布偏斜或统计量非正态时可能优于正态近似区间。
6.7 练习参考解答
6.7.1 概念题参考解答
- 三种 CV 的差异
- 验证集法:最快,但对一次切分很敏感(方差大)。
- LOOCV:偏差小,但每次训练集几乎相同,预测误差高度相关,方差可能较大,且对某些模型计算成本高。
- \(k\) 折 CV:在偏差与方差之间折中,工程上最常用(常见 \(k=5\) 或 \(k=10\))。
- 时间序列的泄露
若把 2024 年的数据随机分到训练集,而 2020 年的数据分到测试集,模型会在训练阶段‘见过未来’的分布与模式,从而高估测试性能。
- 嵌套 CV 的作用
外层用于估计泛化误差,内层用于选择超参数。这样避免‘用同一份数据既选模型又评估’导致的乐观偏差。
- bootstrap 的假设与失效
核心假设是样本能代表总体且观测近似独立同分布。强相关、结构突变或极端小样本会使 bootstrap 区间失真。
- 误差低估原因
模型选择过程本身会把噪声当作信号(对训练数据‘过度适配’),因此若评估不独立,会系统性低估测试误差。
6.7.2 应用题参考解答
- 时间切分 vs 随机切分(模板)
import pandas as pd # 导入pandas用于数据框操作
import numpy as np # 导入numpy用于数值计算
import os # 导入os用于路径处理
from sklearn.linear_model import Ridge # 导入岭回归模型
from sklearn.metrics import mean_squared_error # 导入均方误差评估函数
DATA_DIR = 'C:/qiufei/data' if os.name == 'nt' else '/home/ubuntu/r2_data_mount/data' # 根据操作系统选择数据路径
price_path = os.path.join(DATA_DIR, 'stock/stock_price_pre_adjusted.h5') # 拼接前复权股价文件路径
stock_price_data = pd.read_hdf(price_path).reset_index() # 读取并重置MultiIndex
stock_price_data = stock_price_data[stock_price_data['order_book_id'] == '002415.XSHE'].copy() # 筛选海康威视
stock_price_data['date'] = pd.to_datetime(stock_price_data['date']) # 确保日期为datetime类型
stock_price_data = stock_price_data.sort_values('date') # 按日期排序stock_price_data['ret'] = stock_price_data['close'].pct_change() # 计算日收益率
stock_price_data['y'] = stock_price_data['ret'].shift(-1) # 构造下一期收益率作为预测目标
stock_price_data['x1'] = stock_price_data['ret'].rolling(5).mean() # 5日收益率均值特征
stock_price_data['x2'] = stock_price_data['ret'].rolling(20).std() # 20日收益率标准差特征
cleaned_analysis_data = stock_price_data[['date', 'y', 'x1', 'x2']].dropna().copy() # 选取日期和特征列并删除缺失值# 时间切分
split = cleaned_analysis_data['date'].quantile(0.8) # 计算80%分位数时间点
train_time_split = cleaned_analysis_data[cleaned_analysis_data['date'] <= split] # 训练集:前80%时间段
test_time_split = cleaned_analysis_data[cleaned_analysis_data['date'] > split] # 测试集:后20%时间段
model_time = Ridge(alpha=1.0).fit(train_time_split[['x1', 'x2']], train_time_split['y']) # 在训练集上拟合岭回归模型
predictions_time_split = model_time.predict(test_time_split[['x1', 'x2']]) # 在测试集上预测
print('time_split_mse:', mean_squared_error(test_time_split['y'], predictions_time_split)) # 输出时间切分MSEtime_split_mse: 0.00031587245757769386# 随机切分(示例,不建议用于时间序列)
randomized_data = cleaned_analysis_data.sample(frac=1.0, random_state=7) # 随机打乱数据顺序
sample_size = len(randomized_data) # 获取样本量
train_random_split = randomized_data.iloc[: int(0.8*sample_size)] # 前80%作为训练集
test_random_split = randomized_data.iloc[int(0.8*sample_size):] # 后20%作为测试集
model_random = Ridge(alpha=1.0).fit(train_random_split[['x1', 'x2']], train_random_split['y']) # 拟合岭回归模型
predictions_random_split = model_random.predict(test_random_split[['x1', 'x2']]) # 在测试集上预测
print('random_split_mse:', mean_squared_error(test_random_split['y'], predictions_random_split)) # 输出随机切分MSErandom_split_mse: 0.0005519100942344951随机切分往往更乐观,因为训练集包含了更接近测试期的’未来结构’信息。
- 收益均值置信区间
- 正态近似:\(\bar r \pm 1.96\, s/\sqrt{n}\)。
- bootstrap:重复有放回抽样得到 \(\bar r^*\) 的分布,取 2.5% 与 97.5% 分位数。
import numpy as np # 导入numpy用于数值计算
import pandas as pd # 导入pandas用于数据框操作
target_returns_array = stock_price_data['ret'].dropna().to_numpy() # 从股价数据中提取日收益率数组
sample_size = target_returns_array.size # 获取样本量
sample_mean = target_returns_array.mean() # 计算样本均值
standard_error = target_returns_array.std(ddof=1) / np.sqrt(sample_size) # 计算标准误差
confidence_interval_normal = (sample_mean - 1.96*standard_error, sample_mean + 1.96*standard_error) # 正态近似95%置信区间bootstrap_count = 500 # 教学演示使用500次bootstrap重抽样以缩短渲染时间;正式研究可进一步增加
bootstrap_sample_means = np.empty(bootstrap_count) # 初始化存储bootstrap均值的数组
random_number_generator = np.random.default_rng(7) # 创建随机数生成器,设置种子为7
for b in range(bootstrap_count): # 遍历每次bootstrap
resample_indices = random_number_generator.integers(0, sample_size, size=sample_size) # 有放回抽取样本索引
bootstrap_sample_means[b] = target_returns_array[resample_indices].mean() # 计算重抽样均值
confidence_interval_bootstrap = (np.quantile(bootstrap_sample_means, 0.025), np.quantile(bootstrap_sample_means, 0.975)) # bootstrap 95%置信区间
print('ci_norm:', confidence_interval_normal) # 输出正态近似置信区间
print('ci_boot:', confidence_interval_bootstrap) # 输出bootstrap置信区间ci_norm: (9.793520519545324e-05, 0.0015934204044003141)
ci_boot: (5.30666584045486e-05, 0.0015078961821221233)- 嵌套 CV(思路)
外层把数据切成若干折;对外层每个训练折,再用内层 CV 选择 \(\lambda\),然后在外层测试折上评估。对比普通 CV 的误差估计,嵌套 CV 通常更保守、更接近真实泛化误差。
6.7.3 理论题参考解答
- LOOCV 的偏差与方差直觉
每次训练集大小为 \(n-1\),与全样本训练接近,因此偏差较小;但每次预测误差来自高度重叠的训练集,导致误差项相关,方差可能较大。
- bootstrap 百分位区间
令统计量为 \(T\),bootstrap 样本得到 \(T^*_1,\dots,T^*_B\)。百分位区间定义为 \[ [\,\mathrm{quantile}(T^*,0.025),\ \mathrm{quantile}(T^*,0.975)\,]. \] 当 \(T\) 分布偏斜或非正态时,正态近似区间可能不对称且覆盖率偏离,百分位区间往往更贴近经验分布。